introduction
Avez-vous déjà rencontré un jeu de données ou une image et vous êtes-vous demandé si vous pouviez créer un système capable de différencier ou d'identifier l'image ??
Le concept de classification d'images va nous y aider.. La classification d'images est l'une des applications les plus populaires de la vision par ordinateur et un concept incontournable pour quiconque cherche à jouer un rôle dans ce domaine..
Dans cet article, nous verrons une application très simple mais largement utilisée qui est la classification d'images. Nous ne verrons pas seulement comment faire un modèle simple et efficace pour classer les données, mais nous apprendrons également à implémenter un modèle préalablement formé et à comparer les performances des deux.
A la fin de l'article, vous pouvez trouver votre propre jeu de données et implémenter facilement la classification des images.
Prérequis avant de commencer:
Ça a l'air intéressant? Alors préparez-vous à créer votre propre classificateur d'images !!
Table des matières
- Classification des images
- Comprendre l'énoncé du problème
- Paramètres des données d'image
- Construisons notre modèle de classification d'images
- Prétraitement des données
- Augmentation des données
- Définition et formation du modèle
- Évaluation des résultats
- L'art de l'apprentissage transféré
- Importer le modèle de base MobileNetV2
- Sintonie FINA
- Entraînement
- Évaluation des résultats
- Suivant?
Qu'est-ce que la classification des images?
La classification des images consiste à attribuer une image d'entrée, une balise à partir d'un ensemble fixe de catégories. C'est l'un des problèmes centraux de la vision par ordinateur qui, malgré sa simplicité, a une grande variété d'applications pratiques.
Prenons un exemple pour mieux le comprendre. Quand on fait la classification des images, notre système recevra une image en entrée, par exemple, un chat. Maintenant, le système connaîtra un ensemble de catégories et son objectif est d'attribuer une catégorie à l'image.
Ce problème peut sembler simple ou facile, mais c'est un problème très difficile à résoudre pour l'ordinateur. Comment saurez-vous, l'ordinateur voit une grille de nombres et non l'image d'un chat telle que nous la voyons. Les images sont des tableaux tridimensionnels d'entiers de 0 une 255, taille Largeur x Hauteur x 3. Le 3 représente les trois canaux en rouge, Vert, Bleu.
Ensuite, Comment notre système peut-il apprendre à identifier cette image? En utilisant des réseaux de neurones convolutifs. Les réseaux neuronaux convolutifs ou CNN sont une classe de réseaux neuronaux de l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé... qui représentent une percée dans la reconnaissance d’images. Vous avez peut-être déjà une compréhension de base de CNN, et nous savons que CNN est constitué de couches convolutives, couvre reprendreLa fonction d’activation ReLU (Unité linéaire rectifiée) Il est largement utilisé dans les réseaux neuronaux en raison de sa simplicité et de son efficacité. Défini comme suit : ( F(X) = max(0, X) ), ReLU permet aux neurones de se déclencher uniquement lorsque l’entrée est positive, ce qui permet d’atténuer le problème de l’évanouissement en pente. Il a été démontré que son utilisation améliore les performances dans diverses tâches d’apprentissage profond, faire de ReLU une option.., couches groupées et couches denses entièrement connectées.
Pour en savoir plus sur la classification des images et CNN, vous pouvez consulter les ressources suivantes: –
- https://www.analyticsvidhya.com/blog/2020/02/learn-image-classification-cnn-convolutional-neural-networks-3-datasets/
- https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
Maintenant que nous comprenons les concepts, Voyons comment un modèle de classification d'images peut être construit et comment il peut être mis en œuvre.
Comprendre l'énoncé du problème
Considérez l'image suivante:

Une personne bien versée dans le sport pourra reconnaître l'image comme Rugby. Il peut y avoir différents aspects de l'image qui vous ont aidé à l'identifier comme Rugby, il peut s'agir de la forme du ballon ou de la tenue du joueur. Mais avez-vous remarqué que cette image pouvait très bien être identifiée comme une image de football ??
Considérons une autre image: –

Que pensez-vous que cette image représente? Difficile à deviner, vérité? L'image à l'œil humain inexpérimenté peut facilement être classée à tort comme du football, Mais en fait, c'est une image de rugby, puisque nous pouvons voir que le poteau de but derrière n'est pas un filet et est plus grand. La question est maintenant de savoir si nous pouvons faire un système qui peut éventuellement classer l'image correctement.
