Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
L'analyse des sentiments fait référence à l'identification et à la classification des sentiments exprimés dans la source du texte. Les tweets sont souvent utiles pour générer une grande quantité de données de sentiment après analyse. Ces données sont utiles pour comprendre l'opinion des gens sur une variété de sujets..
Donc, nous devons développer un Modèle d'analyse des sentiments d'apprentissage automatique automatisé pour calculer la perception des clients. En raison de la présence de caractères non utiles (collectivement appelé bruit) avec des données utiles, difficile d'y implémenter des modèles.
Dans cet article, notre objectif est d'analyser le sentiment des tweets fournis par le Ensemble de données Sentiment140 en développant un pipeline d'apprentissage automatique qui implique l'utilisation de trois classificateurs (Régression logistique, Bernoulli Naive Bayes et SVM) avec l'utilisation Terme Fréquence – Inverser la fréquence des documents (TF-IDF). La performance de ces classificateurs est ensuite évaluée en utilisant précision Oui Les scores de F1.

Source de l'image: Google images
Approche du probléme
Dans ce projet, nous essayons de mettre en place un Modèle d'analyse des sentiments Twitter qui aide à surmonter les défis de l'identification des sentiments à partir des tweets. Les détails nécessaires concernant l'ensemble de données sont:
L'ensemble de données fourni est le Ensemble de données Sentiment140 Il se compose de 1,600,000 tweets qui ont été extraits à l'aide de l'API Twitter. Les différentes colonnes présentes dans le jeu de données sont:
- objectif: la polarité du tweet (positif ou négatif)
- identifiants: ID de tweet unique
- Date: la date du tweet
- drapeau: Fait référence à la requête. S'il n'y a pas une telle requête, alors ce n'est PAS DE LA CONSULTATION.
- Nom d'utilisateur: Fait référence au nom de l'utilisateur qui a tweeté.
- texte: Fait référence au texte du tweet.
Pipeline de projets
Les différentes étapes de la Pipeline d'apprentissage automatique est-ce ainsi :
- Importer les dépendances requises
- Lire et charger l'ensemble de données
- L'analyse exploratoire des données
- Visualisation des données des variables cibles
- Prétraitement des données
- Diviser nos données en sous-ensembles d'entraînement et de test
- Transformer l'ensemble de données à l'aide de TF-IDF Vectorizer
- Fonction d'évaluation du modèle
- Construction du modèle
- conclusion
Commençons,
Paso 1: importer les dépendances nécessaires
# utilitaires
importation re
importer numpy en tant que np
importer des pandas au format pd
# traçage
importer seaborn comme sns
à partir de wordcloud importer WordCloud
importer matplotlib.pyplot en tant que plt
# nltk
à partir de nltk.stem importer WordNetLemmatizer
# apprendre
depuis sklearn.svm importer LinearSVC
