Foto de Daddy Mohlala en Unsplash
Les données c'est de l'eau, les purifier pour les rendre comestibles est une fonction de l'analyste de données: Kashish Rastogi
Table des matières:
- Approche du probléme
- Description des données
- Nettoyage de texte avec la PNL
- Trouver si le texte a: avec espace
- Nettoyage de texte avec bibliothèque de préprocesseur
- Analyse des sentiments des données
- Visualisation de données
Je prends les données twitter qui sont disponibles ici sur la plateforme DataPeaker.
Importation de bibliothèques
importer des pandas au format pd importation re importer plotly.express au format px importer nltk espace d'importation
Je charge un petit modèle spacieux. Il y a 3 tailles de modèle que vous pouvez télécharger spacy (peu, moyen et grand) selon vos exigences.
nlp = spacy.load('en_core_web_sm')
Les données ressemblent à ceci
df = pd.read_csv(r'emplacement du fichier') de DF['identifiant'] df.head(5)
Approche du probléme
Le point clé est de trouver le sentiment des données textuelles. Le texte fourni provient de clients de diverses entreprises technologiques qui fabriquent des téléphones, ordinateurs portables, gadgets, etc. La tâche consiste à identifier si les tweets ont un sentiment négatif, positif ou neutre envers l'entreprise.
Description des données
Étiqueter: La colonne d'étiquette a 2 valeurs uniques 0 Oui 1.
Pie: Les colonnes de tweet ont le texte fourni par les clients
Manipulation de données
Trouver la forme des données
Il y a 2 colonnes et 7920 Lignes.
df.forme
Classement des tweets
fig = px.pie(df, noms=df.label, trou=0.7, titre="Classement des tweets",
hauteur=250, color_discrete_sequence=px.colors.qualitative.T10)
fig.update_layout(marge=dict(t=100, b=40, l=60, r=40),
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(taille=25, couleur="#a5a7ab", famille ="Côté, sans empattement"),
police=dict(couleur="#8a8d93"),
)
Prenez un moment et regardez les données. Que vois-tu?

Source de l'image: https://unsplash.com/photos/LDcC7aCWVlo
- Il n'y a pas de balisage à analyser, est du texte brut (yaa!).
- Il y a beaucoup de choses à filtrer comme:
-
- L'identifiant Twitter est masqué (@Nom d'utilisateur), ce qui ne nous est d'aucune utilité.
- Étiquettes
- Liens
- Caractères spéciaux
- Nous voyons que le texte a une valeur numérique en eux.
- Il y a beaucoup de fautes de frappe et de contractions dans le texte.
- Il existe de nombreux noms d'entreprises (Sony, Pomme).
- Le texte n'est pas en minuscule
Nettoyons le texte
Trouver si le texte a:
- Noms d'utilisateur Twitter
- Étiquettes
- Valeurs numériques
- Liens
Suppression si le texte a:
- Nom d'utilisateur Twitter car vous ne fournirez aucune information supplémentaire pour le moment, car pour des raisons de sécurité, le nom d'utilisateur a été remplacé par des noms fictifs
- Les mots hashtag ne donneront aucune signification utile au texte dans l'analyse des sentiments.
- Le lien URL n'ajoutera pas non plus d'informations au texte.
- Retrait
- Notation pour un texte propre
- Mots plus courts que 3 peuvent être supprimés du texte en toute sécurité car les mots seront comme (soja, soja, il est) qui n'ont pas de sens ou de fonction spécifique dans le texte
- Les mots vides sont toujours la meilleure option à supprimer
Retrait Nom d'utilisateur du texte
Créez une fonction pour supprimer le nom d'utilisateur du texte avec le simple Trouver tout() fonction pandas. Où allons-nous sélectionner les mots qui commencent par '@'.
