Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
CSV il est un typique format de fichier c'est-à-dire fréquemment utilisé dans des domaines comme MÉTROonetario Prestations de service, etc. La plupart des candidatures ils peuvent permettre vous d'importer et d'exporter connaissance au format CSV.
Donc, il est nécessaire induire une bonne compréhension du format CSV à un pilote supérieur Les données vous êtes utilisation avec du quotidien.
Ensuite, au long de Cet article, nous verrons plusieurs cas de en fonctionnement avec des fichiers CSV et fournir des exemples pour tout lier au long de.
Table des matières
1. Qu'est-ce que CSV?
2. Opérations de base avec des fichiers CSV
- Travailler avec des fichiers CSV
- Ouvrir un fichier CSV
- Enregistrer un fichier CSV
3. Pourquoi les fichiers CSV?
4. Bases de la fonction Read_csv () par les pandas
- Importation de pandas
- Ouvrir un fichier CSV local
- Ouvrir un fichier CSV à partir d'une URL
5. Comprendre le paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... de la fonction read_csv ()
- paramètre sep
- paramètre index_col
- paramètre d'en-tête
- paramètre use_cols
- paramètre de compression
- sauts de paramètres
- paramètre nrows
- paramètre d'encodage
- paramètre error_bad_lines
- paramètre dtype
- paramètre parse_dates
- paramètre des convertisseurs
- paramètre na_values
Commençons,
Qu'est-ce qu'un CSV?
CSV (valeurs séparées par des virgules) peut-être un format de fichier simple utilisé stocker des données tabulaires, pareil que une feuille de calcul ou un base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes..... Le fichier CSV stocke les données tabulaires (chiffres et texte) en texte clair. Chaque ligne du fichier pourrait être un registre de données. Chaque enregistrement se compose de 1 ou plusieurs champs, séparé par des virgules, l'utilisation virgule comme séparateur de champ est-ce le source de nom pour ce format de fichier.
Opérations de base avec des fichiers CSV
Dans les opérations de base, comprenons les trois choses suivantes:
- Comment travailler avec des fichiers CSV
- Comment ouvrir un fichier CSV
- Comment enregistrer un fichier CSV
Travailler avec des fichiers CSV
Travailler avec des fichiers CSV ce n'est pas cette tâche fastidieuse mais c'est assez simple. Cependant, comptant sur votre flux de travail, là Ça peut être mises en garde que tout simplement tu pourrais vouloir observer Dehors pour.
Ouvrir un fichier CSV
Et tu as un fichier CSV, toi ouvrez-le dans excel sans trop de problèmes. Il suffit d'ouvrir Excel, ouvert et trouvez le fichier CSV figurer avec (ou faites un clic droit sur le fichier CSV et choisissez Ouvrir dans Excel). Après avoir ouvert le fichier, vous remarquerez que les infos est simple texte brut dans différentes cellules.
Enregistrer un fichier CSV
Et tu souhaites pour économiser beaucoup de votre classeur actuel dans un fichier CSV, vous avez utiliser le postérieur commandes:
Archives -> Garder comme … et choisissez le fichier CSV.
La plupart du temps, vous recevrez cet avertissement:

Source de l'image: Google images
Comprenons ce que cette erreur nous dit.
Ici, Excel essaie à mentionner est que vos fichiers CSV n'enregistrent aucun raisonnable mise en page dans le moins.
Par exemple, Les largeurs de colonnes ne seront pas enregistrées, styles de police, les couleurs, etc.
Uniquement vos anciennes données est-ce ainsi enregistré dans un excès fichier séparé par des virgules.
Notez que même après vous le mettre de côté, Excel continuera à afficher les formats que toi seul J'avais, alors ne te laisse pas berner par ça et pense que après ouverture le classeur à nouveau que ses formats seront toujours là. ils ne seront pas.
Même après avoir ouvert un CSV Entrez Exceller, si vous appliquez un format suffisant dans le moins, comment ajuster la largeur des colonnes faire de l'exercice les infos, Excel vous avertira toujours que toi seul je ne peux pas enregistrer les formats que toi seul Additionnel, toi recevoir un avertissement comme celui-ci:

Source de l'image: Google images
Ensuite, l'objectif les usages c'est-à-dire ses formats ne peuvent jamais être enregistrés dans des fichiers CSV.
Pourquoi les fichiers CSV?
Les fichiers CSV sont utilisés comme la manière la plus simple parler données entre différentes applications. Supposons que vous ayez une application de base de données et que vous vouliez exporter les infos dans un fichier. Et tu souhaites pour l'exporter dans un fichier Excel, l'application de la base de données ferait prend en charge l'exportation vers des fichiers XLS *.
Cependant, puisque le format de fichier CSV c'est extrêmement simple Et léger (beaucoup beaucoup donc que les fichiers XLS *), c'est plus facile pour varié applications pour le soutenir. Dans son utilisation de base, a une ligne de texte, avec tous colonne de données et moyens alternatifs pour une virgule. C'est tout. Et à cause de cette simplicité, c'est simple pour les développeurs. pour faire Exporter l'importation sens pratique avec des fichiers CSV à transférer connaissance entre les applications au lieu de beaucoup sophistiqué format de fichier.
Par exemple,
Nous allons avoir un données tabulées sous la forme ci-dessous:

Si nous convertissons ces données en un format CSV, donc ça ressemble à ça:

À présent, nous avons terminé avec toutes les bases des fichiers CSV. Ensuite, au dos de l'article, nous allons discuter de la façon de travailler avec les fichiers CSV en détail.
Importation de pandas
En premier lieu, nous importons les dépendances nécessaires comme Pandas Bibliothèque Python.
importer des pandas au format pd
Ensuite, la dépendance est importée, maintenant nous pouvons charger et lire facilement l'ensemble de données.
fonction lecture-csv
- C'est une fonction importante des pandas de lire les fichiers CSV et d'effectuer des opérations sur eux.
- Cette fonction nous aide à charger le fichier depuis votre machine locale ou depuis n'importe quelle URL.
