Cet article a été publié dans le cadre du Blogathon sur la science des données
Dans le monde d'aujourd'hui axé sur la technologie, chaque seconde, une grande quantité de données est générée. Une surveillance constante et une analyse correcte de ces données sont nécessaires pour obtenir des informations significatives et utiles..
Temps réel Données du capteur, Appareils IoT, fichiers journaux, réseaux sociaux, etc. doivent être étroitement surveillés et traités immédiatement. Donc, pour l'analyse des données en temps réel, nous avons besoin d'un moteur de transmission de données hautement évolutif, fiable et tolérant aux pannes.
Transmission de données
Le streaming de données est un moyen de collecter en continu des données en temps réel à partir de plusieurs sources de données sous forme de flux de données.. Vous pouvez considérer Datastream comme une table qui est continuellement agrégée.
La transmission de données est essentielle pour gérer des quantités massives de données en direct. Ces données peuvent provenir de diverses sources telles que les transactions en ligne, fichiers journaux, capteurs, activités des joueurs dans le jeu, etc.
Il existe plusieurs techniques pour transmettre des données en temps réel, Quoi Apache Kafka, Diffusion Spark, Canal Apache etc. Dans ce billet, nous discuterons de la transmission de données en utilisant Diffusion Spark.
Diffusion Spark
Spark Streaming fait partie intégrante de API centrale de Spark pour l'analyse des données en temps réel. Nous permet de créer une application de diffusion en direct évolutive, haute performance et tolérance aux pannes.
Spark Streaming prend en charge le traitement des données en temps réel à partir de diverses sources d'entrée et le stockage des données traitées sur divers récepteurs de sortie.
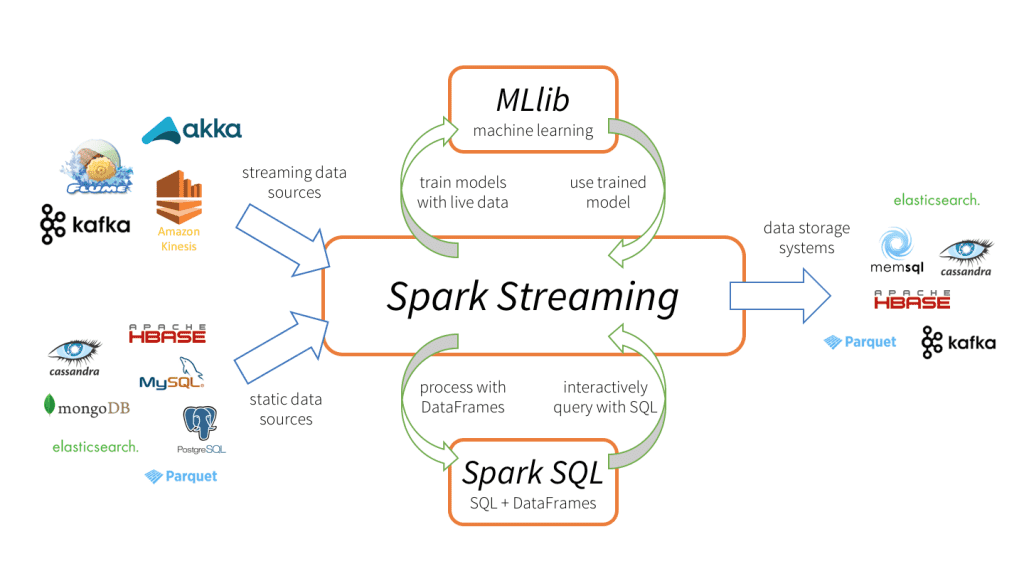
Spark Streaming 3 composants principaux, comme le montre l'image ci-dessus.
-
Sources de données d'entrée: Sources de données en continu (comme Kafka, Buse, Kinésis, etc.), sources de données statiques (comme MySQL, MongoDB, Cassandre, etc.), sockets TCP, Twitter, etc.
-
Moteur Spark Streaming: Pour traiter les données entrantes à l'aide de diverses fonctions intégrées, des algorithmes complexes. En outre, nous pouvons vérifier les émissions en direct, appliquer l'apprentissage automatique en utilisant respectivement Spark SQL et MLlib.
-
Éviers de sortie: Les données traitées peuvent être stockées dans des systèmes de fichiers, base de données (relationnel et NoSQL), panneaux en direct, etc.
De telles capacités de traitement de données uniques, format d'entrée et de sortie faire Diffusion Spark plus attirant, conduisant à une adoption rapide.
Avantages de Spark Streaming
-
Cadre de transmission unifié pour toutes les tâches de traitement des données (y compris l'apprentissage automatique, traitement graphique, Opérations SQL) dans les flux de données en direct.
-
Équilibrage de charge dynamique et meilleure gestion des ressources en équilibrant efficacement la charge de travail entre les travailleurs et en lançant la tâche en parallèle.
-
Profondément intégré avec des bibliothèques de traitement avancées telles que Spark SQL, MLlib, GraphX.
-
Récupération plus rapide des échecs en redémarrant les tâches ayant échoué en parallèle sur d'autres nœuds libres.
Les bases du streaming Spark
Spark Streaming divise les flux de données d'entrée en direct en lots qui sont ensuite traités par Moteur à étincelles.

