Cet article a été publié dans le cadre du Blogathon sur la science des données
GitHub est l'une des plateformes de gestion de code source et de contrôle de version les plus populaires. C'est également l'un des plus grands sites de médias sociaux pour les programmeurs. Les développeurs de logiciels l'utilisent pour présenter leurs compétences aux recruteurs et aux responsables du recrutement. Lors de l'analyse des référentiels sur GitHub, nous pouvons obtenir des informations précieuses telles que le comportement des utilisateurs, ce qui rend un référentiel populaire ou quelles technologies sont à la mode parmi les développeurs aujourd'hui, beaucoup plus.
Vous pouvez trouver le code complet utilisé dans l'article ici.
j'ai utilisé Les « Dépôts GitHub 2020’ Ensemble de données Kaggle, car c'est plus récent.
Mise en œuvre
Aller git cela a commencé par importer les bibliothèques nécessaires et lire les données d'entrée,
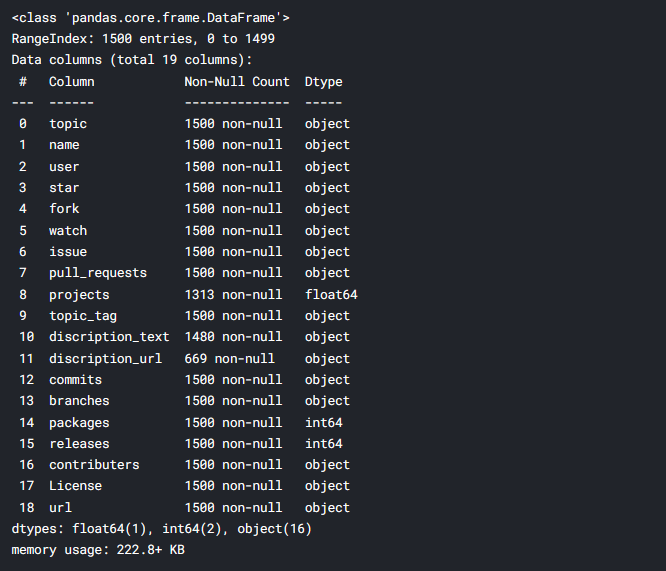
L'ensemble de données contient 19 Colonnes, dont j'ai choisi 11 Colonnes basées sur les terminologies GitHub les plus populaires et celles pertinentes au contexte de cette discussion. Vous pouvez voir qu'il y a des fautes de frappe dans les noms de colonnes, Je les ai renommés pour plus de clarté.
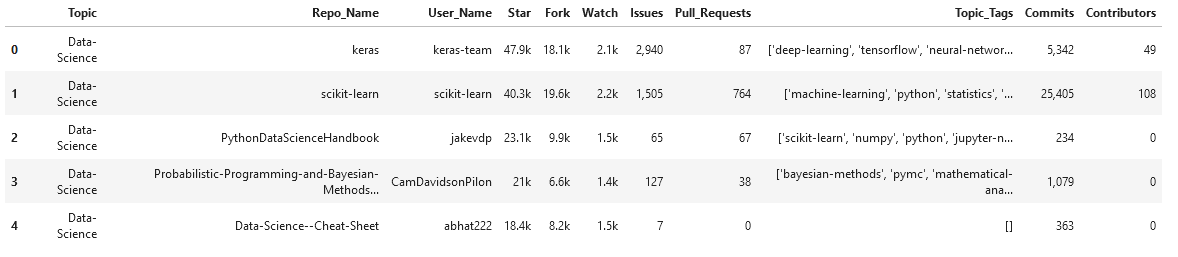
Un bref résumé des colonnes de données,
- Thème – Une balise qui décrit le champ ou le domaine du référentiel.
- Nom_dépôt – Nom du référentiel (nom abrégé du référentiel)
- Nom d'utilisateur – Nom du propriétaire du référentiel
- Etoile – Nombre d'étoiles qu'un référentiel a reçues
- Fourchette – Nombre de fois qu'un référentiel a été fork
- Regarder – Nombre d'utilisateurs consultant le référentiel
- Des questions – Nombre de problèmes ouverts
- Pull_Requests – Nombre total de demandes de tirage générées
- Étiquettes de sujet – Liste des balises de sujet ajoutées à ce référentiel par utilisateur
- Compromis – Nombre total de confirmations effectuées
- Collaborateurs – Nombre de personnes contribuant au référentiel
Trouver comment Etoile, Fourchette, Oui Regarder les colonnes contiennent 'Kansas pour désigner des milliers, convertissons-les donc en multiples de 1000. En outre, remplacer le ',’(virgules) du Des questions Oui Compromis Colonnes.