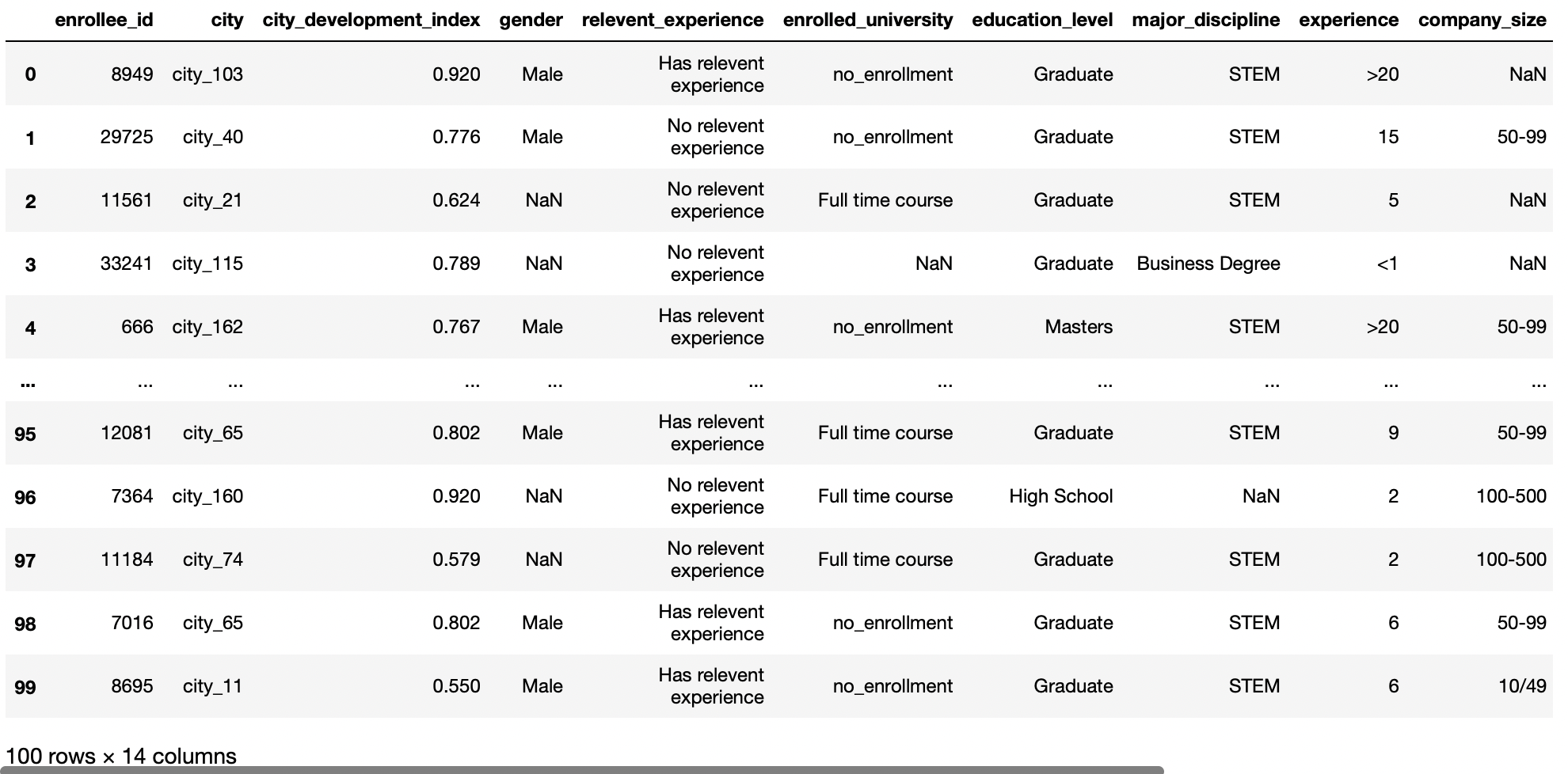
Ouvrir un fichier CSV local
Si le fichier est présent au même endroit que dans notre fichier Python, puis fournissez le nom de fichier juste pour télécharger ce fichier; au contraire, vous devez fournir le chemin relatif à celui-ci.
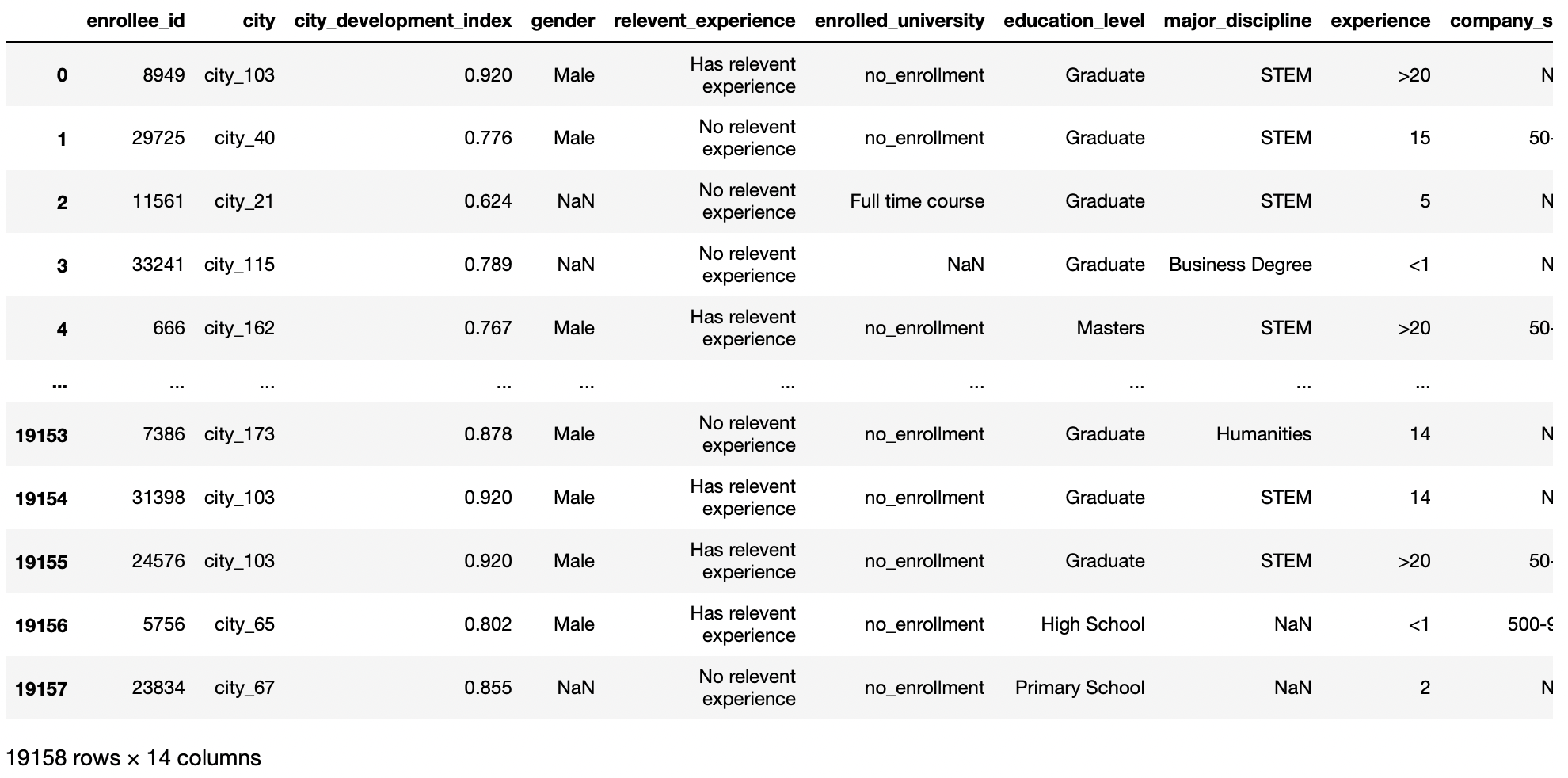
df = pd.read_csv('aug_train.csv')
df
Production:
Ouvrir un fichier CSV à partir d'une URL
Si le fichier n'est pas présent directement sur notre machine locale, mais nous devons rechercher les données d'une certaine URL, puis nous prenons l'aide du module de requêtes pour charger ces données.