de sklearn.naive_bayes import BernoulliNB
de sklearn.linear_model import LogisticRegression
de sklearn.model_selection importer train_test_split
de sklearn.feature_extraction.text importer TfidfVectorizer
de sklearn.metrics importer confusion_matrix, classement_rapport
Paso 2: lire et charger l'ensemble de données
# Importation du jeu de données
DATASET_COLUMNS=['cible','identifiants','Date','drapeau','utilisateur','texte']
DATASET_ENCODING = "ISO-8859-1"
df = pd.read_csv('Project_Data.csv', encoding=DATASET_ENCODING, noms=JEU DE DONNÉES_COLUMNS)
df.échantillon(5)
Production:

Paso 3: L'analyse exploratoire des données
3.1: Cinq principaux registres de données
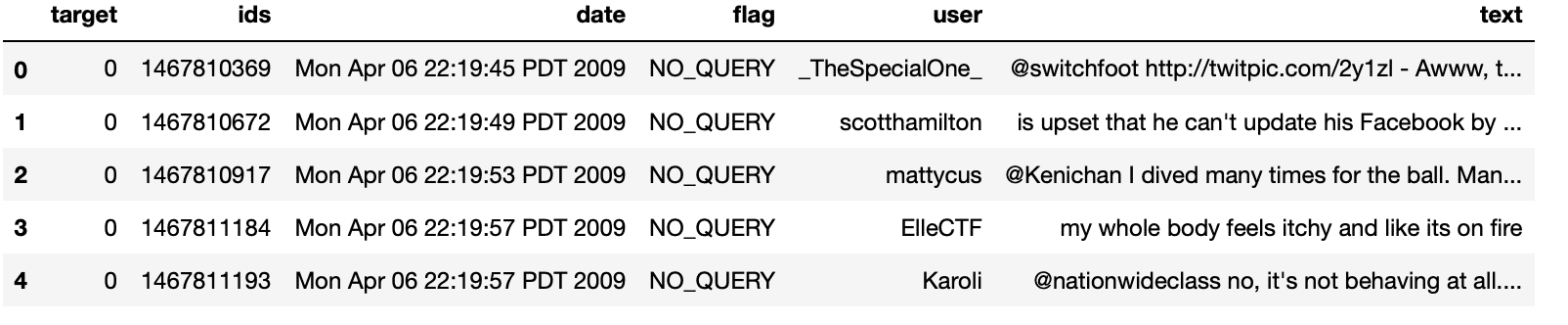
df.head()
Production:
3.2: Colonnes / caractéristiques dans les données
df.colonnes
Production:
Indice(['cible', 'identifiants', 'Date', 'drapeau', 'utilisateur', 'texte'], type="objet")
3.3: Longueur de l'ensemble de données
imprimer('la longueur des données est', longueur(df))
Production:
la longueur des données est 1048576
3.4: Formulaire de données
df. forme
Production:
(1048576, 6)
3.5: Informations de données
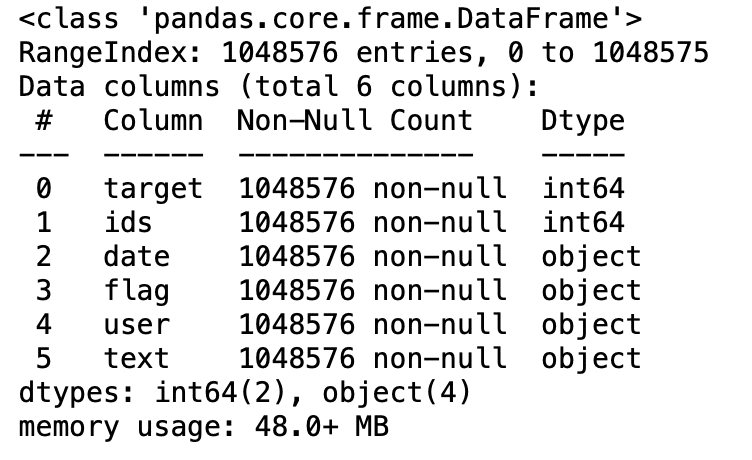
df.info()
Production:
3.6: Types de données de toutes les colonnes
df.dtypes
Production:
cible int64 identifiants int64 objet date objet indicateur objet utilisateur objet texte dtype: objet
3.7: Vérification des valeurs nulles
np.sum(df.isnull().tout(axe=1))
Production:
0
3.8: Lignes et colonnes de l'ensemble de données
imprimer('Le nombre de colonnes dans les données est: ', longueur(df.colonnes))
imprimer('Le nombre de lignes dans les données est: ', longueur(df))
Production:
Le nombre de colonnes dans les données est: 6 Le nombre de lignes dans les données est: 1048576
3.9: Vérifier les valeurs d'objectif unique
df['cible'].unique()
Production:
déployer([0, 4], dtype=int64)
3.10: Vérifier le nombre de valeurs cibles
df['cible'].nuniquam()
Production:
2
Paso 4: Affichage des données de variable cible
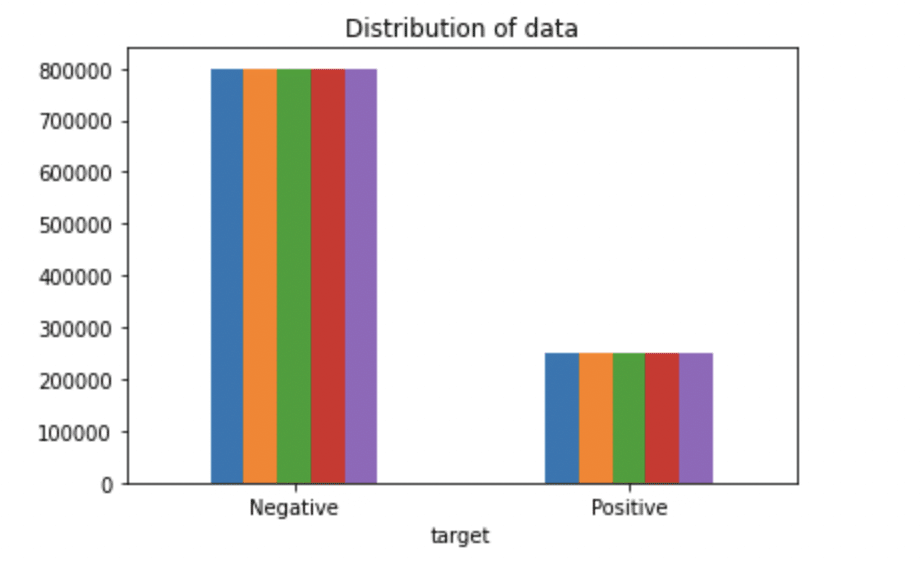
# Tracer la distribution de l'ensemble de données.
ax = df.groupby('cible').compter().terrain(genre='bar', titre="Diffusion des données",légende=Faux)
ax.set_xticklabels(['Négatif','Positif'], rotation=0)
# Stocker des données dans des listes.
texte, sentiment = liste(df['texte']), liste(df['cible'])
Production:
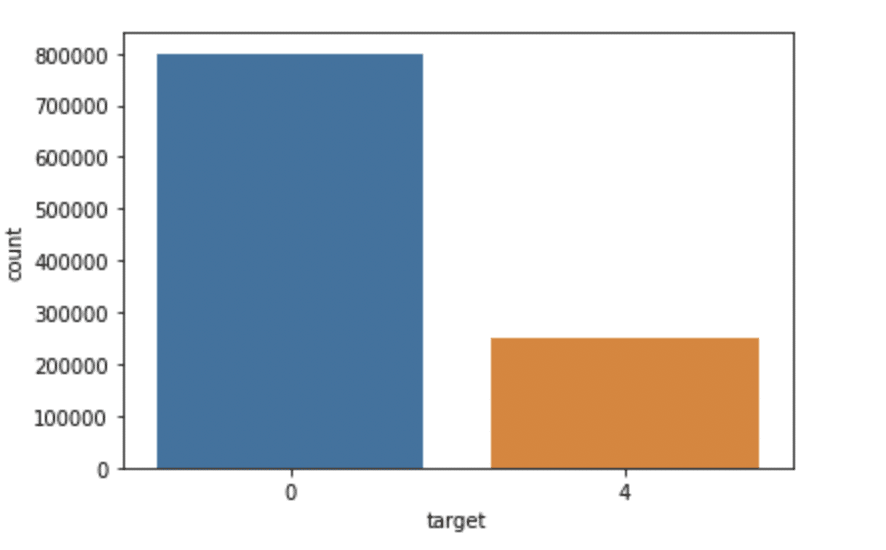
importer seaborn comme sns
sns.countplot(x='cible', données=df)
Production:
Paso 5: prétraitement des données
Dans l'énoncé du problème ci-dessus avant d'entraîner le modèle, nous avons effectué plusieurs étapes de prétraitement sur l'ensemble de données qui concernaient principalement la suppression des mots vides, supprimer les emojis. Alors, le document texte est converti en minuscules pour une meilleure généralisation.
