Cet article a été publié dans le cadre du Blogathon sur la science des données
a été une plate-forme permettant aux clients de donner leur avis aux entreprises en fonction de leur satisfaction. Les avis des clients sont la source de confiance mondiale de contenu authentique pour les autres utilisateurs. Les commentaires des clients servent d'outil de validation tiers pour renforcer la confiance dans la marque de l'utilisateur.. Pour comprendre ces retours clients sur une entité, l'analyse des sentiments devient un outil d'augmentation pour toute organisation.
L'analyse des sentiments consiste à examiner les conversations en ligne telles que les tweets, des articles de blog ou des commentaires sur des services ou des sujets particuliers et séparer les opinions des utilisateurs (positif, négatif et neutre), permettre aux entreprises d'identifier le sentiment des clients envers les produits. Aide les entreprises à savoir comment sont réellement les clients « ils ressentent » sur votre marque et traiter de grandes quantités de données de manière efficace et rentable. En analysant automatiquement les retours clients, des réponses aux sondages aux conversations sur les réseaux sociaux, les marques peuvent écouter attentivement leurs clients et adapter leurs produits et services à leurs besoins.
L'analyse des sentiments peut être classée comme détaillée, détection d'émotion, analyse des sentiments basée sur les aspects et analyse des intentions. Une analyse détaillée des sentiments traite de la polarité de l'interprétation dans l'examen, tandis que la détection des émotions implique l'expression émotionnelle de l'utilisateur à propos d'un produit.
L'analyse des sentiments basée sur les aspects est une variété d'analyses des sentiments qui aide à l'amélioration de l'entreprise en connaissant les caractéristiques de votre produit qui doivent être améliorées en fonction des commentaires des clients pour faire de votre produit un best-seller.. ABSA identifie les aspects de l'examen donné sur un produit et trouve également si l'aspect mentionné dans l'examen appartient à quel type de sentiment.
Dans cet article, nous effectuerons l'ABSA à l'aide de l'ensemble de données des ordinateurs portables et des restaurants de SemEval 2014, ainsi que dans des ensembles de données multilingues tels que l'ensemble de données hindi sur des produits tels que les ordinateurs portables, Téléphone (s, restaurants et hôtels.
Prétraitement des données
Tokenisation: La tokenisation est la division du paragraphe de texte en morceaux plus petits, comme phrases (tokenisation de la phrase) ou des mots (tokenisation des mots). Le principal inconvénient de la tokenisation des mots est les mots sans vocabulaire (OOV), pour éviter les OOV et également pour extraire des informations de la tokenisation de la phrase de texte utilisée dans cette analyse.
Supprimer les mots vides: Après la tokenisation, les mots vides sont identifiés et supprimés des tweets. Les mots vides sont les mots les plus courants dans une langue qui peuvent ne pas ajouter beaucoup d'informations à la phrase ou au document. Ces mots sont filtrés pour minimiser le bruit et améliorer la qualité des données textuelles pour une meilleure classification.. La bibliothèque NLP contient une collection de mots vides pour chaque langue du texte en NLTK. Les mots du texte sont comparés à cette liste de mots vides, les mots de correspondance sont supprimés pour améliorer la qualité des données et également pour extraire facilement les mots de sentiment des tweets.
Supprimer la ponctuation et le caractère: Après expansion des contractions, les caractères spéciaux et les ponctuations sont supprimés par la fonction regex. La principale raison pour cela est que la ponctuation ou les caractères spéciaux ne sont souvent pas très importants lors de l'analyse du texte et qu'ils l'utilisent pour extraire des caractéristiques ou des informations basées sur la PNL et le ML..
Remplacement de négation par des antonymes: Le remplacement des mots négatifs par des antonymes diminue la dimensionnalité du nombre de mots de la matrice du document, il est donc avantageux de compresser le vocabulaire sans perdre son sens pour économiser de la mémoire.
de nltk.corpus importer wordnet
classe AntonyReplacer(objet):
remplacer par défaut(soi, mot, pos=Aucun):
antonymes = ensemble()
pour syn dans wordnet.synsets(mot, position = position):
pour lemme dans syn.lemmas():
pour antonyme dans lemma.antonyms():
antonymes.ajouter(nom.antonyme())
si len(antonymes) == 1:
retour antonyms.pop()
autre:
retour Aucun
def replace_negations(soi, envoyé):
je, l = 0, longueur(envoyé)
mots = []
alors que je < je:
mot = envoyé[je]
si mot == 'pas' et i+1 < je:
fourmi = auto.remplacer(envoyé[i+1])
si fourmi:
mots.append(fourmi)
je += 2
Continuez
mots.append(mot)
je += 1
mots de retour
Correction orthographique: Les mots comportant plusieurs caractères répétés et une orthographe incorrecte dus à des fautes de frappe humaines doivent être supprimés, car ils n'ont pas d'importance en général. Par exemple, des mots comme finalement, exactement, etc. sont des entrées incorrectes, cependant, doit être corrigé pour une utilisation ultérieure.
