Qu'est-ce que la régression logistique?
Cet article suppose que vous avez une connaissance et une compréhension de base des concepts d'apprentissage automatique., comme vecteur cible, la matrice des caractéristiques et des termes associés.
Régression logistique: probablement l'un des algorithmes d'apprentissage automatique supervisé les plus intéressants en apprentissage automatique. En dépit d'avoir « Régression » en son nom, La régression logistique est une méthode supervisée couramment utilisée. Classification Algorithme. Régression logistique, avec leurs cousins parents, à savoir.. Régression logistique multinomiale, nous donne la possibilité de prédire si une observation appartient à une certaine classe en utilisant une approche simple, facile à comprendre et sur.
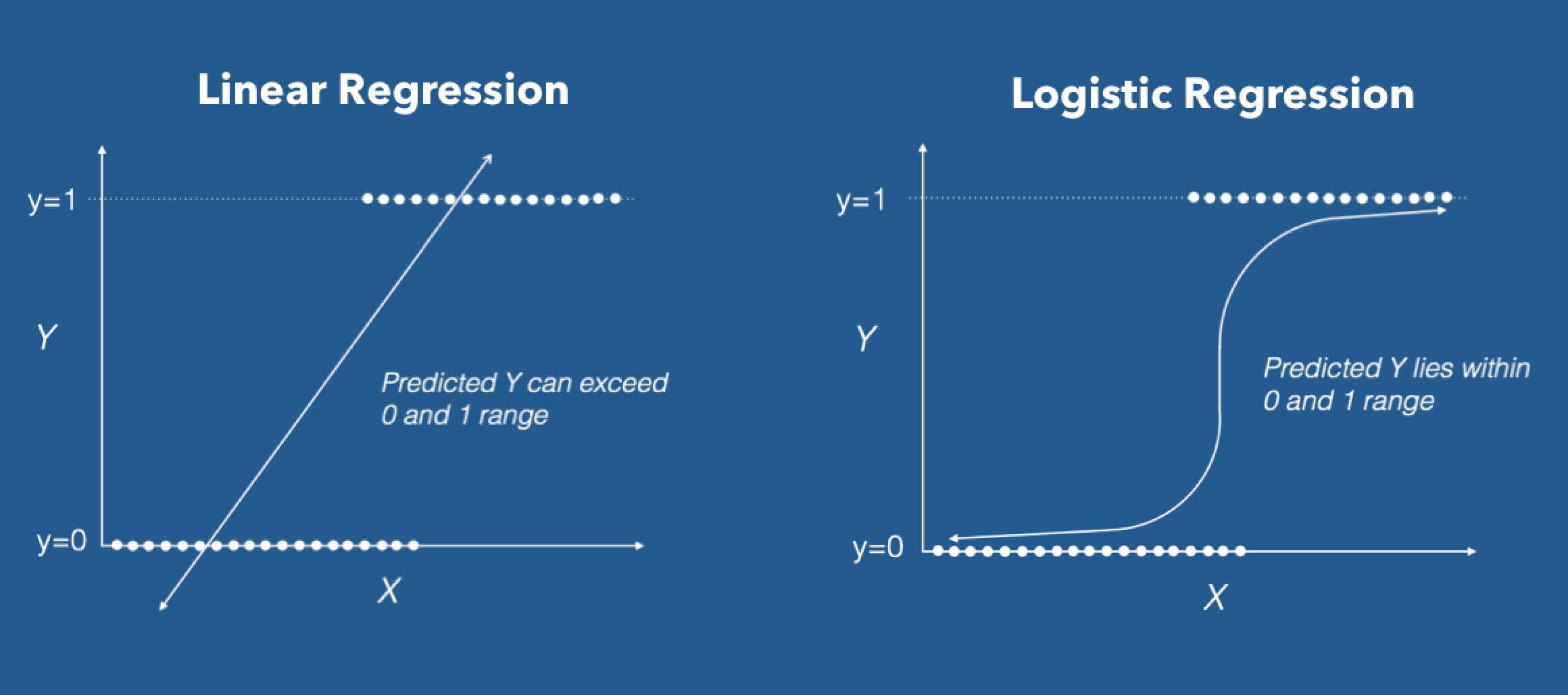
La source: DZone
Régression logistique sous sa forme de base (pour défaut) c'est un Classificateur binaire. Cela signifie que le vecteur cible ne peut prendre la forme que de l'une des deux valeurs. Dans la formule de l'algorithme de régression logistique, nous avons un modèle linéaire, par exemple, b0 + b1X, qui s'intègre dans une fonction logistique (également appelée fonction sigmoïde). La formule du classificateur binaire que nous avons à la fin est la suivante:
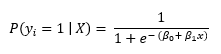
 Où:
Où:
- P (Ouije = 1 | X) est la probabilité du ie Valeur cible des observations, Ouije appartenant à la classe 1.
- ??0 oui1 son los paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... que se deben aprender.
- moi représente le nombre d'Euler.
Objectif principal de la formule de régression logistique.