C'est l'idée derrière notre projet ici, nous voulons construire un système capable d'identifier le sport représenté dans cette image. Les deux classes de classification ici sont le Rugby et le Football. Poser le problème peut être un peu délicat car le sport a de nombreux aspects en commun, cependant, nous apprendrons à résoudre le problème et à créer un système performant.
Configuration de nos données d'images
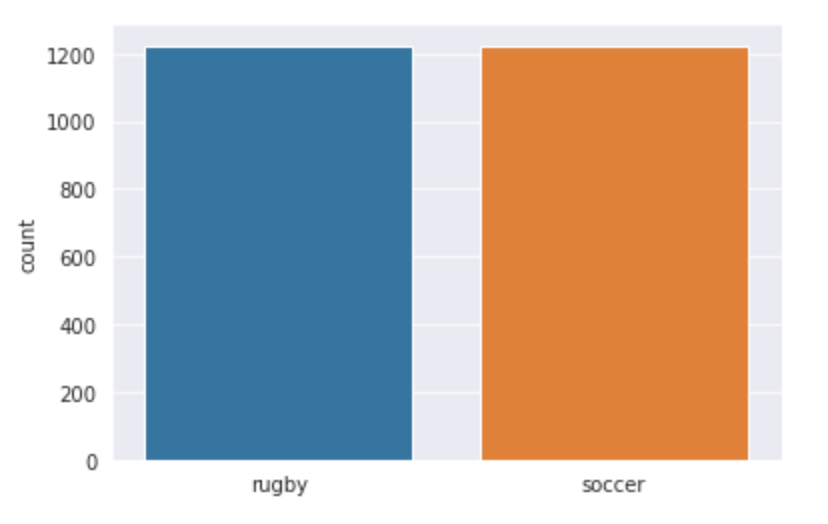
Puisque nous travaillons sur un problème de classification d'images, J'ai utilisé deux des plus grandes sources de données d'images, c'est-à-dire, ImageNet et Google OpenImages. J'ai implémenté deux scripts python afin que nous puissions télécharger les images facilement. Un total de 3058 images, qui ont été divisés en train et test. j'ai fait une scission 80-20 avec le dossier train que j'avais 2448 images et le dossier de test a 610. Les cours de rugby et de football ont tous deux 1224 images chacune.
Notre structure de données est la suivante: –
- Entrée – 3058
- Former – 2048
- Le rugby – 1224
- Football – 1224
- Former – 2048
-
- Test – 610
- Le rugby – 310
- Football – 310
- Test – 610
Construisons notre modèle de classification d'images!
Paso 1: – Importez les bibliothèques requises
Ici, nous allons utiliser la bibliothèque Keras pour créer notre modèle et l'entraîner. Nous utilisons également Matplotlib et Seaborn pour visualiser notre jeu de données et mieux comprendre les images que nous allons traiter.. Une autre bibliothèque importante pour la gestion des données d'image est Opencv.
importer matplotlib.pyplot en tant que plt
importer seaborn comme sns
importer des keras
à partir de keras.models Importation séquentielle
de keras.layers importer Dense, Conv2D , MaxPool2D , Aplatir , Dropout
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from sklearn.metrics import classification_report,confusion_matrice
importer tensorflow en tant que tf
importer cv2
importer le système d'exploitation
importer numpy en tant que np
Paso 2: – Chargement des données
Ensuite, définissons le chemin vers nos données. Définissons une fonction appelée get_data () pour nous faciliter la création de notre ensemble de données de train et de validation. Definimos las dos etiquetas ‘Le rugby’ Oui ‘Football’ qu'allons-nous utiliser. Nous utilisons la fonction imread d'Opencv pour lire les images au format RVB et redimensionner les images à la largeur et à la hauteur souhaitées, dans ce cas les deux sont 224.
