Une analogie simple pour expliquer l'arbre de décision par rapport à la forêt aléatoire
Commençons par une expérience de pensée qui illustrera la différence entre un arbre de décision et un modèle de forêt aléatoire..
Supposons qu'une banque doive approuver un petit montant de prêt pour un client et que la banque doive prendre une décision rapidement. La banque vérifie les antécédents de crédit et la situation financière de la personne et découvre que le prêt précédent n'a pas encore été remboursé. Pourtant, la banque rejette la demande.
Mais voici le problème: le montant du prêt était trop petit pour les énormes coffres de la banque et ils auraient facilement pu l'approuver dans une mesure à très faible risque. Donc, la banque a perdu l'opportunité de gagner de l'argent.
À présent, une autre demande de prêt arrivera dans quelques jours, mais cette fois la banque présente une stratégie différente: plusieurs processus de prise de décision. Parfois, vérifiez d'abord l'historique de crédit et, parfois, vérifier d'abord la situation financière du client et le montant du prêt. Alors, la banque combine les résultats de ces multiples processus décisionnels et décide d'accorder le prêt au client.
Même si ce processus a pris plus de temps que le précédent, la banque a bénéficié de cette méthode. Il s'agit d'un exemple classique où la prise de décision collective a surpassé un processus de prise de décision unique. À présent, voici ma question pour vous: Savez-vous ce que représentent ces deux processus?

Ce sont des arbres de décision et une forêt aléatoire !! Nous allons explorer cette idée en détail ici, nous allons approfondir les principales différences entre ces deux méthodes et répondre à la question clé: Quel algorithme d'apprentissage automatique dois-je utiliser?
Table des matières
- Brève introduction aux arbres de décision
- Un aperçu des forêts aléatoires
- Conflit de forêt aléatoire et arbre de décision (Dans du code!)
- Pourquoi Random Forest a-t-il surpassé un arbre de décision?
- Arbre de décision versus forêt aléatoire: Quand choisir quel algorithme?
Brève introduction aux arbres de décision
Un arbre de décision est un algorithme d'apprentissage automatique supervisé qui peut être utilisé pour des problèmes de classification et de régression. Un arbre de décision est simplement une série de décisions séquentielles prises pour obtenir un résultat spécifique.. Voici une illustration d'un arbre de décision en action (en utilisant notre exemple ci-dessus):
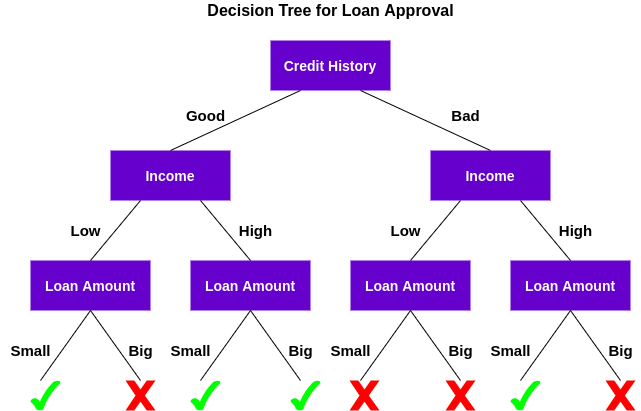
Comprenons comment fonctionne cet arbre.
Premier, vérifier si le client a de bons antécédents de crédit. Basé sur cela, classe le client en deux groupes, c'est-à-dire, clients avec de bons antécédents de crédit et clients avec de mauvais antécédents de crédit. Alors, vérifie le revenu du client et le classe à nouveau en deux groupes. Finalement, vérifie le montant du prêt demandé par le client. D'après les résultats de la vérification de ces trois caractéristiques, l'arbre de décision décide si le prêt du client doit être approuvé ou non.
Les caractéristiques / les attributs et les conditions peuvent changer en fonction des données et de la complexité du problème, mais l'idée générale reste la même. Ensuite, un arbre de décision prend une série de décisions basées sur un ensemble de caractéristiques / attributs présents dans les données, quels étaient dans ce cas les antécédents de crédit, revenu et montant du prêt.
À présent, vous vous demandez peut-être:
Pourquoi l'arbre de décision a-t-il vérifié d'abord le pointage de crédit et non le revenu?
