Cet article a été publié dans le cadre du Blogathon sur la science des données
1. Cibler
L'objectif de cet article est de prévoir les prix des vols compte tenu des différents paramètres. Les données utilisées dans cet article sont accessibles au public sur Kaggle. Ce sera un problème de régression puisque la variable cible ou dépendante est le prix (valeur numérique continue).
2. introduction
Les compagnies aériennes utilisent des algorithmes complexes pour calculer les prix des vols compte tenu des diverses conditions présentes à ce moment particulier.. Ces méthodes prennent en compte les facteurs financiers, marketing et social pour prédire les prix des vols.
Aujourd'hui, le nombre de personnes utilisant des vols a considérablement augmenté. Il est difficile pour les compagnies aériennes de maintenir les prix, puisque les prix changent dynamiquement en raison de conditions différentes. C'est pourquoi nous allons essayer d'utiliser l'apprentissage automatique pour résoudre ce problème.. Cela peut aider les compagnies aériennes en prédisant les prix qu'elles peuvent maintenir. Il peut également aider les clients à prévoir les prix futurs des vols et à planifier leur voyage en conséquence..
3. Données utilisées
Les données Kaggle ont été utilisées, qui est une plate-forme d'accès gratuit pour les scientifiques des données et les passionnés d'apprentissage automatique.
La source: https://www.kaggle.com/nikhilmittal/flight-fare-prediction-mh
Nous utilisons jupyter-notebook pour exécuter la tâche de prédiction du prix des vols.
4. Analyse de données
La procédure d'extraction d'informations à partir de données brutes données est appelée analyse de données. Ici, nous utiliserons eda module préparation des données bibliothèque pour faire cette étape.
à partir de dataprep.eda importer create_report
importer des pandas au format pd
cadre de données = pd.read_excel("../sortie/Data_Train.xlsx")
Creer un rapport(trame de données)
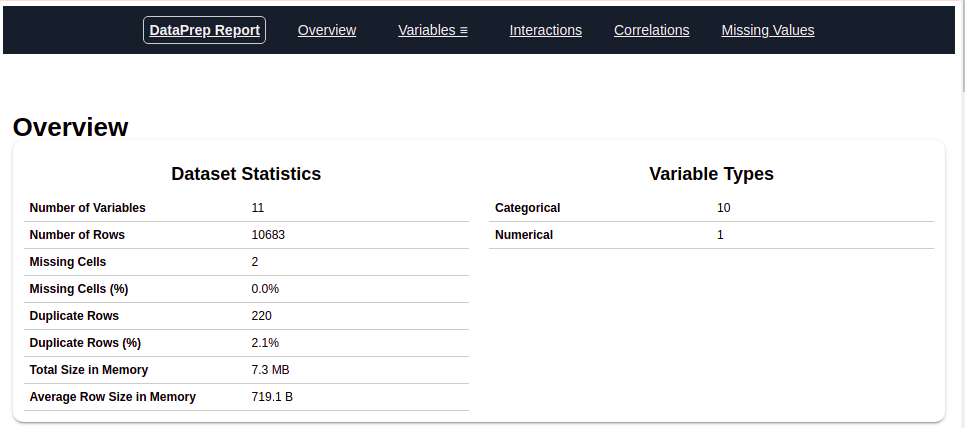
Après avoir exécuté le code ci-dessus, vous obtiendrez un rapport comme indiqué dans la figure ci-dessus. Ce rapport contient plusieurs sections ou onglets. La section ‘Description générale’ de ce rapport nous fournit toutes les informations de base sur les données que nous utilisons. Pour les données actuelles que nous utilisons, nous avons les informations suivantes:
Nombre de variables = 11
Nombre de lignes = 10683
Numéro de type catégoriel caractéristique = 10
Numéro de type numérique caractéristique = 1
Lignes dupliquées = 220, etc.
Explorons les autres sections du rapport une par une.
4.1 Variables
Après avoir sélectionné la section des variables, vous obtiendrez des informations comme indiqué dans les figures suivantes.