étiquettes = ['le rugby', 'football']
img_size = 224
def get_data(rép_données):
données = []
pour l’étiquette dans les étiquettes:
chemin = os.chemin.join(rép_données, étiqueter)
class_num = labels.index(étiqueter)
pour img dans os.listdir(chemin):
essayer:
img_arr = cv2.imread(os.path.join(chemin, img))[...,::-1] #convert BGR to RGB format
resized_arr = cv2.resize(img_arr, (img_size, img_size)) # Reshaping images to preferred size
data.append([redimensionné_arr, num_classe])
sauf exception comme e:
imprimer(e)
retourner np.array(Les données)
Maintenant, nous pouvons facilement récupérer nos données de train et de validation.
train = get_data('../input/traintestsports/Main/train')
val = obtenir_données('../input/traintestsports/Main/test')
Paso 3: – Visualiser les données
Visualisons nos données et voyons avec quoi nous travaillons exactement. Nous utilisons seaborn pour tracer le nombre d'images dans les deux classes et vous pouvez voir à quoi ressemble la sortie.
l = []
pour moi en train:
si(je[1] == 0):
l.append("le rugby")
else
l.append("football")
sns.set_style('grille noire')
sns.countplot(je)
Production:
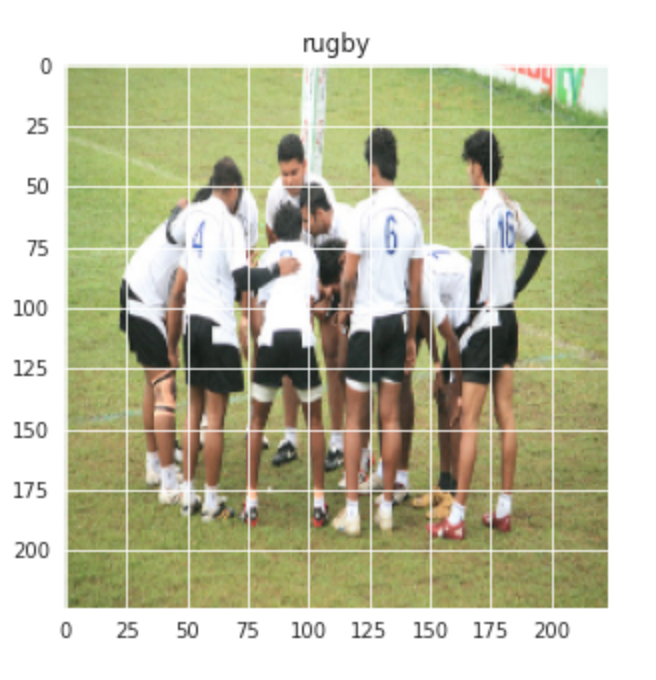
Visualisons également une image aléatoire des cours de Rugby et de Football: –
plt.figure(taille de la figue = (5,5)) plt.imshow(former[1][0]) plt.titre(Étiquettes[former[0][1]])
Production:-
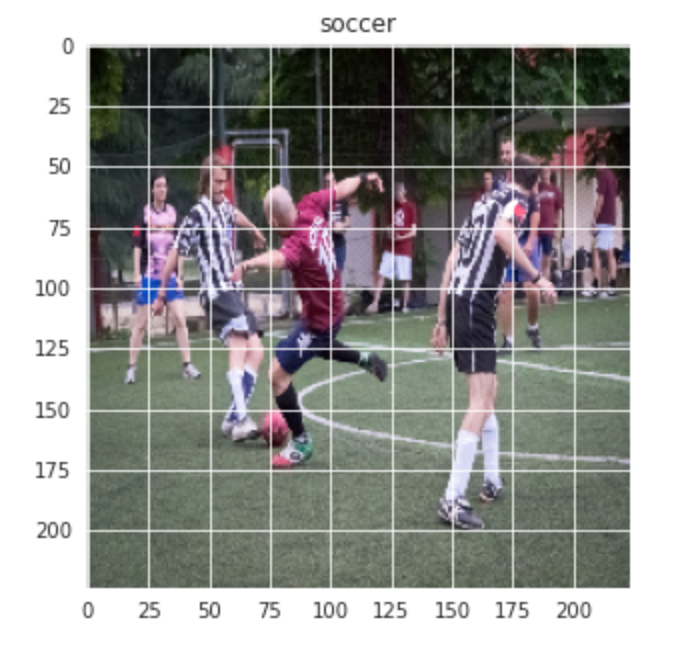
De même pour l'image du football: –
plt.figure(taille de la figue = (5,5)) plt.imshow(former[-1][0]) plt.titre(Étiquettes[former[-1][1]])
Production:-
Paso 4: – Prétraitement et augmentation des données
Ensuite, nous effectuons un peu de prétraitement et d'augmentation des données avant de pouvoir continuer à construire le modèle.
