Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Python est un langage polyvalent. Utilisé à des fins générales de programmation et de développement, et aussi pour des tâches complexes comme l'apprentissage automatique, science des données et analyse de données. Non seulement il est facile d'apprendre, il a aussi de merveilleuses bibliothèques, ce qui en fait le langage de programmation de premier choix pour de nombreuses personnes.
Dans cet article, nous verrons un de ces cas d'utilisation Python. Nous utiliserons Python pour analyser les performances du joueur de cricket indien MS Dhoni dans votre carrière One Day International (ODI).

Base de données
Si vous connaissez le concept de web scraping, vous pouvez en extraire les données Lien ESPN Cricinfo. Si vous ne connaissez pas le web scraping, ne t'en fais pas! Vous pouvez télécharger les données directement depuis ici. Les données sont disponibles sous forme de fichier Excel à télécharger.
Une fois que vous avez le jeu de données avec vous, vous devrez le charger en Python. Vous pouvez utiliser l'extrait de code ci-dessous pour charger l'ensemble de données en Python:
# importer des bibliothèques et des packages essentiels
importer des pandas au format pd
importer numpy en tant que np
date/heure d'importation
importer matplotlib.pyplot en tant que plt
importer seaborn comme sns
# lecture de l'ensemble de données
df = pd.read_excel('MS_Dhoni_ODI_record.xlsx')
Une fois le jeu de données lu, nous devons regarder le début et la fin de l'ensemble de données pour s'assurer qu'il est importé correctement. L'en-tête de l'ensemble de données devrait ressembler à ceci:
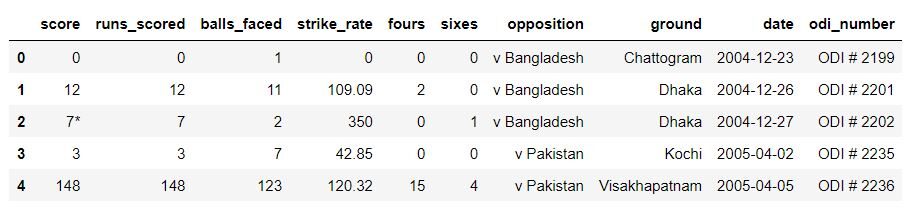
Si les données se chargent correctement, nous pouvons passer à l'étape suivante, nettoyage et préparation des données.
Nettoyage et préparation des données
Ces données ont été extraites d'une page Web, donc ils ne sont pas très propres. Nous commencerons par supprimer le premier 2 caractères de la chaîne d'opposition car ce n'est pas nécessaire.
# enlever le premier 2 caractères dans la chaîne d'opposition df['opposition'] = df['opposition'].appliquer(lambda x: X[2:])
Ensuite, nous allons créer une colonne pour l'année où le jeu a été joué. Assurez-vous que la colonne de date est présente au format DateTime dans votre DataFrame. Au contraire, utiliser pd.to_datetime () pour le convertir au format DateTime.
# créer une fonctionnalité pour l'année de match df['année'] = df['Date'].dt.année.astype(entier)
Nous allons également créer une colonne qui indique si Dhoni n'était pas dans cette entrée ou non.
# créer une fonctionnalité pour ne pas être sorti
df['But'] = df['But'].appliquer(str)
df['not_out'] = np.où(df['But'].str.se termine avec('*'), 1, 0)
Maintenant, nous allons supprimer la colonne du numéro ODI car ce n'est pas nécessaire.
# suppression de la fonctionnalité odi_number car elle n'ajoute aucune valeur à l'analyse df.drop(colonnes="numéro_odi", inplace=Vrai)
Nous supprimerons également toutes les correspondances de nos enregistrements où Dhoni n'a pas touché et stockerons ces informations dans un nouveau DataFrame.
# laisser tomber ces manches où Dhoni n'a pas battu et stocker dans un nouveau DataFrame df_nouveau = df.loc[((df['But'] != 'DNB') & (df['But'] != 'TDNB')), 'runs_scored':]
Finalement, nous allons corriger les types de données de toutes les colonnes présentes dans notre nouveau DataFrame.