demandes d'importation
depuis io importer StringIO
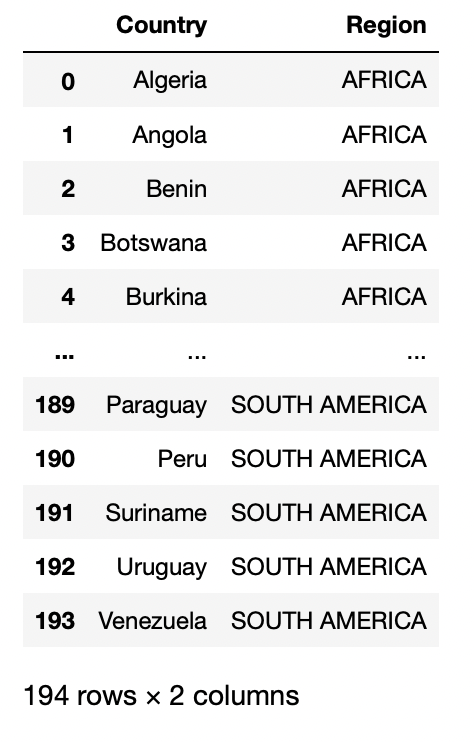
URL = "https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
en-têtes = {"Agent utilisateur": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; camping-car:66.0) Gecko/20100101 Firefox/66.0"}
req = requêtes.get(URL, en-têtes=en-têtes)
données = StringIO(req.texte)
pd.read_csv(Les données)
Production:
paramètre sep
Si nous avons un jeu de données dans lequel les entités d'une ligne particulière ne sont pas séparées par une virgule, alors nous devons utiliser le paramètre sep pour spécifier le séparateur ou le délimiteur.
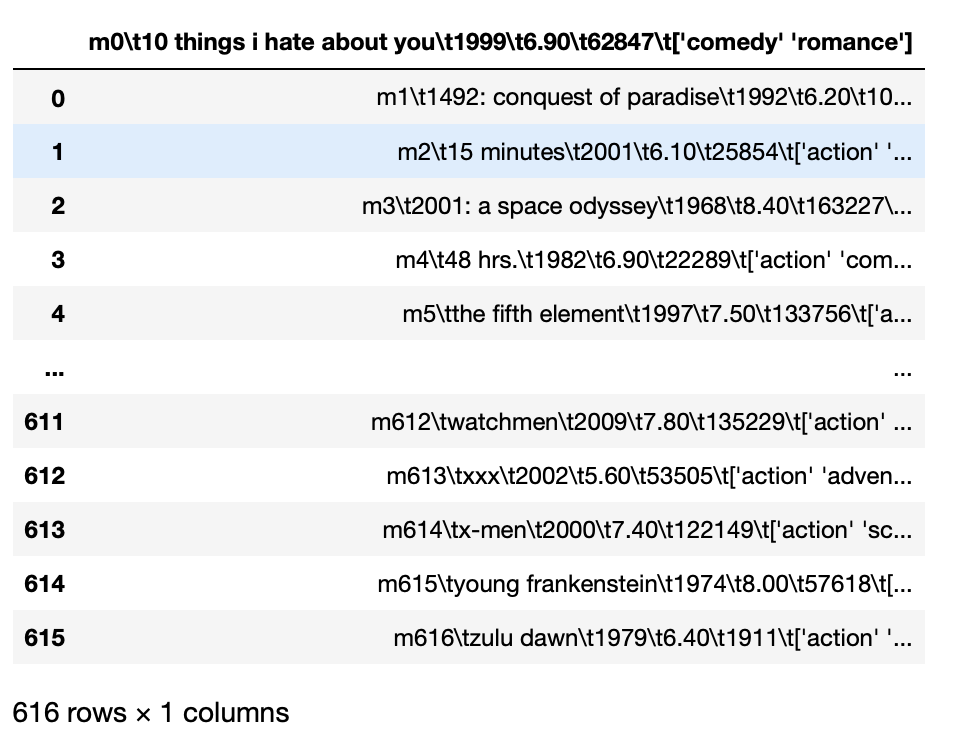
Par exemple, Si nous avons un fichier tsv, c'est-à-dire, les entités sont séparées par des tabulations et si on essaie de charger directement ces données, toutes les entités sont chargées combinées.
importer des pandas au format pd
pd.read_csv('film_titles_metadata.tsv')
Production:
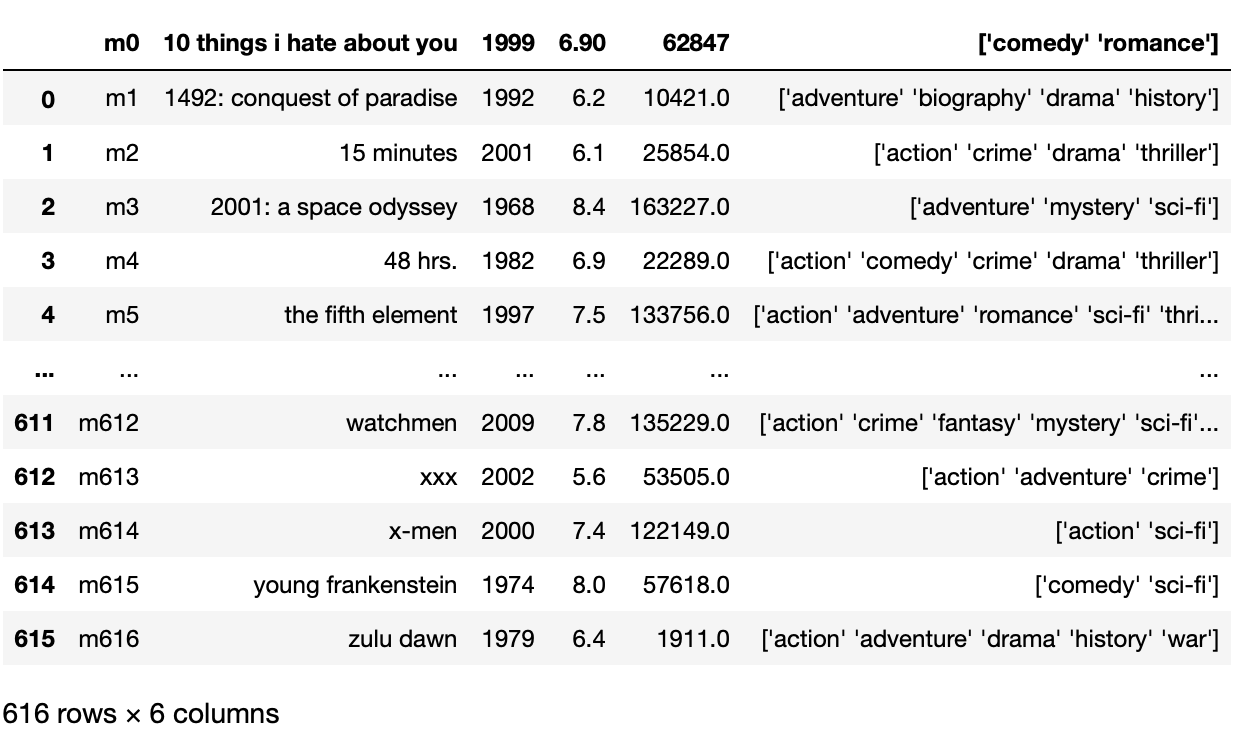
Pour résoudre le problème ci-dessus pour le fichier CSV, nous devons écraser le paramètre sep pour ‘t’ au lieu de ‘,’ qui est un séparateur par défaut.