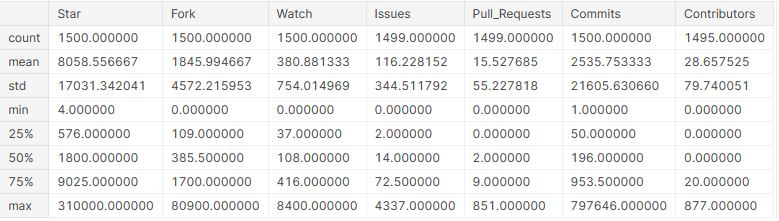
Maintenant que les colonnes sont numériques, nous pouvons obtenir d'eux des informations statistiques de base.
# afficher les détails statistiques de base sur les colonnes github_df.describe()
1. Analyse des principaux référentiels selon leur popularité
Qu'est-ce qui rend un dépôt GitHub populaire? On peut répondre à cette question avec 3 métrique: Etoile, horloge et fourchette.
- Etoile: lorsqu'un utilisateur aime votre référentiel ou veut montrer une certaine appréciation, le marque d'une étoile.
- Regarder: lorsqu'un utilisateur souhaite être informé de toutes les activités dans un référentiel, le voit.
- Fourchette: lorsqu'un utilisateur veut une copie du référentiel ou a l'intention d'apporter une contribution, la fourchette.
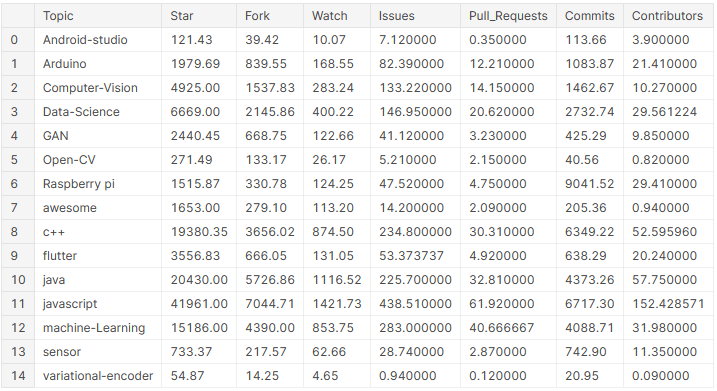
# créer une base de données avec les valeurs moyennes des colonnes sur tous les sujets
pop_mean_df = github_df.groupby('Sujet').moyenne().reset_index()