Lématisation: La lematización es la técnica de preprocesamiento de texto más común utilizada para la standardisationLa normalisation est un processus fondamental dans diverses disciplines, qui vise à établir des normes et des critères uniformes afin d’améliorer la qualité et l’efficacité. Dans des contextes tels que l’ingénierie, Formation et administration, La standardisation facilite la comparaison, Interopérabilité et compréhension mutuelle. Lors de la mise en œuvre des normes, La cohésion est favorisée et les ressources sont optimisées, qui contribue au développement durable et à l’amélioration continue des processus.... de palabras. La lemmatisation d'un mot convertit le mot en sa forme significative de base en observant l'analyse morphologique de chaque mot. La tige est également similaire à la tige, mais le premier ne prend pas en compte le contexte du mot dans la phrase et ne supprime que le suffixe dans les mots.
nltk.télécharger('wordnet')
à partir de nltk.stem importer WordNetLemmatizer
lemmatiseur=WordNetLemmatiseur()
antreplacer = AntonyMplacer()
def clean_text(texte):
#Lemmatiser les textes
# suppression des mots aphostrophes
texte = texte.inférieur() si pd.notnull(texte) autre texte
texte = re.sub(r"c'est quoi", "quel est ",str(texte))
texte = re.sub(r"'s", " ", str(texte))
texte = re.sub(r"'et", " ont ", str(texte))
texte = re.sub(r"ne peut pas", "ne peut pas ", str(texte))
texte = re.sub(je ne suis pas, 'n'est pas', str(texte))
texte = re.sub(je ne veux pas, 'Ne fera pas', str(texte))
texte = re.sub(r"NT", " ne pas ", str(texte))
texte = re.sub(r"je suis", "Je suis ", str(texte))
texte = re.sub(r"'ré", " sommes ", str(texte))
texte = re.sub(r"'ré", " aurait ", str(texte))
texte = re.sub(r"'ll", " volonté ", str(texte))
texte = re.sub(r"'excuses", " excuse ", str(texte))
texte = re.sub('W', ' ', str(texte))
texte = re.sub('s+', ' ', str(texte))
# Supprimer les signes de ponctuation et les chiffres
texte = re.sub('[^ a-zA-Z]', ' ', str(texte))
# Suppression d'un seul caractère
texte = re.sub(r"s+[a-zA-Z]s+", ' ', str(texte))
text=lemmatizer.lemmatize(texte)
# remplacer les mots de négation par des antonymes
text=antreplacer.replace(texte)
# Suppression de plusieurs espaces
texte = re.sub(r's+', ' ', str(texte))
texte = texte.strip(' ')
texte de retour
Modèles de classificateurs

La saisie est la méthode de représentation des mots de la phrase sous forme de vecteurs. La technique d'enrobage que nous utiliserons sera l'enrobage GloVe, construction de matrices de cooccurrence de mots. Les phrases en anglais sont entraînées avec des incrustations GloVe pré-entraînées et les incrustations pour les phrases en hindi sont entraînées sur mesure avec des données de corpus en hindi de 13 M.
def get_word2vec_embedding_matrix(maquette):
matrice_d'intégration = np.zeros((vocab_size,300))
pour mot, je dans tokenizer.word_index.items():
essayer:
embedding_vector = modèle[mot]
sauf KeyError:
embedding_vector = Aucun
si embedding_vector n'est pas Aucun:
matrice_d'intégration[je]= vecteur_embedding
retourner embedding_matrix
Après la conversion des mots en vecteurs avec GloVe Embedding, des modèles bidirectionnels LSTM et CNN sont appliqués sur la couche de saisie pour former et prédire les termes d'aspect et les termes de sentiment, respectivement. Les 1000 Les termes d'aspect les plus couramment utilisés sont identifiés dans l'ensemble de données et le modèle Bi-LSTM est entraîné et classé parmi ces classes d'aspect. Les termes d'aspect prédits sont étiquetés BIO. Le sentiment du terme d'aspect trouvé est prédit à l'aide du modèle CNN pour classer l'avis comme positif, négatif et neutre.
embed_dim = 128 lstm_out = 196 modèle = Séquentiel() model.ajouter(Intégration(10000, embed_dim,longueur_entrée = 28)) model.ajouter(Bidirectionnel(LSTM(lstm_out,return_sequences=Vrai))) model.ajouter(LSTM(lstm_out, abandon=0.2, recurrent_dropout=0.2)) model.ajouter(attention()) model.ajouter(Aplatir()) model.ajouter(Abandonner(0.3)) model.ajouter(Dense(1000, activation='softmax')) modèle.compile(perte ="catégorique_crossentropie", optimiseur="Adam", métriques=['précision']) modèle.résumé()

history_object = model.fit(trainX, trainY, époques=5, taille_lot=8)
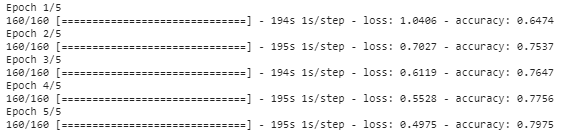
résumé
Dans cet article, nous avons appliqué diverses techniques de prétraitement aux révisions de texte et les mots sont convertis en représentations vectorielles à l'aide de l'intégration GloVe. La couche intégrée est ajoutée avec la couche LSTM bidirectionnelle pour trouver les termes d'aspect dans la phrase et l'attention de Bahdanau est appliquée pour trouver l'association entre la cible et les mots de contexte. Trouvez la polarité des sentiments pour chaque terme d'aspect trouvé dans le modèle ci-dessus et prédit à l'aide du modèle CNN pour classer le terme d'aspect comme positif., négatif ou neutre. Les termes d'aspect qui sont prédits à partir de la phrase sont marqués avec le marquage BIO, a savoir, Début, intermédiaire ou en dehors du terme d'aspect.
Le code complet de ce mini-projet est disponible ici.
Remarques finales
J'espère que vous avez apprécié la lecture de cet article.
Bon apprentissage!!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