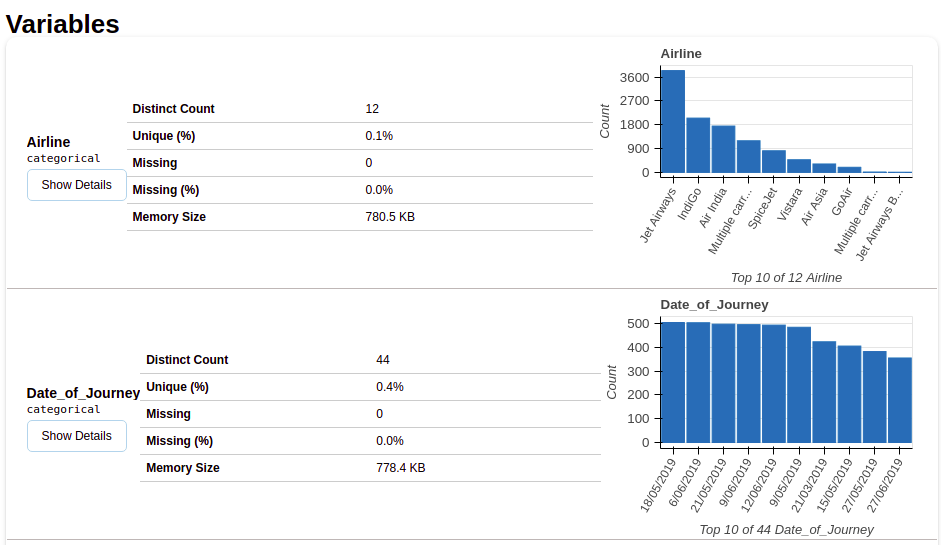
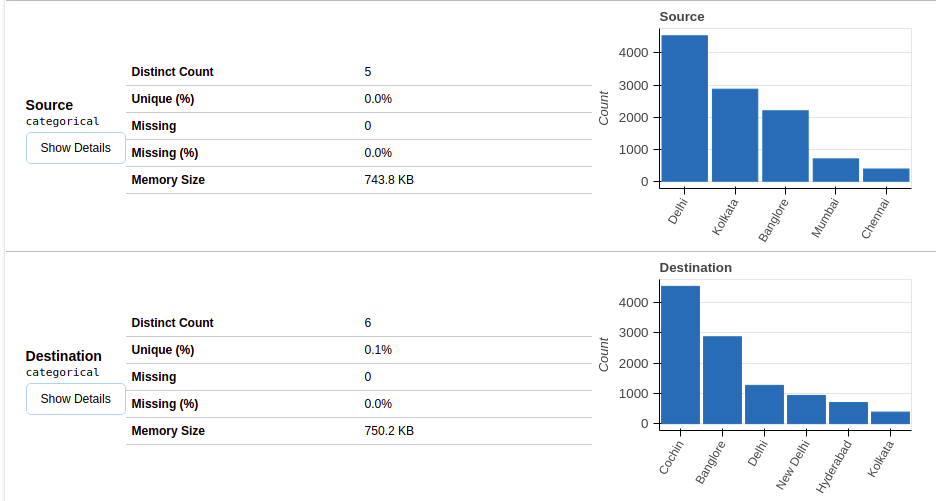
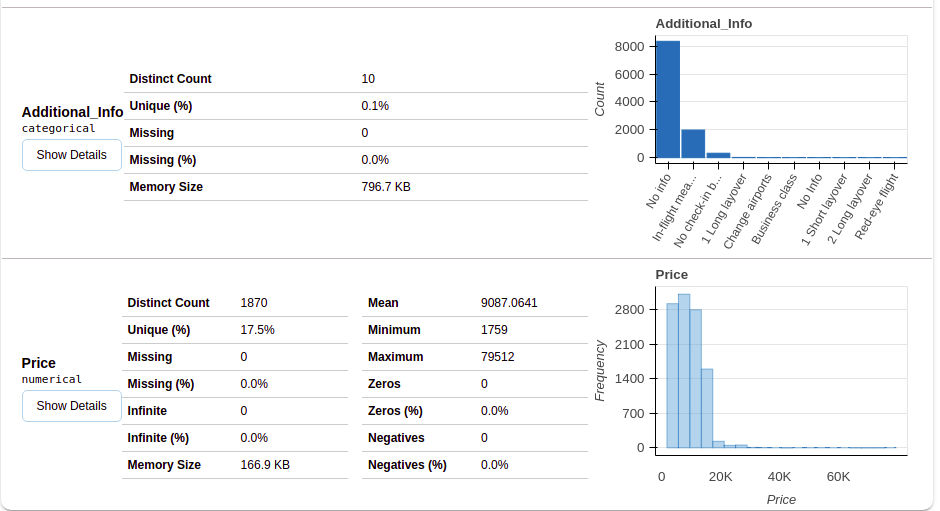
Cette section fournit le type de chaque variable ainsi qu'une description détaillée de la variable..