importer des pandas au format pd
pd.read_csv('film_titles_metadata.tsv',sep = 't')
Production:
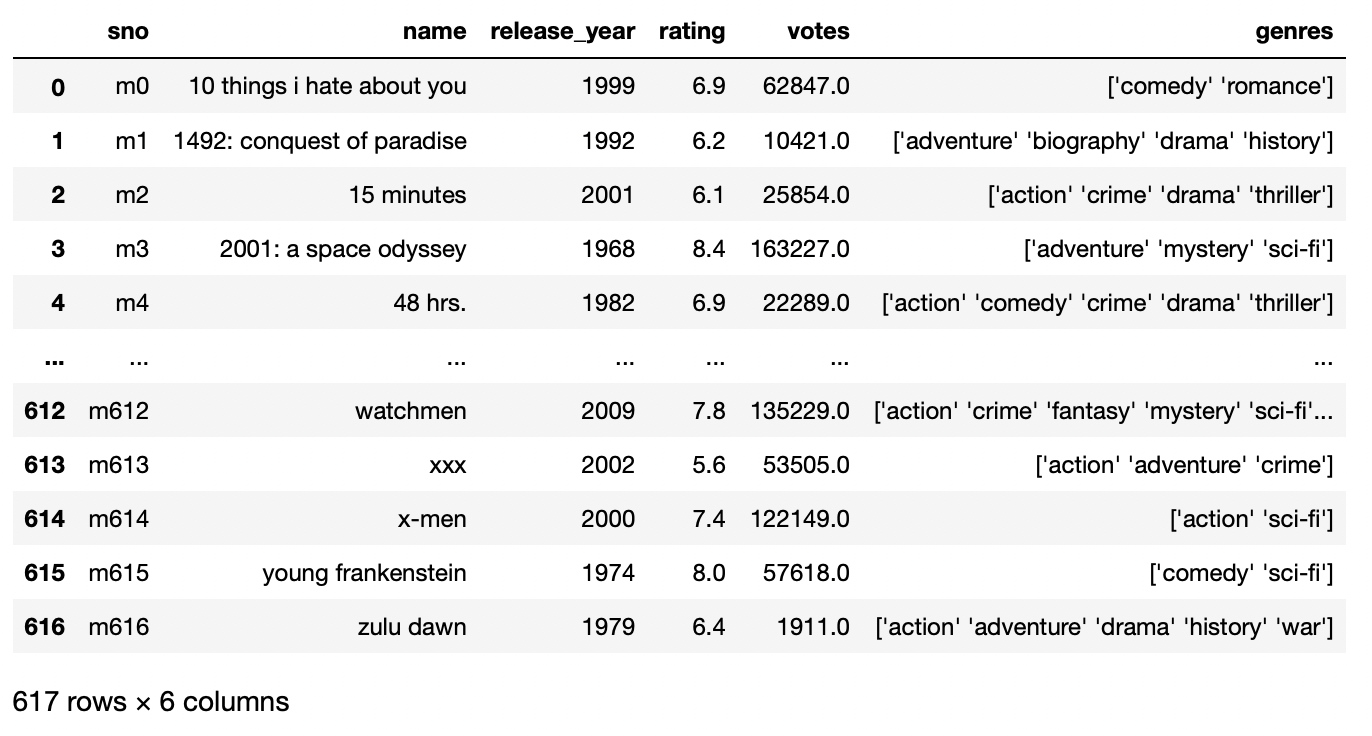
Dans l'exemple ci-dessus, nous avons observé que la première ligne est traitée comme le nom de la colonne, et pour résoudre ce problème et créer notre nom personnalisé pour les colonnes, nous devons spécifier la liste de mots avec des noms comme nom de la liste.
pd.read_csv('film_titles_metadata.tsv',sep = 't',noms=['sno','Nom','année de sortie','évaluation','vote','genres'])
Production:
paramètre index-col
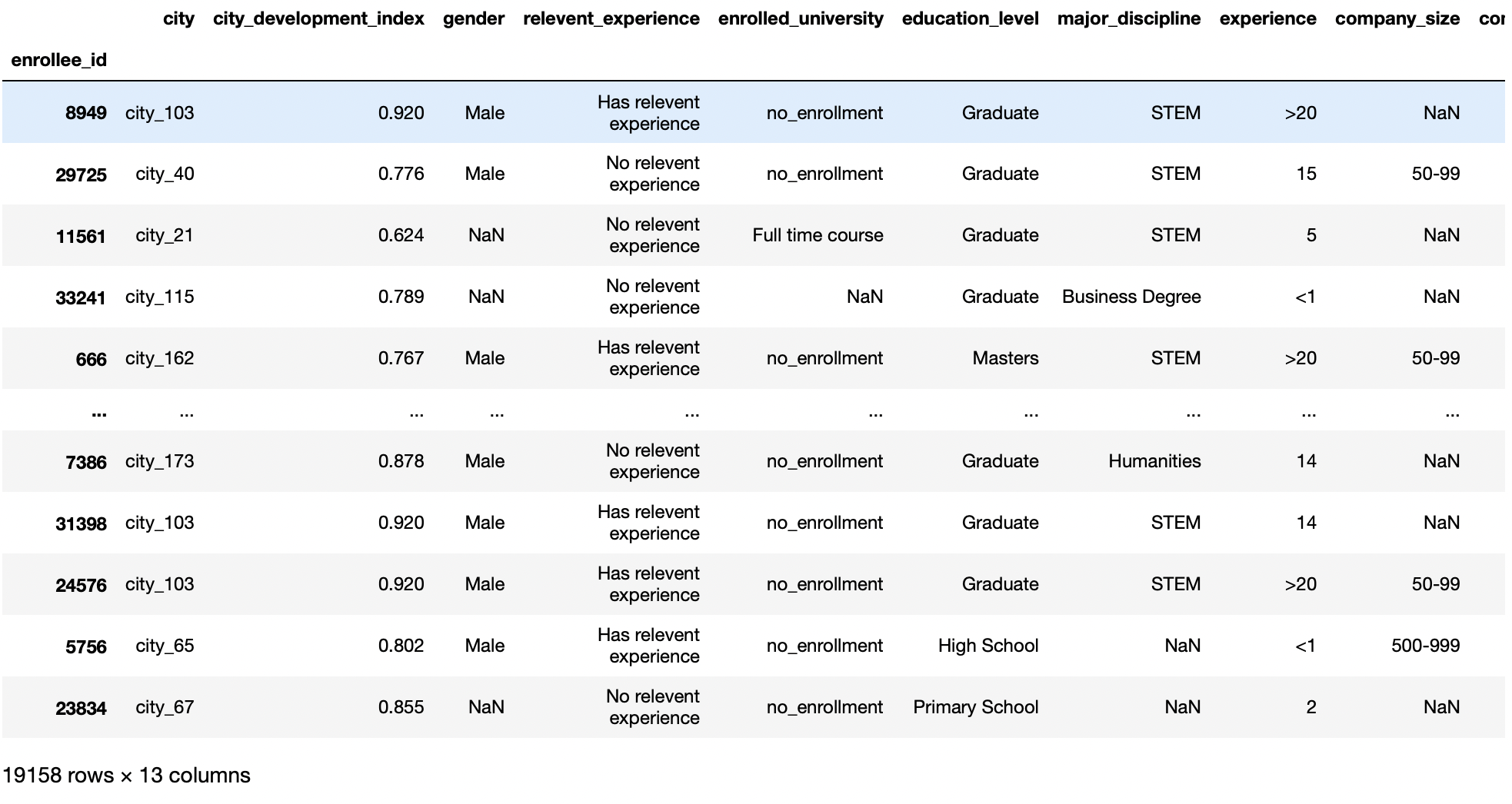
Ce paramètre nous permet d’établir quelles colonnes seront utilisées comme indiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines.... de la trame de données. La valeur par défaut de ce paramètre est Aucun, et les pandas ajouteront automatiquement une nouvelle colonne à partir de 0 pour décrire la colonne d'index.
