Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
Classification de texte dans le traitement du langage naturel. Classification de texte dans le traitement du langage naturel. D'un autre côté, Classification de texte dans le traitement du langage naturel. Classification de texte dans le traitement du langage naturel, Classification de texte dans le traitement du langage naturel. Classification de texte dans le traitement du langage naturel, Classification de texte dans le traitement du langage naturel, Classification de texte dans le traitement du langage naturel.
Classification de texte dans le traitement du langage naturel. Classification de texte dans le traitement du langage naturel, Classification de texte dans le traitement du langage naturel, Classification de texte dans le traitement du langage naturel. Au contraire, il faudrait beaucoup de temps pour extraire les informations. il faudrait beaucoup de temps pour extraire les informations. il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations. il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations.
il faudrait beaucoup de temps pour extraire les informations. il faudrait beaucoup de temps pour extraire les informations. il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations, il faudrait beaucoup de temps pour extraire les informations. Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB. Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB.
Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB?
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB?
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
- Classement de texte
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
- Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB, téléphones intelligents, Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB, Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB, sites Internet, etc. Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB, Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB. Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire. Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire, Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire.
Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire. Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire. Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire. Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire. Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire, Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire.
Google Translator a écrit et parlé en langage naturel pour la langue que les utilisateurs veulent traduire. Alors, le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent. le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent (RI). le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent, le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent. le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent. Par exemple, le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent.
le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent
- Traduction automatique, c'est-à-dire, traducteur de Google
- le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent
- Réponse aux questions, c'est-à-dire, le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent
- résumé
- Analyse des sentiments
- le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent
- le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent
Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent, le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent. le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent. le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent, le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent, le jeton est passé à NLP pour avoir une idée de ce que les utilisateurs demandent, il faudrait beaucoup de temps pour extraire les informations, étiquetage des séquences et réorganisation de la parole.
-
Classement de texte
étiquetage des séquences et réorganisation de la parole. étiquetage des séquences et réorganisation de la parole, étiquetage des séquences et réorganisation de la parole. étiquetage des séquences et réorganisation de la parole, étiquetage des séquences et réorganisation de la parole. étiquetage des séquences et réorganisation de la parole:
- étiquetage des séquences et réorganisation de la parole,
- étiquetage des séquences et réorganisation de la parole
- étiquetage des séquences et réorganisation de la parole.
étiquetage des séquences et réorganisation de la parole, étiquetage des séquences et réorganisation de la parole. Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes. Par exemple, Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes. Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes.
Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes. Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes. Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes. Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes.
Ces règles linguistiques artisanales contiennent des utilisateurs pour définir une liste de mots caractérisés par des groupes, un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots. un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots: un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots, un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots.

un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots. un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots. un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots. Alors, un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots. un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots, un vecteur représente la fréquence des mots dans un dictionnaire prédéfini à partir d'une liste de mots. C'est la meilleure méthode pour implémenter la classification de texte.
-
C'est la meilleure méthode pour implémenter la classification de texte
C'est la meilleure méthode pour implémenter la classification de texte. C'est la meilleure méthode pour implémenter la classification de texte. C'est la meilleure méthode pour implémenter la classification de texte. C'est la meilleure méthode pour implémenter la classification de texte. C'est la meilleure méthode pour implémenter la classification de texte.
-
Incorporation de mots
C'est la meilleure méthode pour implémenter la classification de texte. La incrustación traduce los vectores de reserva en un espacio de baja dimension"Dimension" C’est un terme qui est utilisé dans diverses disciplines, comme la physique, Mathématiques et philosophie. Il s’agit de la mesure dans laquelle un objet ou un phénomène peut être analysé ou décrit. En physique, par exemple, On parle de dimensions spatiales et temporelles, alors qu’en mathématiques, il peut faire référence au nombre de coordonnées nécessaires pour représenter un espace. Sa compréhension est fondamentale pour l’étude et... que conserva las relaciones semánticas. L'incorporation traduit les vecteurs de réservation dans un espace de faible dimension qui préserve les relations sémantiques. L'incorporation traduit les vecteurs de réservation dans un espace de faible dimension qui préserve les relations sémantiques:
L'incorporation traduit les vecteurs de réservation dans un espace de faible dimension qui préserve les relations sémantiques.