pop_mean_df
1.1 Analyse des étoiles
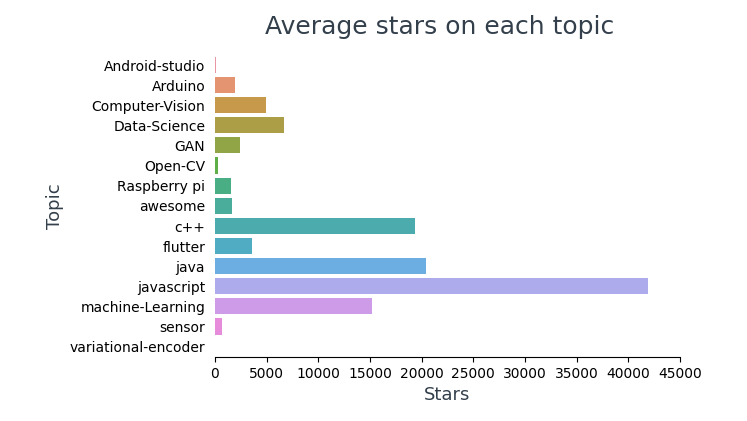
Afficher le nombre moyen d'étoiles dans chaque sujet,
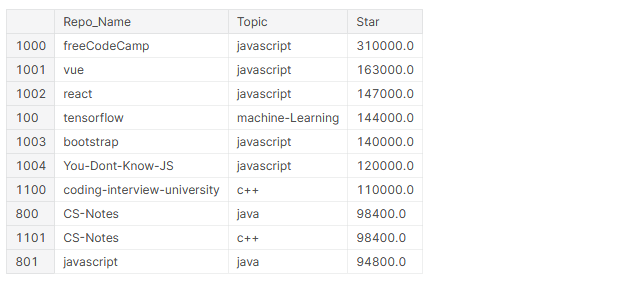
# Haut 10 repos les plus suivis github_df.nlargest(n=10, colonnes="Star")[['Nom_dépôt','Sujet','Star']]
# Conseil rapide: '33[1m' imprime une chaîne en gras et '33[0je l'imprime normalement.
imprimer('Le référentiel le plus suivi est {}{}{} dans le sujet {}{}{} avec {}{}{} étoiles'.
format('33[1je suis,github_df.iloc[github_df['Star'].idxmax ()]['Nom_dépôt'], '33[0je suis,
'33[1je suis,github_df.iloc[github_df['Star'].idxmax ()]['Sujet'], '33[0je suis,
'33[1je suis,github_df.iloc[github_df['Star'].idxmax ()]['Star'], '33[0je suis))

Au sommet 10 les référentiels les plus suivis, 4 sont des cadres (Vue, Réagir, TensorFlow, Amorcer) et 6 d'entre eux concernent JavaScript.
1.2 Analyse de veille
Visualiser le nombre moyen d'observateurs sur chaque sujet,
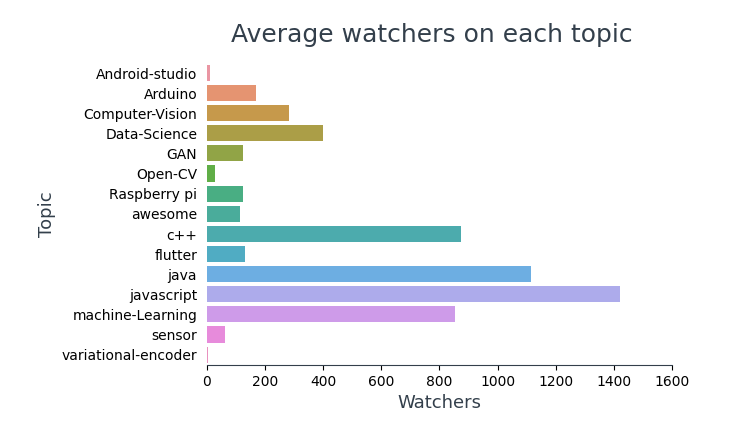
Noter: Le code du graphique ci-dessus est le même que celui des « Étoiles moyennes sur chaque sujet », à l'exception des noms de colonnes. Je n'ai pas ajouté le même pour éviter la redondance.
# Haut 10 repos les plus regardés github_df.nlargest(n=10, colonnes="Regarder")[['Nom_dépôt','Sujet','Regarder']]
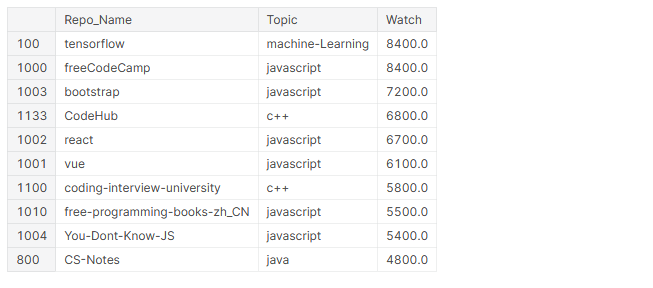
imprimer('Le référentiel le plus regardé est {}{}{} dans le sujet {}{}'.
format('33[1je suis,github_df.iloc[github_df['Regarder'].idxmax()]['Nom_dépôt'],
'33[0je suis,'33[1je suis,github_df.iloc[github_df['Regarder'].idxmax()]['Sujet']))

Dans les 10 référentiels les plus consultés, 4 fils cadres (TensorFlow, Amorcer, Réagir, Vue), 6 concernent JavaScript et 5 d'entre eux contiennent du contenu d'apprentissage pour les programmeurs.