def remove_pattern(input_txt):
r = re.trouver(r"@(w+)", input_txt)
pour i dans r:
input_txt = re.sub(je, '', input_txt)
retourner input_txt
df['@_supprimer'] = np.vectorize(supprimer_motif)(df['tweeter'])
df['@_supprimer'][:3]

Découverte Étiquettes dans le texte
Créer une fonction pour extraire les hashtags du texte avec le simple Trouver tout() fonction pandas. Où allons-nous sélectionner les mots qui commencent par '#’ et les stocker dans une trame de données.
hashtag = []
def hashtag_extract(X):
# Boucle sur les mots dans le tweet
pour i dans x:
ht = re.trouver(r"#(w+)", je)
hashtags.append(ht)
retourner les hashtags

En passant la fonction et en extrayant les hashtags, nous pouvons maintenant visualiser le nombre de hashtags dans les tweets positifs et négatifs
# extraire les hashtags des tweets neg/pos dff_0 = hashtag_extract(df['tweeter'][df['étiqueter'] == 0]) dff_1 = hashtag_extract(df['tweeter'][df['étiqueter'] == 1]) dff_all = hashtag_extract(df['tweeter'][df['étiqueter']]) # liste de désimbrication dff_0 = somme(dff_0,[]) dff_1 = somme(dff_1,[]) dff_all = somme(dff_all,[])
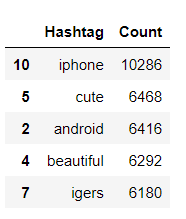
Compter les hashtags fréquents utilisés lorsque label = 0. FreqDist signifie qu'il nous dira combien de fois ce mot est apparu dans l'ensemble du document.
data_0 = nltk.FreqDist(dff_0)
data_0 = pd.DataFrame({'Hashtag': liste(data_0.keys()),
'Compter': liste(data_0.values())}).trier_valeurs(by='Compter', ascendant=Faux)
données_0[:5]
Si vous voulez en savoir plus sur Plotly et comment l'utiliser, les visites sont Blog. Chaque graphique est bien expliqué avec différents paramètres que vous devez garder à l'esprit lorsque vous tracez des graphiques.
fig = px.bar(données_0[:30], x='Hashtag', y='Compter', hauteur=250,
titre="Sommet 30 hashtags",
color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Faux),
fig.update_xaxes(ordre des catégories ="décroissant total")
fig.update_traces(hovertemplate=Aucun)
fig.update_layout(marge=dict(t=100, b=0, l=60, r=40),
hovermode ="x unifié",
xaxis_tickangle = 300,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(taille=25, couleur="#a5a7ab", famille ="Côté, sans empattement"),
police=dict(couleur="#8a8d93")
)
Passer du texte
phrases = pnl(str(texte))
Découverte Nordvaleurs numériques dans le texte
spacy fournit des fonctions like_num qui indique si le texte a des valeurs numériques ou non
pour le jeton dans les phrases:
si jeton.like_num:
num_texte = jeton.texte
imprimer(num_texte)
Découverte Lien URL dans le texte
spacy fournit la fonction like_url qui indique si le texte contient ou non un lien URL
# trouver des liens
pour le jeton dans les phrases:
si jeton.like_url:
text_links = jeton.text
imprimer(text_links)

Il existe une bibliothèque en Python qui aide à nettoyer le texte, vous pouvez trouver la documentation. ici
Actuellement, cette bibliothèque prend en charge le nettoyage, tokenisation et analyse
- URL
- Étiquettes
- Mentions
- Mots réservés (RT, FAV)
- Emojis
- Émoticônes
Importation de la bibliothèque
!pip installer tweet-préprocesseur importer le préprocesseur en tant que p
Appeler une fonction pour nettoyer le texte
def preprocess_tweet(ligne):
texte = ligne['tweeter']
texte = p.nettoyer(texte)
texte de retour
df['clean_tweet'] = df.appliquer(preprocess_tweet, axe=1) df[:6]

Comme on le voit, les colonnes clean_tweet n'ont que du texte, tous les noms d'utilisateur sont supprimés, liens hashtag et URL
Certaines des étapes de nettoyage sont toujours comme
- télécharger tout le texte
- Supprimer des partitions
- Supprimer des numéros
Code:
def preprocessing_text(texte):
# Mettre des minuscules
text = text.str.lower()
# Supprimer la ponctuation
text = text.str.replace('[^ ws]', '', regex=Vrai)
# Supprimer des chiffres
text = text.str.replace('[ré]+', '', regex=Vrai)
texte de retour
pd.set_option('max_colwidth', 500)
df['clean_tweet'] = prétraitement_texte(df['clean_tweet'])
df['clean_tweet'][:5]

Nous avons notre texte propre, supprimons les mots vides.