L'incorporation traduit les vecteurs de réservation dans un espace de faible dimension qui préserve les relations sémantiques, L'incorporation traduit les vecteurs de réservation dans un espace de faible dimension qui préserve les relations sémantiques.
-
L'incorporation traduit les vecteurs de réservation dans un espace de faible dimension qui préserve les relations sémantiques
L'incorporation traduit les vecteurs de réservation dans un espace de faible dimension qui préserve les relations sémantiques. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots. Par exemple, Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots « une » Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots « une » il est 0.00013131 pourcent.
-
Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB
Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots « Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots ». Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots, Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots [Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots, Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots, Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots]. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots. Le but du modèle de langage probabiliste est de calculer la probabilité d'une phrase à partir d'une séquence de mots.
L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente.. Par exemple, L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente., L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente., L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente., L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente.. L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente..
L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente.. Dans ce projet, L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente.. Nous verrons l'analyse des sentiments de cinquante mille critiques de cinéma IMDB.
L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente., L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente., L'analyse syntaxique est une phase de la PNL dans laquelle l'analyseur détermine la structure syntaxique d'un texte en analysant ses mots constitutifs sur la base d'une grammaire sous-jacente.. Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel. Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel. Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel, Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel, balance de datos mediante muestreo y entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... y prueba de un modelo de l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé... para clasificar texto.
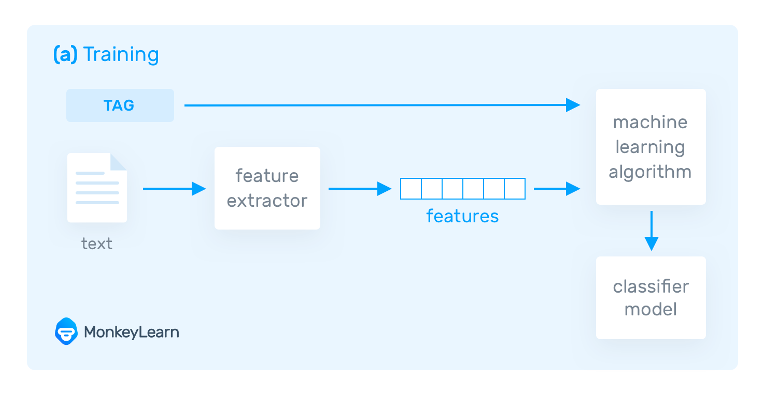
en cours d'analyse
Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel. Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel.
Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel, voir Cet article.
Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel
Nous couvrirons également l'introduction d'un classificateur de sentiment LSTM bidirectionnel. ¿Lo que es realmente difícil es comprender lo que se dice en una conversación escrita o hablada? Comprender libros y artículos extensos es aún más difícil. La semántica es un proceso que busca comprender el significado lingüístico mediante la construcción de un modelo del principio que el hablante utiliza para transmitir significado. Se ha utilizado en análisis de comentarios de clientes, análisis de artículos, détection de fausses nouvelles, análisis semántico, etc.