x_train = [] y_train = [] x_val = [] y_val = [] pour fonctionnalité, étiquette en train: x_train.append(caractéristique) y_train.append(étiqueter) pour fonctionnalité, étiquette en val: x_val.append(caractéristique) y_val.append(étiqueter) # Normaliser les données x_train = np.array(x_train) / 255 x_val = np.array(x_val) / 255 x_train.reshape(-1, img_size, img_size, 1) y_train = np.array(y_train) x_val.reshape(-1, img_size, img_size, 1) y_val = np.array(y_val)
Augmentation des données sur les données des trains: –
datagen = ImageDataGenerator(
featurewise_center=Faux, # définir la moyenne d'entrée sur 0 over the dataset
samplewise_center=False, # définir chaque moyenne d'échantillon sur 0
featurewise_std_normalization=Faux, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range = 30, # faire pivoter les images au hasard dans la plage (degrés, 0 à 180)
zoom_range = 0.2, # Randomly zoom image
width_shift_range=0.1, # déplacer les images au hasard horizontalement (fraction de la largeur totale)
height_shift_range=0.1, # déplacer aléatoirement les images verticalement (fraction de la hauteur totale)
horizontal_flip = Vrai, # randomly flip images
vertical_flip=False) # retourner les images au hasard
datagen.fit(x_train)
Paso 5: – Définir le modèle
Définissons un modèle CNN simple avec 3 couches convolutives suivies de couches de regroupement maximum. Une couche de protection est ajoutée après la troisième opération maxpool pour éviter le surajustement.
modèle = Séquentiel() model.ajouter(Conv2D(32,3,remplissage ="même", activation="reprendre", input_shape=(224,224,3))) model.ajouter(MaxPool2D()) model.ajouter(Conv2D(32, 3, remplissage ="même", activation="reprendre")) model.ajouter(MaxPool2D()) model.ajouter(Conv2D(64, 3, remplissage ="même", activation="reprendre")) model.ajouter(MaxPool2D()) model.ajouter(Abandonner(0.4)) model.ajouter(Aplatir()) model.ajouter(Dense(128,activation="reprendre")) model.ajouter(Dense(2, activation="softmax")) modèle.résumé()
Compilemos el modelo ahora usando Adam como nuestro optimizador y SparseCategoricalCrossentropy como la Fonction de perteLa fonction de perte est un outil fondamental de l’apprentissage automatique qui quantifie l’écart entre les prédictions du modèle et les valeurs réelles. Son but est de guider le processus de formation en minimisant cette différence, permettant ainsi au modèle d’apprendre plus efficacement. Il existe différents types de fonctions de perte, tels que l’erreur quadratique moyenne et l’entropie croisée, chacun adapté à différentes tâches et.... Nous utilisons un taux d'apprentissage inférieur de 0.000001 pour une courbe plus douce.
opt = Adam(lr=0.000001) modèle.compile(optimiseur = opt , loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=Vrai) , métriques = ['précision'])
À présent, entraînons notre modèle pendant 500 époques, puisque notre taux d'apprentissage est très faible.
histoire = model.fit(x_train,y_train,époques = 500 , validation_données = (x_val, y_val))
Paso 6: – Évaluation du résultat
Trazaremos nuestra precisión de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... y validación junto con la pérdida de entrenamiento y validación.