Ensuite, les partitions ont été nettoyées et supprimées, réduisant ainsi le bruit inutile de l'ensemble de données. Après cela, nous avons également supprimé les caractères répétitifs des mots ainsi que les URL, car ils n'ont pas d'importance significative.
Enfin, Nous effectuons Racine (réduire les mots à leurs racines dérivées) Oui Lématisation (réduire les mots dérivés à leur forme racine connue sous le nom de lemme) pour les meilleurs résultats.
5.1: Sélectionnez le texte cible et la colonne pour notre analyse plus approfondie
données=df[['texte','cible']]
5.2: Remplacement des valeurs pour faciliter la compréhension. (Attribution 1 au sentiment positif 4)
Les données['cible'] = données['cible'].remplacer(4,1)
5.3: Imprimer les valeurs uniques des variables cibles
Les données['cible'].unique()
Production:
déployer([0, 1], dtype=int64)
5.4: Séparation des tweets positifs et négatifs
data_pos = données[Les données['cible'] == 1] data_neg = données[Les données['cible'] == 0]
5.5: prendre un quart des données pour pouvoir tourner sur notre machine facilement
pos_données = pos_données.iloc[:entier(20000)] data_neg = data_neg.iloc[:entier(20000)]
5.6: Combiner des tweets positifs et négatifs
jeu de données = pd.concat([pos_données, data_neg])
5.7: Mettre le texte de la déclaration en minuscules
base de données['texte']=ensemble de données['texte'].str.inférieur() base de données['texte'].queue()
Production:

5.8: Ensemble de définitions contenant tous les mots vides en anglais.
liste de mots vides = ['une', 'À propos', 'dessus', 'après', 'de nouveau', 'est', 'tous', 'un m', 'un',
'et','tout','sommes', 'comme', 'à', 'être', 'car', 'été', 'avant',
'étant', 'au dessous de', 'entre','les deux', 'par', 'pouvez', 'ré', 'fait', 'faire',
'Est-ce que', 'Faire', 'vers le bas', 'pendant', 'chaque','quelque', 'pour', 'de',
'plus loin', 'avais', 'a', 'ont', 'ayant', 'il', 'sa', 'ici',
'la sienne', 'se', 'lui', 'lui-même', 'le sien', 'comment', 'je', 'si', 'dans',
'dans','est', 'ce', 'son', 'lui-même', 'seulement', 'll', 'm', 'ma',
'moi', 'Suite', 'plus','ma', 'moi même', 'maintenant', 'O', 'de', 'au', 'une fois que',
'seul', 'ou', 'autre', 'notre', 'les notres','nous-mêmes', 'dehors', 'posséder', 'ré','s', 'même', 'elle', "elle", 'devrait', "j'aurais dû",'donc', 'certains', 'tel',
't', 'que', 'cette', "ça va", 'les', 'leur', 'les leurs', 'eux',
'eux-mêmes', 'alors', 'là', 'ces', 'elles ou ils', 'cette', 'celles',
'par', 'à', 'trop','sous', 'jusqu'à', 'en haut', 'et', 'très', 'était',
'nous', 'étaient', 'Quel', 'lorsque', 'où','lequel','tandis que', 'qui', 'qui',
'Pourquoi', 'volonté', 'avec', 'a gagné', 'et', 'tu', "tu es","tu vas", "tu es",
"vous avez", 'ton', 'les vôtres', 'toi-même', 'vous-mêmes']
5.9: Nettoyer et supprimer l'ancienne liste de mots vides du texte du tweet
STOPWORDS = définir(liste de mots vides)
