Cet article a été publié dans le cadre du Blogathon sur la science des données
w
- Cet article vous donnera une compréhension de base du fonctionnement de l'analyse de texte..
- Connaître les différentes étapes du processus PNL
- Dérivation du sentiment général du texte.
- Tableau de bord affichant les statistiques globales et l'analyse des sentiments du texte.
Abstrait
Dans cette ère numérique moderne, une grande quantité d'informations est générée par seconde. La plupart des données que les humains génèrent par le biais de messages, tweets, blogs, articles de presse, les recommandations de produits et les avis WhatsApp ne sont pas structurés. Ensuite, pour obtenir des informations utiles à partir de ces données hautement non structurées, nous devons d'abord les convertir sous une forme structurée et normalisée.
Traitement du langage naturel (PNL) est une classe d'intelligence artificielle qui exécute une série de processus sur ces données non structurées pour obtenir des informations significatives. Le traitement du langage est de nature totalement non déterministe car le même langage peut avoir des interprétations différentes.. Cela devient fastidieux car quelque chose qui convient à une personne ne convient pas à une autre. En outre, l'utilisation du langage courant, acronymes, hashtags avec des mots attachés, les émoticônes ont une surcharge pour le prétraitement.
Si le interesa el poder de la analytiqueL’analytique fait référence au processus de collecte, Mesurer et analyser les données pour obtenir des informations précieuses qui facilitent la prise de décision. Dans divers domaines, Comme les affaires, Santé et sport, L’analytique peut identifier des modèles et des tendances, Optimiser les processus et améliorer les résultats. L’utilisation d’outils et de techniques statistiques de pointe est essentielle pour transformer les données en connaissances applicables et stratégiques.... de redes sociales, cet article est le point de départ pour vous. Este artículo cubre los conceptos básicos de análisis de texto y le proporciona un tutorial paso a paso para realizar el procesamiento del lenguaje natural sin el requisito de ningún conjunto de datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.....
Introduction à la PNL
Le traitement du langage naturel est le sous-domaine de l'intelligence artificielle qui comprend des processus systématiques pour convertir des données non structurées en informations significatives et en extraire des informations utiles.. La PNL est en outre classée en deux grandes catégories: PNL basée sur des règles et PNL statistique. La PNL basée sur des règles utilise un raisonnement de base pour traiter les tâches, un effort manuel est donc nécessaire sans beaucoup de formation sur l'ensemble de données. PNL statistique, d'un autre côté, entraîne une grande quantité de données et en tire des informations. Il utilise des algorithmes d'apprentissage automatique pour s'entraîner. Dans cet article, nous apprendrons la PNL basée sur des règles.
Applications PNL:
- Résumé du texte
- Machine à traduire
- Systèmes de questions et réponses
- correcteurs orthographiques
- Saisie automatique
- Analyse des sentiments
- Reconnaissance vocale
- SegmentaciónLa segmentation est une technique de marketing clé qui consiste à diviser un large marché en groupes plus petits et plus homogènes. Cette pratique permet aux entreprises d’adapter leurs stratégies et leurs messages aux spécificités de chaque segment, améliorant ainsi l’efficacité de vos campagnes. Le ciblage peut se faire sur des critères démographiques, Psychographique, géographique ou comportementale, Faciliter une communication plus pertinente et personnalisée avec le public cible.... de temas
Canalisation PNL:

La canalisation PNL est divisée en cinq sous-tâches:
1. Analyse lexicale: L'analyse lexicale est le processus d'analyse de la structure des mots et des phrases présents dans le texte.. Le lexique est défini comme le plus petit morceau de texte identifiable. pourrait être un mot, phrase, etc. Implique d'identifier et de diviser le texte entier en phrases, paragraphes et mots.
2. Analyse syntaxique: L'analyse est le processus d'ordre des mots d'une manière qui montre la relation entre les mots.. Cela implique de les analyser pour les modèles grammaticaux.. Par exemple, prière « le collège va à la fille ». est rejeté par l'analyseur.
3. Analyse sémantique: L'analyse sémantique est le processus d'analyse d'un texte pour déterminer sa signification.. Tenir compte des structures syntaxiques pour mapper les objets dans le domaine de la tâche. Par exemple, la phrase « Tu veux manger de la glace chaude » est rejeté par l'analyseur sémantique.
4. Intégration de la divulgation: L'intégration de la divulgation est le processus d'étude du contexte du texte. Les phrases sont disposées dans un ordre significatif pour former un paragraphe, ce qui signifie que la phrase avant une phrase particulière est nécessaire pour comprendre le sens général. En outre, la phrase qui suit la phrase dépend de la précédente.
5. analyse pragmatique: L'analyse pragmatique est définie comme le processus de reconfirmation que ce que le texte voulait vraiment dire est le même que ce qui en a été dérivé..
Lecture du fichier texte:
nom de fichier = "C:UsersDellDesktopexample.txt" texte = ouvert(nom de fichier, "r").lire()
imprimer le texte:
imprimer(texte)

Installation de la librairie pour NLP:
Nous utiliserons la librairie spaCy pour ce tutoriel. espace est une bibliothèque logicielle open source pour la PNL avancée écrite dans les langages de programmation Python et Cython.. La bibliothèque est publiée sous licence MIT. Contrairement à NLTK, qui est largement utilisé pour l’enseignement et la recherche, spaCy se concentre sur la fourniture de logiciels pour une utilisation en production. spaCy también admite flujos de trabajo de l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé... que permiten conectar modelos estadísticos entrenados por bibliotecas de aprendizaje automático populares como TensorFlow, Pytorch via sa propre bibliothèque d’apprentissage automatique Thinc.[Wikipédia]
pip install -U pip setuptools wheel
pip install -U spacy
Puisque nous avons affaire à la langue anglaise. Ensuite, nous devons installer le en_core_web_sm paquet pour elle.
python -m spacy télécharger en_core_web_sm
Vérification de la réussite du téléchargement et importation du package spacy:
import spacy
nlp = spacy.load('en_core_web_sm')
Après la création réussie de l’objet NLP, nous pouvons passer au prétraitement.
Tokenisation:
La tokenisation est le processus de conversion de tout le texte en une série de mots appelés jetons.. C'est la première étape de tout processus PNL.. Diviser tout le texte en unités significatives.
text_doc = pnl(texte) imprimer ([token.text pour le jeton dans text_doc])

Comme nous pouvons le voir dans les jetons, il y a beaucoup d'espaces vides, virgules, mots vides inutiles du point de vue de l'analyse.
Identification de la phrase
L'identification des phrases du texte est utile lorsque nous voulons configurer des parties importantes du texte qui se produisent ensemble.. C'est pourquoi il est utile de trouver des phrases.
about_doc = pnl(about_text) phrases = liste(about_doc.sents)

Suppression des mots parasites
Les mots vides sont définis comme des mots qui apparaissent fréquemment dans la langue. No tienen ningún papel significativo en el análisis de texto y obstaculizan el análisis de Distribution de fréquenceLa distribution de fréquence est un outil statistique qui organise et résume les données en intervalles ou en catégories, faciliter son analyse. Vous permet de visualiser la fréquence à laquelle différentes valeurs apparaissent dans un jeu de données, soit par le biais de tableaux ou de graphiques. Cette technique est fondamentale en statistique descriptive, car il aide à identifier des modèles, Tendances et dispersion des données, Soutenir la prise de décisions éclairées..... Par exemple, la, ongle, ongle, O, etc. Donc, doit être retiré du texte pour obtenir une image plus claire du texte.
texte_normalisé = [token pour token dans text_doc sinon token.is_stop] imprimer (texte_normalisé)