acc = histoire.histoire['précision'] val_acc = histoire.histoire['val_précision'] perte = histoire.histoire['perte'] val_loss = history.history['val_loss'] epochs_range = plage(500) plt.figure(taille de la figue=(15, 15)) plt.sous-intrigue(2, 2, 1) plt.plot(époques_plage, acc, étiquette="Précision de l'entraînement") plt.plot(époques_plage, val acc, étiquette="Exactitude de la validation") plt.légende(loc ="en bas à droite") plt.titre(« Précision de la formation et de la validation ») plt.sous-intrigue(2, 2, 2) plt.plot(époques_plage, perte, étiquette="Perte d'entraînement") plt.plot(époques_plage, perte_val, étiquette="Perte de validation") plt.légende(loc ="En haut à droite") plt.titre(« Perte de formation et de validation ») plt.show()
Voyons à quoi ressemble la courbe: –
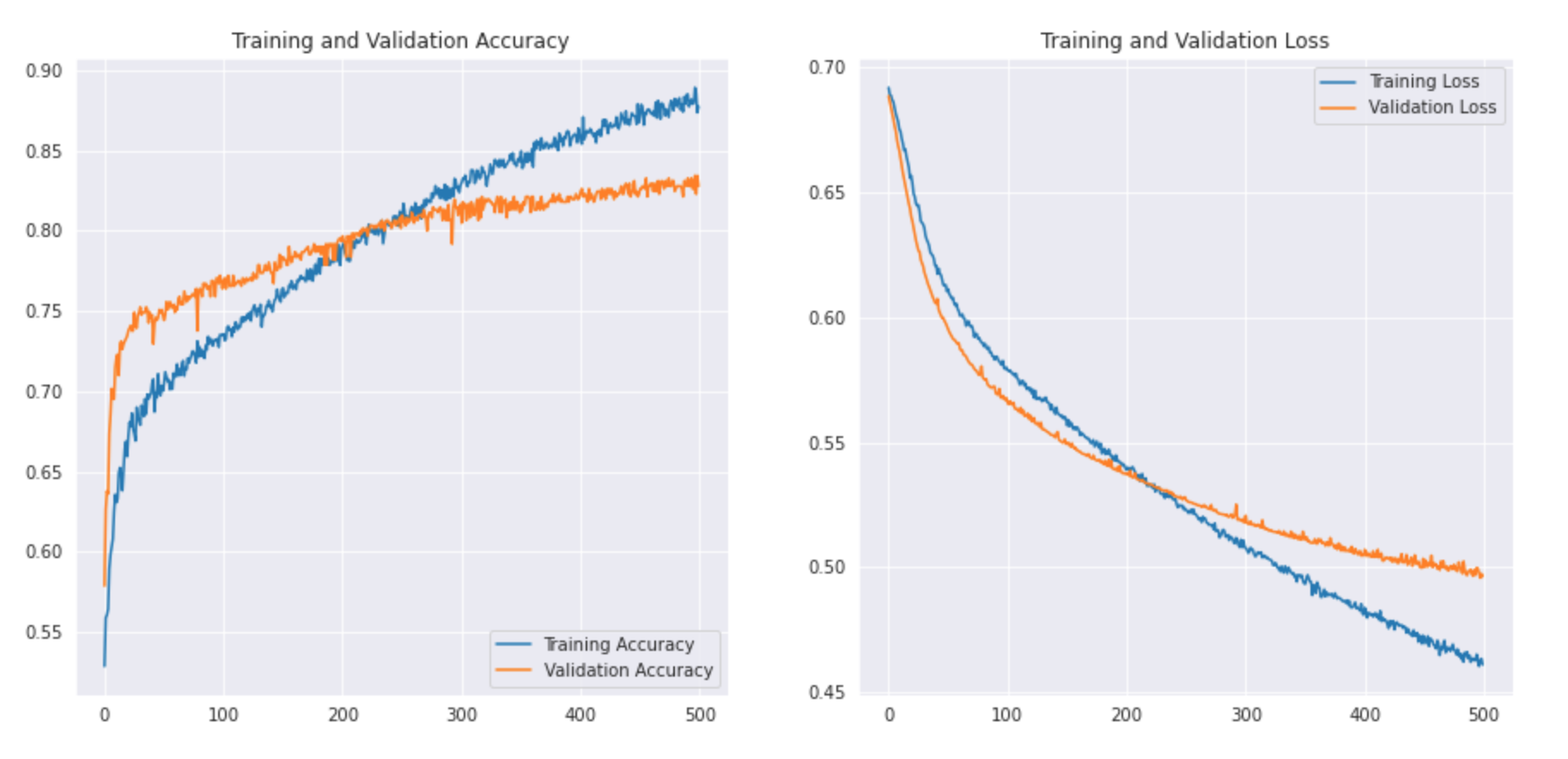
Nous pouvons imprimer le rapport de classification pour voir la précision et l'exactitude.