def nettoyage_mots stop(texte):
revenir " ".rejoindre([mot pour mot en str(texte).diviser() si le mot n'est pas dans les STOPWORDS])
base de données['texte'] = jeu de données['texte'].appliquer(texte lambda: nettoyage_mots_arrêts(texte))
base de données['texte'].diriger()
Production:

5.10: Nettoyage et suppression des partitions
chaîne d'importation
ponctuations_english = chaîne.ponctuation
liste_ponctuations = ponctuations_english
def nettoyage_ponctuations(texte):
traducteur = str.maketrans('', '', liste_ponctuations)
renvoyer le texte.translate(traducteur)
base de données['texte']= jeu de données['texte'].appliquer(lambda x: nettoyage_ponctuations(X))
base de données['texte'].queue()
Production:

5.11: Nettoyer et supprimer les caractères répétés
def nettoyage_répétition_char(texte):
retour re.sub(r'(.)1+', r'1', texte)
base de données['texte'] = jeu de données['texte'].appliquer(lambda x: nettoyage_répétition_char(X))
base de données['texte'].queue()
Production:

5.12: Nettoyage et suppression d'URL
def nettoyage_URLs(Les données):
retour re.sub('((www.[^s]+)|(https?://[^s]+))',' ',Les données)
base de données['texte'] = jeu de données['texte'].appliquer(lambda x: nettoyage_URLs(X))
base de données['texte'].queue()
Production:

5.13: Nettoyage et suppression des nombres numériques
def nettoyage_numéros(Les données):
retour re.sub('[0-9]+', '', Les données)
base de données['texte'] = jeu de données['texte'].appliquer(lambda x: nombre_nettoyage(X))
base de données['texte'].queue()
Production:

5.14: Obtenir la tokenisation du texte du tweet
de nltk.tokenize importer RegexpTokenizer tokenizer = RegexpTokenizer(r'w+') base de données['texte'] = jeu de données['texte'].appliquer(tokenizer.tokenize) base de données['texte'].diriger()
Production:

5.15: Demande de contournement
importer nltk
st = nltk.PorterStemmer()
def stemming_on_text(Les données):
texte = [st.tige(mot) pour mot dans les données]
renvoyer des données
base de données['texte']= jeu de données['texte'].appliquer(lambda x: stemming_on_text(X))
base de données['texte'].diriger()
Production:

5.16: Application de lemmatiseur
lm = nltk.WordNetLemmatizer()
def lemmatizer_on_text(Les données):
texte = [lm.lemmatize(mot) pour mot dans les données]
renvoyer des données
base de données['texte'] = jeu de données['texte'].appliquer(lambda x: lemmatizer_on_text(X))
base de données['texte'].diriger()
Production:

5.17: Séparation de la fonction d'entrée et de l'étiquette
X=données.texte y=données.cible
5.18: tracer un nuage de mots pour les tweets négatifs
data_neg = données['texte'][:800000]
plt.figure(taille de la figue = (20,20))
wc = WordCloud(max_mots = 1000 , largeur = 1600 , hauteur = 800,
collocations=Faux).produire(" ".rejoindre(data_neg))
plt.imshow(toilettes)
Production:
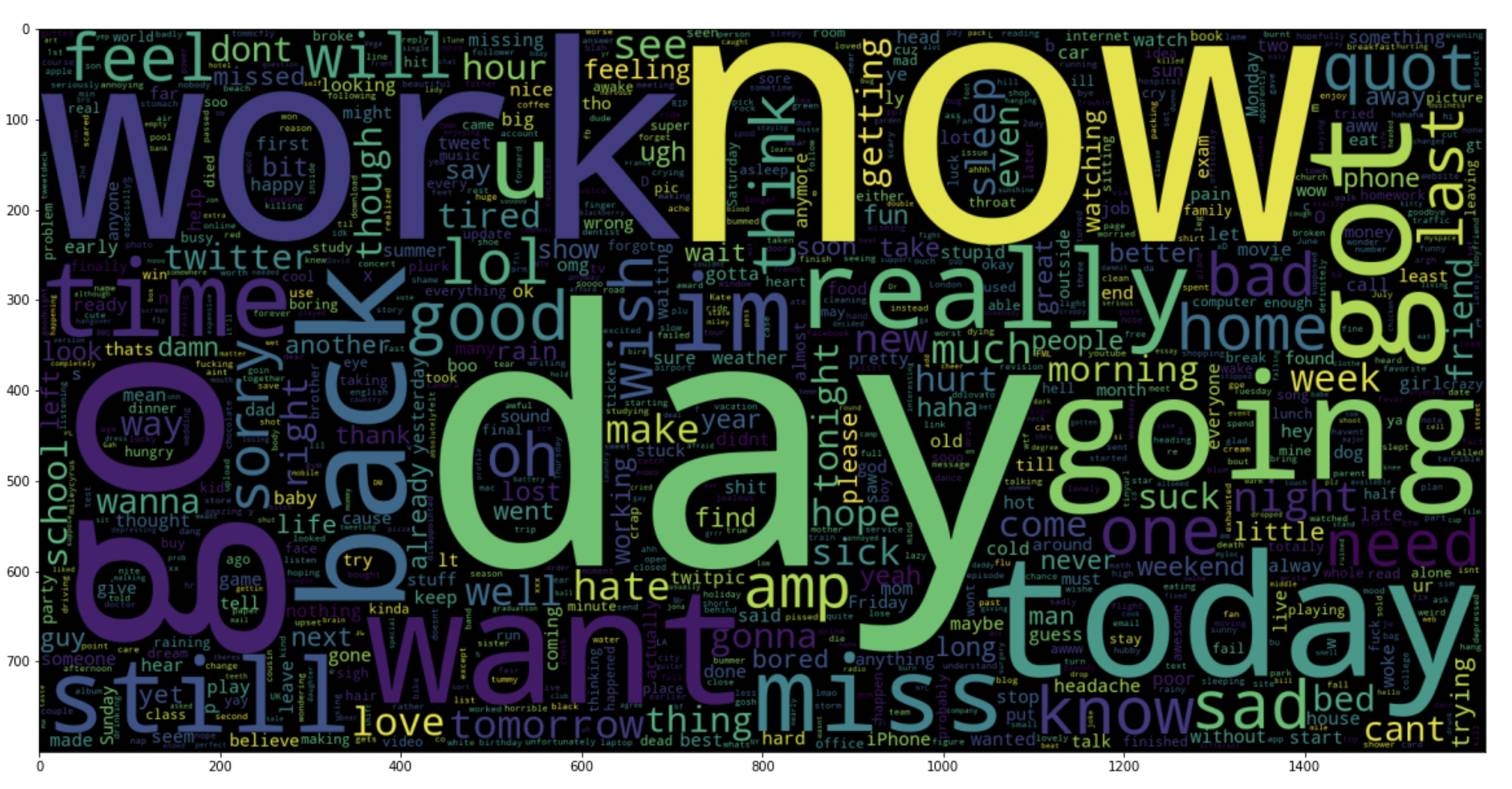