La formule de régression logistique vise à limiter ou à contraindre la sortie linéaire et / le sigmoïde entre une valeur de 0 Oui 1. La raison principale est à des fins d'interprétabilité, c'est-à-dire, nous pouvons lire la valeur comme une simple probabilité; Ce qui signifie que si la valeur est supérieure à 0,5, la classe un serait prédite; au contraire, la classe est prévue 0.
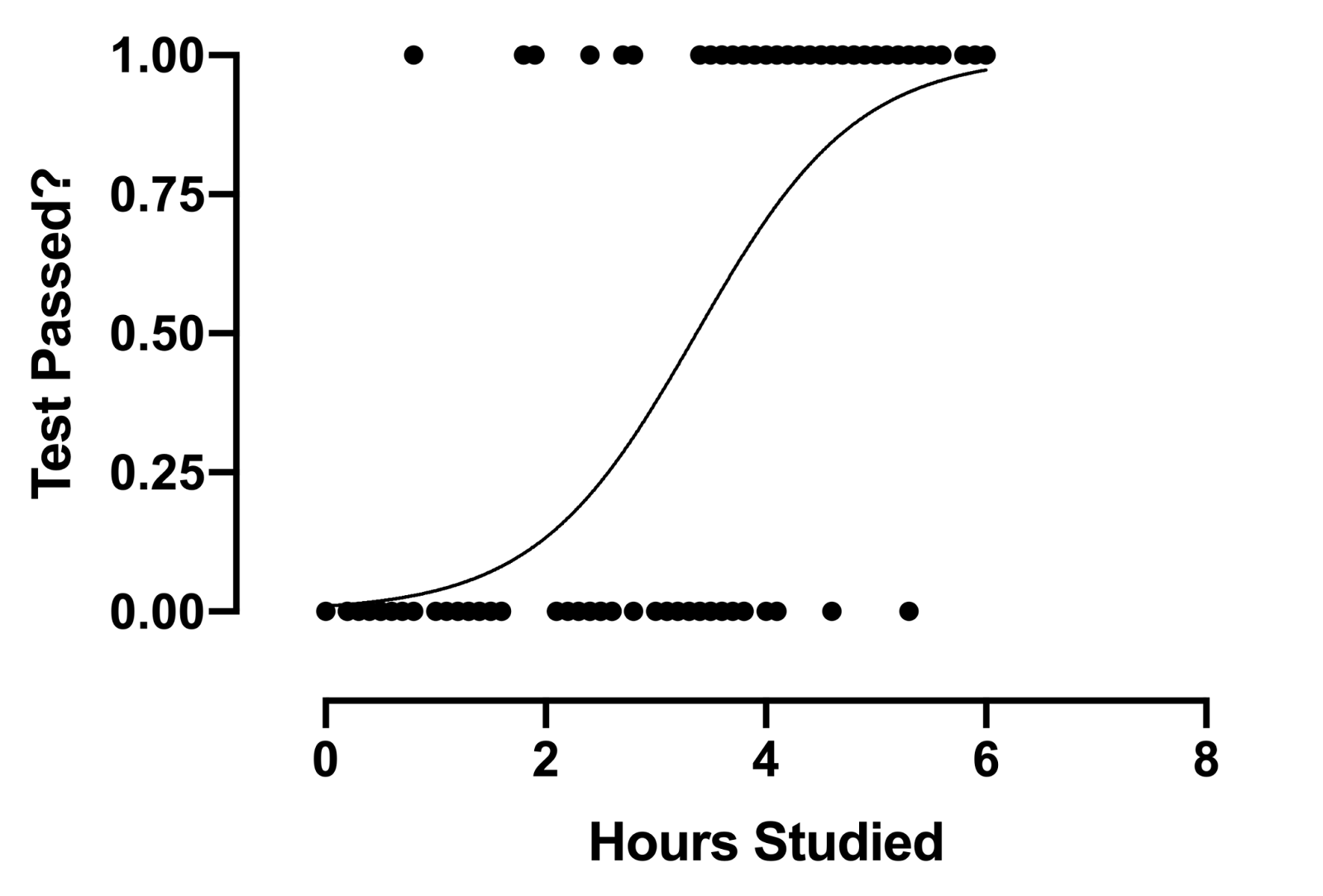
La source: GraphPad
Implémentation Python.
Nous allons maintenant voir l'implémentation du langage de programmation Python. Pour cet exercice, Nous utiliserons l'ensemble de données sur l'ionosphère qui est disponible en téléchargement à partir du Référentiel d'apprentissage automatique de l'UCI.
# On commence par importer les packages nécessaires
# à utiliser pour le problème d'apprentissage automatique
importer des pandas au format pd
importer numpy en tant que np
à partir de sklearn.linear_model import LogisticRegression
de sklearn.preprocessing importer StandardScaler
# Nous lisons les données dans notre système à l'aide de Pandas
# méthode 'read_csv'. Cela transforme le fichier .csv
# dans un objet Pandas DataFrame.
cadre de données = pd.read_csv('ionosphere.data', header=Aucun)
# Nous configurons les paramètres d'affichage du
# Cadre de données Pandas.
pd.set_option('display.max_rows', 10000000000)
pd.set_option('display.max_columns', 10000000000)
pd.set_option('affichage.largeur', 95)
# Nous regardons la forme du dataframe. Spécifiquement
# le nombre de lignes et de colonnes présentes.
imprimer('Ce DataFrame a %d lignes et %d colonnes'%(dataframe.shape))
La sortie du code précédent serait la suivante (la forme du bloc de données):
![]()
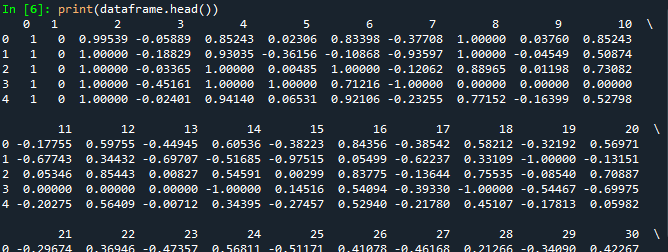
# Nous imprimons les cinq premières lignes de notre dataframe. imprimer(dataframe.head())
La sortie du code ci-dessus ressemblera à ce qui suit (la sortie suivante est tronquée):