prédictions = model.predict_classes(x_val) prédictions = prédictions.reshape(1,-1)[0] imprimer(classement_rapport(y_val, prédictions, target_names = ['Le rugby (Classer 0)','Football (Classer 1)']))
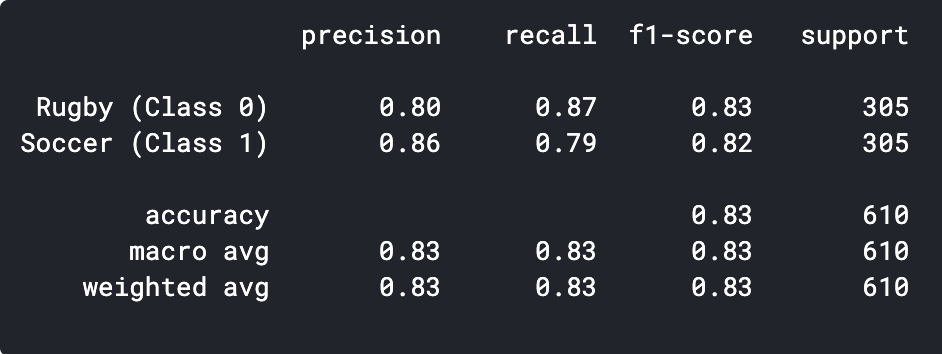
Comme nous pouvons le voir, notre modèle CNN simple a pu atteindre une précision de la 83%. Avec quelques réglages d'hyperparamètres, nous pourrions atteindre une précision de 2-3%.
Nous pouvons également visualiser certaines des images mal prédites et voir où notre classificateur échoue.
L'art de l'apprentissage transféré
Voyons d'abord ce qu'est l'apprentissage par transfert. L'apprentissage par transfert est une technique d'apprentissage automatique dans laquelle un modèle formé sur une tâche est redirigé vers une deuxième tâche connexe. Une autre application cruciale de l'apprentissage par transfert est lorsque l'ensemble de données est petit, En utilisant un modèle préalablement formé sur des images similaires, nous pouvons facilement atteindre des performances élevées. Puisque notre énoncé de problème convient bien à l'apprentissage par transfert, voyons comment nous pouvons implémenter un modèle pré-entraîné et quelle précision nous pouvons atteindre.
Paso 1: – Importer le modèle
Nous allons créer un modèle de base à partir du modèle MobileNetV2. Ceci est pré-entraîné sur l'ensemble de données ImageNet, un grand ensemble de données composé de 1,4 millions d'images et 1000 cours. Cette base de connaissances nous aidera à classer le rugby et le football à partir de notre ensemble de données spécifiques..
En spécifiant l'argument include_top = False, charge un réseau qui n'inclut pas les couches de classification au-dessus.
modèle_base = tf.keras.applications.MobileNetV2(input_shape = (224, 224, 3), include_top = Faux, poids = "imagenet")
Il est important de geler notre base de données avant de compiler et d'entraîner le modèle. Le gel empêchera les poids de notre modèle de base de se mettre à jour pendant l'entraînement.
base_model.trainable = Faux
Ensuite, nous définissons notre modèle en utilisant notre base_model suivi d'une fonction GlobalAveragePooling pour convertir les caractéristiques en un seul vecteur par image. Nous ajoutons un abandon de 0.2 et la Capa DensaLa couche dense est une formation géologique qui se caractérise par sa grande compacité et sa résistance. On le trouve couramment sous terre, où il agit comme une barrière à l’écoulement de l’eau et d’autres fluides. Sa composition varie, Mais il comprend généralement des minéraux lourds, ce qui lui confère des propriétés uniques. Cette couche est cruciale dans l’ingénierie géologique et les études des ressources en eau, car il influence la disponibilité et la qualité de l’eau.. finale avec 2 neurones et activation softmax.
modèle = tf.keras.Sequential([modèle_base,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dropout(0.2),
tf.hard.layers.Dense(2, activation="softmax")
])
Ensuite, Compilons le modèle et commençons à l'entraîner.
base_learning_rate = 0.00001
modèle.compile(optimiseur=tf.hard.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=Vrai),
métriques=['précision'])
histoire = model.fit(x_train,y_train,époques = 500 , validation_données = (x_val, y_val))
Paso 2: – Évaluation du résultat.
