Noter: cet article a été initialement publié le 13 septembre 2015 et mis à jour le 11 septembre 2017
Vue d'ensemble
- Comprendre l'un des algorithmes de classification d'apprentissage automatique les plus populaires et les plus simples, l'algorithme de Naive Bayes
- Il est basé sur le théorème de Bayes pour calculer les probabilités et les probabilités conditionnelles.
- Apprenez à implémenter le classificateur Naive Bayes dans R et Python
introduction
Voici une situation dans laquelle vous vous êtes retrouvé Science des données projet:
Vous travaillez sur un obstacle de classification et avez généré votre ensemble d'hypothèses, créé des caractéristiques et discuté de la pertinence des variables. Dans une heure, les parties prenantes veulent voir la première coupe du modèle.
Que vas-tu faire? Tienes cientos de cientos de puntos de datos y bastantes variables en tu conjunto de datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines..... Dans une telle situation, si j'étais à ta place, aurait utilisé ‘Bayes ingénieux‘, qui peut être extrêmement rapide dans la création de liens avec les autres algorithmes de classification. Fonctionne avec le théorème de probabilité de Bayes pour prédire la classe des ensembles de données inconnus.
Dans ce billet, Je vais expliquer les bases de cet algorithme, donc la prochaine fois que vous rencontrerez de grands ensembles de données, peut mettre cet algorithme en action. En même temps, si vous êtes un débutant en Python le R, vous ne devriez pas être submergé par la présence de codes disponibles dans ce post.
Si vous préférez apprendre le théorème de Naive Bayes des bases à la mise en œuvre de manière structurée, vous pouvez vous inscrire à ce cours gratuitement:
Êtes-vous un débutant en Machine Learning? Avez-vous l'intention de maîtriser des algorithmes d'apprentissage automatique comme Naive Bayes? Aquí hay un curso completo que cubre el aprendizaje automático y los algoritmos de l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé... en détail:
Projet d'application Naive BayesApproche du problémeL'analyse RH révolutionne le fonctionnement des services RH, conduisant à une plus grande efficacité et de meilleurs résultats dans l'ensemble. Los recursos humanos han estado usando la analytiqueL’analytique fait référence au processus de collecte, Mesurer et analyser les données pour obtenir des informations précieuses qui facilitent la prise de décision. Dans divers domaines, Comme les affaires, Santé et sport, L’analytique peut identifier des modèles et des tendances, Optimiser les processus et améliorer les résultats. L’utilisation d’outils et de techniques statistiques de pointe est essentielle pour transformer les données en connaissances applicables et stratégiques.... pendant des années. Malgré cela, la compilation, el procesamiento y el análisis de datos ha sido en gran mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... manual y, dada la naturaleza de la dinámica de los recursos humanos y los KPIKPI, o Indicateurs clés de performance, Il s’agit de mesures utilisées par les organisations pour évaluer leur succès dans l’atteinte d’objectifs spécifiques. Ces indicateurs vous permettent de suivre les progrès et de prendre des décisions éclairées. Il existe différents types de KPI, qui peuvent varier en fonction du secteur et des objectifs stratégiques de l’entreprise. Sa bonne mise en œuvre est essentielle pour améliorer l’efficience et l’efficacité des opérations.... de recursos humanos, l'accent s'est limité aux ressources humaines. Pour cela, il est surprenant que les départements des ressources humaines se soient rendu compte de l'utilité de l'apprentissage automatique si tard dans le jeu. Il s'agit d'une possibilité de tester l'analyse prédictive pour identifier les travailleurs les plus susceptibles d'être promus. |
Table des matières
- Qu'est-ce que l'algorithme Naive Bayes?
- Comment fonctionnent les algorithmes de Naive Bayes?
- Quels sont les avantages et les inconvénients de l'utilisation de Naive Bayes?
- 4 Applications de l'algorithme naïf de Bayes
- Étapes pour créer un modèle Naive Bayes de base en Python
- Conseils pour augmenter la puissance du modèle naïf de Bayes
Qu'est-ce que l'algorithme Naive Bayes?
C'est un technique de classement basé sur le théorème de Bayes avec une hypothèse d'indépendance entre les prédicteurs. En termes simples, un classificateur Naive Bayes suppose que la présence d'une caractéristique particulière dans une classe n'est pas liée à la présence de toute autre caractéristique.
Par exemple, un fruit peut être considéré comme une pomme s'il est rouge, ronde et a environ 3 pouces de diamètre. Même si ces caractéristiques dépendent les unes des autres ou de l'existence d'autres caractéristiques, todas estas propiedades contribuyen de forma independiente a la probabilidad de que esta fruta sea una manzana y es por esto que se la conoce como ‘Naive’.
Le modèle Naive Bayes est facile à construire et particulièrement utile pour les très grands ensembles de données.. Avec la simplicité, Naive Bayes est connu pour surpasser même les méthodes de classification très sophistiquées.
Le théorème de Bayes permet de calculer la probabilité postérieure P (c | X) de P (c), P (X) yP (X | c). Regardez l'équation suivante:
 Sur,
Sur,
- PAG(c | X) est la probabilité postérieure de classe (C, objectif) dé prédicteur (X, les attributs).
