Vue d'ensemble
- Discutiremos cómo puede consultar una base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes.... MongoDB usando la biblioteca PyMongo.
- Nous couvrirons les opérations d'agrégation de base dans MongoDB.
introduction
Suite à l'expansion mondiale d'Internet, nous générons des données à un rythme sans précédent maintenant. Parce que mener tout type d'analyse nous obligerait à collecter / consultons les données nécessaires de la base de données, il est extrêmement important que nous choisissions le bon outil pour consulter les données. En conséquence, nous ne pouvons pas imaginer utiliser SQL pour travailler avec ce volume de données, car chaque consultation coûtera cher.
Interroger une base de données MongoDB à l'aide de PyMongo
C'est précisément là qu'intervient MongoDB. MongoDB est une base de données non structurée qui stocke des données sous forme de documents. En outre, MongoDB puede manejar grandes volúmenes de datos de manera muy eficiente y es la base de datos NoSQLLas bases de datos NoSQL son sistemas de gestión de datos que se caracterizan por su flexibilidad y escalabilidad. A diferencia de las bases de datos relacionales, utilizan modelos de datos no estructurados, como documentos, clave-valor o gráficos. Son ideales para aplicaciones que requieren manejo de grandes volúmenes de información y alta disponibilidad, como en el caso de redes sociales o servicios en la nube. Su popularidad ha crecido en... más utilizada, car il offre un langage de requête riche et un accès rapide et flexible aux données.
Dans cet article, nous verrons plusieurs exemples d'interrogation d'une base de données MongoDB à l'aide de PyMongo. En outre, veremos cómo utilizar los operadores de comparaciónLos operadores de comparación son herramientas fundamentales en programación y matemáticas que permiten evaluar relaciones entre valores. Estos incluyen operadores como mayor que (>), menor que (<), égal à (==) y diferente de (!=). Su función principal es retornar un valor booleano, c'est-à-dire, vrai ou faux, facilitando la toma de decisiones en algoritmos y la manipulación de datos en estructuras de control como condicionales y bucles.... et les operadores lógicosLos operadores lógicos son símbolos o palabras clave que permiten combinar y evaluar expresiones booleanas en programación y matemáticas. Los más comunes son AND, OR y NOT. Estos operadores son fundamentales para el desarrollo de algoritmos y la toma de decisiones en sistemas informáticos, facilitando la ejecución de condiciones complejas. Su correcto uso optimiza el flujo de control y mejora la eficiencia en la resolución de problemas...., principes de base des pipelines d'expression régulière et d'agrégation.
Cet article est une continuation du didacticiel MongoDB en Python pour les débutants, où nous couvrons les défis des bases de données non structurées, Étapes d'installation et opérations de base de MongoDB. Ensuite, si vous êtes un débutant complet à MongoDB, Je vous recommande de lire cet article en premier.
Table des matières
- Qu'est-ce que PyMongo?
- Étapes d'installation
- Insérer les données dans la base de données
- Consulter la base de données
- Filtre basé sur le champ
- Filtre basé sur des opérateurs de comparaison
- Filtre basé sur des opérateurs logiques
- Expressions régulières
- Tuyaux d'agrégation
- Remarques finales
Qu'est-ce que PyMongo?
PyMongo est une bibliothèque Python qui nous permet de nous connecter avec MongoDB. En outre, c'est la manière la plus recommandée de travailler avec MongoDB et Python.
En outre, Nous avons choisi Python pour interagir avec MongoDB car c'est l'un des langages les plus utilisés et considérablement plus puissants pour Science des données. PyMongo nous permet de récupérer les données avec une syntaxe similaire à celle d'un dictionnaire.
Si vous êtes débutant en Python, Je vous recommande de vous inscrire à ce cours gratuit: Introduction à Python.
Étapes d'installation
L'installation de PyMongo est simple et directe. Ici, je suppose que tu as déjà python 3 et MongoDB installé. La commande suivante vous aidera à installer PyMongo:
pip3 installer pymongo
Insérer les données dans la base de données
Maintenant, configurons les choses avant d'interroger une base de données MongoDB à l'aide de PyMongo. Nous allons d'abord insérer les données dans la base de données. Les étapes suivantes vous aideront dans cette:
-
Importez les bibliothèques et connectez-vous au client mongo
Démarrez le serveur MongoDB sur votre machine. Je suppose qu'un fichier s'exécute sur localhost: 27017.
Commençons par importer certaines des bibliothèques que nous allons utiliser. Par défaut, Serveur MongoDB exécuté sur le port 27017 de la machine locale. Alors, nous allons nous connecter au client MongoDB en utilisant le Pymongo Une bibliothèque.
Alors, obtenir l'instance de base de données à partir de la base de données sample_db. Au cas où il n'y aurait pas, MongoDB en créera un pour vous.
-
Créer les collections à partir des fichiers JSON
Nous utiliserons les données d'une entreprise de livraison de nourriture qui opère dans plusieurs villes. En outre, ils ont plusieurs centres logistiques dans ces villes pour envoyer des commandes de nourriture à leurs clients. Vous pouvez télécharger le données et code ici.
- demande_hebdomadaire:
- identifiant: ID unique pour chaque document
- la semaine: Numéro de semaine
- center_id: ID unique pour le centre de distribution
- id_aliment: ID d'aliment unique
- caisse_prix: Prix final avec remise, taxes et frais d'expédition
- prix de base: Prix du repas de base
- emailer_for_promotion: Emailer envoyé pour la promotion de la nourriture
- homepage_featured: Nourriture présentée sur la page d'accueil.
- nombre_commandes: (destin) Nombre de commandes
- info_alimentaire:
- id_aliment: ID unique pour la nourriture
- Catégorie: Genre de nourriture (boissons / collations / soupes….)
- cuisine: Cuisine alimentaire (Inde / italienne /…)
Ensuite, nous allons créer deux collections dans la base de données sample_db:


- demande_hebdomadaire:
-
Insérer des données dans des collections
À présent, los datos que tenemos están en formato JSONJSON, o Notation d’objet JavaScript, Il s’agit d’un format d’échange de données léger, facile à lire et à écrire pour les humains, et facile à analyser et à générer pour les machines. Il est couramment utilisé dans les applications Web pour envoyer et recevoir des informations entre un serveur et un client. Sa structure est basée sur des paires clé-valeur, ce qui le rend polyvalent et largement adopté dans le développement de logiciels... Ensuite, nous obtiendrons l'instance de collection, Nous allons lire le fichier de données et insérer les données en utilisant le insert_many une fonction.
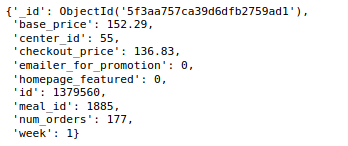
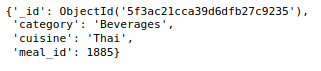
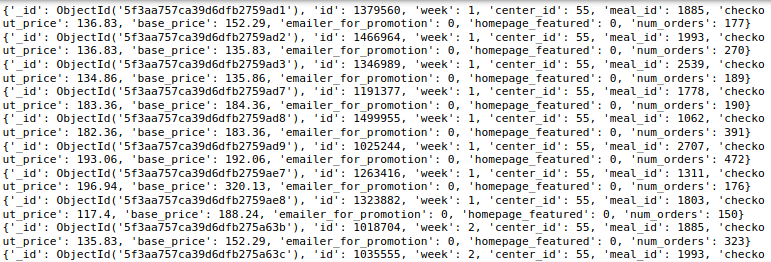
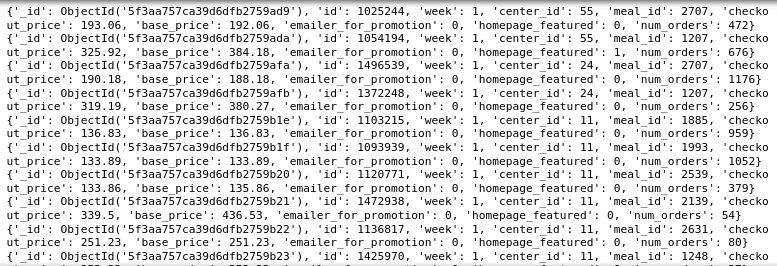
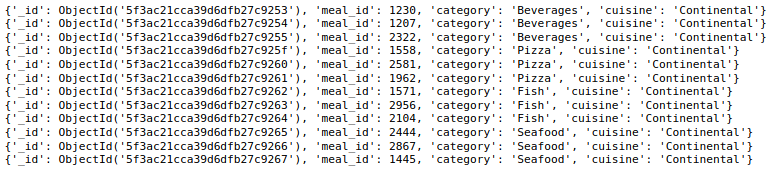
Finalement, avoir 456548 documents dans la collecte hebdomadaire des demandes et 51 documents dans la collecte d'informations sur les aliments. À présent, Regardons un document de chacune de ces collections.
collection_hebdomadaire
repas_info_collection
À présent, nos données sont prêtes. Allons consulter cette base de données.
Consulter la base de données
Nous pouvons interroger une base de données MongoDB en utilisant PyMonfo avec le trouve fonction pour obtenir tous les résultats qui satisfont à la condition donnée et également en utilisant la en trouver un fonction qui ne renverra qu'un résultat satisfaisant à la condition.
Ce qui suit est la syntaxe de find et find_one:
votre_collection.find( {<< mettre en doute >>} , { << des champs>>} )
Vous pouvez interroger la base de données à l'aide des techniques de filtrage suivantes:
-
Filtre basé sur le champ
Par exemple, vous avez des centaines de champs et vous ne voulez en voir que quelques-uns. Vous pouvez le faire en mettant simplement tous les noms de champs requis avec la valeur 1. Par exemple:

D'un autre côté, si vous souhaitez supprimer certains champs uniquement de l'ensemble du document, vous pouvez mettre les noms de champs égaux à 0. Donc, seuls ces champs seront exclus. Notez que vous ne pouvez pas utiliser une combinaison de 1 Oui 0 pour obtenir les champs. Soit tout doit être un, soit tout doit être zéro.

-
Filtrer avec une condition
À présent, dans cette section, nous fournirons une condition dans les premières accolades et des champs à écarter dans le second. En conséquence, renverra le premier document avec center_id égal 55 et repas_id est égal 1885 et il supprimera également les champs _id et week.

-
Filtre basé sur des opérateurs de comparaison
Voici les neuf opérateurs de comparaison dans MongoDB.
NOM LA DESCRIPTION $eqCorrespondra aux valeurs qui sont égales à une valeur spécifiée. $gtCorrespondra aux valeurs supérieures à une valeur spécifiée. $gteCorrespondra à toutes les valeurs supérieures ou égales à une valeur spécifiée. $inCorrespondra à l'une des valeurs spécifiées dans un tableau. $ltCorrespondra à toutes les valeurs inférieures à une valeur spécifiée. $lteCorrespondra à toutes les valeurs inférieures ou égales à une valeur spécifiée. $neCorrespondra à toutes les valeurs qui ne sont pas égales à une valeur spécifiée. $ninNe correspondra à aucune des valeurs spécifiées dans un tableau. Voici quelques exemples d'utilisation de ces opérateurs de comparaison:
-
Identique et différent de
Nous trouverons tous les documents où center_id est égal à 55 et homepage_featured n'est pas égal à 0. Comment allons-nous utiliser la fonction de recherche, renverra le curseur pour cette commande. En outre, utiliser une boucle for pour parcourir les résultats de la requête.

-
Sur la liste et non sur la liste
Par exemple, doit correspondre à un élément avec plusieurs éléments. Dans ce cas, au lieu d'utiliser l'opérateur $ égaliser plusieurs fois, on peut utiliser l'opérateur $ dans. Nous allons essayer de trouver tous les documents où se trouve center_id 24 vous 11.

Alors, nous recherchons tous les documents où center_id n'est pas présent dans la liste spécifiée. La requête suivante renverra tous les documents où center_id n'est pas 24 et non plus 11.

-
Inférieur à et Supérieur à
À présent, trouvons tous les documents où se trouve center_id 55 et checkout_price est supérieur à 100 et moins de 200. Utilisez la syntaxe suivante pour cela-

-
-
Filtre basé sur l'opérateur logique
NOM LA DESCRIPTION $andRejoindra les clauses de requête avec une logique. ANDet renvoie tous les documents qui remplissent les deux conditions.$notCela inversera l'effet d'une requête et renverra des documents qui ne sont pas non expression de requête de correspondance. $norRejoindra les clauses de requête avec une logique. NORet retourner tous les documents non conformes aux clauses.$orRejoindra les clauses de requête avec une logique. ORet retourner tous les documents qui correspondent aux conditions de l'une des clauses.Les exemples suivants illustrent l'utilisation des opérateurs logiques:
-
Et opérateur
La requête suivante renverra tous les documents où center_id est égal à 11 et aussi repas_id n'est pas égal à 1778. Les sous-requêtes pour le Oui L'opérateur saisira une liste.

