Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
De nombreuses entreprises croient encore à la création de leur propre cadre pour les pipelines de données et n'utilisent pas les outils existants même si cela nécessite un large éventail de compétences.. La façon traditionnelle de faire ETL est de le faire manuellement avec du code et ce n'est pas un travail d'une personne. L'ETL traditionnel peut être considéré comme un goulot d'étranglement, mais cela ne veut pas dire que c'est inestimable.. Comprenons le scénario actuel ici!
ETL en quelques mots
En tant que passionnés de données, nous devons tous avoir fréquemment rencontré ce terme lorsque nous traitons des données tous les jours, vérité? Comme d'habitude, les ingénieurs de données s'occupent de tout ce travail, mais même les analystes de données, les scientifiques des données et les ingénieurs en intelligence d'affaires doivent avoir une expérience pratique.. Toutes les entreprises ne fourniront pas des données claires pour une analyse et un reporting directs; certains seront impatients de travailler en collaboration avec des ingénieurs de données pour créer des pipelines de données finaux évolutifs et efficaces.
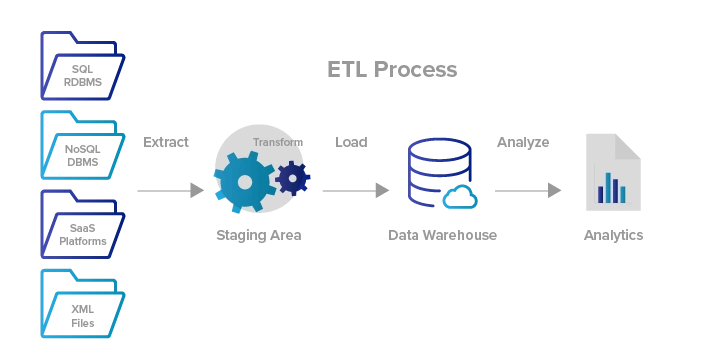
Pourquoi est-il si médiatisé?
Les grandes entreprises embauchent surtout des développeurs ETL, Des spécialistes ETL qui gèrent uniquement l'intégration des données et conçoivent pour eux des entrepôts de données. Le processus de 3 les étapes semblent simples, mais dans les coulisses, il y a des centaines de choses extrêmement lourdes à gérer pour extraire des données de diverses sources, en particulier les données elles-mêmes sont devenues beaucoup plus volumineuses et désordonnées.
C'est la partie la plus difficile de l'ensemble du flux de données et vous ne pouvez pas vous permettre de mal gérer des informations cruciales avant de passer à l'étape suivante.. Après avoir transformé les données nettoyées et validées de la manière souhaitée, stockage sûr dans un entrepôt de données à des fins de modélisation et d'analyse de données. Divers risques sont impliqués pendant les premières étapes de la phase de production et c'est pourquoi plus sont payés. Connaître l'entrée et la sortie des données est la base de toute fonction liée aux données et il est obligatoire d'avoir une idée de base de la façon d'utiliser les données intelligemment avec les ressources disponibles..
Comment effectuer l'ETL?
Il existe différents workflows dans le pipeline de données et ils peuvent être exécutés dans 2 formes:
- Talend
- Informatique
- Alteryx
- SSIS
- Amazon Redshift
- Xplein
- QlikSense
- Piton
- R
- SQL
- Java
- Cochon Apache
ETL sans code vs ETL manuel
Une plate-forme ETL sans code nécessite peu ou pas de codage. Les outils fournissent une interface graphique facile à utiliser avec diverses fonctionnalités pour créer une carte de données. Une fois la carte de données terminée, les équipes n'ont qu'à exécuter le processus et le serveur fera son travail. Le processus est facile à comprendre pour les clients et facile à entretenir. Il est évolutif et fait gagner beaucoup de temps et d'argent aux entreprises qui gèrent des ensembles de données en temps réel. La lógica es reutilizable para cualquier Source des donnéesOngle "Source des données" désigne tout lieu ou support où des informations peuvent être obtenues. Ces sources peuvent être à la fois primaires et, tels que les enquêtes et les expériences, en tant que secondaire, comme bases de données, articles universitaires ou rapports statistiques. Le bon choix d’une source de données est crucial pour garantir la validité et la fiabilité des informations dans la recherche et l’analyse.... y existen funciones personalizadas de manipulación de datos. Il existe des abonnements et des services ETL payants qui s'exécutent sur un serveur cloud avec des millions de données. Donc, l'entreprise doit choisir judicieusement l'outil en fonction du cas d'utilisation et des exigences du client.