1.3 Analyse de la fourche
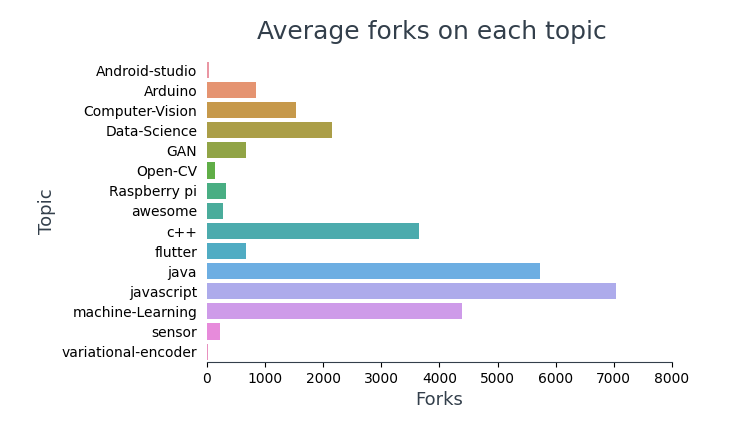
Afficher le nombre moyen de fourchettes dans chaque sujet,
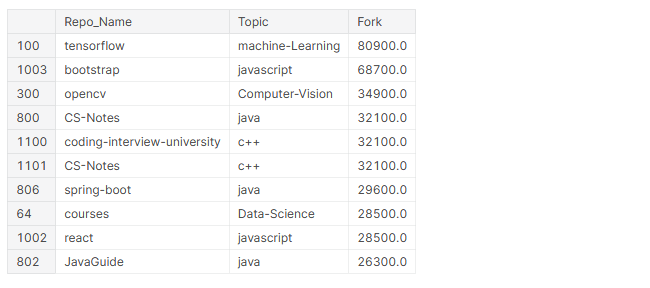
# Haut 10 repos les plus fourchus github_df.nlargest(n=10, colonnes="Fourchette")[['Nom_dépôt','Sujet','Fourchette']]
imprimer('La plupart des référentiels forkés sont {}{}{} dans le sujet {}{}'.
format('33[1je suis,github_df.iloc[github_df['Fourchette'].idxmax()]['Nom_dépôt'],'33[0je suis,
'33[1je suis,github_df.iloc[github_df['Fourchette'].idxmax()]['Sujet']))

En haut 10 plus de référentiels fourchus, 4 fils cadres (TensorFlow, amorcer, botte à ressort, réagir) Oui 5 d'entre eux contiennent du contenu d'apprentissage pour les programmeurs.
1.4 Relation étoile, épingle à cheveux et montre
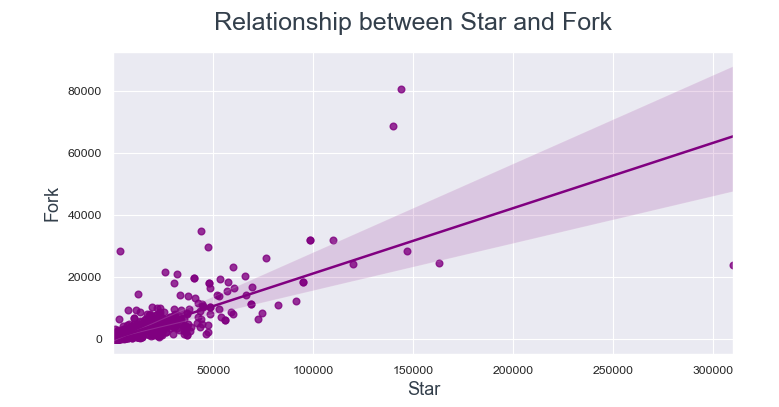
Souvent, les utilisateurs créent un référentiel lorsqu'ils souhaitent y contribuer. Ensuite, Explorons la relation entre la fourchette d'étoiles et la fourchette d'horloge.