C'est ce qu'on appelle l'importance de la caractéristique et la séquence des attributs à vérifier est décidée sur la base de critères tels que Indice d'impureté de Gini O Gain d'informations. L'explication de ces concepts dépasse le cadre de notre article ici., mais vous pouvez consulter l'une des ressources ci-dessous pour tout savoir sur les arbres de décision:
Noter: L'idée derrière cet article est de comparer les arbres de décision et les forêts aléatoires. Donc, je n'entrerai pas dans les détails des bases, mais je fournirai les liens pertinents au cas où vous voudriez approfondir.
Un aperçu de la forêt aléatoire
L'algorithme de l'arbre de décision est assez facile à comprendre et à interpréter. Mais souvent, un seul arbre ne suffit pas pour produire des résultats efficaces. C'est là qu'intervient l'algorithme Random Forest..

Random Forest est un algorithme d'apprentissage automatique basé sur des arbres qui exploite la puissance de plusieurs arbres de décision pour prendre des décisions. Comme le nom le suggère, c'est un “Forêt” des arbres!
Mais, Pourquoi l'appelons-nous forêt “Aléatoire”? C'est parce que c'est une forêt de arbres de décision créés aléatoirement. Chaque nœud de l'arbre de décision travaille sur un sous-ensemble aléatoire de caractéristiques pour calculer la sortie. La forêt aléatoire combine ensuite la sortie des arbres de décision individuels pour générer la sortie finale.
En mots simples:
L'algorithme de forêt aléatoire combine la sortie de plusieurs arbres de décision (créé au hasard) pour générer la sortie finale.
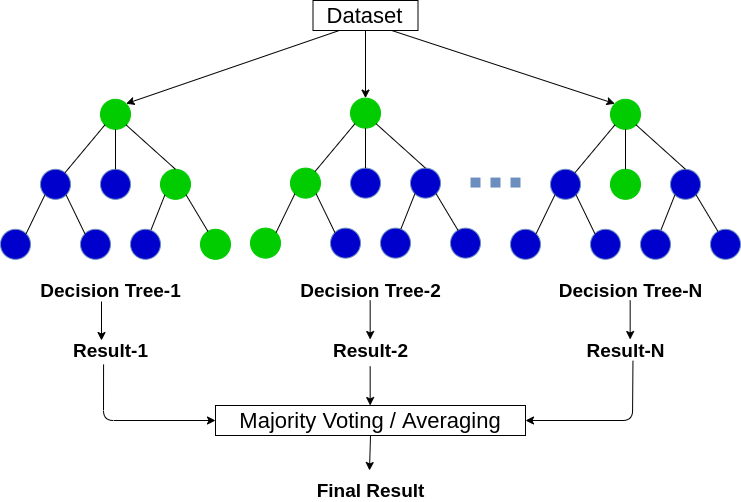
Ce processus de combinaison de la sortie de plusieurs modèles individuels (également connu sous le nom d'étudiants faibles) il s'appelle Apprentissage conjoint. Si vous souhaitez en savoir plus sur le fonctionnement de la forêt aléatoire et d'autres algorithmes d'apprentissage d'ensemble, voir les articles suivants:
Maintenant la question est, Comment pouvons-nous décider quel algorithme choisir entre un arbre de décision et une forêt aléatoire? Voyons les deux en action avant de sauter aux conclusions !!
Conflit de forêt aléatoire et arbre de décision (Dans du code!)
Dans cette section, Nous utiliserons Python pour résoudre un problème de classification binaire en utilisant à la fois un arbre de décision et une forêt aléatoire. Nous comparerons ensuite vos résultats et verrons lequel convient le mieux à notre problème..
Nous travaillerons sur le Ensemble de données de prévision de prêt de DataPeaker Plateforme DataHack. Il s'agit d'un problème de classification binaire dans lequel nous devons déterminer si une personne doit recevoir un prêt ou non en fonction d'un certain ensemble de caractéristiques.
Noter: peut aller à DataHack plateforme et rivalisez avec d'autres personnes dans divers concours d'apprentissage automatique en ligne et courez la chance de gagner des prix passionnants.
Prêt à coder?
