introduction
Théorie de l'estimation Oui Tests d'hypothèses sont les concepts très importants de la statistique qui sont largement utilisés par Statistiques, Ingénieurs en apprentissage automatique, Oui Scientifiques des données.
Ensuite, dans ce post, nous discuterons des estimateurs ponctuels dans la théorie de l'estimation des statistiques.
Table des matières
1. Estimateurs et estimateurs
2. Que sont les estimateurs ponctuels?
3. Quel est l'échantillon aléatoire et la statistique?
4. Deux statistiques courantes utilisées:
- Échantillon moyen
- Écart de l'échantillon
5. Propriétés des estimateurs ponctuels
- Impartialité
- Efficace
- Cohérent
- Suffisant
6. Méthodes courantes de recherche d'estimations ponctuelles
7. Estimation ponctuelle vs estimation par intervalle
Estimation et estimateurs
Soit X une variable aléatoire de distribution FX(X; ??), où est un paramètre inconnu. Un échantillon aléatoire, X1, X2, –, XNord, de taille n prise à X.
Le problème d'estimation ponctuelle consiste à sélectionner une statistique, g (X1, X2, —, XNord), qui estime au mieux le paramètre θ.
Une fois observé, la valeur numérique de g (X1, X2, —, XNord) ça s'appelle l'estimation et les statistiques g (X1, X2, —, XNord) ça s'appelle estimateur.
Que sont les estimateurs ponctuels?
Les estimateurs ponctuels sont définis comme les fonctions utilisées pour trouver une valeur approximative d'un paramètre de population à partir d'échantillons aléatoires de la population.. Ils prennent l'aide d'échantillons de données d'une population pour établir une estimation ponctuelle ou une statistique qui sert de meilleure estimation d'un paramètre inconnu d'une population.
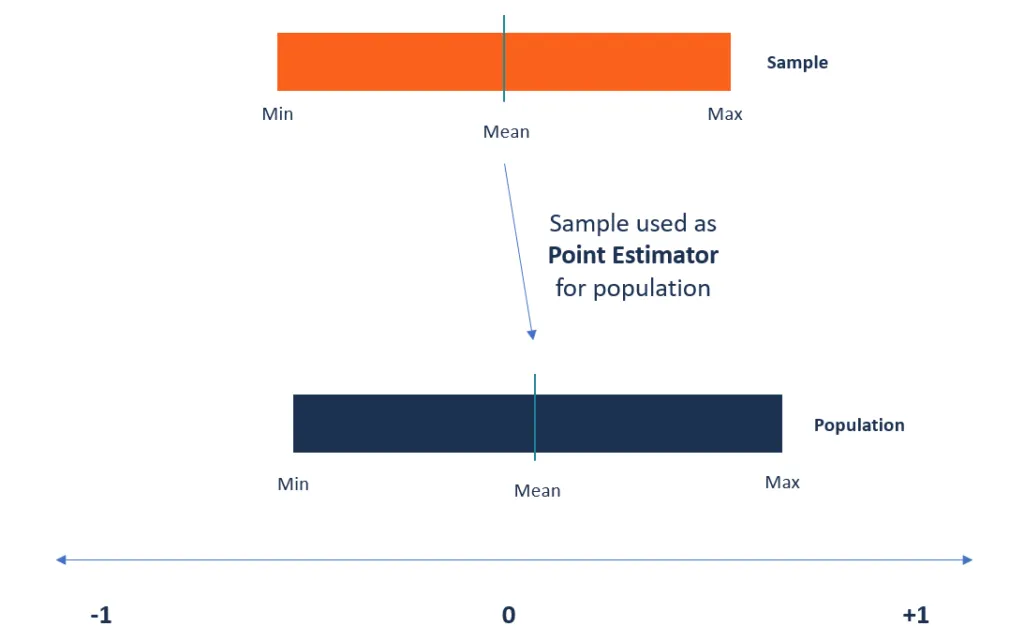
Source de l'image: Google images
Très souvent, les méthodes existantes pour trouver les paramètres de grandes populations sont irréalistes.
Par exemple, quand on veut connaître la taille moyenne des personnes assistant à une conférence, il sera impossible de collecter la hauteur exacte de toutes les villes de conférence dans le monde. En échange, un statisticien peut utiliser l'estimateur ponctuel pour estimer le paramètre de population.
Échantillon aléatoire et statistiques
Échantillon aléatoire: Un ensemble de IID (distribués de manière indépendante et identique) Variables aléatoires, X1, X2, X3, —, XNord établi dans le même espace d'échantillonnage est appelé un échantillon aléatoire de taille n.
