Ce blog a été publié dans le cadre de Blogathon sur la science des données 7
importer des pandas au format pd
Chaque projet d'analyse de données nécessite un ensemble de données. Ces ensembles de données sont disponibles dans divers formats de fichiers, en tant que .xlsx, .json, .csv, .html. Conventionnellement, les ensembles de données se trouvent principalement dans .csv format. CSV (O Valeurs séparées par des virgules), comme le nom le suggère, avoir des éléments de données séparés par des virgules. Les fichiers CSV sont des fichiers texte bruts qui ont une taille de fichier plus légère. En outre, Les fichiers CSV peuvent être visualisés et enregistrés sous forme de tableau dans des outils populaires tels que Microsoft Excel et Google Sheets.
Les virgules utilisées dans les fichiers CSV sont appelées délimiteurs. Considérez les délimiteurs comme une limite de séparation qui fait la distinction entre deux éléments de données suivants.

Lecture de fichiers CSV avec Pandas
Pour lire ces fichiers CSV, nous utilisons une fonction de la bibliothèque Pandas appelée lire_csv ().
df = pd.read_csv()
La fonction read_csv () il a des dizaines de paramètres dont un est obligatoire et d'autres sont facultatifs pour une utilisation ad hoc. Ce paramètre obligatoire spécifie le fichier CSV que nous voulons lire. Par exemple,
df = pd.read_csv("C:UtilisateursRahulDesktopabc.csv")
Noter: N'oubliez pas d'utiliser des doubles barres obliques inverses lors de la spécification du chemin du fichier.

(La source: ordinateur personnel)
Le paramètre sep
Un des paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... opcionales en read_csv () il est SEP, un nom court pour le séparateur. Cet opérateur est le délimiteur dont nous avons parlé avant. Ce paramètre sep indique à l'interpréteur, quel délimiteur est utilisé dans notre ensemble de données ou en termes simples, comment les éléments de données sont séparés dans notre fichier CSV.
La valeur par défaut du paramètre sep est la coma (,) ce qui signifie que si nous ne spécifions pas le paramètre sep dans notre fonction read_csv (), notre fichier est censé utiliser une virgule comme délimiteur. Donc, dans notre extrait de code ci-dessus, nous ne spécifions pas le paramètre sep, notre fichier était censé avoir des virgules comme délimiteurs.
Utiliser d'autres délimiteurs
ça peut arriver souvent, l'ensemble de données au format de fichier .csv a des éléments de données séparés par un délimiteur qui n'est pas une virgule. Cela inclut les points-virgules, deux points, espace de tabulation, barres verticales, etc. Dans ces cas, nous devons utiliser le paramètre sep dans la fonction read.csv (). Par exemple, un fichier appelé Exemple.csv c'est un fichier CSV séparé par des points-virgules.
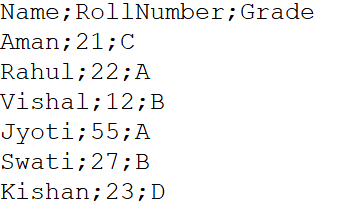
(La source: ordinateur personnel)
df = pd.read_csv("C:UtilisateursRahulDesktopExample.csv", sep = ';')
Lors de l'exécution de ce code, nous obtenons une trame de données appelée df:
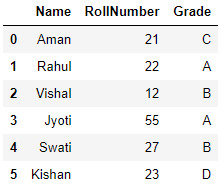
(La source: ordinateur personnel)
Séparateur de barres verticales
Donc, un fichier délimité par des barres verticales peut être lu par:
df = pd.read_csv("C:UtilisateursRahulDesktopExample.csv", sep = '|')
Séparateur de deux points
Et un fichier délimité par deux points peut être lu par:
df = pd.read_csv("C:UtilisateursRahulDesktopExample.csv", sep = ':')
Séparateur d'onglets
Nous pouvons souvent trouver des ensembles de données au format de fichier .tsv. Ces fichiers .tsv ont des valeurs séparées par des tabulations ou on peut dire qu'il a un espace de tabulation comme délimiteur. Ces fichiers peuvent être lus à l'aide de la même fonction .read_csv () des pandas et nous devons spécifier le délimiteur. Par exemple:
df = pd.read_csv("C:UtilisateursRahulDesktopExample.tsv", sep = 't')
de la même manière, d'autres séparateurs peuvent être utilisés en fonction du délimiteur identifié de nos données.
conclusion
Il est toujours utile de vérifier comment nos données sont stockées dans notre ensemble de données. Vous devez comprendre les données avant de commencer à les utiliser. Un délimiteur peut être identifié sans effort en vérifiant les données. Selon notre inspection, nous pouvons utiliser le délimiteur approprié dans le paramètre sep.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