5.19: tracer un nuage de mots pour les tweets positifs
data_pos = données['texte'][800000:]
wc = WordCloud(max_mots = 1000 , largeur = 1600 , hauteur = 800,
collocations=Faux).produire(" ".rejoindre(pos_données))
plt.figure(taille de la figue = (20,20))
plt.imshow(toilettes)
Production:
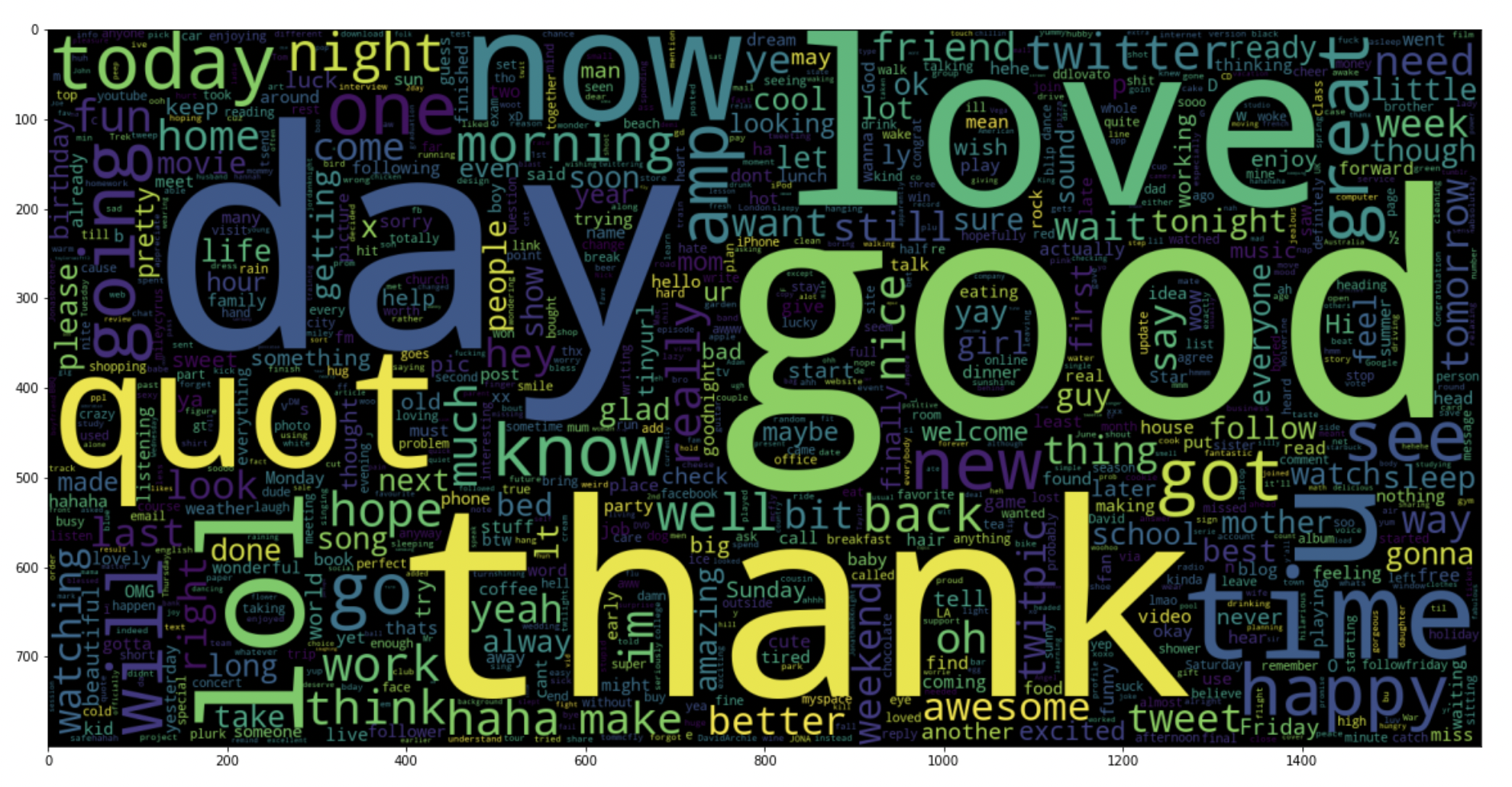
Paso 6: Diviser nos données en sous-ensembles d'entraînement et de test
# Séparer le 95% données pour les données d'entraînement et 5% pour tester les données X_train, X_test, y_train, y_test = train_test_split(X,Oui,taille_test = 0.05, état_aléatoire =26105111)
Paso 7: Transformer l'ensemble de données à l'aide de TF-IDF Vectorizer
7.1: Installer le Vectoriseur TF-IDF
vectoriser = TfidfVectorizer(ngram_range=(1,2), max_caractéristiques=500000)
vectoriser.fit(X_train)
imprimer('Non. de feature_words: ', longueur(vectoriser.get_feature_names()))
Production:
Non. de feature_words: 500000
7.2: Transformez les données à l'aide de TF-IDF Vectorizer
X_train = vectoriser.transformer(X_train) X_test = vectoriser.transform(X_test)
Paso 8: Fonction d'évaluation du modèle
Après avoir formé le modèle, nous appliquons les mesures d'évaluation pour vérifier les performances du modèle. En conséquence, Nous utilisons les paramètres d'évaluation suivants pour vérifier les performances des modèles respectivement:
- Note de précision
- Matrice de confusion d'éclosion
- Curva ROC-AUC
def model_Evaluate(maquette):
# Prédire les valeurs pour l'ensemble de données de test
y_pred = model.predict(X_test)
# Imprimer les métriques d'évaluation pour l'ensemble de données.
imprimer(classement_rapport(y_test, y_pred))
# Calculer et tracer la matrice de confusion
cf_matrix = confusion_matrice(y_test, y_pred)
catégories = ['Négatif','Positif']
nom_groupe = ['Vrai Nég','Fausse position', 'Faux Nég','Vrai Pos']
group_percentages = ['{0:.2%}'.format(valeur) pour la valeur dans cf_matrix.flatten() / np.sum(cf_matrice)]
étiquettes = [F'{v1}m{v2}' pour v1, v2 en zip(nom_groupe,group_percentages)]
étiquettes = np.asarray(Étiquettes).remodeler(2,2)
sns.heatmap(cf_matrice, annot = étiquettes, cmap = 'Bleu',fmt="",
xticklabels = catégories, yticklabels = catégories)
plt.xlabel("Valeurs prédites", fontdict = {'Taille':14}, chemin de l'étiquette = 10)
plt.ylabel("Valeurs réelles" , fontdict = {'Taille':14}, chemin de l'étiquette = 10)
plt.titre ("Matrice de confusion", fontdict = {'Taille':18}, tampon = 20)
Paso 9: Construction de maquettes
Dans l'énoncé du problème, nous avons utilisé respectivement trois modèles différents:
- Bernoulli ingenuo Bayes
- SVM (machine à vecteur de soutien)
- Régression logistique
L'idée derrière le choix de ces modèles est que nous voulons tester tous les classificateurs de l'ensemble de données, des modèles simples aux modèles complexes, puis essayez de trouver celui qui offre les meilleures performances parmi eux.