# fixation des types de données des colonnes numériques df_nouveau['runs_scored'] = df_nouveau['runs_scored'].astype(entier) df_nouveau['balles_faced'] = df_nouveau['balles_faced'].astype(entier) df_nouveau['strike_rate'] = df_nouveau['strike_rate'].astype(flotter) df_nouveau["à quatre pattes"] = df_nouveau["à quatre pattes"].astype(entier) df_nouveau['six'] = df_nouveau['six'].astype(entier)
Statistiques de course
Nous allons jeter un oeil à la statistiques descriptives de la carrière ODI de MS Dhoni. Vous pouvez utiliser le code suivant pour cela:
first_match_date = df['Date'].dt.date.min().strftime('%B %d, %ET') # premier match
imprimer('Premier match:', first_match_date)
last_match_date = df['Date'].dt.date.max().strftime('%B %d, %ET') # dernier match
imprimer('nDernière correspondance:', last_match_date)
nombre_de_matches = df.shape[0] # nombre de maths jouées en carrière
imprimer('nNombre de matchs joués:', nombre_de_correspondances)
number_of_inns = df_new.shape[0] # nombre de manches
imprimer('nNombre de manches jouées:', nombre_d'auberges)
not_outs = df_new['not_out'].somme() # nombre de non-sorties en carrière
imprimer('nNot outs:', not_outs)
runs_scored = df_new['runs_scored'].somme() # points marqués en carrière
imprimer('nRuns marqué en carrière:', runs_scored)
balls_faced = df_new['balles_faced'].somme() # balles affrontées en carrière
imprimer('nBalls face en carrière:', boules_faced)
carrière_sr = (runs_scored / boules_faced)*100 # taux de grève de carrière
imprimer(Taux de grève 'nCareer: {:.2F}'.format(carrière_sr))
carrière_moy = (runs_scored / (nombre_d'auberges - not_outs)) # moyenne de carrière
imprimer('nCarrière moyenne: {:.2F}'.format(carrière_moyenne))
plus_score_date = df_new.loc[df_new.runs_scored == df_new.runs_scored.max(), 'Date'].valeurs[0]
score_le plus élevé = df.loc[df.date == plus haut_score_date, 'But'].valeurs[0] # le score le plus élevé
imprimer('nMeilleur score en carrière:', le score le plus élevé)
centaines = df_new.loc[df_nouveau['runs_scored'] >= 100].forme[0] # nombre de 100
imprimer('nNombre de 100:', des centaines)
années cinquante = df_new.loc[(df_nouveau['runs_scored']>=50)&(df_nouveau['runs_scored']<100)].forme[0] #nombre de 50
imprimer('nNombre de 50:', la cinquantaine)
fours = df_new["à quatre pattes"].somme() # nombre de quatre en carrière
imprimer('nNombre de 4s:', à quatre pattes)
six = df_new['six'].somme() # nombre de six en carrière
imprimer('nNombre de 6s:', six)
La sortie devrait ressembler à ceci:
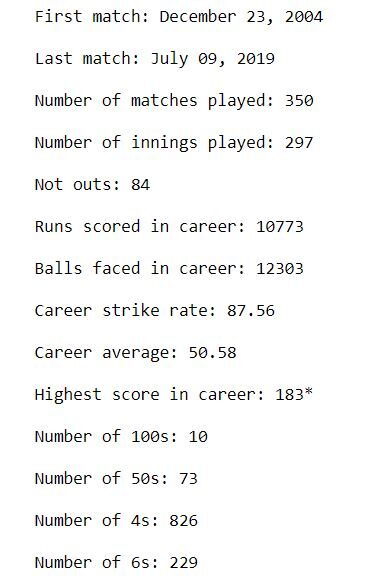
Cela nous donne une bonne idée de la carrière globale de MS Dhoni. J'ai commencé à jouer dans 2004, et joué pour la dernière fois un ODI dans 2019. Dans une carrière de plus de 15 ans, a marqué 10 cents et une quantité stupéfiante de 73 cinquante. A marqué plus de 10,000 carrières dans sa carrière avec une moyenne de 50.6 et un taux de grève de 87.6. Votre score le plus élevé est 183 *.