# définir la taille de la figure et le dpi
figure, ax = plt.subplots(taille de la figue=(8,4), ppp=100)
# définir un thème marin pour les grilles d'arrière-plan
sns.set_theme('papier')
# tracer les données
sns.regplot(données=github_df, x='Regarder', y='Fourchette', couleur="violet");
# définir les étiquettes et le titre des axes x et y
ax.set_xlabel('Regarder', taille de police=13, couleur="#333F4B")
ax.set_ylabel('Fourchette', taille de police=13, couleur="#333F4B")
fig.sous-titre(« Relation entre la montre et la fourchette »,taille de police=18, couleur="#333F4B")
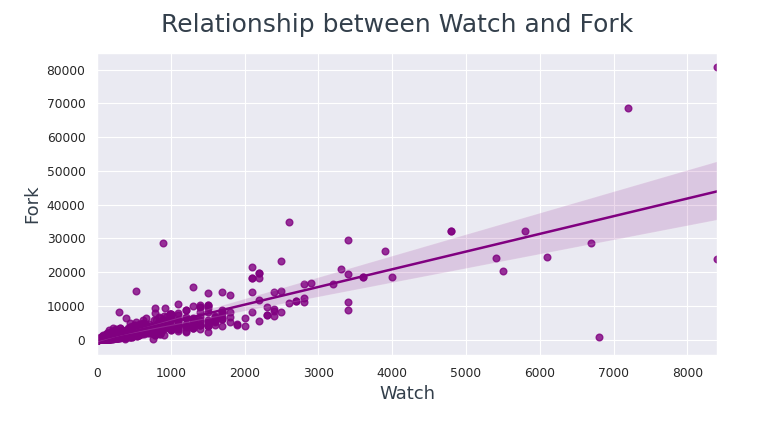
Les points de données sont beaucoup plus proches de la ligne de régression entre Watch et Fork par rapport à Star et Fork.
De là on peut conclure, si un utilisateur consulte un référentiel, plus susceptible de le fork.
2. Analyse des utilisateurs avec plus de référentiels
Jetons un coup d'œil aux utilisateurs qui ont les référentiels les plus populaires.
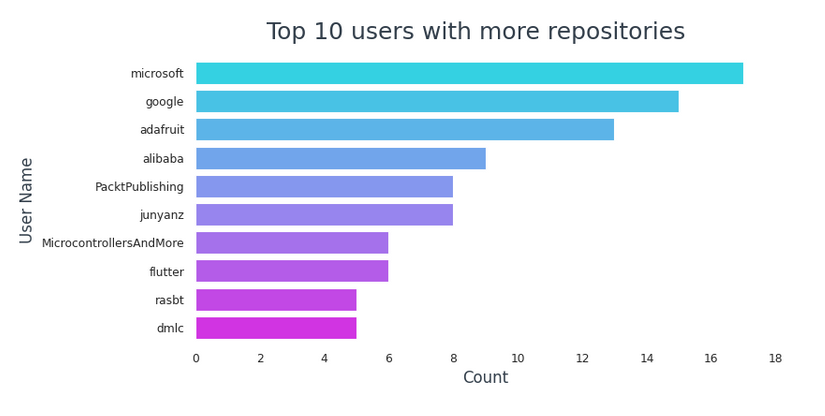
En haut 10 utilisateurs avec plus de référentiels,
- Microsoft arrive en tête de liste avec 17 référentiels.
- Google continue avec 15 référentiels.
- 6 d'entre eux sont des entreprises ou appartiennent à une entreprise (Microsoft, Google, Adafruit, Alibaba, PacktPublishing, battement)
- 3 ce sont des utilisateurs individuels (junyanz, rasb, MicrocontrôleursEtPlus)
3. Comprendre les activités de contribution dans les référentiels
GitHub est célèbre pour son graphe de contribution.
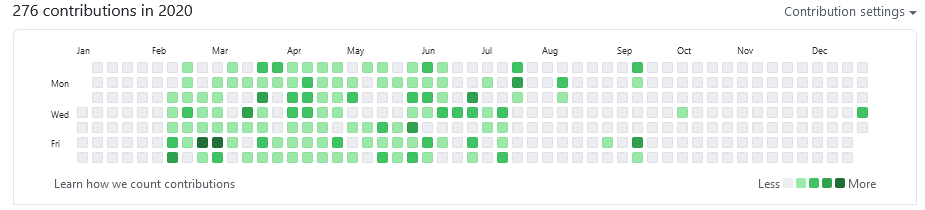
Ce graphique est un enregistrement de toutes les contributions d'un utilisateur. Chaque fois qu'un utilisateur fait une confirmation, ouvrir un problème ou proposer une pull request, est considéré comme une contribution. Il y a quatre colonnes liées aux contributions dans notre ensemble de données, Problèmes, Pull_Requests, S'engage, Collaborateurs. Voyons s'il y a une vraie relation entre eux.