4.2 Valeurs manquantes
Cette section a plusieurs façons d'analyser les valeurs manquantes dans les variables. Nous discuterons des trois méthodes les plus utilisées, graphique à barres, spectre et carte thermique. Explorons chacun un par un.
4.2.1 Graphique à barres
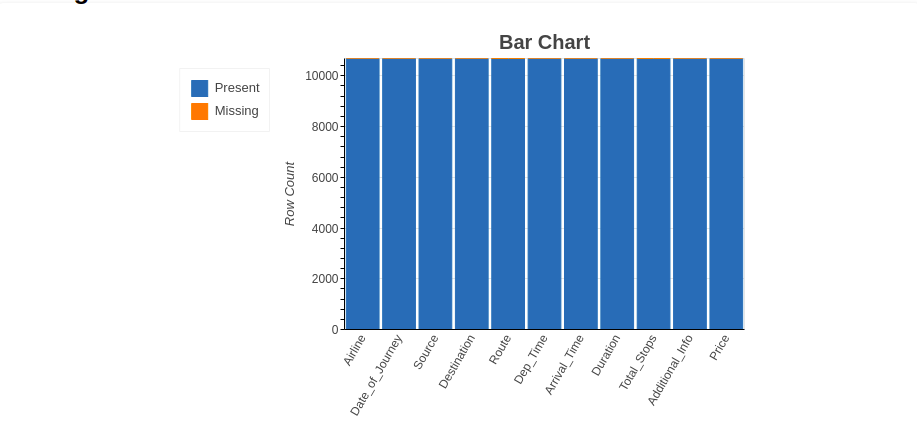
La méthode du graphique à barres montre le « nombre de valeurs manquantes et présentes’ dans chaque variable dans une couleur différente.
4.2.2 Spectre
La méthode du spectre montre le pourcentage de valeurs manquantes dans chaque variable.
4.2.3 Carte de chaleur
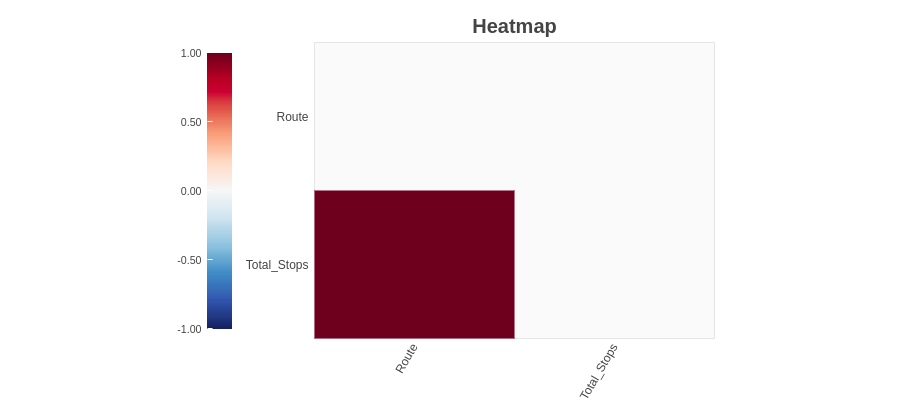
La méthode de la carte thermique montre les variables qui ont des valeurs manquantes en termes de corrélation. Depuis « Route’ et 'Total_Paradas’ sont fortement corrélées, les deux ont des valeurs manquantes.
Comme on peut le constater, les 'variables de chemin’ et 'Total_Paradas’ avoir des valeurs manquantes. Étant donné que nous n'avons trouvé aucune information sur les valeurs manquantes à partir de la méthode du graphique à barres du spectre, mais nous trouvons des variables de valeur manquante en utilisant la méthode de la carte thermique. Combiner ces informations, on peut dire que les variables 'Route’ et 'Total_Paradas’ ont des valeurs manquantes mais sont très faibles.