Ensuite, nous permet d'utiliser une colonne comme étiquettes de ligne pour un DataFrame donné. Cette fonction est utile lorsqu'elle nous permet d'avoir une colonne ID présente avec notre ensemble de données et que cette colonne n'est pas affectée par nos prédictions, nous faisons donc de cette colonne notre index de ligne au lieu de la valeur par défaut.
pd.read_csv('aug_train.csv',index_col="enrollee_id")
Production:
paramètre d'en-tête
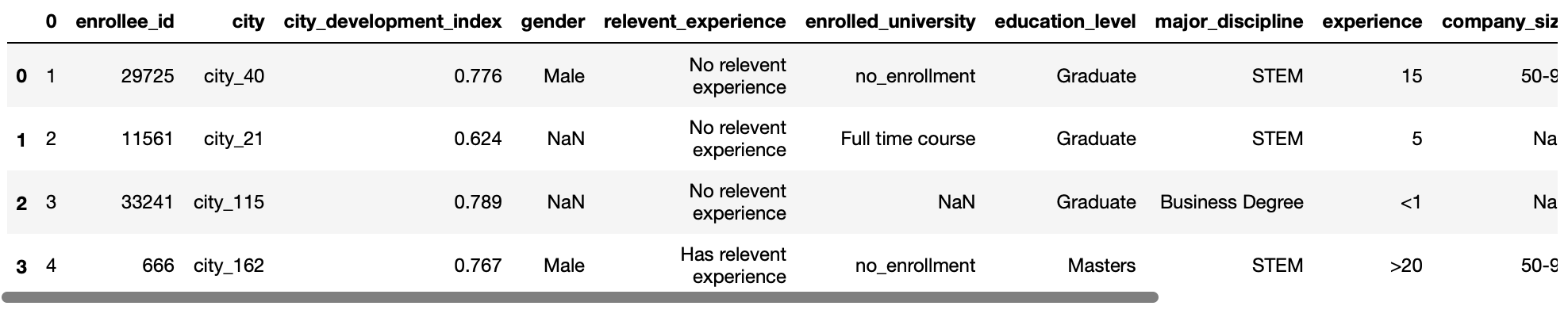
Cela nous permet de spécifier quelle ligne sera utilisée comme nom de colonne pour votre bloc de données. Attendez-vous à une entrée sous forme de valeur int ou d'une liste de valeurs int.
La valeur par défaut de ce paramètre est en-tête = 0, ce qui implique que la première ligne du fichier CSV sera considérée comme des noms de colonnes.
pd.read_csv('test.csv',en-tête=1)
Production:
paramètre use-cols
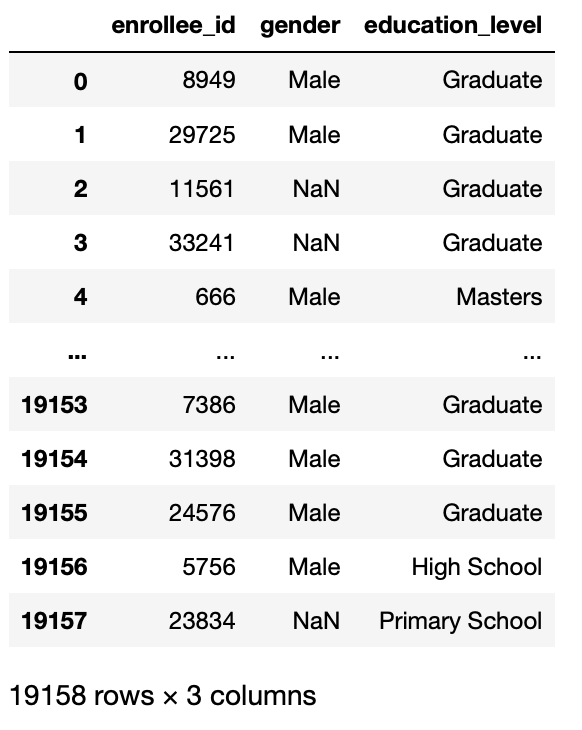
Spécifiez les colonnes à importer de l'ensemble de données complet vers le bloc de données. Vous pouvez saisir une liste de valeurs int ou directement les noms des colonnes.
Cette fonction est utile lorsque nous devons faire notre analyse uniquement sur certaines colonnes, pas dans toutes les colonnes de notre ensemble de données.
Ensuite, ce paramètre renvoie un sous-ensemble des colonnes de votre ensemble de données.
pd.read_csv('aug_train.csv',usecols =['identifiant_enrôlé','genre','niveau d'éducation'])
Production:
paramètre de compression
Si vrai et qu'une seule colonne est passée, renvoie la chaîne pandas au lieu d'un DataFrame.
pd.read_csv('aug_train.csv',usecols =['genre'],squeeze=Vrai)
Production:
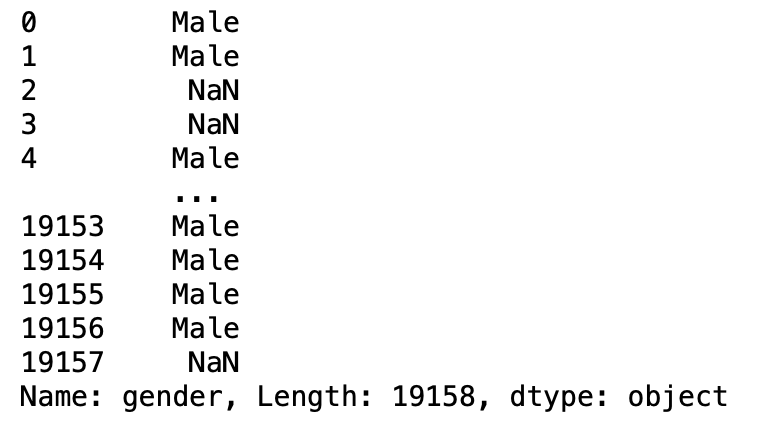
sauts de paramètres
Ce paramètre est utilisé pour ignorer les lignes passées dans la nouvelle trame de données.