Nous allons maintenant faire une analyse plus exhaustive de leurs performances contre différentes équipes. On verra aussi leurs performances année après année. Nous allons prendre l'aide de visualisations pour cela.
Une analyse
En premier lieu, on verra combien jeux que vous avez joués contre différentes oppositions. Vous pouvez utiliser le code suivant à cette fin:
# nombre de matchs joués contre différentes oppositions df['opposition'].value_counts().terrain(genre='bar', titre="Nombre de matchs contre différentes oppositions", taille de la figue=(8, 5));
La sortie devrait ressembler à ceci:
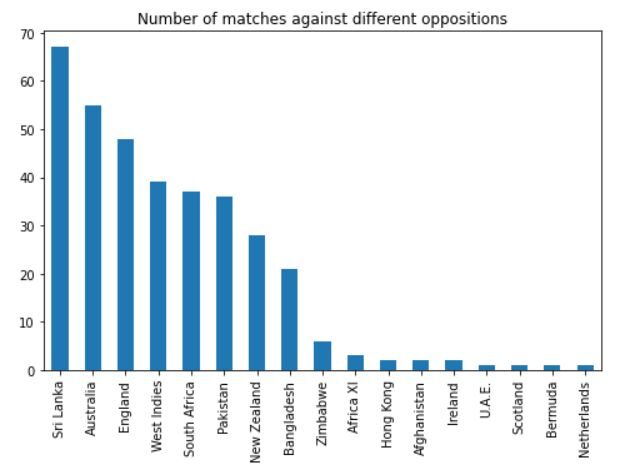
On peut voir qu'il a joué la plupart de ses matchs contre le Sri Lanka, Australie, Angleterre, Antilles, Afrique du Sud et Pakistan.
Voyons combien carrières que vous avez marqué contre différentes oppositions. Vous pouvez utiliser l'extrait de code suivant pour générer le résultat:
runs_scored_by_opposition = pd.DataFrame(df_nouveau.groupby('opposition')['runs_scored'].somme())
runs_scored_by_opposition.plot(genre='bar', titre="Points marqués contre différentes oppositions", taille de la figue=(8, 5))
plt.xlabel(Rien);
La sortie ressemblera à ceci:
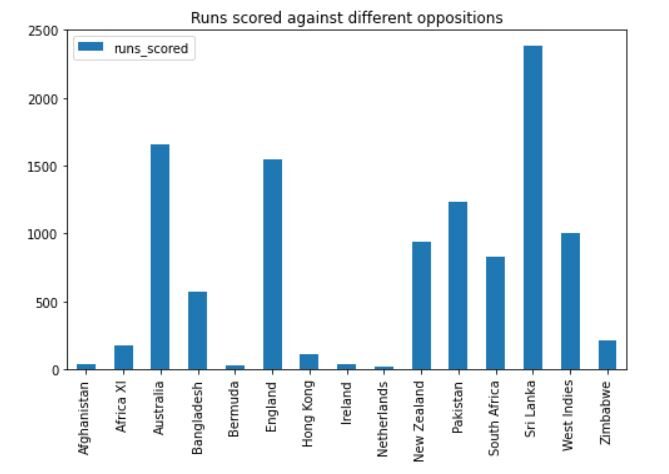
On peut voir que Dhoni a marqué le plus de points contre le Sri Lanka, suivi de l'Australie, Angleterre et Pakistan. Il a également joué de nombreux matchs contre ces équipes, donc c'est logique.