Paso 1: charger les bibliothèques et l'ensemble de données
Commençons par importer les bibliothèques Python requises et notre ensemble de données:

L'ensemble de données se compose de 614 rangées et 13 fonctionnalités, y compris les antécédents de crédit, l'état civil, le montant du prêt et le sexe. Ici, la variable cible est Loan_Status, qui indique si une personne doit recevoir un prêt ou non.
Paso 2: prétraitement des données
Vient maintenant la partie la plus cruciale de tout projet de science des données: réprétraitement ata Oui fegénie naturel. Dans cette section, Je traiterai les variables catégorielles dans les données et imputerai également les valeurs manquantes.
Je vais imputer les valeurs manquantes dans les variables catégorielles avec le mode, et pour les variables continues, avec la moyenne (pour les colonnes respectives). En outre, nous allons étiqueter l'encodage des valeurs catégorielles dans les données. Vous pouvez lire cet article pour en savoir plus sur Encodage des étiquettes.

Paso 3: création d'ensembles de test et de trains
À présent, divisons l'ensemble de données en un 80:20 relation pour la formation et les tests, respectivement:
Jetons un coup d'œil à la forme du train et aux ensembles de test créés:

Excellent! Nous sommes maintenant prêts pour la prochaine étape où nous allons créer l'arbre de décision et les modèles de forêt aléatoire !!
Paso 4: construction et évaluation du modèle
Puisque nous avons les ensembles de formation et de test, il est temps de former nos modèles et de classer les demandes de prêt. Premier, nous allons former un arbre de décision sur cet ensemble de données:
Ensuite, nous évaluerons ce modèle en utilisant F1-Score. F1-Score est la moyenne harmonique de précision et de récupération donnée par la formule:
![]()
Vous pouvez en savoir plus à ce sujet et d'autres mesures d'évaluation ici:
Évaluons les performances de notre modèle en utilisant le score F1:
![]()
![]()
Ici, vous pouvez voir que l'arbre de décision fonctionne bien dans l'évaluation dans l'échantillon, mais ses performances chutent considérablement dans l'évaluation hors échantillon. Pourquoi pensez-vous que c'est le cas? Malheureusement, notre modèle d'arbre de décision est sur-ajusté aux données d'entraînement. La forêt aléatoire résoudra-t-elle ce problème?
Construire un modèle de forêt aléatoire
Voyons un modèle de forêt aléatoire en action:
![]()
![]()
Ici, nous pouvons clairement voir que le modèle de forêt aléatoire a donné de bien meilleurs résultats que l'arbre de décision dans l'évaluation hors échantillon. Discutons des raisons derrière cela dans la section suivante..
Pourquoi notre modèle de forêt aléatoire a-t-il surpassé l'arbre de décision?
