Considérez le fait suivant:
Facebook compte actuellement plus d'un milliard d'utilisateurs actifs chaque mois
Prenons quelques secondes pour réfléchir aux informations que Facebook stocke habituellement sur ses utilisateurs. Une partie de cela est:
- Données démographiques de base (par exemple, date de naissance, sexe, situation actuelle, emplacement précédent, l'universitè)
- Pacte d'activités et mises à jour des utilisateurs (ses photos, commentaires, J'aime, applications que vous avez utilisées, jeux auxquels vous avez joué, messages, bavarder, etc.)
- Votre réseau social (tes amis, leurs cercles, comment êtes-vous apparenté, etc.)
- Intérêts des utilisateurs (Lire des livres, films vus, endroits, etc.)

En utilisant ceci et beaucoup d'autres informations (par exemple, sur quoi un utilisateur a cliqué, qu'as-tu lu et combien de temps as-tu passé dessus), Facebook fait ce qui suit en temps réel:
- Recommandez des personnes que vous connaissez et des liens mutuels avec elles.
- Utilisez vos activités actuelles et passées pour comprendre ce qui vous intéresse
- Vous contacter avec des mises à jour, activités et annonces qui pourraient vous intéresser davantage.
En même temps que ces, il y a des activités à proximité (mis à jour par lots et non en temps réel) comme le nombre de personnes qui parlent d'une page, personnes atteintes en une semaine.
À présent, imaginez le type d'infrastructure de données nécessaire pour faire fonctionner Facebook, la taille de votre centre de données, la puissance de traitement requise pour répondre aux besoins des utilisateurs. L'ampleur peut être excitante ou terrifiante, selon la façon dont vous le regardez.
La prochaine infographie d'IBM met en évidence l'ampleur des exigences / traitement des données pour certaines institutions similaires:

Ce type de taille et d'échelle n'a été entendu par aucun analyste jusqu'à il y a quelques années et l'infrastructure de données dans laquelle certaines de ces institutions avaient investi n'était pas préparée à gérer cette échelle.. C'est ce qu'on appelle souvent un problème de Big Data..
Ensuite, Qu'est-ce que le Big Data?
Les mégadonnées sont des données trop volumineuses, complexe et dynamique pour tout outil de données conventionnel à capturer, boutique, gérer et analyser. Les outils traditionnels ont été conçus en tenant compte de l'échelle. Par exemple, lorsqu'une organisation souhaite investir dans une solution de Business Intelligence, partenaire de mise en œuvre viendrait, étudier les besoins de l'entreprise, puis créer une solution pour répondre à ces exigences.
Si les besoins de cette organisation augmentent avec le temps ou si vous souhaitez exécuter une analyse plus granulaire, a dû réinvestir dans l'infrastructure de données. Le coût des ressources impliquées dans la mise à l'échelle des ressources qui sont régulièrement utilisées pour augmenter de façon exponentielle. En même temps, il y aurait une limite à la taille à laquelle il pourrait évoluer (par exemple, taille de la machine, CPU, RAM, etc.). Ces systèmes traditionnels ne pouvaient pas prendre en charge l'échelle requise par certaines des sociétés Internet..
En quoi le big data est-il différent des données traditionnelles?
Heureusement ou malheureusement, il n'y a pas de limite de taille / paramétrique pour choisir si les données sont « Big Data » ou non. Les mégadonnées sont généralement caractérisées sur la base de ce qui est communément appelé 3 Vs:
- Le volume – Actuellement, il y a des institutions qui produisent des téraoctets de données par jour. Avec des données croissantes, vous devrez laisser certaines données non analysées, si vous souhaitez utiliser des outils traditionnels. UNE mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que el tamaño de los datos aumente aún más, laissera de plus en plus de données non analysées. Cela signifie laisser de la valeur sur la table. Il contient toutes les informations sur ce que le client fait et dit, Mais je ne peux pas comprendre! – un signe certain que vous traitez avec des données plus volumineuses que celles prises en charge par votre système.
- Variété – Bien que le volume ne soit que le début, la variété est ce qui rend les outils traditionnels très difficiles. Les outils traditionnels fonctionnent mieux avec des données structurées. Exiger que les données aient une structure et un format particuliers pour avoir un sens. Malgré cela, le flot de données des e-mails, commentaires des clients, forums de médias sociaux, le parcours client sur le portail web et les centres d'appels ne sont pas structurés par nature ou, Dans le meilleur des cas, ils sont semi-structurés.
- La vitesse – La vitesse à laquelle les données sont générées est aussi critique que les deux autres facteurs. La rapidité avec laquelle une entreprise peut analyser les données deviendrait à terme un avantage concurrentiel pour elle.. C'est sa vitesse d'analyse qui permet à Google de prédire la localisation des patients grippés en temps quasi réel. Pour cela, si vous ne pouvez pas analyser les données à une vitesse plus rapide que votre flux d'entrée, vous pourriez avoir besoin d'une solution Big Data.
Individuellement, chacun de ces V peut toujours être corrigé à l'aide de solutions traditionnelles. Par exemple, si la plupart de vos données sont structurées, vous pouvez toujours obtenir de 80% Al 90% de valeur commerciale grâce aux outils traditionnels. Malgré cela, si vous faites face à un défi avec les trois V, vous saurez qu'il s'agit « Big Data ».