8.1: Modèle 1
Modèle BNB = BernoulliNB() BNBmodel.fit(X_train, y_train) model_Evaluate(Modèle BNB) y_pred1 = BNBmodel.predict(X_test)
Production:
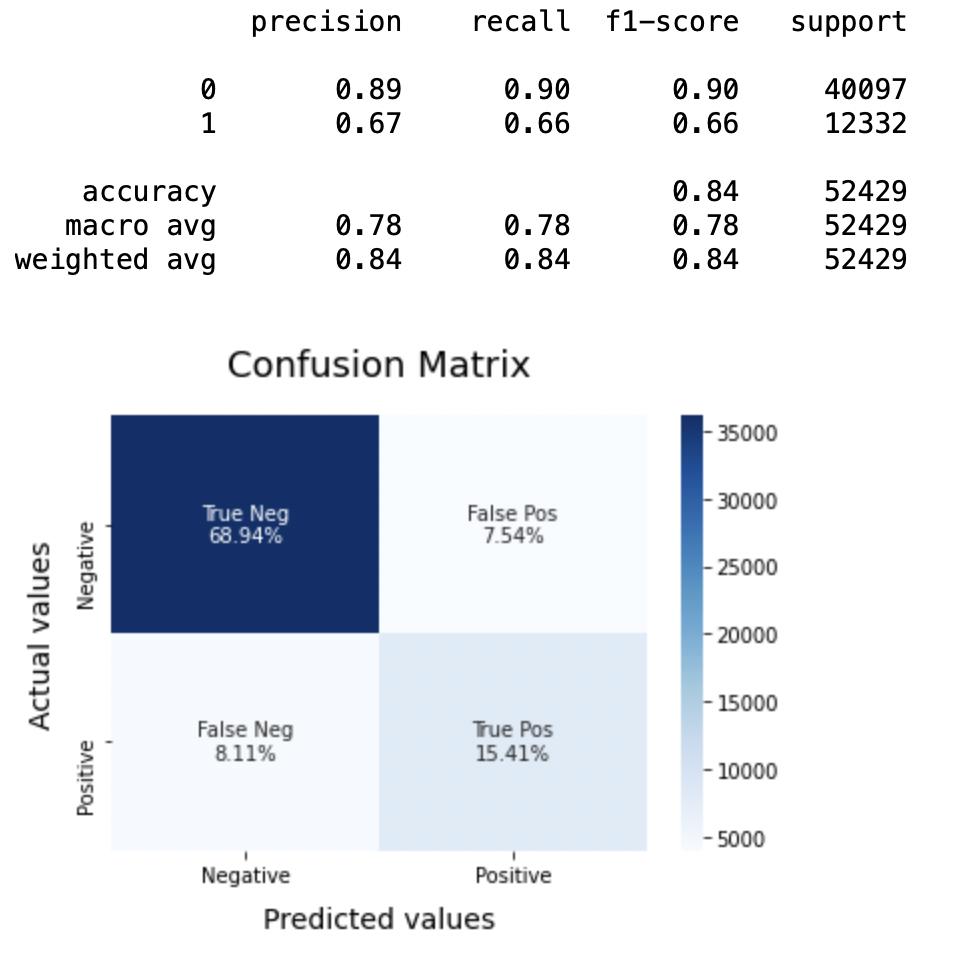
8.2: Tracer la courbe ROC-AUC pour le modèle 1
à partir de sklearn.metrics importer roc_curve, auc
fpr, tpr, seuils = roc_curve(y_test, y_pred1)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, couleur="Orange sombre", lw=1, étiquette="courbe ROC (zone = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel(« Taux de faux positifs »)
plt.ylabel(« Taux Vraiment Positif »)
plt.titre('COURBE ROC')
plt.légende(loc ="en bas à droite")
plt.show()
Production:
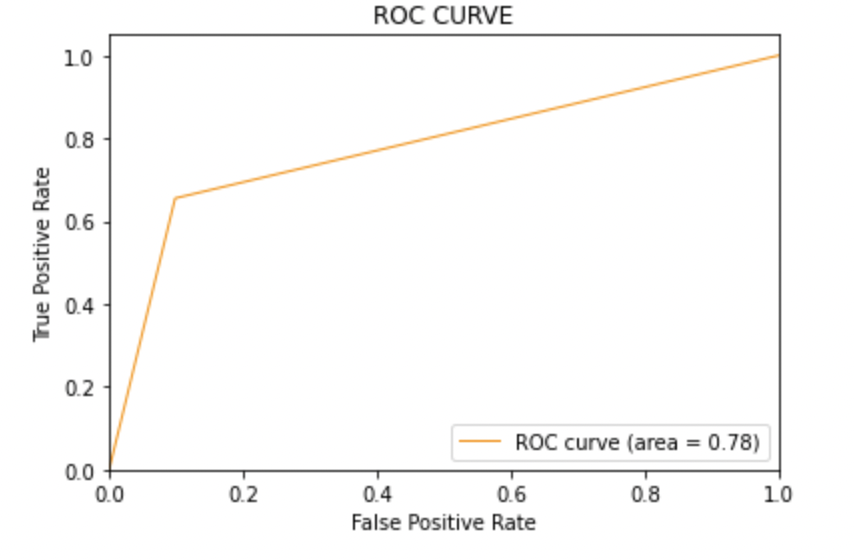
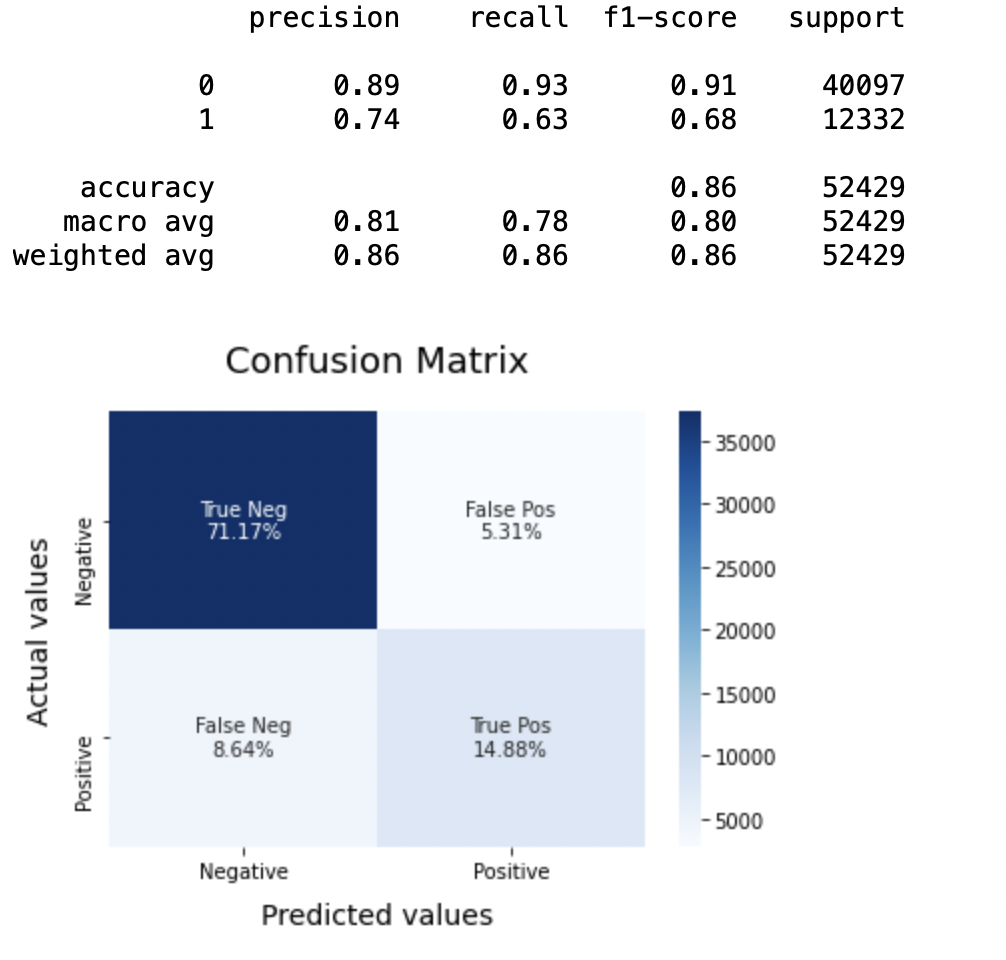
8.3: Modèle-2:
Modèle SVC = LinéaireSVC() SVCmodel.fit(X_train, y_train) model_Evaluate(Modèle SVC) y_pred2 = SVCmodel.predict(X_test)
Production:
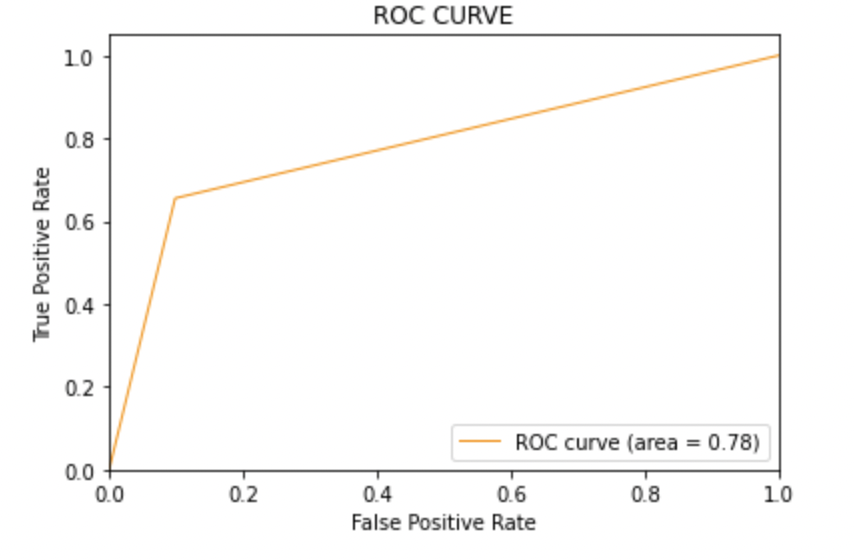
8.4: Tracer la courbe ROC-AUC pour le modèle 2
à partir de sklearn.metrics importer roc_curve, auc
fpr, tpr, seuils = roc_curve(y_test, y_pred2)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, couleur="Orange sombre", lw=1, étiquette="courbe ROC (zone = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel(« Taux de faux positifs »)