-
Opérateur OU
La requête suivante renverra tous les documents où center_id est égal à 11 o repas_id es 1207 O 2707. En outre, les sous-requêtes pour le O L'opérateur saisira une liste.

-
-
Filtrer avec des expressions régulières
Les expressions régulières sont très utiles lorsque vous avez des champs de texte et que vous souhaitez rechercher des documents avec un modèle spécifique. Si vous souhaitez en savoir plus sur les expressions régulières, je vous conseille de lire cet article: Tutoriel du débutant pour les expressions régulières en Python.
Peut être utilisé avec l'opérateur. $ expression régulière et nous pouvons fournir une valeur à l'opérateur pour que le modèle regex soit matc. Nous utiliserons la collection repas_info pour cette requête, puis nous trouverons les documents où le champ cuisine commence par caractère C.

Prenons un autre exemple d'expressions régulières. Nous découvrirons tous les documents dans lesquels la catégorie part du personnage. « S » et la cuisine se termine par « Ian".

-
Tuyaux d'agrégation
Le pipeline d'agrégation MongoDB fournit un cadre pour effectuer une série de transformations de données sur un ensemble de données. Voici sa syntaxe:
votre_collection.agrégat( [ { <étape 1> }, { <étape2> },.. ] )
La première étape prend l'ensemble des documents en entrée et, De là, chaque étape suivante prend l'ensemble de résultats de la transformation précédente en entrée de l'étape suivante et produit la sortie.
Il y a autour de 10 transformations disponibles dans l'agrégat MongoDB, dont nous verrons $ correspondre Oui $ grouper dans cet article. Nous discuterons de chacune des transformations en détail dans le prochain article de MongoDB.
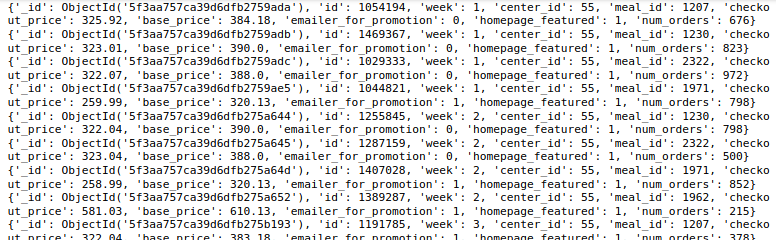
Par exemple, Dans la première étape, nous allons faire correspondre les documents où center_id est égal à 11 et dans la prochaine étape, comptera le nombre de documents avec center_id égal à 11. Veuillez noter que nous avons attribué le $ compter opérateur valeur égale total_rows dans la deuxième étape c'est le nom du champ que nous voulons dans la sortie.

À présent, prenons un autre exemple où la première étape est la même que précédemment, c'est-à-dire, center_id est égal à 11 et dans la deuxième étape, nous voulons calculer la moyenne du champ num_orders pour le center_id 11 et les seuls repas_ids pour le center_id 11.









Remarques finales
La quantité insondable de données générées aujourd'hui rend nécessaire de trouver de meilleures alternatives comme celle-ci pour consulter les données. Pour resumer, dans cet article, nous avons appris à interroger une base de données MongoDB à l'aide de PyMongo. En outre, nous avons compris comment appliquer divers filtres selon la situation requise.
Si vous souhaitez plus d'informations sur la requête de données, Je recommande le cours suivant: Langage de requêtes structurées (SQL) pour la science des données
Dans le prochain article, nous analyserons en détail les pipelines d'agrégation.
Je vous encourage à essayer des choses par vous-même et à partager vos expériences dans la section commentaires. En outre, si vous avez un problème avec l'un des concepts ci-dessus, n'hésitez pas à me demander dans les commentaires ci-dessous.