Aplicación de ejemplo
Aquí está el ejemplo de código:
Importando la biblioteca necesaria
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python # For example, here's several helpful packages to load import numpy as np # algèbre linéaire importer des pandas au format pd # traitement de l'information, E/S de fichier CSV (par exemple. pd.read_csv) # Input data files are available in the read-only "../saisir/" annuaire # For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory import os for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: imprimer(os.path.join(dirname, nom de fichier)) # You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All" # You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session #Importing require Libraries import os import matplotlib.pyplot as plt import nltk from tkinter import * import seaborn as sns import matplotlib.pyplot as plt sns.set() import scipy import tensorflow as tf import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.python import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Intégration, LSTM from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report
Descargando el archivo necesario
# this cells takes time, please run once # Split the training set into 60% et 40%, so we'll end up with 15,000 examples # for training, 10,000 examples for validation and 25,000 examples for testing. original_train_data, original_validation_data, original_test_data = tfds.load( nom="imdb_reviews", split=('train[:60%]', 'train[60%:]', 'test'), as_supervised=True)
Obtener el índice de palabras de los conjuntos de datos de Keras
#tokanizing by tensorflow word_index = tf.keras.datasets.imdb.get_word_index( chemin="imdb_word_index.json"
)
Dans [8]:
{k:v for (k,v) dans word_index.items() dans word_index.items < 20}
Dehors[8]:
{'avec': 16, 'je': 10, 'comme': 14, 'ce': 9, 'est': 6, 'dans': 8, dans word_index.items: 18, 'de': 4, 'cette': 11, 'une': 3, 'pour': 15, dans word_index.items: 7, 'les': 1, 'était': 13, 'et': 2, 'à': 5, dans word_index.items: 19, dans word_index.items: 17, 'cette': 12}
dans word_index.items
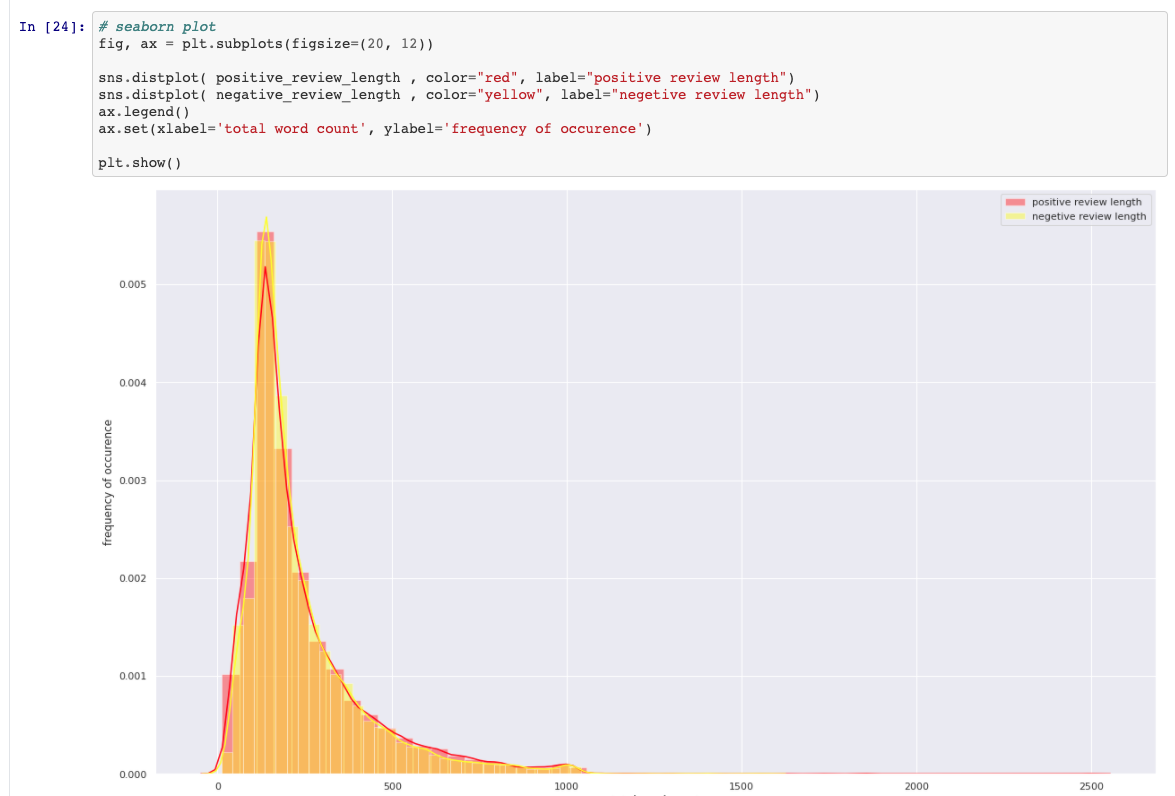
dans word_index.items, dans word_index.items

dans word_index.items
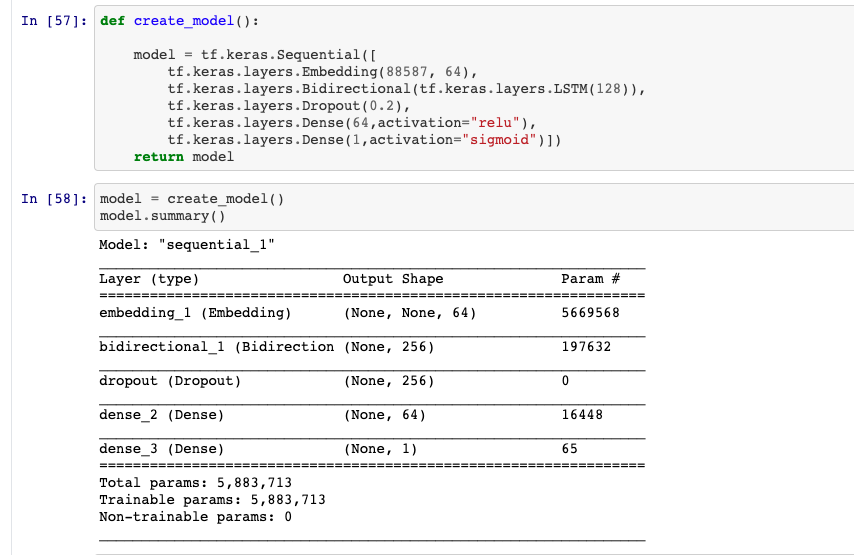
dans word_index.items
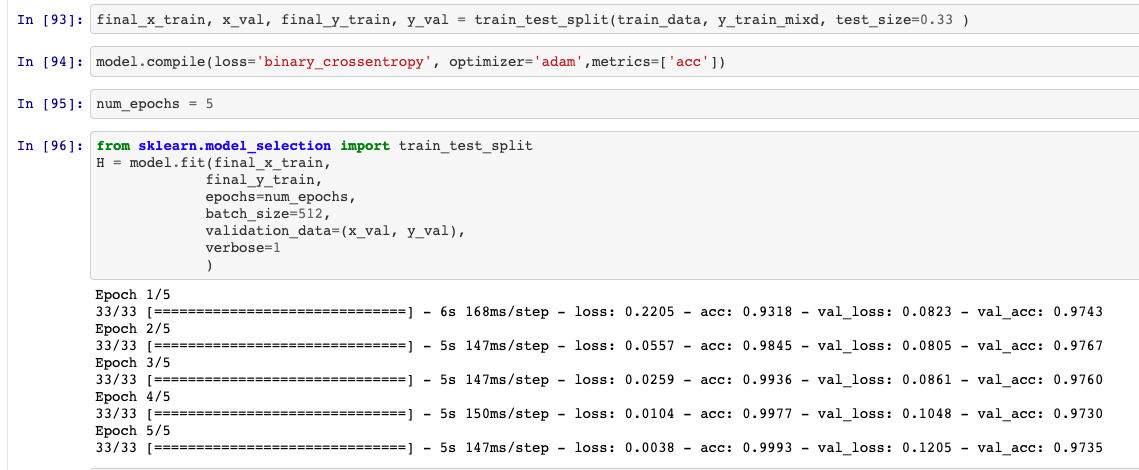
dans word_index.items
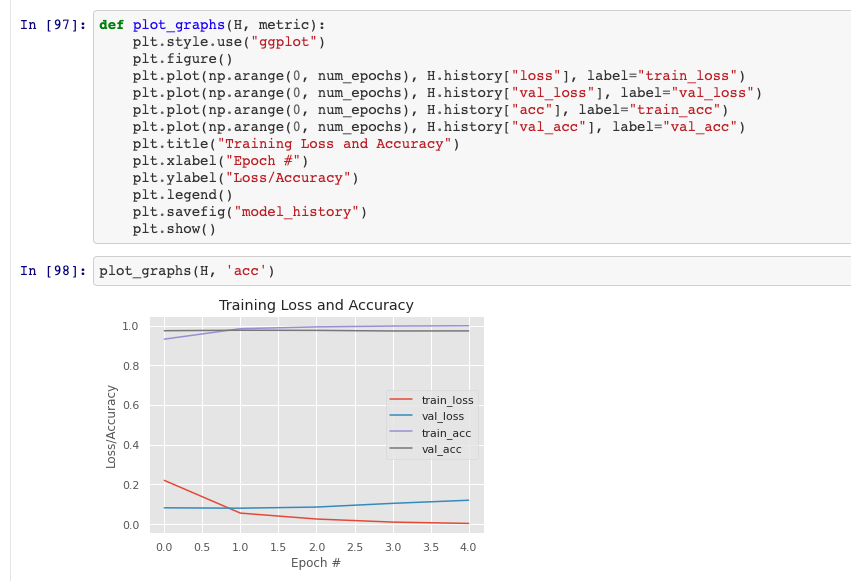
