Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
L'apprentissage automatique est un domaine technologique développé avec d'immenses compétences et applications dans l'automatisation des tâches, où aucune intervention humaine ou programmation explicite n'est nécessaire.
La puissance de l'apprentissage automatique est si grande que nous pouvons voir que ses applications sont à la mode presque partout dans notre vie quotidienne.. Le ML a résolu de nombreux problèmes qui existaient auparavant et a fait progresser considérablement les entreprises du monde.
Aujourd'hui, nous analyserons l'un de ces problèmes pratiques et créerons une solution (maquette) par nous-mêmes en utilisant ML.
Qu'est-ce qu'il y a de si excitant à propos de ça?
Bon, nous allons implémenter notre modèle construit à l'aide des applications Flask et Heroku. Et enfin, nous aurons des applications Web entièrement fonctionnelles entre nos mains.
Pourquoi est-il important de mettre en œuvre votre modèle?
Les modèles d'apprentissage automatique visent généralement à être une solution à un ou plusieurs problèmes existants. Et à un moment de ta vie, vous devez avoir pensé comment votre modèle serait une solution et comment les gens l'utiliseraient-ils? En réalité, les gens ne peuvent pas utiliser leurs cahiers et coder directement, et c'est là que vous devez implémenter votre modèle.
Vous pouvez implémenter votre modèle, en tant qu'API ou service Web. Ici, nous utilisons le micro-framework Flask. Flask définit un ensemble de restrictions pour l'application Web pour envoyer et recevoir des données.
Attention système de prévision des prix
Nous sommes sur le point de mettre en œuvre un modèle ML pour la prédiction et l'analyse des prix de vente des voitures. Ce type de système est utile pour de nombreuses personnes.
Imaginez une situation où vous avez une vieille voiture et vous voulez la vendre. Bien sûr, vous pouvez approcher un agent pour cela et trouver le prix du marché, mais plus tard, vous devrez payer de l'argent de votre poche pour leur service lors de la vente de votre voiture. Mais, Et si vous pouviez connaître le prix de vente de votre voiture sans l'intervention d'un agent? Ou si vous êtes un agent, cela facilitera certainement votre travail. Oui, ce système a déjà appris les prix de vente précédents pendant des années de diverses voitures.
Ensuite, pour être clair, Cette application web mise en place vous fournira le prix de vente approximatif de votre voiture selon le type de carburant, des années de service, le prix de la salle d'exposition, le nombre d'anciens propriétaires, les kilomètres parcourus, si vous êtes distributeur / individuel et enfin si le type de transmission est manuel / automatique. Et c'est un point de brownie.
Tout type de modification peut également être intégré ultérieurement dans cette application. Il n'est possible de faire plus tard une installation pour rencontrer des acheteurs. C'est une bonne idée pour un grand projet que vous pouvez essayer. Vous pouvez l'implémenter en tant qu'application comme OLA ou n'importe quelle application de commerce électronique. Les applications d'apprentissage automatique ne s'arrêtent pas là. De la même manière, il y a des possibilités infinies que vous pouvez explorer. Mais pour l'instant, laissez-moi vous aider à créer le modèle de prévision des prix des voitures et son processus de mise en œuvre.
Importer un jeu de données
L'ensemble de données est attaché dans le dossier GitHub. Vérifiez ici
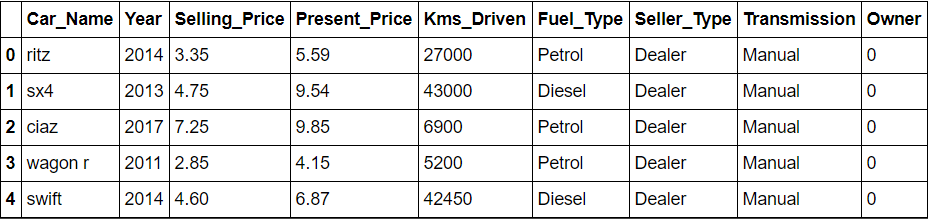
Les données consistent en 300 rangées et 9 Colonnes. Puisque notre objectif est de trouver le prix de vente, l'attribut cible et est également le prix de vente, les caractéristiques restantes sont prises pour l'analyse et les prédictions.
