Cet article a été publié dans le cadre du Blogathon sur la science des données
Ordre du jour
Nous avons tous construit une régression logistique à un moment donné de notre vie.. Même si nous n'avons jamais construit de modèle, nous avons définitivement appris théoriquement cette technique de modèle prédictif. Deux concepts simples et sous-estimés utilisés dans l'étape de prétraitement pour construire un modèle de régression logistique sont le poids de la preuve et la valeur de l'information.. Je souhaite vous remettre sur le devant de la scène à travers cet article..
Cet article est structuré comme suit:
- Introduction à la régression logistique
- Importance de la sélection des fonctionnalités
- Besoin d'un bon imputateur pour les caractéristiques catégorielles
- AFFLICTION
- IV
Commençons!
1. Introduction à la régression logistique
Le premier est le premier, nous savons tous que la régression logistique est un problème de classification. En particulier, on considère ici des problèmes de classification binaire.
Les modèles de régression logistique prennent à la fois des données catégorielles et numériques en entrée et en sortie la probabilité d'occurrence de l'événement..
Des exemples d'énoncés de problèmes qui peuvent être résolus avec cette méthode sont:
- Compte tenu des données client, Quelle est la probabilité que le client achète un nouveau produit présenté par une entreprise?
- Compte tenu des données requises, Quelle est la probabilité qu'un client de la banque fasse défaut sur un prêt ??
- Compte tenu des données météorologiques du mois dernier, quelle est la probabilité qu'il pleuve demain?
Toutes les déclarations ci-dessus ont eu deux résultats. (acheter et ne pas acheter, par défaut et non par défaut, pluie et pas pluie). Pourtant, un modèle de régression logistique binaire peut être construit. La régression logistique est une méthode paramétrique. Qu'est ce que ça signifie? Une méthode paramétrique comporte deux étapes.
1. Premier, nous assumons une forme ou une forme fonctionnelle. Dans le cas de la régression logistique, nous supposons que

2. Il faut prédire les poids / coefficients bi de sorte que, la probabilité d'un événement pour une observation x est proche de 1 si la valeur réelle de la cible est 1 et la probabilité est proche de 0 si la valeur réelle de la cible est 0.
Avec cette compréhension de base, comprenons pourquoi nous avons besoin d'une sélection de fonctionnalités.
2. Importance de la sélection des fonctionnalités
En cette ère numérique, nous sommes équipés d'une énorme quantité de données. Cependant, toutes les fonctions dont nous disposons ne sont pas utiles dans toutes les prédictions du modèle. Nous avons tous entendu le dicton, "Garbage in!, les ordures sortent!". Donc, Choisir les bonnes caractéristiques pour notre modèle est d'une importance primordiale.. Les fonctionnalités sont sélectionnées en fonction de la force prédictive de la fonctionnalité.
Par exemple, Disons que nous voulons prédire la probabilité qu'une personne achète une nouvelle recette de poulet dans notre restaurant.. Si nous avons une fonction: « Préférence alimentaire » avec des valeurs {Végétarien, Non végétarien, Oeuftarien}, nous sommes presque certains que cette fonctionnalité séparera clairement les personnes qui sont plus susceptibles d'acheter ce nouveau plat de celles qui ne l'achèteront jamais. . Donc, cette fonctionnalité a un pouvoir prédictif élevé.
Nous pouvons quantifier le pouvoir prédictif d'une caractéristique en utilisant le concept de valeur d'information qui sera décrit ici..
3. Besoin d'un bon imputateur pour les fonctions catégorielles
La régression logistique est une méthode paramétrique qui nous oblige à calculer une équation linéaire. Cela nécessite que toutes les fonctionnalités soient numériques. Cependant, nous pouvons avoir des caractéristiques catégorielles dans nos ensembles de données qui sont nominales ou ordinales. Il existe de nombreuses méthodes d'imputation telles que le codage à chaud ou simplement l'attribution d'un numéro à chaque classe de caractéristiques catégorielles. chacune de ces méthodes a ses avantages et ses inconvénients. Cependant, Je ne parlerai pas de la même chose ici.
Dans le cas de la régression logistique, nous pouvons utiliser le concept WoE (Poids de la preuve) imputer des caractéristiques catégorielles.
4. poids de la preuve
Après tout le contexte fourni, Nous sommes enfin arrivés au sujet du jour !!
La formule de calcul du poids de la preuve pour toute caractéristique est donnée par
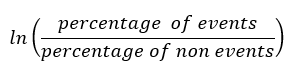
Avant de continuer à expliquer l'intuition derrière cette formule, prenons un exemple fictif:
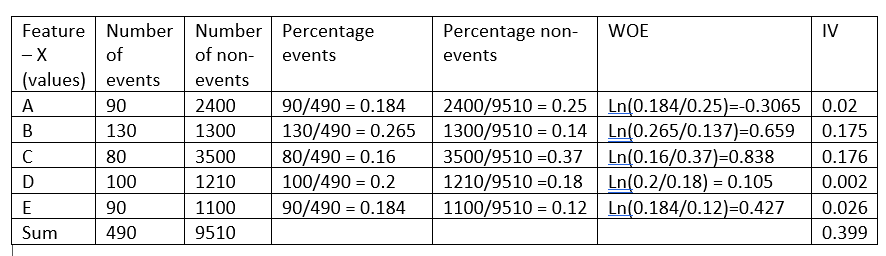
Le poids de la preuve indique le pouvoir prédictif d'une seule caractéristique par rapport à sa caractéristique indépendante.. Si l'une des catégories / les bacs d'une fonctionnalité ont une grande proportion d'événements par rapport à la proportion de non-événements, nous obtiendrons une valeur WoE élevée qui à son tour indique que cette classe d'entités sépare les événements des non-événements. .