DStream (flux discrétisé)
DStream est une abstraction de haut niveau fournie par Spark Streaming, essentiellement, désigne le flux continu de données. Peut être créé à partir de sources de données en streaming (comme Kafka, Buse, Kinésis, etc.) ou effectuer des opérations de haut niveau sur d'autres DStreams.
Intérieurement, DStream est un flux RDD et ce phénomène permet à Spark Streaming de s'intégrer à d'autres composants Spark tels que MLlib, GraphX, etc.

Lors de la création d'une application de streaming, nous devons également spécifier la durée du lot pour créer de nouveaux lots à intervalles de temps réguliers. Normalement, la durée du lot varie de 500 ms à plusieurs secondes. Par exemple, fils 3 secondes, puis les données d'entrée sont collectées tous les 3 secondes.
Spark Streaming vous permet d'écrire du code dans des langages de programmation populaires comme Python, Scala et Java. Jetons un coup d'œil à un exemple d'application de streaming qui utilise PySpark.
Exemple d'application
Comme nous en avons discuté plus tôt, Diffusion Spark il permet également de recevoir des flux de données via des sockets TCP. Écrivons donc un simple programme de streaming pour recevoir des flux de texte sur un port particulier, effectuer un nettoyage de texte de base (comment supprimer les espaces, suppression du mot vide, lématisation, etc.) et imprimer le texte propre sur l'écran.
Commençons maintenant à l'implémenter en suivant les étapes ci-dessous.
1. Créer un contexte pour transmettre et recevoir des flux de données
Contexte de diffusion est le point d'entrée principal pour toute application de streaming. Il peut être créé en instanciant Contexte de diffusion cours de pyspark.streaming module.
à partir de pyspark importer SparkContext depuis pyspark.streaming importer StreamingContext
Lors de la création Contexte de diffusion on peut préciser la durée du batch, par exemple, ici la durée du batch est 3 secondes.
sc = SparkContext(Nom de l'application = "Nettoyage de texte") strc = StreamingContext(sc, 3)
Une fois la Contexte de diffusion est créé, nous pouvons commencer à recevoir des données sous forme de DStream via le protocole TCP sur un port spécifique. Par exemple, ici le nom d'hôte est spécifié comme “hôte local” et le port utilisé est 8084.
text_data = strc.socketTextStream("hôte local", 8084)
2. Exécution d'opérations sur des flux de données
Après avoir créé un DStream objet, nous pouvons effectuer des opérations dessus selon les besoins. Ici, nous avons écrit une fonction de nettoyage de texte personnalisée.
Cette fonction convertit d'abord le texte saisi en minuscules, puis supprimez les espaces supplémentaires, caractères non alphanumériques, liens / URL, mots vides, puis enchaîner le texte à l'aide de la bibliothèque NLTK.
importation re
à partir de nltk.corpus importer des mots vides
stop_words = définir(mots.mots.mots('Anglais'))
à partir de nltk.stem importer WordNetLemmatizer
lemmatiseur = WordNetLemmatiseur()
def clean_text(phrase):
phrase = phrase.inférieur()
phrase = re.sub("s+"," ", phrase)
phrase = re.sub("W"," ", phrase)
phrase = re.sub(r"httpS+", "", phrase)
phrase =" ".rejoindre(mot pour mot dans la phrase.split() si le mot n'est pas dans stop_words)
phrase = [lemmatiseur.lemmatize(jeton, "v") pour jeton dans phrase.split()]
phrase = " ".rejoindre(phrase)
phrase de retour.bande()
3. Démarrer le service de diffusion en continu
Le service de streaming n'a pas encore démarré. Utilisez le début() fonction au sommet de la Contexte de diffusion objet pour le démarrer et continuer à recevoir les données de transmission jusqu'à la commande de terminaison (Ctrl + C ou Ctrl + AVEC) ne pas être reçu par attendreRésiliation () une fonction.
strc.start() strc.waitTermination()
REMARQUE – Le code complet peut être téléchargé à partir de ici.
Maintenant, nous devons d'abord exécuter le ‘Caroline du Nord'commander (Netchat Utilitaire) pour envoyer les données texte du serveur de données au serveur de streaming Spark. Netcat est un petit utilitaire disponible sur les systèmes de type Unix pour lire et écrire des connexions réseau via les ports TCP ou UDP. Vos deux options principales sont:
-
-je: Permettre Caroline du Nord pour écouter une connexion entrante au lieu d'initier une connexion à un hôte distant.
-
-k: Espèces Caroline du Nord pour rester à l'écoute d'une autre connexion une fois la connexion actuelle terminée.
Alors lancez ce qui suit Caroline du Nord commande dans le terminal.
nc -lk 8083
de la même manière, exécutez le script pyspark dans un autre terminal à l'aide de la commande suivante pour effectuer un nettoyage de texte sur les données reçues.
spark-submit streaming.py localhost 8083
D'après cette démonstration, tout texte tapé dans le terminal (fonctionnement chat net serveur) sera nettoyé et le texte nettoyé sera imprimé sur un autre terminal chaque 3 secondes (durée du lot).


Remarques finales
Dans cet article, Nous avons discuté Diffusion Spark, vos avantages dans la transmission de données en temps réel et un exemple d'application (utiliser les sockets TCP) recevoir des flux de données en direct et les traiter selon les besoins.
Les médias présentés dans cet article sur la mise en œuvre de modèles d'apprentissage automatique qui tirent parti de CherryPy et de Docker ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