importer numpy en tant que np importer des pandas au format pd données = pd.read_csv(r'C:UtilisateursSURABHIOneDriveDocumentsprojectsdatasetscar.csv') data.head()
Ingénierie fonctionnelle
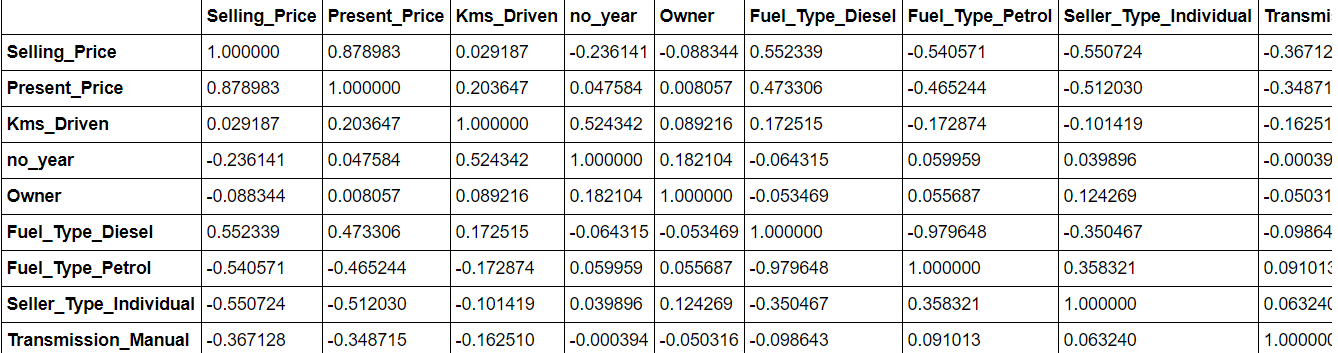
Les données. corr () cela vous donnera une idée de la corrélation entre tous les attributs du jeu de données. Des fonctionnalités plus corrélées peuvent être supprimées, car ils peuvent provoquer un ajustement excessif du modèle.
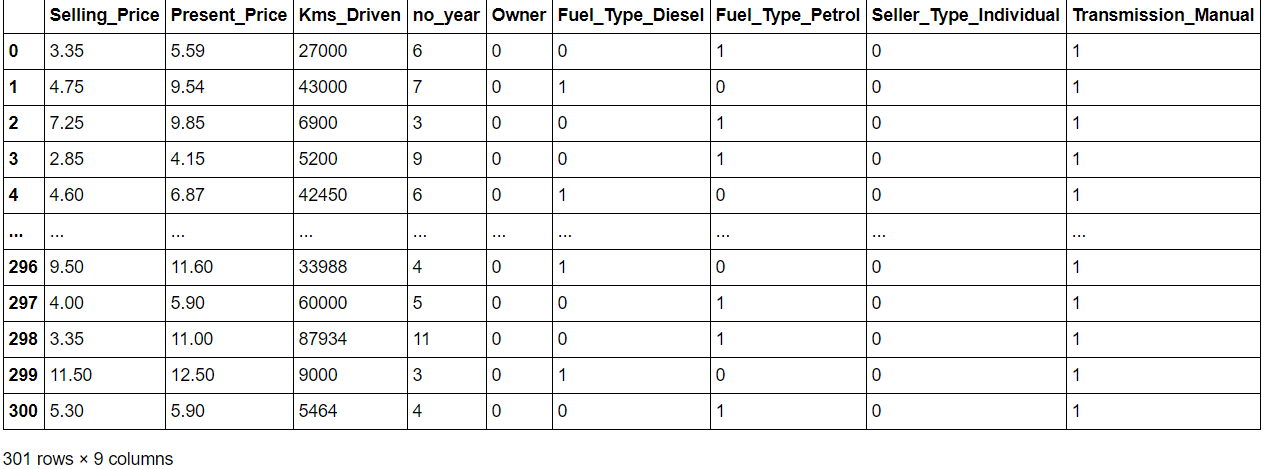
données = données.drop(['Voiture_Name'], axe=1) Les données['année actuelle'] = 2020 Les données['no_year'] = données['année actuelle'] - Les données['Année'] données = données.drop(['Année','année actuelle'],axe = 1) données = pd.get_dummies(Les données,drop_first=Vrai) données = données[['Prix de vente',« Prix_présent »,'Kms_Driven','no_year','Propriétaire','Fuel_Type_Diesel','Fuel_Type_Petrol', 'Seller_Type_Individual','Transmission_Manuel']] Les données
data.corr()
Ensuite, nous divisons les données en ensembles d'apprentissage et de test.