# Nous isolons la matrice de fonctionnalités du DataFrame.
features_matrix = dataframe.iloc[:, 0:34]
# Nous isolons le vecteur cible du DataFrame.
target_vector = dataframe.iloc[:, -1]
# Nous vérifions la forme de la matrice de caractéristiques, et vecteur cible.
imprimer('La matrice des fonctionnalités a %d lignes et %d colonne(s)'%(features_matrix.shape))
imprimer('La matrice cible a %d lignes et %d colonne(s)'%(np.array(vecteur_cible).remodeler(-1, 1).forme))
La sortie de la forme de notre matrice de caractéristiques et du vecteur cible serait la suivante:
![]()

# Nous utilisons le StandardScaler de scikit-learn afin de # prétraiter les données de la matrice de caractéristiques. Cette volonté # s'assurer que toutes les valeurs saisies sont sur le même # échelle pour l'algorithme. features_matrix_standardized = StandardScaler().fit_transformer(features_matrix)
# Nous créons une instance de l'algorithme LogisticRegression # Nous utilisons les valeurs par défaut pour les paramètres et # hyperparamètres. algorithme = Régression Logistique(pénalité='l2', dual=Faux, péage=1e-4, C=1.0, fit_intercept=Vrai, intercept_scaling=1, class_weight=Aucun, random_state=Aucun, solveur="lbfg", max_iter=100, multi_classe="auto", verbeux=0, warm_start=Faux, n_jobs=Aucun, l1_ratio=Aucun) # Nous utilisons la méthode « ajustement » afin de procéder à la # processus de formation sur notre matrice de fonctionnalités et notre vecteur cible. Logistic_Regression_Model = algorithm.fit(features_matrix_standardized, vecteur_cible)
# Nous créons un constat avec des valeurs, en ordre # pour tester le pouvoir prédictif de notre modèle. observation = [[1, 0, 0.99539, -0.05889, 0.8524299999999999, 0.02306, 0.8339799999999999, -0.37708, 1.0, 0.0376, 0.8524299999999999, -0.17755, 0.59755, -0.44945, 0.60536, -0.38223, 0.8435600000000001, -0.38542, 0.58212, -0.32192, 0.56971, -0.29674, 0.36946, -0.47357, 0.56811, -0.51171, 0.41078000000000003, -0.46168000000000003, 0.21266, -0.3409, 0.42267, -0.54487, 0.18641, -0.453]]
# Nous stockons la valeur de classe prédite dans une variable # appelé "prédictions". prédictions = Logistic_Regression_Model.predict(observation)
# Nous imprimons la classe prédite du modèle pour l'observation.
imprimer('Le modèle a prédit que l'observation appartenait à la classe %s'%(prédictions))
La sortie vers le bloc de code précédent doit être la suivante:


# Nous examinons les classes spécifiques pour lesquelles le modèle a été formé pour prédire.
imprimer('L'algorithme a été formé pour prédire l'une des deux classes: %s'%(algorithm.classes_))
La sortie vers le bloc de code précédent ressemblera à ce qui suit:


imprimer("""Le modèle dit que la probabilité de l'observation que nous avons transmise appartient à la classe ['b'] Est %s"""%(algorithm.predict_proba(observation)[0][0]))
imprimer()
imprimer("""Le modèle dit que la probabilité de l'observation que nous avons transmise appartient à la classe ['g'] Est %s"""%(algorithm.predict_proba(observation)[0][1]))
Le résultat attendu serait le suivant:

conclusion.
Ceci conclut mon article. Maintenant, nous comprenons la logique derrière cet algorithme d'apprentissage automatique supervisé et nous savons comment l'implémenter dans un problème de classification binaire.
Merci pour ton temps.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