Suppression de la ponctuation:
Comme nous pouvons le voir dans le résultat ci-dessus, il y a des signes de ponctuation qui ne nous servent pas. Alors éliminons-les.
texte_propre = [token pour token dans normalized_text sinon token.is_punct] imprimer (texte_propre)

Lématisation:
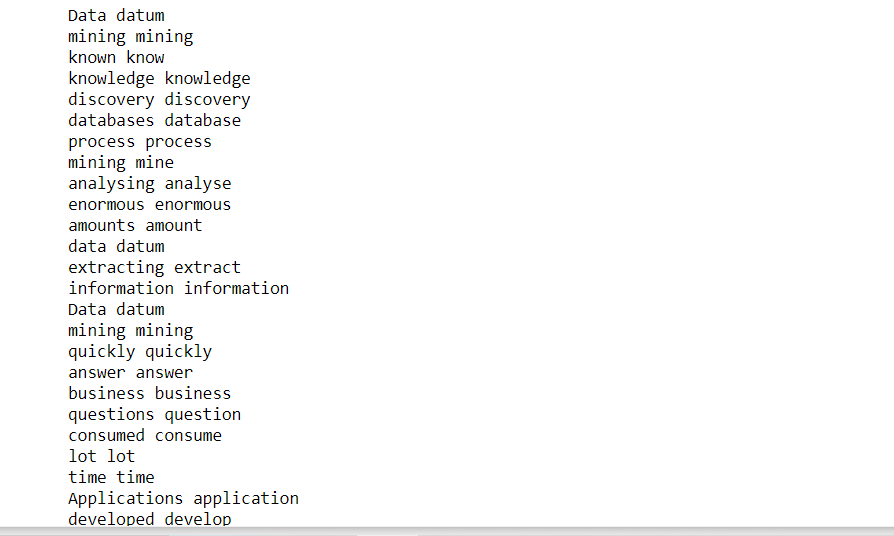
La lemmatisation est le processus de réduction d'un mot à sa forme originale.. Lemme est un mot qui représente un groupe de mots appelés lexèmes.. Par exemple: participer, participer, participer. Ils se résument tous à une devise commune, c'est-à-dire, participer.
pour le jeton dans clean_text: imprimer (jeton, token.lemma_)
Nombre de fréquences de mots:
Effectuons maintenant une analyse statistique du texte. Nous trouverons les dix premiers mots en fonction de leur fréquence dans le texte.
from collections import Counter words = [token.text pour token dans clean_text s’il n’est pas token.is_stop et n’est pas token.is_punct] word_freq = Compteur(mots) # 10 commonly occurring words with their frequencies common_words = word_freq.most_common(10) imprimer (common_words)

Analyse des sentiments
L’analyse des sentiments est le processus d’analyse du sentiment du texte. Une façon de le faire est à travers la polarité des mots., qu’il soit positif ou négatif.
VADER (Valence Aware Dictionary et Sentiment Reasoner) est une bibliothèque d’analyse des sentiments basée sur des règles et un lexique en Python. Utilise une série de lexiques de sentiments. Un lexique des sentiments est une série de mots qui sont assignés à leurs polarités respectives., c'est-à-dire, positif, négatif et neutre selon son sens sémantique.
Par exemple:
1. des mots comme bien, génial, étonnante, fantastique ils sont de polarité positive.
2. Des mots comme mauvais, pire, pathétique sont de polarité négative.
L'analyseur de sentiments VADER trouve les pourcentages de mots de polarité différente et donne les scores de polarité de chacun d'eux respectivement. La sortie de l'analyseur est notée à partir de 0 une 1, qui peut être converti en pourcentage. Il ne s'agit pas seulement de scores de positivité ou de négativité, mais aussi à quel point un sentiment est positif ou négatif.
Commençons par télécharger le package en utilisant pip.
pip installer VaderSentiment
Alors, analyser les scores de sentiment.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
vs = analyseur.polarity_scores(texte)
vs