x = données.iloc[:,1:] y = data.iloc[:,0]
Découvrez l'importance des fonctions pour éliminer les fonctions indésirables
La bibliothèque extratressregressor vous permet de voir l'importance des fonctionnalités et, donc, supprimer les caractéristiques les moins importantes des données. Il est toujours recommandé de supprimer les fonctions inutiles car elles peuvent certainement produire de meilleurs scores de précision.
de sklearn.ensemble importer ExtreesRegressor model = ExtraTreesRegressor() model.fit(X,Oui)

model.feature_importances_
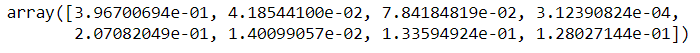
Optimisation des hyperparamètres
Ceci est fait pour obtenir les valeurs optimales à utiliser dans notre modèle, cela peut aussi dans une certaine mesure
aider à obtenir de bons résultats en prédiction
n_estimateurs = [entier(X) pour x dans np.linspace(commencer = 100, arrêt = 1200,num = 12)] max_features = ['auto','sqrt'] profondeur_max = [entier(X) pour x dans np.linspace(5,30,nombre = 6)] min_samples_split = [2,5,10,15,100] min_samples_leaf = [1,2,5,10]
grille = {'n_estimateurs': n_estimateurs,
'max_caractéristiques': max_caractéristiques,
'profondeur max': profondeur max,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
imprimer(la grille)
# Production
{'n_estimateurs': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200],
'max_caractéristiques': ['auto', 'sqrt'],
'profondeur max': [5, 10, 15, 20, 25, 30],
'min_samples_split': [2, 5, 10, 15, 100],
'min_samples_leaf': [1, 2, 5, 10]}
Essai de train fractionné
à partir de sklearn.model_selection import train_test_split #importation du module de fractionnement de test de train x_train, x_test,y_train,y_test = train_test_split(X,Oui,random_state=0,test_size=0.2)
Entraîner le modèle
Nous avons utilisé le régresseur de forêt aléatoire pour prédire les prix de vente car il s'agit d'un problème de régression et cette forêt aléatoire utilise plusieurs arbres de décision et a montré de bons résultats pour mon modèle.
à partir de sklearn.ensemble importer le modèle RandomForestRegressor = RandomForestRegressor()
hyp = RandomizedSearchCV(estimateur = modèle,
param_distributions=grille,
n_iter=10,
scoring = 'neg_mean_squared_error'
cv=5, verbeux = 2,
random_state = 42,n_jobs = 1)
hyp.fit(x_train,y_train)
hyp est un modèle créé en utilisant les hyperparamètres optimaux obtenus par validation croisée de recherche aléatoire
Production
Maintenant, nous utilisons enfin le modèle pour prédire l'ensemble de données de test.
y_pred = hyp.predict(x_test) y_pred

Pour utiliser le framework Flask pour le déploiement, il est nécessaire de packager tout ce modèle et de l'importer dans un fichier Python pour créer des applications web. Donc, nous vidons notre modèle dans le fichier pickle en utilisant le code donné.
importer des cornichons
fichier = ouvrir("fichier.pkl", "wb") # ouverture d'un nouveau fichier en écriture
cornichon.dump(hype, déposer) # vidage du modèle créé dans un fichier pickle
Code complet
https://github.com/SurabhiSuresh22/Car-Price-Prediction/blob/master/car_project.ipynb
Cadre de flacon
Ce dont nous avons besoin, c'est d'une application Web qui contient un formulaire pour prendre l'entrée de l'utilisateur et renvoyer les prédictions du modèle. Ensuite, nous allons développer une application web simple pour cela. L'interface est faite en utilisant HTML et CSS simples. Je vous conseille de revoir les bases du développement web pour comprendre le sens du code écrit pour l'interface. Ce serait bien aussi si je connaissais la monture de la fiole. Traverser est la vidéo si vous êtes nouveau sur Flask.