Statistiques: Une fonction d'un échantillon aléatoire s'appelle une statistique (s'il ne dépend pas d'une entité inconnue)
Par exemple, X1+ X2+ —— + XNord, X12X2+ eX3, X1– XNord
Moyenne de l'échantillon et variance de l'échantillon
Deux statistiques importantes:
Soit x1, X2, X3, —, XNord être un échantillon aléatoire, ensuite:
La moyenne de l'échantillon est désignée par X, et la variance de l'échantillon est notée s2
Ici x̄ ys2 ils sont appelés les exemples de paramètres.
Les paramètres de la population sont indiqués par:
??2 = variance de la population et µ = moyenne de la population

Figure. Population et moyenne de l'échantillon
Source de l'image: Google images

Figure. Population de l'échantillon et variance
Source de l'image: Google images
Caractéristiques de la moyenne de l'échantillon:
E (X) = 1 / m (E (Xje)) = 1 / m (nµ) = µ
Où (X) = 1 / m2(Var (Xje)) = 1 / m2 (non2) =2/Nord
Caractéristiques de la variance de l'échantillon:
s2 = 1 / (n-1) (?? (Xje– X )2 ) = 1 / (n-1) (xje2 – 2x̄ Σ xje + nx̄2 ) = 1 / (n-1) (xje2 – nx̄2 )
À présent, Prenons l'attente des deux côtés, on obtient:
E (s2) = 1 / (n-1) (E (Xje2) – ni (X2)) = 1 / (n-1) (?? (µ2+ ??2) – m (µ2+ ??2/ m)) = 1 / (n-1) ((n-1) ??2) =2.
Propriétés des estimateurs ponctuels
Dans tout problème d'estimation donné, nous pouvons avoir une classe infinie d'estimateurs appropriés pour sélectionner. Le problème est de trouver un estimateur g (X1, X2, —, XNord), pour un paramètre inconnu ou sa fonction ?? (??), qui a des propriétés “joli”.
Essentiellement, on voudrait que l'estimateur g soit « proche » de Ψ.
Voici les principales propriétés des estimateurs ponctuels:
1. impartialité:
Comprenons d'abord le sens du terme “Biais”
La différence entre la valeur attendue de l'estimateur et la valeur du paramètre qui est estimée est appelée le biais d'un estimateur ponctuel..
Pour cela, l'estimateur est considéré comme sans biais lorsque la valeur estimée du paramètre et la valeur du paramètre estimé sont égales.
En même temps, plus la valeur attendue d'un paramètre est proche de la valeur du paramètre mesuré, plus la valeur de biais est faible.
Mathématiquement,
Un estimateur g (X1, X2, —, XNord) est dit un estimateur sans biais de θ si
E (g (X1, X2, —, XNord)) =
En d'autres termes, En moyenne, on s'attend à ce que g soit proche du vrai paramètre θ. Nous avons vu que si X1, X2, —, XNord être un échantillon aléatoire d'une population de moyenne µ et de variance2, après
E (X) = µ y E (s2) =2
Pour cela, x̄ et s2 sont des estimateurs sans biais pour µ et σ2
2. Efficace:
L'estimateur ponctuel le plus efficace est celui dont la variance est la plus faible de tous les estimateurs sans biais et cohérents.. La variance représente le niveau de dispersion de l'estimation, et la plus petite variance devrait moins varier d'un échantillon à l'autre.
Généralement, l'efficacité de l'estimateur dépend de la distribution de la population.
Mathématiquement,
Un estimateur gramme1(X1, X2, —, XNord) est plus efficace que gramme2(X1, X2, —, XNord), pour θ oui
Où (g1(X1, X2, —, XNord)) <= Var (g2(X1, X2, —, XNord))
3. Cohérent:
La cohérence décrit à quel point l'estimateur ponctuel reste proche de la valeur du paramètre à mesure qu'il augmente en taille.. Pour le rendre plus cohérent et précis, l'estimateur ponctuel a besoin d'une grande taille d'échantillon.
Nous pouvons également vérifier si un estimateur ponctuel est cohérent en observant sa valeur attendue et sa variance respectives.
Pour que l'estimateur ponctuel soit cohérent, la valeur attendue doit se rapprocher de la valeur réelle du paramètre.
Mathématiquement,
Soit g1, g2, g3, ——- être une suite d'estimateurs, la suite est dite consistante si elle converge vers θ en probabilité, En d'autres termes,
P (| gmétro(X1, X2, —, XNord) – ?? | >) -> 0 quand m-> ∞
Si X1, X2, —, XNord est une suite de variables aléatoires IID telle que E (Xje) = µ, plus tard par WLLN (Loi faible des grands nombres):
XNord‘—–> µ de probabilité
Où XNord« Est-ce que la moyenne de X1, X2, X3, —, XNord
4. Suffisant:
Soyez un échantillon de X ~ f (X; ??). Et Y = g (X1, X2, —, XNord) est une statistique telle que pour toute autre statistique Z = h (X1, X2, —, XNord), la distribution conditionnelle de Z, puisque Y = y ne dépend pas de θ, alors Y est appelé statistique suffisante pour θ.