Quels sont les mots vides? Faut-il supprimer les mots vides?
Les mots vides sont les mots les plus courants dans toutes les langues naturelles. Les mots vides sont comme moi, soja, ton, lorsque, etc., ne pas ajouter d'informations supplémentaires au texte.
Pas besoin de supprimer les mots vides à chaque fois cela dépend de l'étude de cas, on retrouve ici le feeling du texte, donc nous n'avons pas besoin d'arrêter les mots.
à partir de nltk.corpus importer des mots vides
# Supprimer les mots vides
stop = mots vides.mots('Anglais')
df['clean_tweet'] = df['clean_tweet'].appliquer(lambda x: ' '.rejoindre([mot pour mot dans x.split() si le mot n'est pas dans (arrêter)]))
df['clean_tweet'][:5]
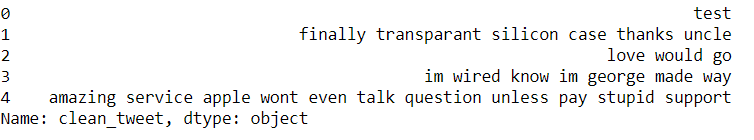
Après avoir mis en œuvre toutes les étapes, nous avons obtenu notre texte propre. À présent, Que faire du texte?
- Pouvons-nous savoir quels mots sont utilisés fréquemment?
- Quels mots sont utilisés le plus négativement / positivement dans le texte?
Tokeniser les mots et calculer la fréquence et le nombre de mots et les stocker dans une trame de données.
Une distribution de fréquence enregistre le nombre de fois où chaque mot s'est produit. Par exemple, un nouveau mot a été utilisé fréquemment dans les données complètes suivi d'autres mots iPhone, Téléphone, etc.
a = df['clean_tweet'].str.cat(sep=' ')
mots = nltk.tokenize.word_tokenize(une)
word_dist = nltk.FreqDist(mots)
dff = pd.DataFrame(word_dist.most_common(),
colonnes=['Mot', 'La fréquence'])
dff['Word_Count'] = dff.Word.apply(longueur)
dff[:5]
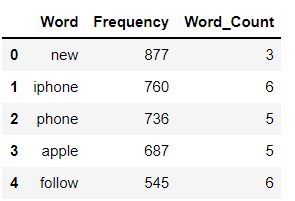
fig = px.histogramme(dff[:20], x='Mot', y='Fréquence', hauteur=300,
titre="Le plus commun 20 mots dans les tweets", color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Faux),
fig.update_xaxes(ordre des catégories ="décroissant total")
fig.update_traces(hovertemplate=Aucun)
fig.update_layout(marge=dict(t=100, b=0, l=70, r=40),
hovermode ="x unifié",
xaxis_tickangle = 360,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(taille=25, couleur="#a5a7ab", famille ="Côté, sans empattement"),
police=dict(couleur="#8a8d93"),
)
fig = px.bar(dff.queue(10), x='Mot', y='Fréquence', hauteur=300,
titre="Le moins commun 10 mots dans les tweets", color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Faux),
fig.update_xaxes(ordre des catégories ="décroissant total")
fig.update_traces(hovertemplate=Aucun)
fig.update_layout(marge=dict(t=100, b=0, l=70, r=40),
hovermode ="x unifié",