Laisse-moi t'expliquer, brièvement, ce que j'ai codé en utilisant Flask.
Ensuite, commençons le code en important toutes les bibliothèques requises utilisées ici.
de l'importation du flacon Flacon, render_template, demander importer des cornichons demandes d'importation importer numpy en tant que np
Comment savez-vous, nous devons importer le modèle enregistré ici pour faire les prédictions des données fournies par l'utilisateur. Nous importons donc le modèle enregistré
modèle = pickle.load(ouvert("modèle.pkl", "rb"))
Passons maintenant au code pour créer l'application de flacon réelle.
application = Flacon(_Nom_)
@app.route("/") # cela nous dirigera vers la page d'accueil lorsque nous cliquerons sur le lien de notre application Web
def maison():
retourner render_template("home.html") # page d'accueil
@app.route("/prédire", méthodes = ["PUBLIER"]) # cela fonctionne lorsque l'utilisateur clique sur le bouton de prédiction
def prédire():
année = entier(formulaire de demande["année"]) # prendre l'année entrée de l'utilisateur
tot_year = 2020 - année
present_price = float(formulaire de demande["prix_présent"]) #prendre le prix actuel
type_carburant = demande.formulaire["type de carburant"] # type de carburant de voiture
# if boucle pour attribuer des valeurs numériques
si type_carburant == "Essence":
fuel_P = 1
carburant_D = 0
autre:
fuel_P = 0
carburant_D = 1
kms_driven = entier(formulaire de demande["kms_conduit"]) # kilométrage total parcouru de la voiture
transmission = demande.formulaire["transmission"] # type de transmission
# attribution de valeurs numériques
si transmission == "Manuel":
transmission_manuel = 1
autre:
transmission_manuel = 0
vendeur_type = request.form["vendeur_type"] # type de vendeur
si seller_type == "Individuel":
vendeur_individu = 1
autre:
vendeur_individu = 0
propriétaire = entier(formulaire de demande["propriétaire"]) # nombre de propriétaires
valeurs = [[
prix_présent,
kms_conduit,
propriétaire,
tot_year,
carburant_D,
carburant_P,
vendeur_individuel,
transmission_manuel
]]
# créé une liste de toutes les valeurs saisies par l'utilisateur, puis l'utiliser pour la prédiction
prédiction = model.predict(valeurs)
prédiction = tour(prédiction[0],2)
# renvoyer la valeur prédite afin de l'afficher dans l'application Web frontale
retourner render_template("home.html", pred = "Le prix de la voiture est {} Lakh".format(flotter(prédiction)))
si _nom_ == "_principale_":
app.run(déboguer = Vrai)
Implémentation avec Heroku
Tout ce que vous avez à faire est de connecter votre référentiel GitHub contenant tous les fichiers nécessaires au projet avec Heroku. Pour tous ceux qui ne savent pas ce qu'est Heroku, Héroku est une plateforme qui permet aux développeurs de créer, exécuter et exploiter des applications cloud.