Pour avoir une image plus claire, jetons un coup d'oeil à votre moyenne au bâton contre chaque équipe. L'extrait de code suivant nous aidera à obtenir le résultat souhaité:
innings_by_opposition = pd.DataFrame(df_nouveau.groupby('opposition')['Date'].compter())
not_outs_by_opposition = pd.DataFrame(df_nouveau.groupby('opposition')['not_out'].somme())
temp = runs_scored_by_opposition.merge(innings_by_opposition, left_index=Vrai, right_index=Vrai)
moyenne_par_opposition = temp.merge(not_outs_by_opposition, left_index=Vrai, right_index=Vrai)
moyenne_par_opposition.renommer(colonnes = {'Date': 'manches'}, inplace=Vrai)
moyenne_par_opposition['eff_num_of_inns'] = moyenne_par_opposition['manches'] - moyenne_par_opposition['not_out']
moyenne_par_opposition['moyenne'] = moyenne_par_opposition['runs_scored'] / moyenne_par_opposition['eff_num_of_inns']
moyenne_par_opposition.replace(par exemple inf, np.nan, inplace=Vrai)
major_nations = ['Australie', 'Angleterre', 'Nouvelle-Zélande', 'Pakistan', 'Afrique du Sud', 'Sri Lanka', 'Antilles']
Pour générer le graphique, utilisez l'extrait de code ci-dessous:
plt.figure(taille de la figue = (8, 5))
plt.plot(moyenne_par_opposition.loc[major_nations, 'moyenne'].valeurs, marqueur="O")
plt.plot([carrière_moyenne]*longueur(major_nations), '--')
plt.titre("Moyenne par rapport aux grandes équipes")
plt.xticks(gamme(0, 7), major_nations)
plt.ylim(20, 70)
plt.légende(['Moy contre opposition', « Moyenne de carrière »]);
La sortie ressemblera à ceci:
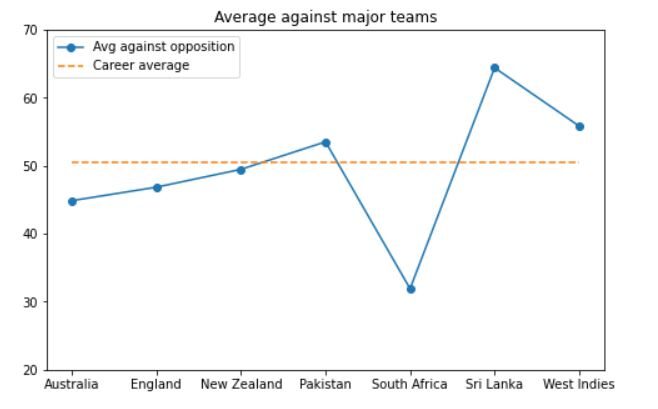
Comme nous pouvons le voir, Dhoni a réalisé des performances remarquables contre des équipes difficiles comme l'Australie, Angleterre et Sri Lanka. Sa moyenne contre ces équipes est proche de sa moyenne en carrière ou légèrement supérieure.. La seule équipe contre laquelle il n'a pas bien performé est l'Afrique du Sud.
Voyons maintenant leurs statistiques d'année en année. On va commencer par chercher combien de jeux avez-vous joué chaque année après ses débuts. Le code pour cela sera:
df['année'].value_counts().index_tri().terrain(genre='bar', titre="Matchs joués par année", taille de la figue=(8, 5)) plt.xticks(rotation=0);
L'intrigue ressemblera à ceci:
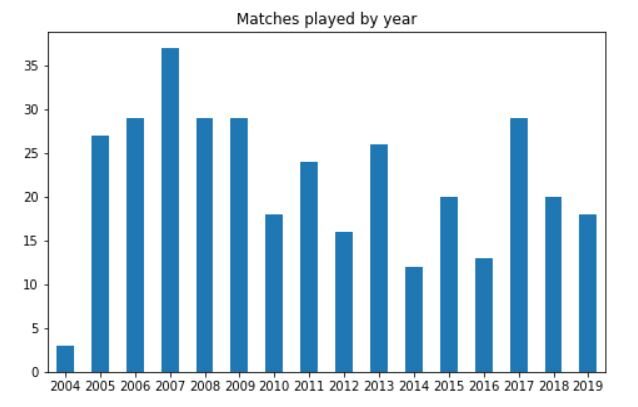
On peut le voir dans 2012, 2014 Oui 2016, Dhoni a joué très peu de matchs ODI pour l'Inde. En général, après que 2005-2009, le nombre moyen de matchs joués a légèrement diminué.