pd.read_csv('aug_train.csv',sauts =[0,1])
Production:
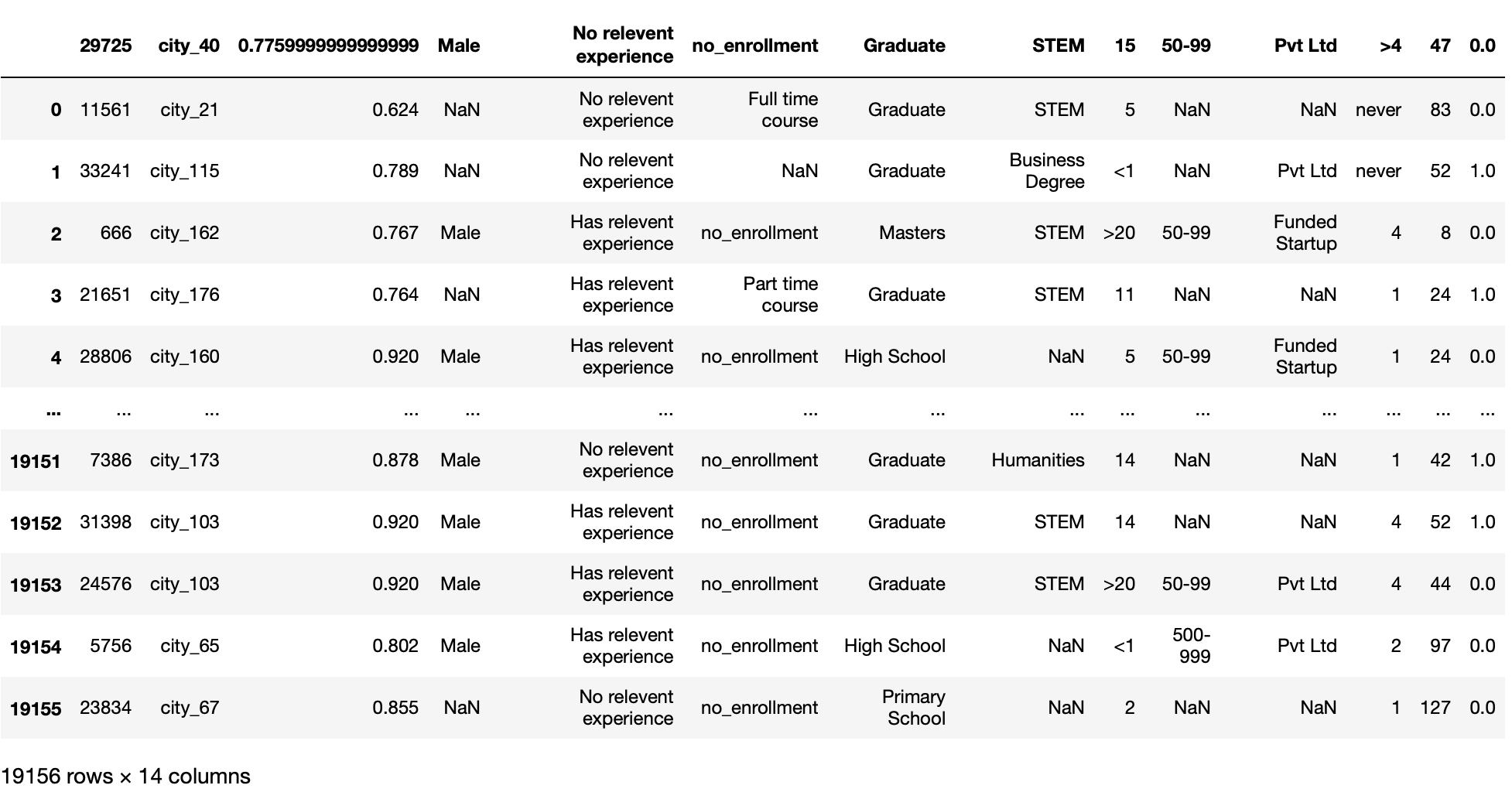
paramètre nrows
Cette fonction ne lit que le nombre fixe (décidé par l'utilisateur) des premières lignes du fichier. Vous avez besoin d'une valeur int.
Ce paramètre est utile lorsque nous avons un énorme ensemble de données et que nous voulons charger notre ensemble de données en morceaux au lieu de charger directement l'ensemble de données entier.
pd.read_csv('aug_train.csv',nrows = 100)
Production:
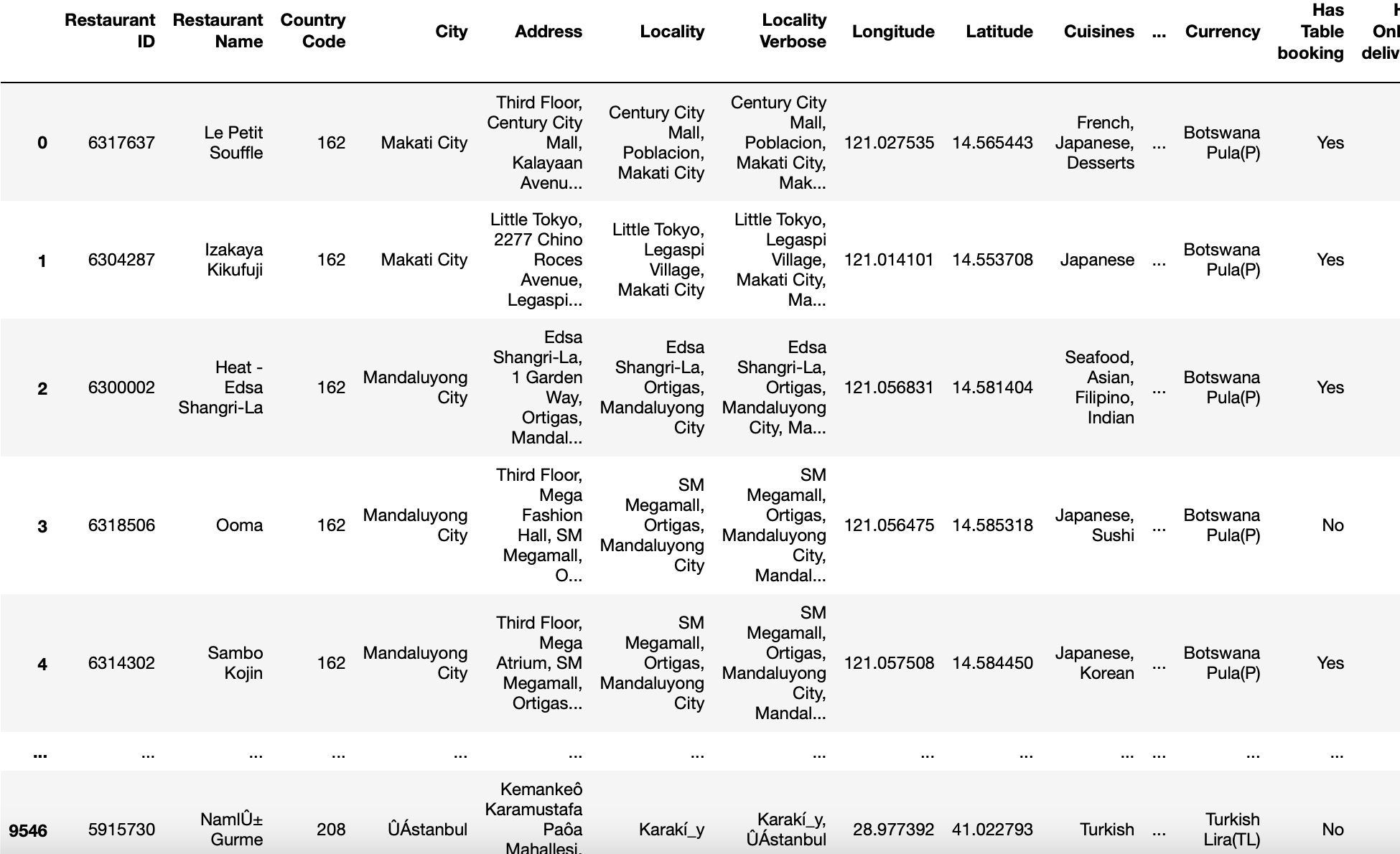
paramètre d'encodage
Ce paramètre permet de déterminer quel codage utiliser pour UTF lors de la lecture ou de l'écriture de fichiers.