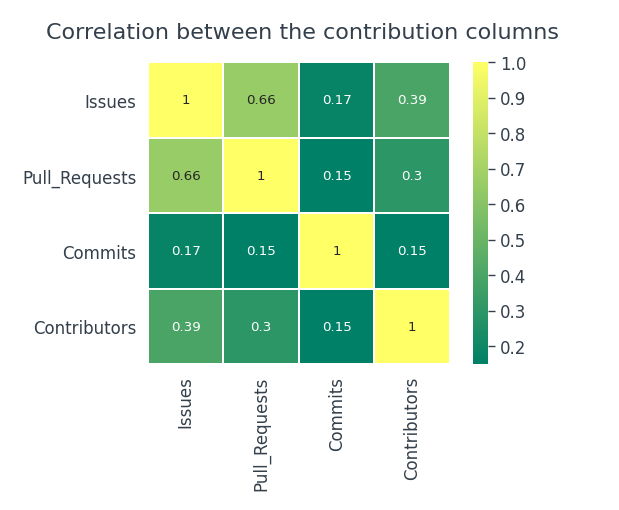
Le nombre de confirmations ne dépend d'aucun problème, pull request ou contributeurs. Il existe une relation positive modérée entre les problèmes et les demandes de tirage.
Explorons le 100 les référentiels les plus populaires et voyons si c'est la même chose,
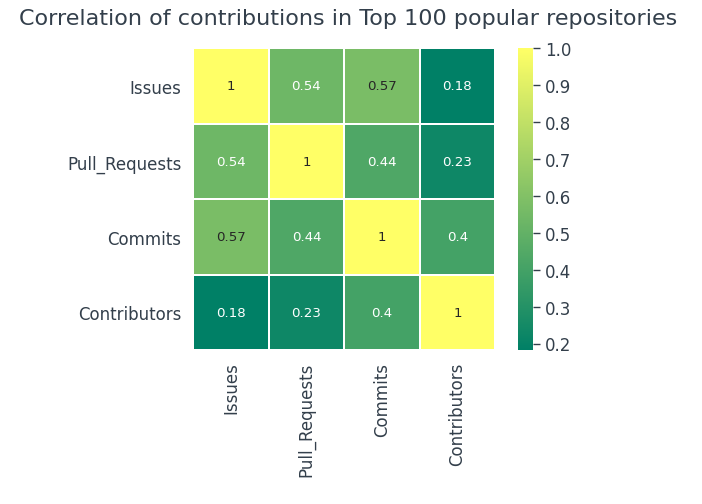
C'est à peu près la même chose dans 100 référentiels plus populaires que dans l'ensemble de données général.
Trouvons des utilisateurs avec plus de référentiels,
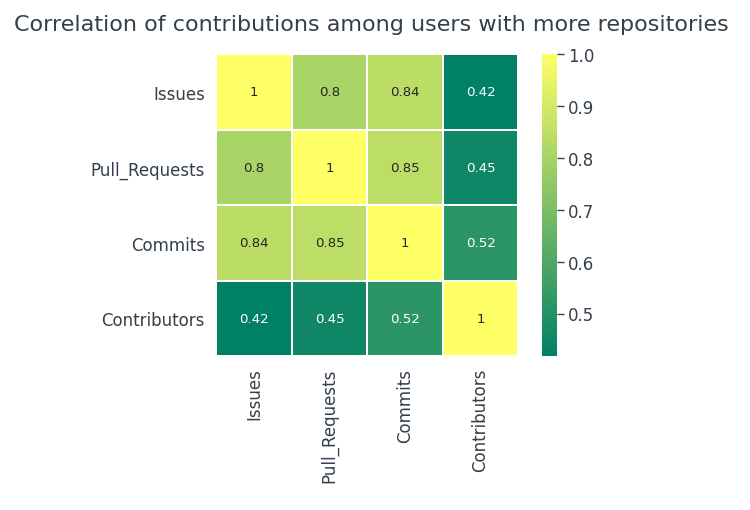
Étonnamment, les utilisateurs avec plus de référentiels ont tendance à être plus actifs. Il existe une corrélation positive assez forte entre
- Confirmer et extraire les demandes
- Compromis et problèmes
- Demandes de tirage et problèmes
Concernant les cotisations,
- Il n'y a pas de relation réelle entre les activités de contribution dans l'ensemble de données global.
- Il n'y a pas non plus de corrélation entre les contributions dans le 100 référentiels les plus populaires.
- Si les utilisateurs ont tendance à avoir plus de référentiels, alors les possibilités d'apports sont beaucoup plus élevées.