Nous devrions également examiner combien carrières qu'il a marquées chaque année. Le code pour cela sera:
df_nouveau.groupby('année')['runs_scored'].somme().terrain(genre='ligne', marqueur="O", titre="Runs marqués par année", taille de la figue=(8, 5))
années = df['année'].unique().lister()
plt.xticks(années)
plt.xlabel(Rien);
La sortie devrait ressembler à ceci:
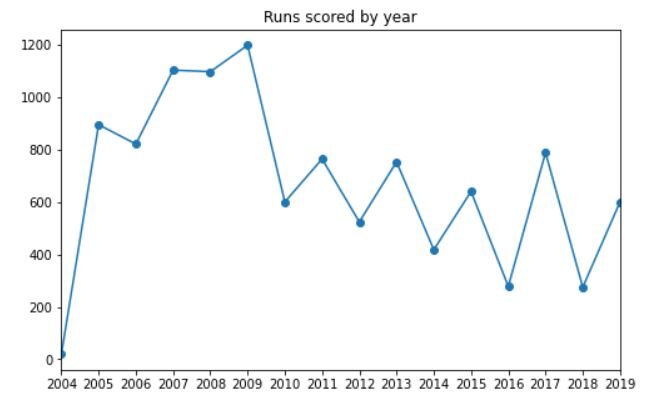
Vous pouvez clairement voir que Dhoni a marqué le plus de courses de l'année 2009, suivi de 2007 Oui 2008. Le nombre de courses a commencé à diminuer après 2010 (parce que le nombre de parties jouées a également commencé à diminuer).
Finalement, voyons son Progression moyenne au bâton en carrière par manche. Ce sont des données de séries chronologiques et ont été tracées dans un diagramme linéaire. Le code pour cela sera:
df_new.reset_index(drop=Vrai, inplace=Vrai) carriere_average = pd.DataFrame() carrière_moyenne['runs_scored_in_career'] = df_nouveau['runs_scored'].cumsum() carrière_moyenne['manches'] = df_new.index.tolist() carrière_moyenne['manches'] = carrière_moyenne['manches'].appliquer(lambda x: x+1) carrière_moyenne['not_outs_in_career'] = df_nouveau['not_out'].cumsum() carrière_moyenne['eff_num_of_inns'] = carrière_moyenne['manches'] - carrière_moyenne['not_outs_in_career'] carrière_moyenne['moyenne'] = carrière_moyenne['runs_scored_in_career'] / carrière_moyenne['eff_num_of_inns']
L'extrait de code pour l'intrigue sera:
plt.figure(taille de la figue = (8, 5)) plt.plot(carrière_moyenne['moyenne']) plt.plot([carrière_moyenne]*carrière_moyenne.shape[0], '--') plt.titre(« Progression moyenne de carrière par manches ») plt.xlabel(« Nombre de manches ») plt.légende(['Progression moyenne', « Moyenne de carrière »]);
Le graphique de sortie ressemblera à ceci:
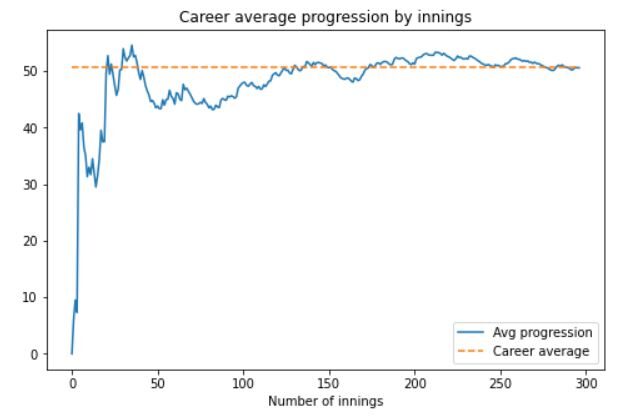
Nous pouvons voir qu'après un démarrage lent et une baisse des performances sur le nombre d'entrée 50, La performance de Dhoni s'est considérablement redressée. Vers la fin de sa carrière, systématiquement en moyenne au-dessus 50.
Note de fin
Dans cet article, nous analysons les performances au bâton du joueur de cricket indien MS Dhoni. Nous regardons les statistiques générales de votre carrière, votre performance contre différents adversaires et votre performance année après année.
Cet article a été écrit par Vishesh Arora. Vous pouvez me joindre à LinkedIn.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