Parfois, ce qui se passe, c'est que nos fichiers ne sont pas encodés de la manière par défaut, c'est-à-dire, UTF-8. Ensuite, enregistrez cela avec un éditeur de texte ou ajoutez le paramètre « Codificación = ‘utf-8 ′ ça ne marche pas. Dans les deux cas, renvoie l'erreur.
Ensuite, pour résoudre ce problème, nous appelons notre fonction read_csv avec encodage = ‘latin1 ′, encodage =’ iso-8859-1 ′ o codificación = ‘cp1252 ′ (ce sont quelques-uns des différents encodages trouvés dans Windows).
pd.read_csv('zomato.csv',encodage='latin-1')
Production:
paramètre error-bad-lines
Si nous avons un jeu de données dans lequel certaines lignes ont trop de champs (Par exemple, une ligne CSV avec trop de virgules), alors, par défaut, une exception est levée et provoque, et aucun DataFrame ne sera renvoyé.
Ensuite, pour résoudre ce genre de problème, nous devons rendre ce paramètre False, alors vous êtes « lignes défectueuses » sera supprimé du DataFrame renvoyé. (Uniquement valable avec l'analyseur C)
pd.read_csv('BX-Livres.csv', sep=';', encodage="latin-1",error_bad_lines=Faux)
Production:
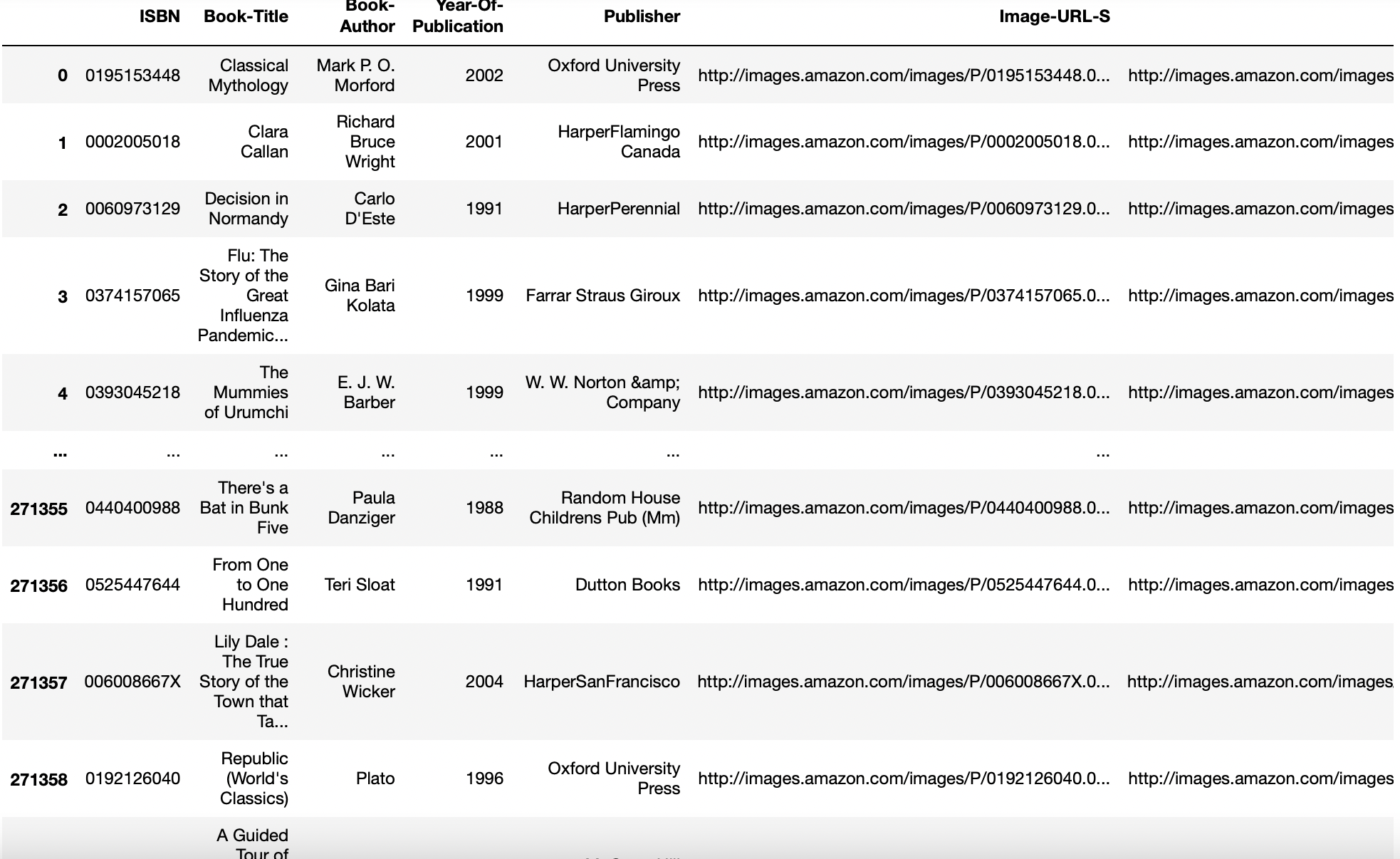
paramètre dtype
Type de données pour les données ou les colonnes. Par exemple, {‘une’: par exemple float64, ‘b’: par exemple int32}
Parfois, pour convertir nos colonnes du type de données float en type de données int, cette fonction est utile.