plt.ylabel(« Taux Vraiment Positif »)
plt.titre('COURBE ROC')
plt.légende(loc ="en bas à droite")
plt.show()
Production:
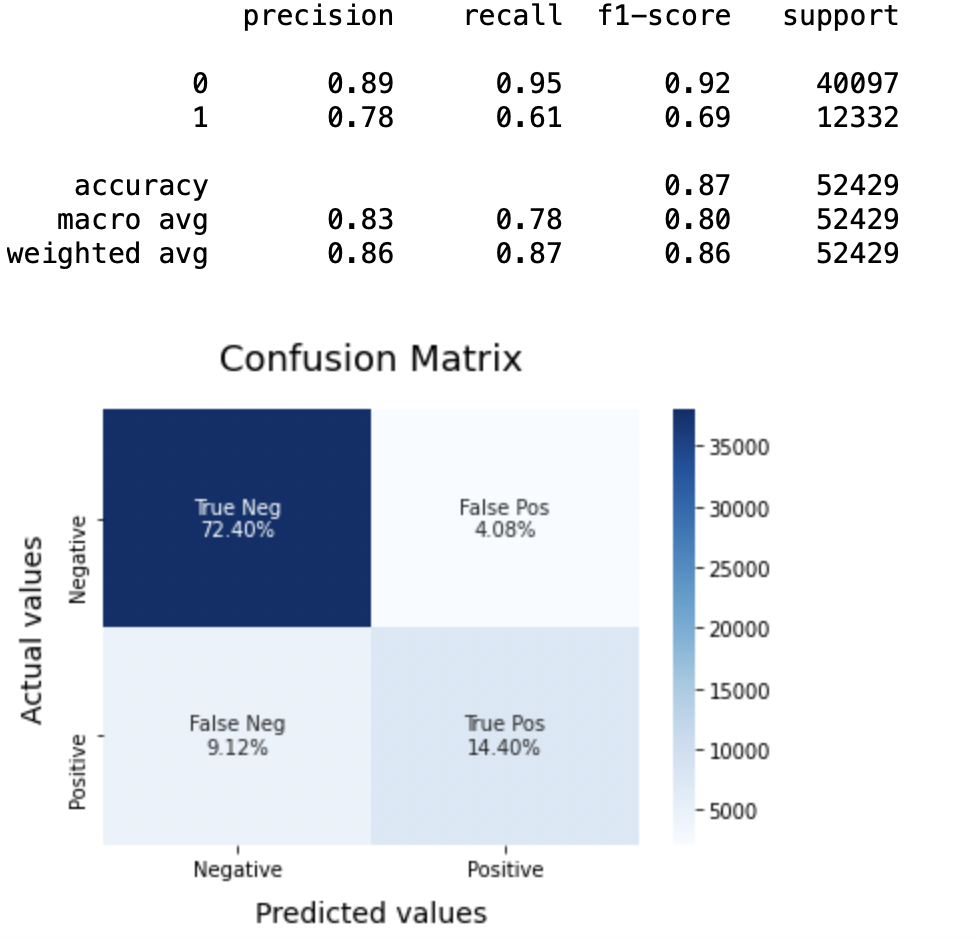
8.5: Modèle-3
LRmodel = LogisticRegression(C = 2, max_iter = 1000, n_emplois=-1) LRmodel.fit(X_train, y_train) model_Evaluate(LRmodèle) y_pred3 = LRmodel.predict(X_test)
Production:
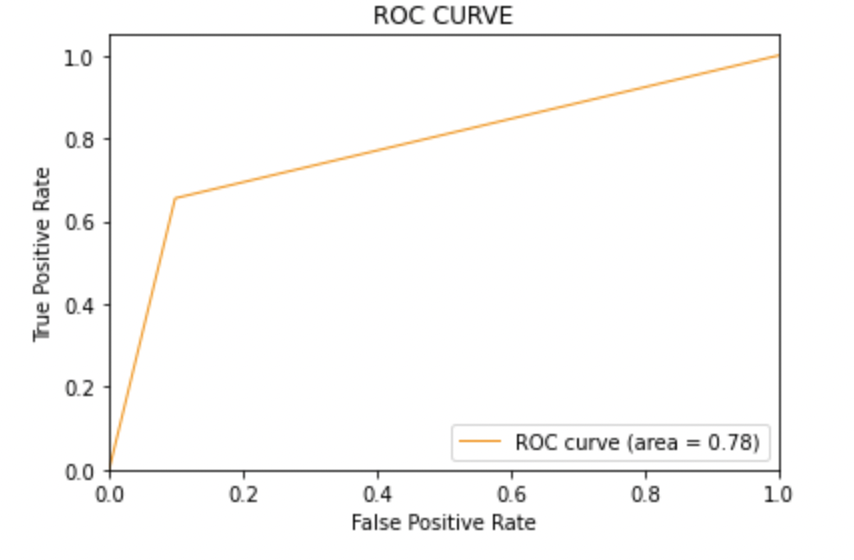
8.6: Tracer la courbe ROC-AUC pour le modèle 3
à partir de sklearn.metrics importer roc_curve, auc
fpr, tpr, seuils = roc_curve(y_test, y_pred3)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, couleur="Orange sombre", lw=1, étiquette="courbe ROC (zone = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel(« Taux de faux positifs »)
plt.ylabel(« Taux Vraiment Positif »)
plt.titre('COURBE ROC')
plt.légende(loc ="en bas à droite")
plt.show()
Production:
Paso 10: conclusion
Lors de l'évaluation de tous les modèles, nous pouvons conclure les détails suivants, c'est-à-dire,
Précision: Concernant la précision du modèle, la régression logistique fonctionne mieux que SVM, qui à son tour fonctionne mieux que Bernoulli Naive Bayes.
Score F1: F1 scores pour la classe 0 et la classe 1 fils:
(une) Pour la classe 0: Bernoulli Naïf Bayes (précision = 0,90) <SVM (précision = 0,91) <Régression logistique (précision = 0,92)
(b) Pour la classe 1: Bernoulli Naïf Bayes (précision = 0,66) <SVM (précision = 0,68) <Régression logistique (précision = 0,69)
Score ASC: Les trois modèles ont le même score ROC-AUC.
Donc, nous concluons que la régression logistique est le meilleur modèle pour l'ensemble de données ci-dessus.
Dans notre énoncé du problème, Régression logistique suit le principe de Le rasoir d'Occam qui définit que pour un énoncé de problème particulier, si les données n'ont pas d'hypothèses, donc le modèle le plus simple fonctionne le mieux. Étant donné que notre ensemble de données n'a pas d'hypothèses et que la régression logistique est un modèle simple, le concept est valable pour l'ensemble de données mentionné ci-dessus.
Remarques finales
J'espère que vous avez apprécié l'article.
Si tu veux te connecter avec moi, Ne doutez pas de rester en contact avec moi. sur Courrier électronique
Vos suggestions et doutes sont les bienvenus ici dans la section commentaires. Merci d'avoir lu mon article!
Les supports présentés dans cet article ne sont pas la propriété d'Analytics Vidhya et sont utilisés à la discrétion de l'auteur..