5. Préparation des données
Avant de commencer la préparation des données, examinons d'abord les données.
dataframe.head()

Comme nous l'avons vu dans l'analyse des données, il y a 11 variables dans les données données. Ci-dessous la description de chaque variable.
Compagnie aérienne: Nom de la compagnie aérienne utilisée pour voyager
Date_de_Voyage: Date à laquelle une personne a voyagé
La source: Lieu de départ du vol
destin: Lieu de fin de vol
Route: Contient des informations sur le lieu de départ et d'arrivée du voyage dans le format standard utilisé par les compagnies aériennes.
Dept_Time: Heure de départ du vol depuis le point de départ
Heure d'arrivée: Heure d'arrivée du vol à destination
Durée: Durée du vol en heures / minutes
Total_Arrêts: Nombre total d'escales effectuées par le vol avant d'atterrir à destination.
Information complémentaire: Afficher toute information supplémentaire sur un vol
Prix: Prix du vol
Quelques observations sur certaines variables:
1. ‘Prix« Sera notre variable dépendante et toutes les variables restantes peuvent être utilisées comme variables indépendantes.
2. ‘Total_Arrêts'Peut être utilisé pour déterminer si le vol était direct ou en correspondance.
5.1 Gestion des valeurs manquantes
Comment nous avons découvert, les 'variables de chemin’ et 'Total_Paradas’ ont des valeurs manquantes très faibles dans les données. Voyons maintenant le pourcentage de valeurs manquantes dans les données.
(dataframe.isnull().somme()/dataframe.shape[0])*100
Production :
Compagnie aérienne 0.000000 Date_de_Voyage 0.000000 La source 0.000000 Destination 0.000000 Route 0.009361 Dept_Time 0.000000 Heure d'arrivée 0.000000 Durée 0.000000 Total_Arrêts 0.009361 Information additionnelle 0.000000 Prix 0.000000 dtype: float64
Comme on peut le constater, 'Route’ y 'Total_Stops’ ils ont tous les deux 0.0094% des valeurs perdues. Dans ce cas, il vaut mieux supprimer les valeurs manquantes.
dataframe.dropna(inplace= Vrai) dataframe.isnull().somme()
Production :
Compagnie aérienne 0 Date_de_Voyage 0 La source 0 Destination 0 Route 0 Dept_Time 0 Heure d'arrivée 0 Durée 0 Total_Arrêts 0 Information additionnelle 0 Prix 0 dtype: int64
Maintenant, nous n'avons pas de valeur perdue.
5.2 Gestion des variables de date et d'heure
Tenemos « Date_of_Voyage », une variable de type date et’ Dept_Time',’ Arrival_Time 'qui capture les informations de temps.
Nous pouvons extraire ‘Journey_day’ y 'Voyage_Mois’ de la variable 'Date_of_Voyage'. “Journée de voyage” indique le jour du mois où le voyage a commencé.
trame de données["Journey_day"] = pd.to_datetime(dataframe.Date_of_Journey, format="%j/%m/%Y").jour.dt trame de données["Voyage_mois"] = pd.to_datetime(trame de données["Date_de_Voyage"], format = "%j/%m/%Y").dt.mois trame de données.tomber(["Date_de_Voyage"], axe = 1, en place = vrai)
de la même manière, nous pouvons extraire ‘Heure de départ’ et « Heure de départ’ ainsi que « Heure d'arrivée et minute d'arrivée’ des variables 'Time_dep.’ Et 'Heure d'arrivée’ respectivement.
trame de données["Dép_heure"] = pd.to_datetime(trame de données["Dept_Time"]).dt.heure trame de données["Dép_min"] = pd.to_datetime(trame de données["Dept_Time"]).dt.minute trame de données.tomber(["Dept_Time"], axe = 1, en place = vrai)
trame de données["Heure_d'arrivée"] = pd.to_datetime(dataframe.Arrival_Time).dt.heure trame de données["Arrivée_min"] = pd.to_datetime(dataframe.Arrival_Time).dt.minute trame de données.tomber(["Heure d'arrivée"], axe = 1, en place = vrai)
Nous avons également des informations sur la durée de la variable 'Durée'. Cette variable contient des informations combinées d'heures et de minutes de durée.