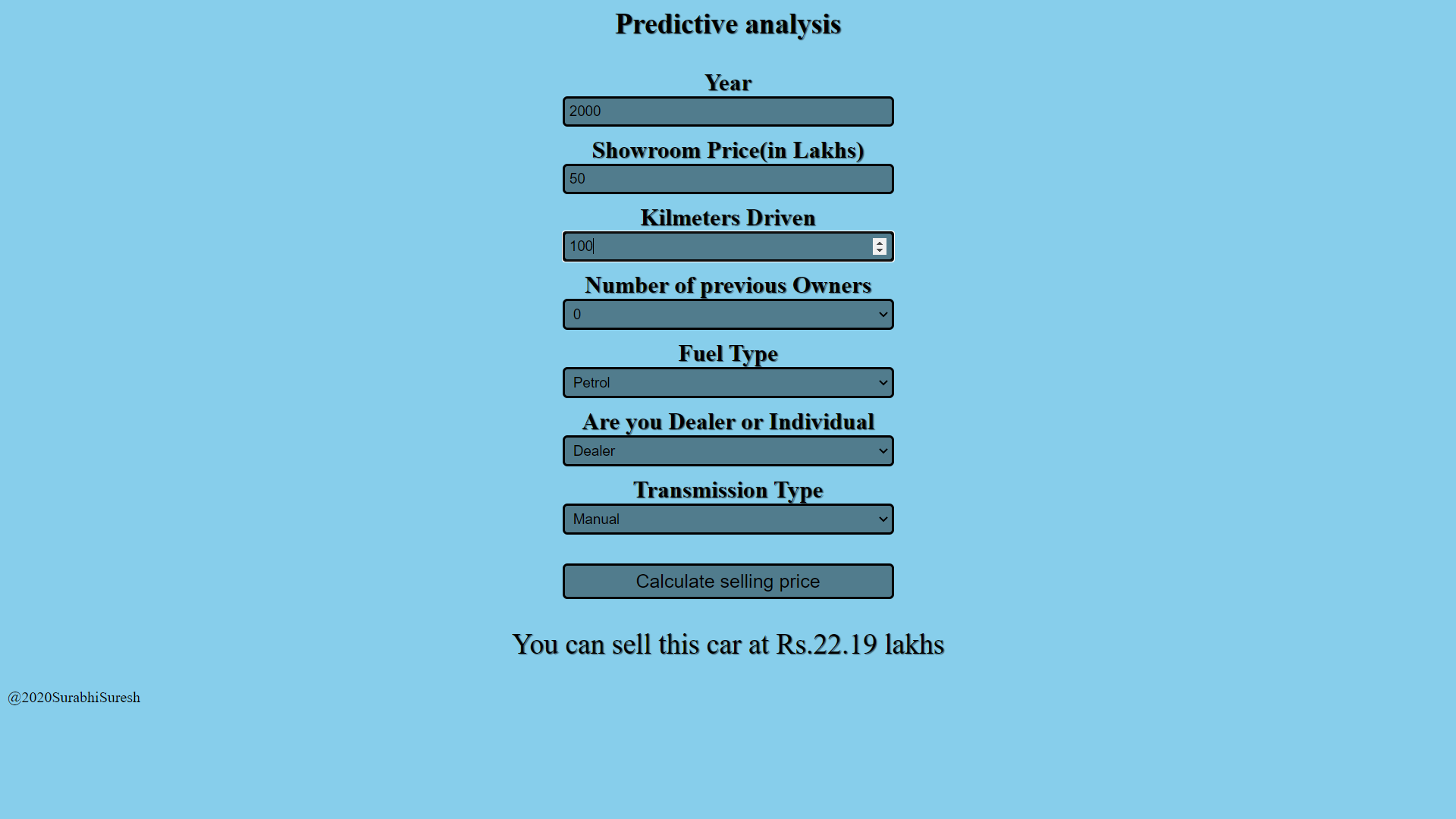
Ceci est le lien vers l'application Web que j'ai créée à l'aide de la plateforme Heroku. Ensuite, nous avons vu le processus de création et de mise en œuvre d'un modèle d'apprentissage automatique. Tu peux aussi le faire, en savoir plus et n'hésitez pas à essayer de nouvelles choses et à les développer.
https://car-price-analysis-app.herokuapp.com/
conclusion
Ensuite, nous avons vu le processus de création et de mise en œuvre d'un modèle d'apprentissage automatique. Tu peux aussi le faire, en savoir plus et n'hésitez pas à essayer de nouvelles choses et à les développer. N'hésitez pas à me contacter sur lié dans.
Merci
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