Même les employeurs non techniques doivent être formés pour planifier les flux de travail, emplois et tâches pour se familiariser avec l'outil. Il existe des entreprises qui encouragent les pratiques sans code pour développer divers produits..
Selon le cabinet de recherche informatique Forrester, le marché des plateformes de développement low-code atteindra une valeur de $ 21,2 milliards pour 2022, croissant à un rythme annuel de 40 pourcent. En outre, les 45 pour cent des développeurs ont déjà utilisé une plate-forme low-code ou prévoient de le faire dans un proche avenir « . [1]
Coder son propre pot d'échappement est tentant mais difficile en même temps. De nombreuses entreprises adaptent l'écriture de scripts Python pour extraire, transformer et télécharger des données même dans un environnement cloud. Tout type de personnalisation de code peut être effectué si quelque chose n'est pas disponible dans la solution ETL existante. Le codage de notre propre ETL peut être très avantageux en termes de flexibilité et d'optimisation des performances. S'il y a un ingénieur de données expert à bord qui connaît les processus ETL, le processus ETL peut être ajusté pour fonctionner aussi bien que possible. Le codage fastidieux est utile dans les libre-services où l'on peut prétraiter indépendamment les données.
Des questions? Changer le code et maintenir les scripts peut être un gros problème si ETL ne fonctionne pas bien pour les schémas complexes. L'automatisation de l'ETL manuel nécessite d'autres outils tels que Selenium, el programador de tareas de Windows para ejecutar automáticamente scripts de forma diaria o semanal para almacenar datos en Excel o en una base de donnéesUne base de données est un ensemble organisé d’informations qui vous permet de stocker, Gérez et récupérez efficacement les données. Utilisé dans diverses applications, Des systèmes d’entreprise aux plateformes en ligne, Les bases de données peuvent être relationnelles ou non relationnelles. Une bonne conception est essentielle pour optimiser les performances et garantir l’intégrité de l’information, facilitant ainsi la prise de décision éclairée dans différents contextes..... Donc, sont conçus pour un ensemble spécifique d'utilisateurs et d'opérations de données.
Vous aimez jouer avec des données sales et les nettoyer ??
Si vous aimez expérimenter avec les données en vérifiant manuellement toutes les erreurs et en normalisant les données, donc implémenter plusieurs packages Python et R est un bon moyen de le faire. Même l'écriture de requêtes SQL peut être intéressante et difficile pour extraire des informations à partir de données désordonnées. Cela peut vous aider à acquérir une compréhension approfondie de la logique derrière la gestion des données à partir de zéro plutôt que de commencer par un outil en premier..
En bout de ligne: Todo depende de varios paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... como el tamaño de los datos, mémoire et budget pour choisir la solution optimale aux problèmes de l'entreprise. En outre, le choix de l'approche ETL varie en fonction du niveau d'expertise technique et non technique d'une entreprise.
Dernières pensées
C'est un sujet assez discutable et les deux ont leurs avantages et leurs inconvénients.. Les outils ETL ne sont pas morts, mais ils ne sont pas préférables de tous. On pourrait maintenant se retrouver avec une surcharge inutile d'utiliser un outil ETL là où il n'est pas nécessaire, qui héberge également une logique métier qui n'est pas transférable en dehors de l'outil ETL.. Mais les compétences développées en créant des pipelines ETL en utilisant Python ou SQL resteront toujours ensemble pour les années à venir..
Les outils ETL actuels peuvent se démoder et s'adapter aux nouveaux peut être difficile pour certaines personnes. Donc, même les outils peuvent devenir une nuisance pour une entreprise s'ils ne sont pas utilisés correctement. Indépendamment de l'ETL manuel ou sans code, l'ensemble du processus lui-même est compliqué mais aussi très intéressant à apprendre.
Quel est ton préféré? Faites-moi savoir dans les commentaires!!
Merci d'avoir lu cet article.
Référence
[1] Comment les plateformes low-code transforment le développement logiciel
A propos de l'auteur:
Saloni Somaiya travaille comme data scientist dans une startup du secteur de la santé aux États-Unis. Titulaire d'une maîtrise en systèmes d'information de la Northeastern University, Boston. Aime lire des articles et explorer les nouvelles technologies. Elle est disposée à contribuer davantage au domaine de la science et de l'analyse de données.
LinkedIn: https://www.linkedin.com/in/saloni-somaiya/
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