Nous pouvons extraire ‘Duration_hours’ et 'Durée_minutes’ séparément de la variable 'Durée'.
def get_duration(X):
x=x.split(' ')
heures=0
minutes=0
si len(X)==1:
x=x[0]
si x[-1]=='h':
heures=int(X[:-1])
autre:
minutes=int(X[:-1])
autre:
heures=int(X[0][:-1])
minutes=int(X[1][:-1])
heures de retour,minutes
trame de données['Durée_heures']=dataframe.Duration.apply(lambda x:get_duration(X)[0])
trame de données['Durée_mins']=dataframe.Duration.apply(lambda x:get_duration(X)[1])
dataframe.drop(["Durée"], axe = 1, en place = vrai)
5.3 Traitement des données catégorielles
Compagnie aérienne, Origine, destin, Route, Total_Arrêts, Les informations supplémentaires sont les variables catégorielles que nous avons dans nos données. Traitons chacun un par un.
Variable de compagnie aérienne
Voyons comment la variable Compagnie aérienne est liée à la variable Prix.
importer seaborn comme sns
sns.set()
sns.catplot(y = "Prix", x = "Compagnie aérienne", données = train_data.sort_values("Prix", ascendant = Faux), genre ="boxe", hauteur = 6, aspect = 3)
plt.show()
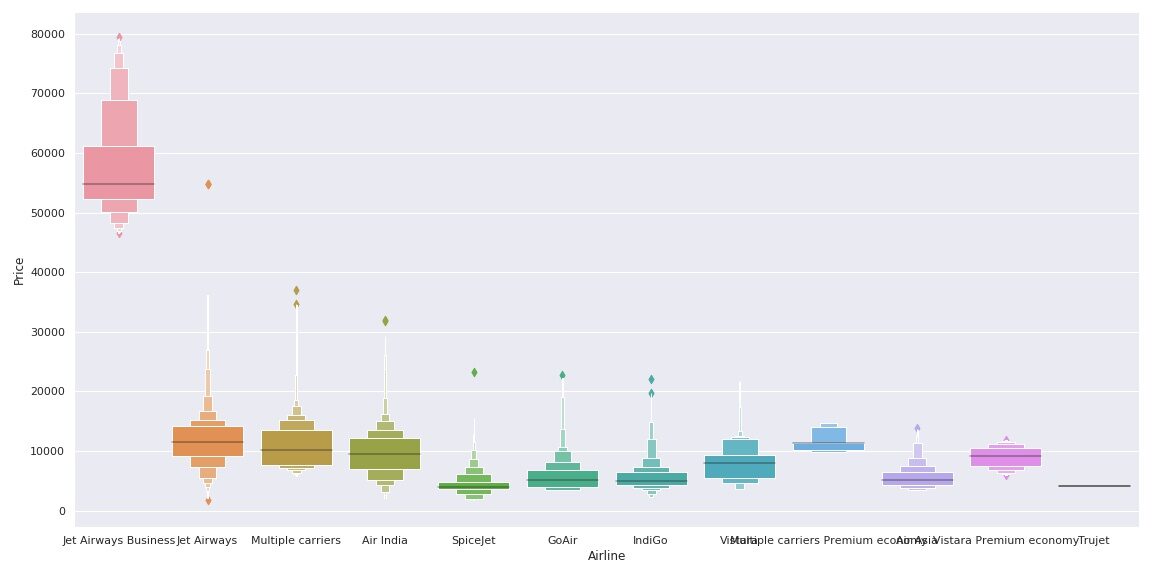
Comme nous pouvons le voir, le nom de la compagnie aérienne est important. « Affaires JetAirways’ a la gamme de prix la plus élevée. Le prix des autres compagnies aériennes varie également.
Depuis le Compagnie aérienne la variable est Données catégorielles nominales (Il n'y a aucun ordre d'aucune sorte dans les noms des compagnies aériennes) nous utiliserons encodage à chaud pour gérer cette variable.
Compagnie aérienne = dataframe[["Compagnie aérienne"]] Compagnie aérienne = pd.get_dummies(Compagnie aérienne, drop_first= Vrai)
Les données de la compagnie aérienne’ encodés en One-Hot sont stockés dans la variable Airline comme indiqué dans le code ci-dessus.