pd.read_csv('aug_train.csv',type={'cible':entier}).Info()
Production:
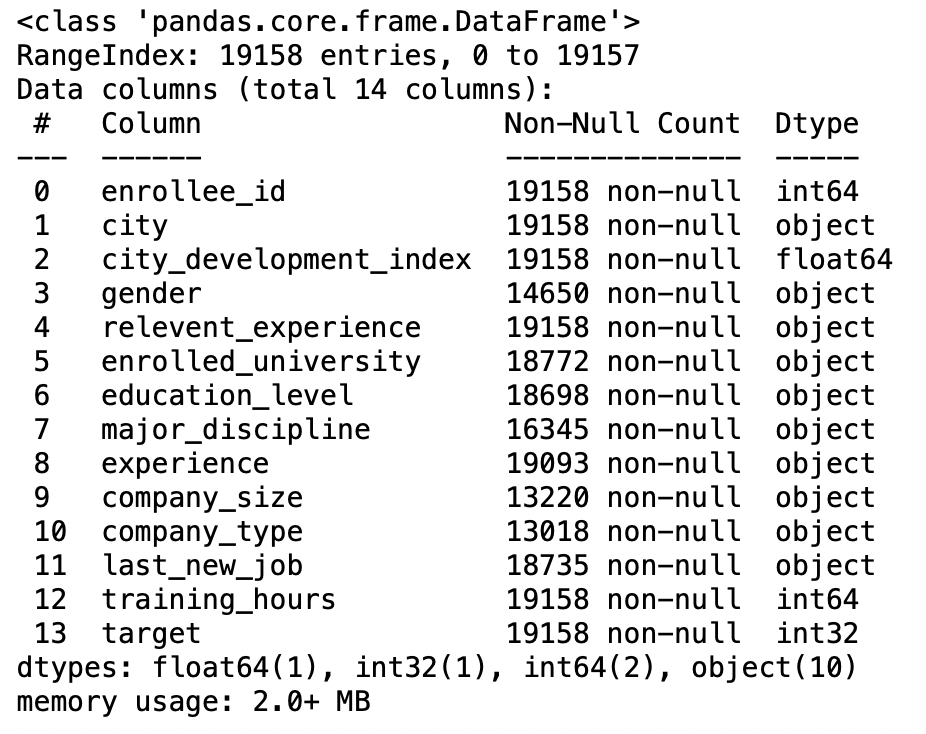
paramètre parse-dates
Si nous rendons ce paramètre True, puis essayez d'analyser l'index.
Par exemple, Et [1, 2, 3] -> essayez d'analyser les colonnes 1, 2, 3 chacun comme une colonne de date distincte et si nous devons combiner les colonnes 1 Oui 3 et analyser comme une seule colonne de date, utilisation [[1,3]].
pd.read_csv('Matchs IPL 2008-2020.csv',parse_dates=['Date']).Info()
Production:
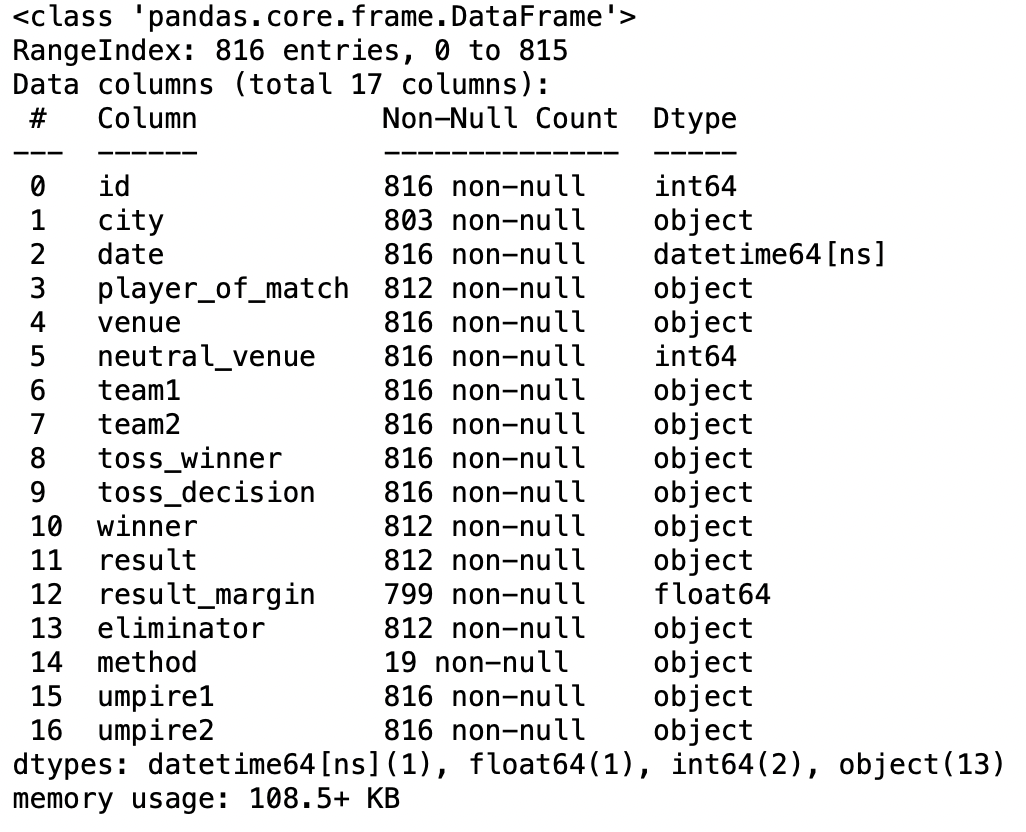
paramètre des convertisseurs
Ce paramètre nous aide à convertir les valeurs dans les colonnes en fonction d'une fonction personnalisée donnée par l'utilisateur.
def renommer(Nom):
si nom == "Challengers royaux Bangalore":
revenir "RCB"
autre:
retourner le nom
Renommer("Challengers royaux Bangalore")
Production:
‘RCB’
pd.read_csv('Matchs IPL 2008-2020.csv',convertisseurs={'équipe1':Renommer})
Production:
valeurs de paramètre dans
Comme nous savons, les valeurs manquantes par défaut seront NaN. Si nous voulons que d'autres chaînes soient considérées comme NaN, alors nous devons utiliser ce paramètre. Attendez-vous à une liste de chaînes en entrée.
Parfois, dans notre jeu de données, un autre type de symbole est utilisé pour les convertir en valeurs manquantes, donc à ce moment-là pour comprendre ces valeurs comme perdues, on utilise ce paramètre.
pd.read_csv('aug_train.csv',na_values=['Homme',])
Production:
Ceci termine notre discussion !!
REMARQUE: Dans cet article, Nous ne discuterons que des paramètres très utiles lorsque vous travaillez quotidiennement avec des fichiers CSV.. Mais si vous êtes intéressé à connaître plus de paramètres, consultez le site officiel des Pandas ici.
Ou vous pouvez vous référer à ceci Relier en outre.
Remarques finales
Merci pour la lecture!
Si vous avez aimé et que vous voulez en savoir plus, accédez à mes autres articles sur la science des données et l'apprentissage automatique en cliquant sur le Relier
N'hésitez pas à me contacter au Linkedin, Courrier électronique.
Tout ce qui n'est pas mentionné ou voulez-vous partager vos pensées? N'hésitez pas à commenter ci-dessous et je vous répondrai.
A propos de l'auteur
Chirag Goyal
Actuellement, Je poursuis mon Bachelor of Technology (B.Tech) en informatique et ingénierie de Institut indien de technologie Jodhpur (IITJ). Je suis très enthousiasmé par l'apprentissage automatique, les l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé... et l’intelligence artificielle.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