4. Analyse des balises de sujet
La colonne topic_tags est constituée de listes. Pour trouver des balises populaires, convertir la colonne entière en une liste de listes et compter l'occurrence de chaque étiquette. Avec ça, nous pouvons visualiser certaines des balises de sujet les plus populaires et voir quels sujets ont tendance à être le plus balisés.
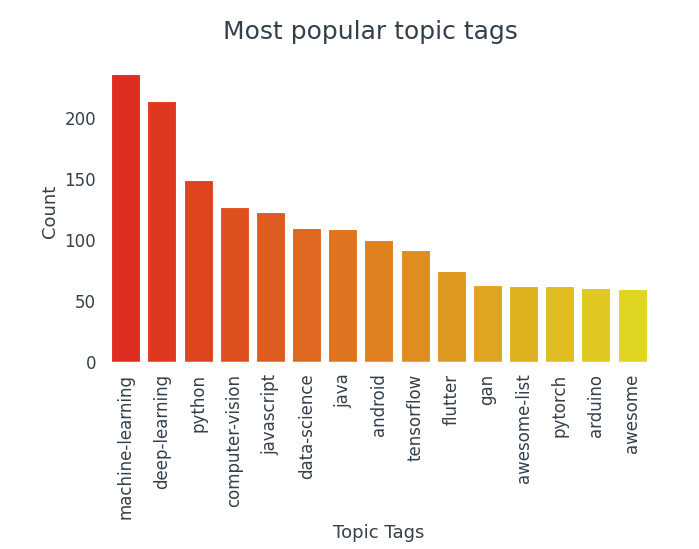
Des 15 les balises les plus populaires, 10 appartenir au monde de la science des données.
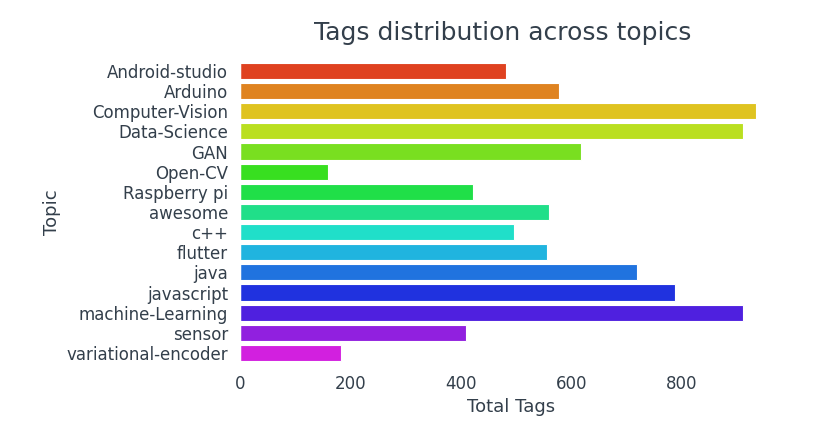
Référentiels avec des thèmes Computer Vision, La science des données et l'apprentissage automatique ont tendance à être plus étiquetés.
Terminons avec un nuage de mots de topic_tags,
Inférence:
- Entre le 10 référentiels les plus importants, vu et fourchu, 4 fils cadres.
- Tensorflow est le référentiel forké le plus regardé.
- Si un utilisateur consulte un référentiel, plus susceptible de le fork.
- Microsoft et Google ont tendance à être des utilisateurs avec des référentiels plus populaires.
- En haut 10 utilisateurs avec les référentiels les plus populaires, 6 d'entre eux sont des entreprises.
- Il n'y a pas de relation réelle entre les activités de contribution (problèmes, demandes de tirage, confirmations).
- Les balises les plus utilisées sont le Machine Learning, L'apprentissage en profondeur, Python, Vision par ordinateur, JavaScript.
- Référentiels avec des thèmes Computer Vision, La science des données et l'apprentissage automatique ont plus d'étiquettes.
Si nous avions analysé les données d'il y a dix ans, ces tendances auraient été complètement différentes. C'est comme si la science des données avait connu une croissance monstrueuse ces dernières années !!
Merci d'avoir regardé jusqu'ici! j'aimerais bien me connecter LinkedIn
Faites-moi savoir dans la section commentaire si vous avez des préoccupations, commentaire ou critique. Bonne journée!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