- PAG(C) est la probabilité a priori de classe.
- PAG(X | c) est la probabilité qui est la probabilité de prédicteur dé classe.
- PAG(X) est la probabilité a priori de prédicteur.
Comment fonctionne l'algorithme Naive Bayes?
Comprenons avec un exemple. A continuación tengo un conjunto de datos de entrenamiento del clima y la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... objetivo respectivo ‘Jouer’ (suggérer des possibilités de jeu). À présent, il faut catégoriser si les joueurs joueront ou non en fonction des conditions météo. Suivons les étapes ci-dessous pour le faire.
Paso 1: convertir l'ensemble de données en une table de fréquences
Paso 2: Créez une table de probabilités en trouvant les probabilités comme la probabilité de Nuageux = 0.29 et la probabilité de jouer est 0.64.
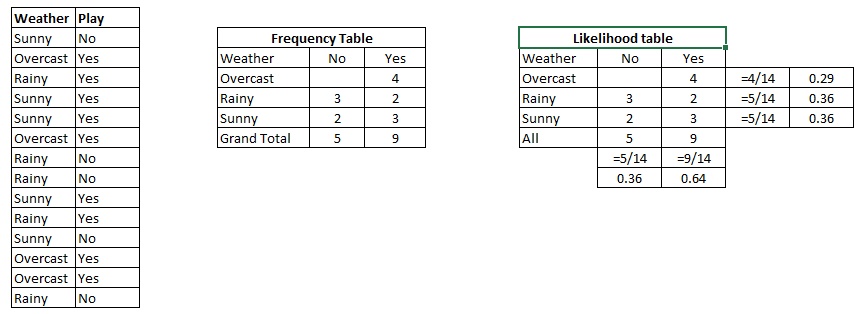
Paso 3: à présent, les usages Ingenuo bayesiano équation pour calculer la probabilité postérieure pour chaque classe. La classe avec la probabilité postérieure la plus élevée est le résultat du pronostic.
Problème: Les joueurs joueront s'il fait beau. Cette déclaration est-elle correcte?
Nous pouvons le résoudre en utilisant la méthode de probabilité postérieure discutée précédemment.
P (Oui | Ensoleillé) = P (Ensoleillé | Oui) * P (Oui) / P (Ensoleillé)
Ici nous avons P (Ensoleillé | Oui) = 3/9 = 0.33, P (Ensoleillé) = 5/14 = 0.36, P (Oui) = 9/14 = 0.64
À présent, P (Oui | Ensoleillé) = 0.33 * 0.64 / 0.36 = 0.60, ce qui est plus probable.
Naive Bayes utilise une méthode équivalente pour prédire la probabilité de différentes classes en fonction de divers attributs. Cet algorithme est principalement utilisé dans la classification de texte et avec des problèmes qui ont plusieurs classes.
Quels sont les avantages et les inconvénients de Naive Bayes?
Avantages:
- Il est facile et rapide de prédire le type d'ensemble de données de test. Fonctionne également bien dans les prévisions multi-classes.
- Lorsque l'hypothèse d'indépendance est remplie, un classificateur Naive Bayes fonctionne mieux que d'autres modèles tels que la régression logistique et nécessite moins de données d'apprentissage.
- Fonctionne bien pour les variables d'entrée catégorielles par rapport aux variables numériques. Pour la variable numérique, une distribution normale est supposée (courbe en cloche, ce qui est une hypothèse solide).
Les inconvénients:
- Si la variable catégorielle a une catégorie (dans le jeu de données de test), qui n'a pas été observé dans l'ensemble de données d'entraînement, alors le modèle attribuera une probabilité 0 (zéro) et ne sera pas en mesure de faire une prédiction. Ceci est souvent appelé « Fréquence zéro ». Pour réparer ça, on peut utiliser la technique du lissage. L'une des techniques de lissage les plus simples s'appelle l'estimation de Laplace..
- D'autre part, Bayes ingenuo además se conoce como un mal estimateurLe "Estimateur" est un outil statistique utilisé pour déduire les caractéristiques d’une population à partir d’un échantillon. Il s’appuie sur des méthodes mathématiques pour fournir des estimations précises et fiables. Il existe différents types d’estimateurs, tels que l’impartialité et la cohérence, qui sont choisis en fonction du contexte et de l’objectif de l’étude. Son utilisation correcte est essentielle dans la recherche scientifique, enquêtes et analyses de données...., donc les sorties de probabilité de prédire_test ne doit pas être pris trop au sérieux.
- Une autre limite de Bayes ingénieux est l'hypothèse de prédicteurs indépendants. Dans la vie réelle, il nous est presque impossible d'obtenir un ensemble de prédicteurs totalement indépendants.
4 Applications des algorithmes naïfs de Bayes
- Prédiction en temps réel: Naive Bayes est un classificateur d'apprentissage avide et sûr qui est rapide. Pourtant, pourrait être utilisé pour faire des prédictions en temps réel.
- Prédiction de classes multiples: Cet algorithme est également bien connu pour sa fonction de prédiction à classes multiples.. Ici, nous pouvons prédire la probabilité de plusieurs classes de variable cible.