Par exemple, considérer la catégorie C de la caractéristique X dans l'exemple ci-dessus, la proportion d'événements (0,16) est très faible par rapport à la proportion de non-événements (0,37). Cela implique que si la valeur de la caractéristique X est C, la valeur cible est plus susceptible d'être 0 (pas d'évènement). La valeur WoE nous indique seulement dans quelle mesure nous sommes convaincus que la fonction nous aidera à prédire correctement la probabilité d'un événement..
Maintenant que nous savons que WoE mesure le pouvoir prédictif de chaque bin / catégorie d'une fonctionnalité, quels sont les autres avantages de WoE ??
1. Valeurs WoE pour les différentes catégories d’un variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes.... Les caractéristiques catégorielles peuvent être utilisées pour imputer une caractéristique catégorielle et la convertir en caractéristique numérique, puisqu'un modèle de régression logistique nécessite que toutes ses caractéristiques soient numériques.
En examinant attentivement la formule WoE et l'équation de régression logistique à résoudre, nous voyons que WoE d'une caractéristique a une relation linéaire avec les probabilités logarithmiques. Cela garantit que l'exigence selon laquelle les caractéristiques ont une relation linéaire avec les probabilités logarithmiques est satisfaite..
2. Pour la même raison que ci-dessus, si une caractéristique continue n'a pas de relation linéaire avec les probabilités logarithmiques, la fonctionnalité peut être regroupée en groupes et une nouvelle fonctionnalité créée en remplaçant chaque conteneur par sa valeur WoE peut être utilisée à la place de la fonctionnalité d'origine. Pourtant, WoE est une bonne méthode de transformation de variables pour la régression logistique.
3. Lors de l'organisation d'une caractéristique numérique dans l'ordre croissant, si les valeurs WoE sont toutes linéaires, nous savons que l'entité a la relation linéaire correcte avec la cible. Cependant, si le WoE de la caractéristique n'est pas linéaire, nous devrions le rejeter ou envisager une autre transformation de variable pour assurer la linéarité. Donc, WoE nous donne un outil pour vérifier la relation linéaire avec la fonction dépendante.
4. WoE est meilleur que l'encodage à chaud car l'encodage à chaud nécessitera que vous créiez de nouvelles fonctionnalités h-1 pour prendre en charge une fonctionnalité catégorique avec des catégories h. Cela implique que le modèle n'aura pas à prédire les coefficients h-1 (avec un) au lieu de 1. Cependant, dans la transformation de la variable WoE, nous devrons calculer un coefficient unique pour la caractéristique considérée.
5. Valeur informative
Après avoir discuté de la valeur WoE, la valeur WoE nous indique le pouvoir prédictif de chaque bin d'une fonctionnalité. Cependant, une valeur unique représentant la puissance prédictive de l'ensemble de la fonctionnalité sera utile dans la sélection de la fonctionnalité.
L'équation pour IV est
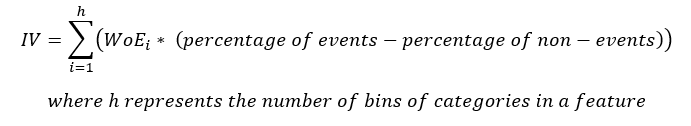
A noter que le terme (pourcentage d'événements – le pourcentage de non-événements) suit le même signe que WoE, donc, s'assure que le IV est toujours un nombre positif.
Comment interpréter la valeur de IV?
Le tableau ci-dessous vous donne une règle définie pour vous aider à sélectionner les meilleures fonctionnalités pour votre modèle.
| Valeur informative | pouvoir de prédiction |
| <0.02 | Inutile |
| 0,02 jusqu'à 0,1 | prédicteurs faibles |
| 0,1 jusqu'à 0,3 | prédicteurs moyens |
| 0,3 jusqu'à 0,5 | Prédicteurs forts |
| > 0,5 | Suspicaz |
Comme on le voit dans l'exemple ci-dessus, la caractéristique X a une valeur d'information de 0.399, ce qui en fait un puissant prédicteur et, donc, sera utilisé dans le modèle.
6. conclusion
Comme on le voit dans l'exemple ci-dessus, Les calculs WoE et IV sont bénéfiques et nous aident à analyser plusieurs points comme indiqué ci-dessous.
1. WoE aide à vérifier la relation linéaire d'une fonctionnalité avec sa fonctionnalité dépendante à utiliser dans le modèle.
2. WoE est une bonne méthode de transformation variable pour les caractéristiques continues et catégorielles.
3. WoE est meilleur que l'encodage à chaud, puisque cette méthode de transformation des variables n'augmente pas la complexité du modèle.
4. IV est un bon mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... pouvoir prédictif d’une caractéristique et aide également à signaler la caractéristique suspecte.
Bien que WoE et IV soient très utiles, assurez-vous toujours qu'il n'est utilisé qu'avec la régression logistique. Contrairement aux autres méthodes de sélection de fonctionnalités disponibles, les fonctionnalités sélectionnées par IV peuvent ne pas être le meilleur ensemble de fonctionnalités pour la construction de modèles non linéaires.
J'espère que cet article vous a aidé à comprendre le fonctionnement de WoE et IV..
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