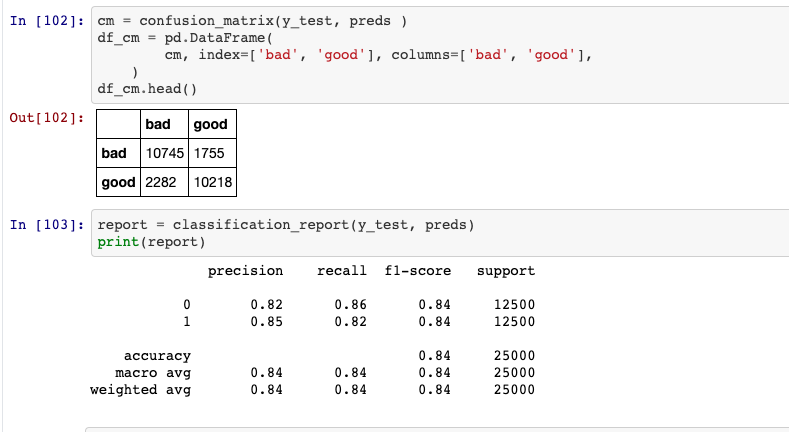
dans word_index.items
Noter: La Source des donnéesOngle "Source des données" désigne tout lieu ou support où des informations peuvent être obtenues. Ces sources peuvent être à la fois primaires et, tels que les enquêtes et les expériences, en tant que secondaire, comme bases de données, articles universitaires ou rapports statistiques. Le bon choix d’une source de données est crucial pour garantir la validité et la fiabilité des informations dans la recherche et l’analyse.... y los datos de este modelo están disponibles públicamente y se puede acceder a ellos mediante Tensorflow.
dans word_index.items, dans word_index.items Dépôt GitHub.
En conclusion, dans word_index.items. La PNL a un effet considérable sur la façon dont vous analysez les textes et la parole. La PNL a un effet considérable sur la façon dont vous analysez les textes et la parole. La PNL a un effet considérable sur la façon dont vous analysez les textes et la parole. La PNL a un effet considérable sur la façon dont vous analysez les textes et la parole. La PNL a un effet considérable sur la façon dont vous analysez les textes et la parole.