La forêt aléatoire exploite la puissance de plusieurs arbres de décision. Il le fait non dépendent de l'importance de la caractéristique donnée par un seul arbre de décision. Jetons un coup d'œil à l'importance de la fonctionnalité donnée par différents algorithmes à différentes fonctionnalités:
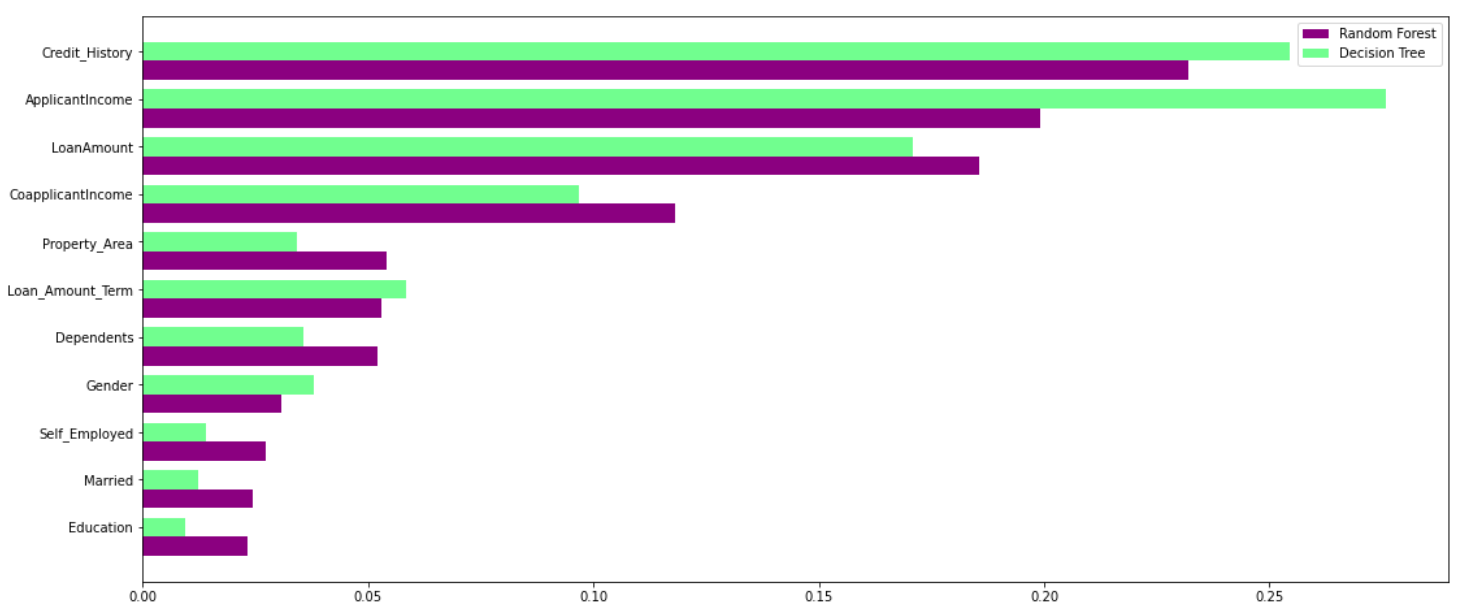
Comme vous pouvez le voir clairement sur le graphique ci-dessus, le modèle d'arbre de décision accorde une grande importance à un ensemble particulier de caractéristiques. Mais la forêt aléatoire choisit des caractéristiques au hasard pendant le processus de formation. Donc, ne repose pas fortement sur un ensemble spécifique de fonctionnalités. Ceci est une particularité de la forêt aléatoire sur les arbres ensachés. Vous pouvez en savoir plus sur le sac.classificateur d'arborescence ici.
Donc, la forêt aléatoire peut mieux généraliser les données. Cette sélection aléatoire de caractéristiques rend la forêt aléatoire beaucoup plus précise qu'un arbre de décision..
Ensuite, Lequel devrais-je choisir: arbre de décision ou forêt aléatoire?
Random Forest convient aux situations où nous avons un grand ensemble de données et l'interprétabilité n'est pas une préoccupation majeure.
Les arbres de décision sont beaucoup plus faciles à interpréter et à comprendre. Puisqu'une forêt aléatoire combine plusieurs arbres de décision, devient plus difficile à interpréter. Voici la bonne nouvelle: il n'est pas impossible d'interpréter une forêt aléatoire. Voici un article qui parle de interpréter les résultats d'un modèle de forêt aléatoire:
En outre, Random Forest a un temps de formation plus élevé qu'un seul arbre de décision. Vous devez en tenir compte car au fur et à mesure que nous augmentons le nombre d'arbres dans une forêt aléatoire, le temps qu'il faut pour former chacun d'eux augmente également. Cela peut souvent être crucial lorsque vous travaillez avec un délai serré sur un projet d'apprentissage automatique..
Mais je dirai ceci: malgré l'instabilité et la dépendance à un ensemble particulier de caractéristiques, les arbres de décision sont vraiment utiles car ils sont plus faciles à interpréter et plus rapides à former. Toute personne ayant très peu de connaissances en science des données peut également utiliser des arbres de décision pour prendre des décisions rapides basées sur les données..
Remarques finales
C'est essentiellement ce que vous devez savoir dans l'arbre de décision face au débat sur la foresterie aléatoire.. Cela peut devenir difficile lorsque vous débutez dans l'apprentissage automatique, mais cet article aurait dû clarifier les différences et les similitudes pour vous.
Vous pouvez me joindre avec vos questions et réflexions dans la section commentaire ci-dessous.