PanneauUn panel est un groupe d’experts qui se réunit pour discuter et analyser un sujet spécifique. Ces forums sont courants lors des conférences, Séminaires et débats publics, où les participants partagent leurs connaissances et leurs points de vue. Les panneaux peuvent aborder une variété de domaines, De la science à la politique, et son objectif est d’encourager l’échange d’idées et la réflexion critique entre les participants.... de control del analizador de texto
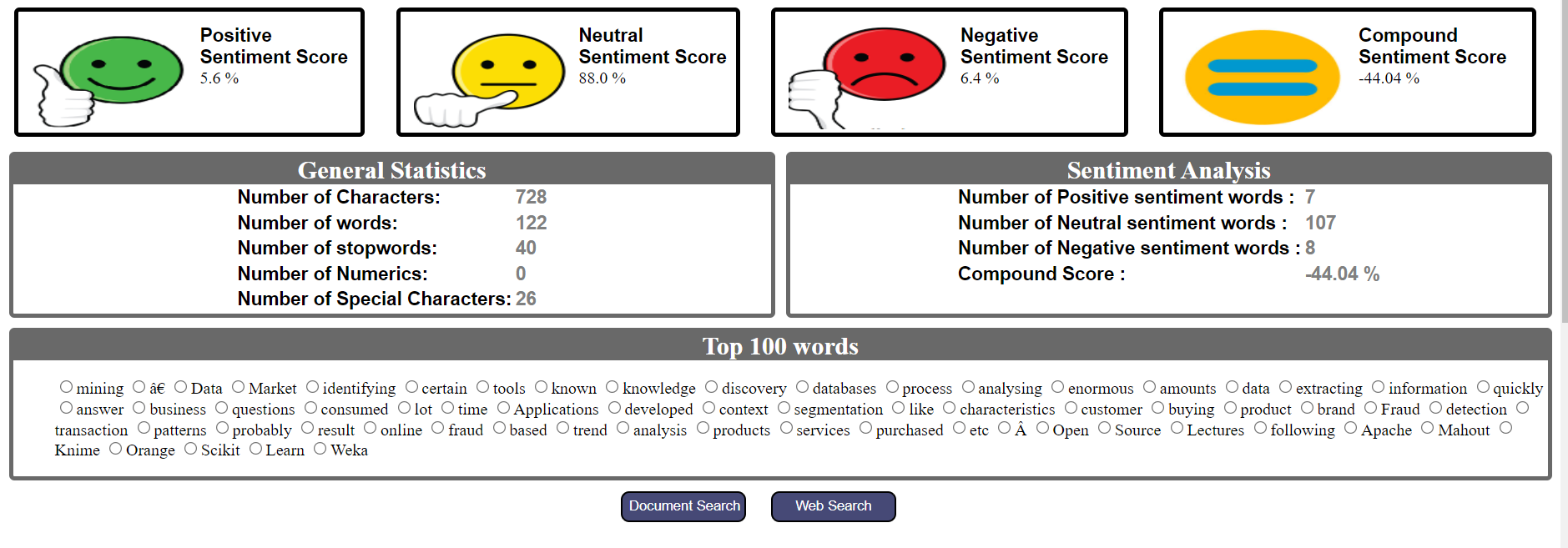
Les étapes ci-dessus peuvent être résumées pour créer un tableau de bord pour l’analyseur de texte. Inclure le nombre de mots, le nombre de caractères, le nombre de numéros, les N mots principaux, l’intention du texte, l’avis général, le score de l’avis positif, le score de l’avis négatif, notation neutre de l’opinion et nombre de mots d’opinion.
conclusion
NLP a eu un impact énorme dans des domaines tels que l’analyse des critiques de produits., recommandations, analyse des réseaux sociaux, traduction de texte et, donc, a fait d’énormes profits pour les grandes entreprises.
J'espère que cet article vous aidera à démarrer votre voyage dans le domaine de la PNL..
Et finalement, … Pas besoin de dire,
Merci pour la lecture!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