- Classement de texte / filtrage anti-spam / analyse des sentiments: Classificateurs naïfs de Bayes utilisés principalement dans la classification de texte (en raison d'un meilleur résultat dans les problèmes de classes multiples et la règle d'indépendance) ont un taux de réussite plus élevé par rapport aux autres algorithmes. Comme conséquence, largement utilisé dans le filtrage anti-spam (identifier les spams) et analyse des sentiments (dans l'analyse des médias sociaux, identifier les sentiments positifs et négatifs des clients).
- Système de recommandation: classificateur naïf de Bayes et Filtrage collaboratif ensemble, ils construisent un système de recommandation qui utilise des techniques d'apprentissage automatique et d'exploration de données pour filtrer les informations invisibles et prédire si un utilisateur veut une certaine ressource ou non
Comment construire un modèle de base en utilisant Naive Bayes en Python et R?
Encore, scikit apprendre (bibliothèque Python) aidera ici à construire un modèle Naive Bayes en Python. Il existe trois types de modèle Naive Bayes dans la bibliothèque scikit-learn:
-
Gaussiano: Il est utilisé dans la classification et suppose que les caractéristiques suivent une distribution normale.
-
Multinomial: Utilisé pour les comptages discrets. Par exemple, disons que nous avons un obstacle de tri de texte. Ici, nous pouvons considérer les essais de Bernoulli, ce qui est un pas de plus et au lieu de « mot qui apparaît dans le document », avoir « compter la fréquence à laquelle le mot apparaît dans le document », vous pouvez le considérer comme « nombre de fois que le résultat est observé nombre x_i pendant les n essais ».
-
Bernoulli: Le modèle binomial est utile si ses vecteurs caractéristiques sont binaires (En d'autres termes, zéros et uns). Una aplicación sería la clasificación de texto con el modelo de ‘sac de mots’ où l' 1 Oui 0 fils « le mot apparaît dans le document » Oui « le mot n’apparaît pas dans le document », respectivement.
Code Python:
Essayez le code suivant dans la fenêtre d’encodage et vérifiez ses résultats à la volée!
Code R:
Exige(e1071) #Holds the Naive Bayes Classifier Train <- lire.csv(fichier.choisir()) Test <- lire.csv(fichier.choisir()) #Make sure the target variable is of a two-class classification problem only levels(Train$Item_Fat_Content) maquette <- naïveBayes(Item_Fat_Content~., données = Train) classer(maquette) pred <- prédire(maquette,Test) tableau(pred)
Précédemment, nous analysons le modèle de base de Naive Bayes, puede mejorar la potencia de este modelo básico ajustando los paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... y manejando las suposiciones de manera inteligente. Voyons les méthodes pour booster les performances du modèle Naive Bayes. je vous propose de passer ce document pour plus de détails sur la classification du texte à l'aide de Naive Bayes.
Conseils pour augmenter la puissance du modèle naïf de Bayes
Ensuite, Voici quelques conseils pour augmenter la puissance de Bayes ingénieux Modèle:
- Si les entités continues n'ont pas de distribution normale, nous devrions utiliser la transformation ou différentes méthodes pour les convertir en distribution normale.
- Si l'ensemble de données de test a un obstacle de fréquence zéro, appliquer des techniques de lissage de « correction de Laplace » pour prédire la classe de l'ensemble de données de test.
- Supprimer les fonctionnalités corrélées, puisque les caractéristiques fortement corrélées sont votées deux fois dans le modèle et peuvent conduire à une pertinence exagérée.
- Les classificateurs Naive Bayes ont des options limitées pour définir des paramètres tels que alpha = 1 lisser, fit_prior =[Vrai|Faux] apprendre les probabilités antérieures de la classe ou non et quelques autres options (voir les détails ici). Je recommanderais de se concentrer sur le prétraitement des données et la sélection des fonctionnalités.
- Pourriez-vous penser à appliquer certains technique de combinaison de classificateurs comme ensemble, ensachage et renfort, mais ces méthodes n'aideraient pas. En réalité, « rejoindre, renforcer, poche » n'aidera pas, puisque son objectif est de réduire la variation. Naive Bayes n'a aucune variation à minimiser.
Remarques finales
Dans ce billet, nous analysons l'un des algorithmes d'apprentissage automatique supervisé »Naïf Bayes » qui est principalement utilisé pour le tri. toutes nos félicitations, si vous avez bien compris ce post, vous avez déjà fait le premier pas pour maîtriser cet algorithme. À partir d'ici, tout ce dont vous avez besoin c'est de la pratique.
En même temps, Je vous suggère de vous concentrer davantage sur le prétraitement des données et la sélection des fonctionnalités avant d'appliquer l'algorithme Naive Bayes.0 Dans un futur post, Je parlerai plus en détail de la classification des textes et des documents à l'aide de bayes naïfs.
Ce post vous a-t-il été utile? Partagez vos opinions / pensées dans la section des commentaires ci-dessous.
Vous pouvez utiliser gratuitement la ressource suivante pour apprendre- Naïf Bayes-