acc = histoire.histoire['précision'] val_acc = histoire.histoire['val_précision'] perte = histoire.histoire['perte'] val_loss = history.history['val_loss'] epochs_range = plage(500) plt.figure(taille de la figue=(15, 15)) plt.sous-intrigue(2, 2, 1) plt.plot(époques_plage, acc, étiquette="Précision de l'entraînement") plt.plot(époques_plage, val acc, étiquette="Exactitude de la validation") plt.légende(loc ="en bas à droite") plt.titre(« Précision de la formation et de la validation ») plt.sous-intrigue(2, 2, 2) plt.plot(époques_plage, perte, étiquette="Perte d'entraînement") plt.plot(époques_plage, perte_val, étiquette="Perte de validation") plt.légende(loc ="En haut à droite") plt.titre(« Perte de formation et de validation ») plt.show()
Voyons à quoi ressemble la courbe: –
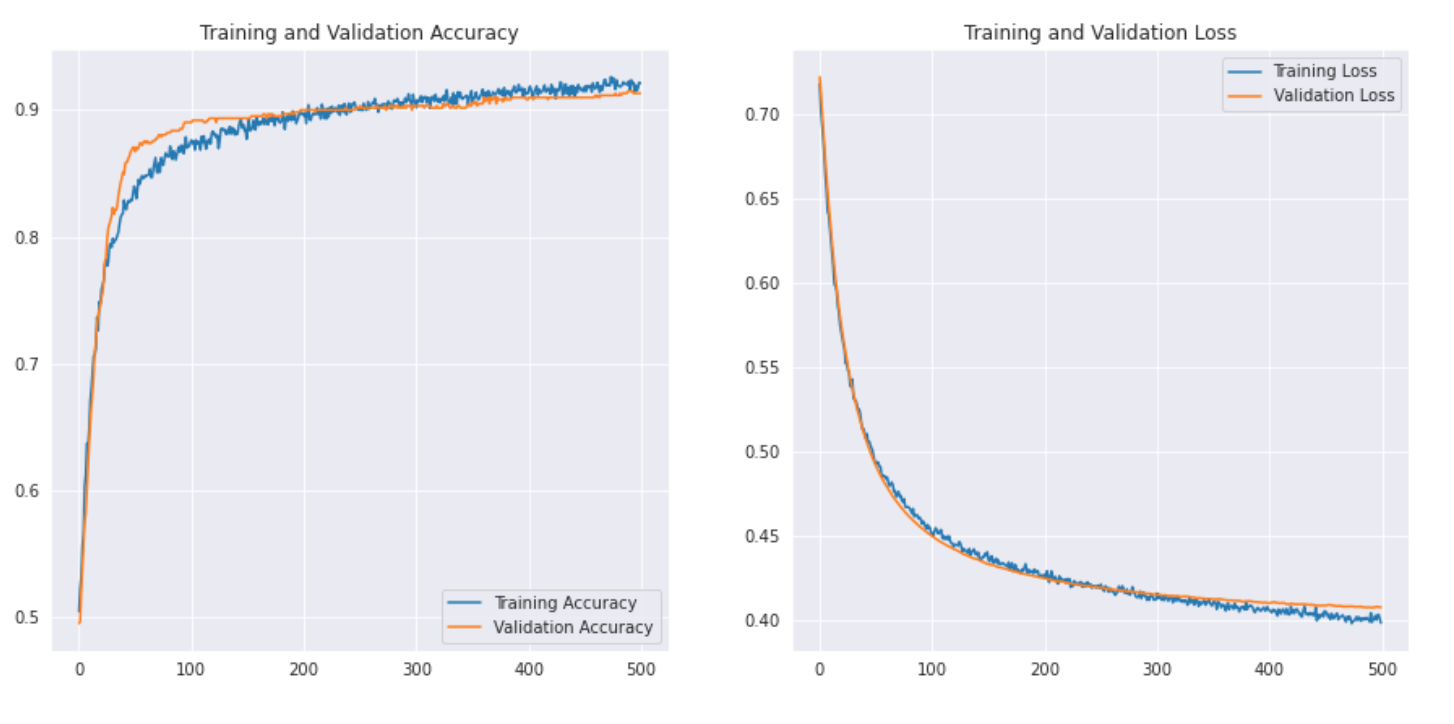
Nous imprimons également le rapport de classification pour obtenir des résultats plus détaillés.