Variable source et destination
Encore, les 'Variables sources’ et « Destination’ sont des données catégorielles nominales. Nous utiliserons à nouveau l'encodage One-Hot pour gérer ces deux variables.
Source = cadre de données[["La source"]] Source = pd.get_dummies(La source, drop_first= Vrai) Destination = train_data[["Destination"]] Destination = pd.get_dummies(Destination, drop_first = Vrai)
Variable de chemin
La variable de chemin représente le chemin du voyage. Étant donné que la variable 'Total_Stops’ capte les informations si le vol est direct ou connecté, J'ai décidé d'éliminer cette variable.
dataframe.drop(["Route", "Information additionnelle"], axe = 1, en place = vrai)
Variable Total_Arrêts
trame de données["Total_Arrêts"].unique()
Production:
déployer(['sans arrêt', '2 arrêts', '1 arrêt', '3 arrêts', '4 arrêts'],
type=objet)
Ici, sans escale signifie 0 Balance, ce que signifie vol direct. de la même manière, le sens des autres valeurs est évident. On voit que c'est un Données catégorielles ordinales alors on utilisera Encodeur d'étiquette ici pour gérer cette variable.
dataframe.replace({"sans arrêt": 0, "1 arrêter": 1, "2 s'arrête": 2, "3 s'arrête": 3, "4 s'arrête": 4}, en place = vrai)
Variable Additional_Info
dataframe.Additional_Info.unique()
Production:
déployer(['Pas d'information', « Repas en vol non inclus »,
« Pas de bagage en soute inclus », '1 Courte escale', 'Pas d'information',
'1 Longue escale', « Changer d'aéroport », 'Classe affaire',
'Vol des yeux rouges', '2 Longue escale'], type=objet)
Comme nous pouvons le voir, cette fonctionnalité capture des informations pertinentes qui peuvent affecter de manière significative le prix du vol. Les valeurs ‘Aucune information’ sont également répétées.. Gérons cela d'abord.
trame de données['Information additionnelle'].remplacer({"Pas d'information": 'Pas d'information'}, en place = vrai)
Maintenant bien, cette variable est également une donnée catégorielle nominale. Utilisons One-Hot Encoding pour gérer cette variable.
Add_info = cadre de données[["Information additionnelle"]] Add_info = pd.get_dummies(Ajouter_info, drop_first = Vrai)
5.4 Bloc de données final
Nous allons maintenant créer le bloc de données final en concaténant toutes les fonctionnalités codées par balise et One-hot dans le bloc de données d'origine.. Nous supprimerons également les variables d'origine avec lesquelles nous avons préparé de nouvelles variables encodées.
cadre de données = pd.concat([trame de données, Compagnie aérienne, La source, Destination,Ajouter_info], axe = 1) dataframe.drop(["Compagnie aérienne", "La source", "Destination","Information additionnelle"], axe = 1, en place = vrai)
Voyons le nombre de variables finales que nous avons dans le bloc de données.
dataframe.shape[1]
Production:
38
Ensuite, avoir 38 variables dans le bloc de données final, y compris la variable dépendante 'Prix'. Il y a seulement 37 variables pour la formation.
6. Construction de maquettes
X=dataframe.drop('Prix',axe=1)
y = cadre de données['Prix']
#fractionnement train-test
de sklearn.model_selection importer train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Oui, taille_test = 0.2, état_aléatoire = 42)
6.1 Application de prédiction paresseuse
L'un des problèmes de l'exercice de modélisation est “Comment décider quel algorithme d'apprentissage automatique appliquer?”
C'est là qu'intervient Lazy Prediction.. Lazy Prediction est une bibliothèque d'apprentissage automatique disponible en Python qui peut rapidement nous fournir les performances de plusieurs classifications standard ou modèles de régression sur plusieurs matrices de performances..
Voyons voir comment ça fonctionne ...