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(taille=25, couleur="#a5a7ab", famille ="Côté, sans empattement"),
police=dict(couleur="#8a8d93"),
)
fig = px.bar(une, hauteur=300, titre="Fréquence des mots dans les tweets",
color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Faux),
fig.update_xaxes(ordre des catégories ="décroissant total")
fig.update_traces(hovertemplate=Aucun)
fig.update_layout(marge=dict(t=100, b=0, l=70, r=40), showlegend=Faux,
hovermode ="x unifié",
xaxis_tickangle = 360,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(taille=25, couleur="#a5a7ab", famille ="Côté, sans empattement"),
police=dict(couleur="#8a8d93"),
)
Analyse des sentiments
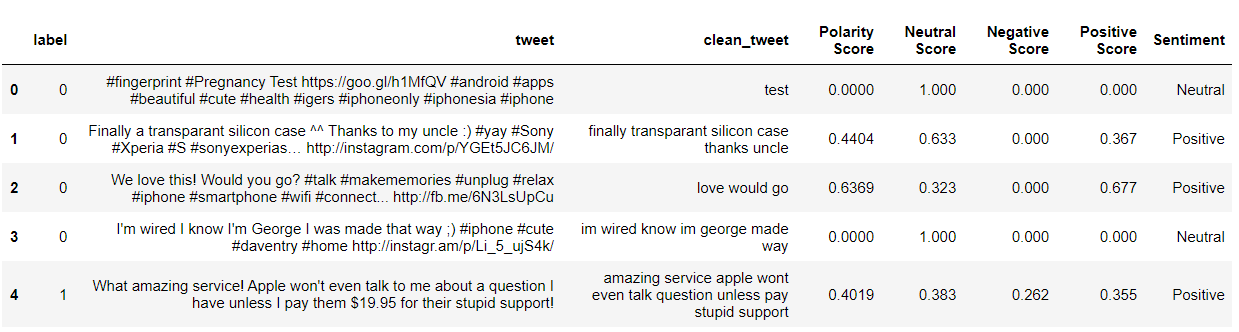
de nltk.sentiment.vader importer SentimentIntensityAnalyzer à partir de l'importation nltk.sentiment.util * #Analyse des sentiments SIA = SentimentIntensityAnalyzer() df["nettoyer_tweet"]= df["nettoyer_tweet"].astype(str) # Modèle d'application, Création de variables df[« Score de polarité »]=df["nettoyer_tweet"].appliquer(lambda x:SIA.polarity_scores(X)['composé']) df[« Score neutre »]=df["nettoyer_tweet"].appliquer(lambda x:SIA.polarity_scores(X)['Nouveau']) df[« Score négatif »]=df["nettoyer_tweet"].appliquer(lambda x:SIA.polarity_scores(X)['nég']) df[« Score positif »]=df["nettoyer_tweet"].appliquer(lambda x:SIA.polarity_scores(X)['pos']) # Conversion 0 à 1 Score décimal d'une variable catégorielle df['Sentiment']='' df.loc[df[« Score de polarité »]>0,'Sentiment']='positif' df.loc[df[« Score de polarité »]==0,'Sentiment']='Neutre' df.loc[df[« Score de polarité »]<0,'Sentiment']='Négatif' df[:5]
Classification des tweets basée sur le sentiment
fig_pie = px.pie(df, noms="Sentiment", titre="Classification des Tweets", hauteur=250,
trou=0.7, color_discrete_sequence=px.colors.qualitative.T10)
fig_pie.update_traces(textfont=dict(couleur="#fff"))
fig_pie.update_layout(marge=dict(t=80, b=30, l=70, r=40),
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(taille=25, couleur="#a5a7ab", famille ="Côté, sans empattement"),
police=dict(couleur="#8a8d93"),
légende=dict(orientation="h", yanchor="bas", y = 1, xancre ="droit", x=0,8)
)
conclusion:
Nous avons vu comment nettoyer les données de texte lorsque nous avons un nom d'utilisateur Twitter, hashtag, Liens URL, chiffres et a fait une analyse des sentiments sur les données textuelles.
Nous avons vu comment trouver si le texte contient des liens URL ou des chiffres à l'aide de spacy.
A propos de l'auteur:
Pouvez-vous me connecter
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