Méthodes courantes de recherche d'estimations ponctuelles
La procédure d'estimation ponctuelle implique l'utilisation de la valeur d'une statistique obtenue à l'aide de données d'échantillon pour établir la meilleure estimation du paramètre inconnu respectif de la population.. Diverses méthodes peuvent être utilisées pour calculer ou déterminer les estimateurs ponctuels, et chaque technique a des propriétés différentes. Certaines des méthodes sont les suivantes:
1. Méthode des instants (MAMAN)
Il commence par considérer tous les faits connus sur une population, puis applique ces faits à un échantillon de la population.. En premier lieu, dérive des équations qui relient les moments de population aux paramètres inconnus.
L'étape suivante consiste à extraire un échantillon de la population qui sera utilisé pour estimer les moments de population. Les équations générées à la première étape sont ensuite résolues à l'aide de la moyenne d'échantillon des moments de population. Cela donne la meilleure estimation des paramètres de population inconnus.
Mathématiquement,
Considérons un exemple X1, X2, X3, —, XNord de F (X; ??1, ??2, —–, ??métro) .L'objectif est d'estimer les paramètres θ1, ??2, —–, ??métro.
Que les moments de population soient (théoriciens) une1, une2, ——–, uner, qui sont des fonctions de paramètres inconnus θ1, ??2, —–, ??métro.
En égalant les moments d'échantillonnage et les moments de population, on obtient les estimateurs de θ1, ??2, —–, ??métro.
2. Estimateur du maximum de vraisemblance (MLE)
Cette méthode de recherche d'estimateurs ponctuels tente de trouver les paramètres inconnus qui maximisent la fonction de vraisemblance. Prenez un modèle connu et utilisez les valeurs pour comparer des ensembles de données et trouver la meilleure correspondance pour les données.
Mathématiquement,
Considérons un exemple X1, X2, X3, —, XNord de f (X; ??). L'objectif est d'estimer les paramètres θ (scalaire ou vecteur).
La fonction de vraisemblance est définie comme:
L (??; X1, X2, —, XNord) = f (X1, X2, —, XNord; ??)
Un MLE de est la valeur ‘(un exemple de fonction) qui maximise la fonction de vraisemblance
Si L est une fonction dérivable de θ, alors la prochaine équation de vraisemblance est utilisée pour obtenir le MLE (‘):
ré / dθ (dans (L (??; X1, X2, —, XNord) = 0
Si est un vecteur, alors on considère que les dérivées partielles obtiennent les équations de vraisemblance.
Estimation ponctuelle vs estimation par intervalle
Simplement, il existe deux principaux types d'estimateurs en statistique:
- Estimateurs ponctuels
- Estimateurs d'intervalle
L'estimation ponctuelle est l'opposé de l'estimation par intervalle.
L'estimation ponctuelle génère une valeur unique, tandis que l'estimation d'intervalle génère une plage de valeurs.
Un estimateur ponctuel est une statistique utilisée pour estimer la valeur d'un paramètre inconnu dans une population. Utilise des exemples de données de la population lors du calcul d'une statistique unique qui sera considérée comme la meilleure estimation pour le paramètre de population inconnu.

Source de l'image: Google images
Au contraire, l'estimation d'intervalle prend des échantillons de données pour établir la plage de valeurs possibles d'un paramètre inconnu dans une population. La plage de paramètres est sélectionnée pour être comprise dans un 95% ou plus vraisemblablement, aussi connu sous le nom intervalle de confiance. L'intervalle de confiance décrit la fiabilité d'une estimation et est calculé à partir des données observées. Les points finaux des intervalles sont appelés supérieur Oui limites de confiance inférieures.
Remarques finales
Merci pour la lecture!
J'espère que vous avez apprécié le post et augmenté vos connaissances de la théorie de l'estimation.
N'hésitez pas à me contacter sur Courrier électronique
Tout ce qui n'est pas mentionné ou voulez-vous partager vos pensées? N'hésitez pas à commenter ci-dessous et je vous répondrai.
A propos de l'auteur
Aashi Goyal
En ce moment, Je poursuis mon Bachelor of Technology (B.Tech) en génie électronique et des communications Universidad Guru Jambheshwar (GJU), Hisar. Je suis très excité par les statistiques, apprentissage automatique et apprentissage profond.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