Comment nous travaillons sur une tâche de régression, nous utiliserons des modèles de régresseurs.
de lazypredict.Import supervisé LazyRegressor reg = LazyRegressor(verbeux=0, ignore_warnings=Faux, custom_metric=Aucun) des modèles, prédictions = reg.fit(x_train, x_test, y_train, y_test) modeles.head(10)
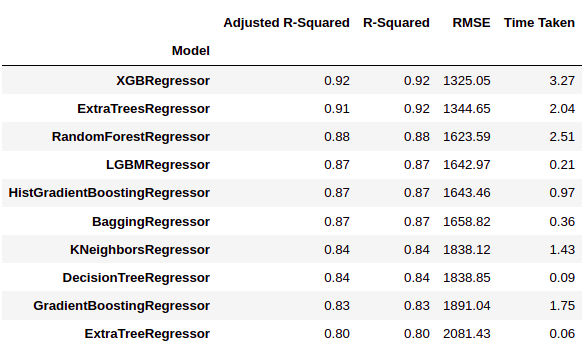
Comme nous pouvons le voir, LazyPredict nous donne les résultats de plusieurs modèles dans plusieurs matrices de performances. Dans la figure ci-dessus, nous avons montré les dix meilleurs modèles.
Ici ‘XGBRegressor’ et 'ExtraTreesRegressor’ surpassent considérablement les autres modèles. Il faut beaucoup de temps de formation par rapport aux autres modèles. Dans cette étape, nous pouvons choisir la priorité si nous voulons “conditions météorologiques” O “performance”.
Nous avons décidé de choisir “performance” sur le temps de formation. Nous allons donc former 'XGBRegressor et visualiser les résultats finaux.
6.2 Formation de modèle
à partir de xgboost importer XGBRegressor modèle = XGBRegressor() model.fit(x_train,y_train)
Production:
XGBRégresseur(base_score=0.5, booster ="gbtree", colsample_bylevel = 1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type="Gain", interaction_contraintes="",
taux_apprentissage=0.300000012, max_delta_step=0, profondeur_max=6,
min_child_weight=1, manquant = nan, monotone_contraintes="()",
n_estimateurs = 100, n_emplois=0, num_parallel_tree=1, état_aléatoire=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, sous-échantillon=1,
tree_method='exact', valider_paramètres=1, verbosité=Aucun)
Vérifions les performances du modèle …
y_pred = model.predict(x_test)
imprimer('Score d'entraînement :',model.score(x_train, y_train))
imprimer('Score du test :',model.score(x_test, y_test))
Production:
Score d'entraînement : 0.9680428701701702 Score du test : 0.918818721300552
Comme nous pouvons le voir, le score du modèle est assez bon. Visualisons les résultats de quelques prédictions.
nombre_d'observations=50
x_ax = plage(longueur(y_test[:nombre_d'observations]))
plt.plot(x_ax, y_test[:nombre_d'observations], étiquette="original")
plt.plot(x_ax, y_pred[:nombre_d'observations], étiquette="prédit")
plt.titre("Test de prix de vol et données prédites")
plt.xlabel('Numéro d'observation')
plt.ylabel('Prix')
plt.légende()
plt.show()
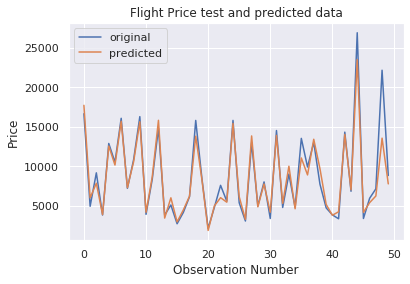
Comme on peut le voir sur la figure précédente, les prédictions du modèle et les prix d'origine se chevauchent. Ce résultat visuel confirme le score élevé du modèle que nous avons vu précédemment.
7. conclusion
Dans cet article, nous avons vu comment appliquer la bibliothèque Laze Prediction pour choisir le meilleur algorithme d'apprentissage automatique pour la tâche à accomplir.
Lazy Prediction permet d'économiser du temps et des efforts pour créer un modèle d'apprentissage automatique en fournissant des performances de modèle et du temps de formation. On peut choisir n'importe lequel selon la situation en question.
Il peut également être utilisé pour créer un ensemble de modèles d'apprentissage automatique. Il existe de nombreuses façons d'utiliser les fonctionnalités de la bibliothèque LazyPredict.
J'espère que cet article vous a aidé à comprendre les approches d'analyse de données, préparation et modélisation des données de manière beaucoup plus simple.
Contactez la section commentaires en cas de question.
Merci et bonne journée.. 🙂
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