Quand avez-vous besoin d'une solution Big Data?
Bien que le 3 V vous dira si vous avez affaire à du « big data » ou non, si vous avez besoin ou non d'une solution big data selon vos besoins. Vous trouverez ci-dessous des scénarios dans lesquels les solutions Big Data sont intrinsèquement plus adaptées:
- Lorsqu'il s'agit de données volumineuses semi-structurées ou non structurées provenant de plusieurs sources
- Vous devez analyser toutes vos données et ne pouvez pas les échantillonner.
- La procédure est de nature itérative (par exemple, recherches dans le moteur de recherche Google, rechercher des graphiques sur Facebook)
Comment fonctionne la réponse Big Data?
Bien que les limites des solutions traditionnelles soient claires, Comment les solutions Big Data les résolvent-elles? Les solutions Big Data fonctionnent sur une architecture fondamentalement différente qui repose sur les caractéristiques suivantes (illustratif ci-dessous):
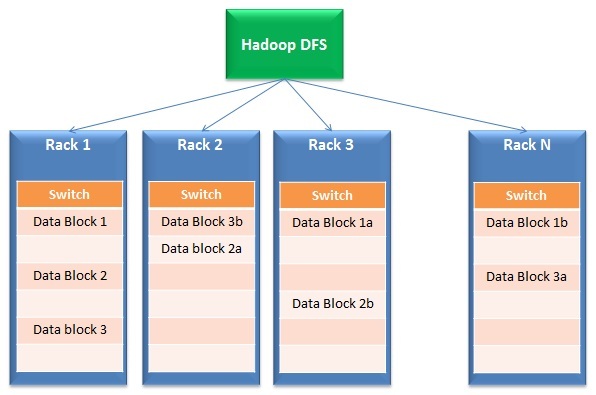
- Distribution de données et traitement parallèle: Les solutions Big Data fonctionnent sur le stockage distribué et le traitement parallèle. Brièvement, les fichiers sont divisés en plusieurs petits blocs et stockés dans différents lecteurs (appels dans les coulisses). Après, le traitement s'effectue en parallèle dans ces blocs et les résultats sont à nouveau fusionnés. La première partie de l'opération est généralement appelée Système de fichiers distribuéUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. En outre, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... (DFS) tandis que la deuxième partie s'appelle Petite carte.
- Tolérance à l'échec: Par la nature de sa conception, Big Data Response a une redondance intégrée. Par exemple, Hadoop crée 3 copies de chaque bloc de données dans au moins 2 étagères. Pour cela, même si un rack complet tombe en panne ou n'est pas activé, la réponse fonctionne toujours. Pourquoi est-il incorporé? Cette fonctionnalité permet aux solutions Big Data de s'adapter même à du matériel d'entrée de gamme peu coûteux au lieu de disques SAN coûteux..
- Évolutivité et flexibilité: C'est la genèse du paradigme complet des solutions big data. Puede agregar o quitar racks fácilmente del grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois.... sin preocuparse por el tamaño para el que se diseñó esta solución.
- Rentabilité: En raison de l'utilisation de matériel de base, le coût de création de cette infrastructure est beaucoup moins élevé que l'achat de serveurs coûteux avec des disques résistants aux pannes (par exemple, SAN)
En résumé, Et si tout était dans le cloud?
Bien que développer une architecture big data soit rentable, trouver les bonnes ressources est difficile, ce qui augmente le coût de mise en œuvre.
Imaginez une situation où un fournisseur de services cloud s'occupe également de tous vos problèmes informatiques / Infrastructure. Vous vous concentrez sur la réalisation d'analyses et la fourniture de résultats à l'entreprise au lieu d'organiser les racks et de vous soucier de l'étendue de leur utilisation.
Il ne vous reste plus qu'à payer selon votre consommation. Actuellement, des solutions de bout en bout sont disponibles sur le marché, où vous pouvez non seulement stocker vos données dans le cloud, mais aussi les consulter et les analyser dans le cloud. Vous pouvez interroger des téraoctets de données en quelques secondes et laisser à quelqu'un d'autre le soin de s'occuper de cette infrastructure !!
Bien que j'aie fourni un aperçu des solutions Big Data, cela ne couvre en aucun cas tout le spectre. Le but est de commencer le voyage et de se préparer à la révolution qui est en cours..