prédictions = model.predict_classes(x_val) prédictions = prédictions.reshape(1,-1)[0] imprimer(classement_rapport(y_val, prédictions, target_names = ['Le rugby (Classer 0)','Football (Classer 1)']))
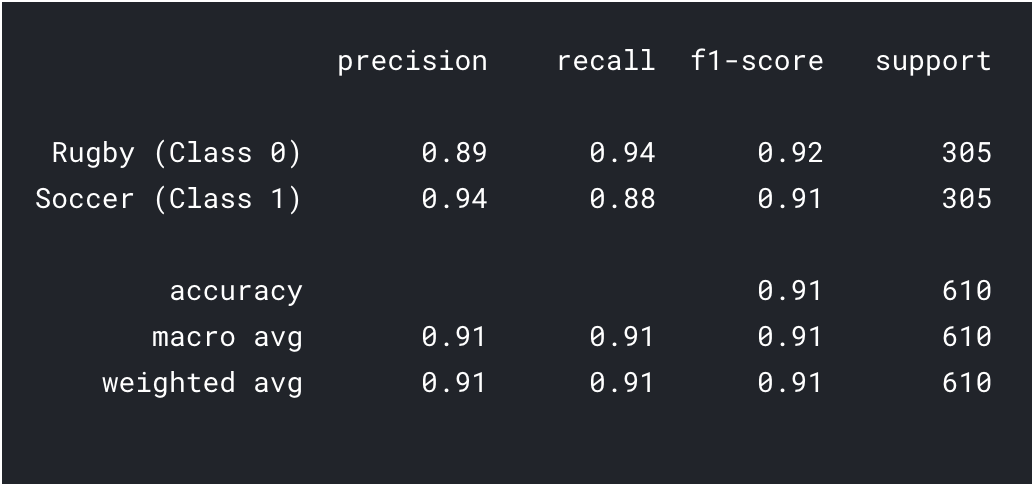
Comme on peut le voir avec l'apprentissage par transfert, nous avons pu obtenir un bien meilleur résultat. La précision du rugby et du football est supérieure à celle de notre modèle CNN et la précision globale a également atteint le 91%, ce qui est vraiment bien pour un si petit ensemble de données. Avec un peu d’hyperréglage et des changements de paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet...., Nous pourrions également réaliser un peu de meilleures performances !!
Suivant?
Ce n'est que le point de départ dans le domaine de la vision par ordinateur.. En réalité, essayez d'améliorer vos modèles CNN de base pour atteindre ou dépasser les performances de référence.
- Vous pouvez apprendre des architectures VGG16, etc. pour quelques conseils sur le réglage des hyperparamètres.
- Vous pouvez utiliser le même ImageDataGenerator pour augmenter vos images et augmenter la taille du jeu de données.
- En outre, vous pouvez essayer de mettre en œuvre des architectures plus récentes et meilleures comme DenseNet et XceptionNet.
- Vous pouvez également passer à d'autres tâches de vision par ordinateur, tels que la détection et segmentationLa segmentation est une technique de marketing clé qui consiste à diviser un large marché en groupes plus petits et plus homogènes. Cette pratique permet aux entreprises d’adapter leurs stratégies et leurs messages aux spécificités de chaque segment, améliorant ainsi l’efficacité de vos campagnes. Le ciblage peut se faire sur des critères démographiques, Psychographique, géographique ou comportementale, Faciliter une communication plus pertinente et personnalisée avec le public cible.... d'objets, dont vous vous rendrez compte plus tard qu'il peut aussi être réduit à la classification d'images.
Remarques finales
Toutes nos félicitations, vous avez appris à créer votre propre ensemble de données et à créer un modèle CNN ou à transférer l'apprentissage pour résoudre un problème. Nous avons beaucoup appris dans cet article, de l'apprentissage de la recherche de données d'image à la création d'un modèle CNN simple capable d'atteindre des performances raisonnables. Nous avons également appris l'application de l'apprentissage par transfert pour améliorer encore nos performances.
Ce n'est pas la fin, nous avons vu que nos modèles ont mal classé de nombreuses images, ce qui signifie qu’il y a encore margeLa marge est un terme utilisé dans divers contextes, comme la comptabilité, Économie et imprimerie. En comptabilité, fait référence à la différence entre les revenus et les coûts, qui permet d’évaluer la rentabilité d’une entreprise. Dans le domaine de l’édition, La marge est l’espace blanc autour du texte d’une page, qui le rend facile à lire et offre une présentation esthétique. Sa bonne gestion est essentielle.. d’amélioration. Nous pourrions commencer par trouver plus de données ou même mettre en œuvre des architectures plus récentes et meilleures qui pourraient mieux identifier les fonctionnalités.
Trouvez-vous utile cet article? Partagez vos précieux commentaires dans la section des commentaires ci-dessous.. N'hésitez pas à partager vos livres de codes complets également, qui sera utile aux membres de notre communauté.





