Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Dans le traitement du langage naturel, l'extraction de caractéristiques est l'une des étapes triviales à franchir pour mieux comprendre le contexte de ce à quoi nous avons affaire. Après avoir nettoyé et normalisé le texte initial, nous devons le transformer dans ses caractéristiques pour l'utiliser dans la modélisation. Nous utilisons une méthode particulière pour attribuer des poids à des mots particuliers dans notre document avant de les modéliser. Nous avons opté pour la représentation numérique des mots individuels, car il est facile pour l'ordinateur de traiter les nombres; dans ces cas, nous avons opté pour des inclusions de mots.

La source: https://www.analyticsvidhya.com/blog/2020/06/nlp-project-information-extraction/
Dans cet article, Nous discuterons des différentes méthodes d'intégration de mots et d'extraction de caractéristiques qui sont pratiquées dans le traitement du langage naturel..
Extraction de caractéristiques:
Sac de mots:
Dans cette méthode, nous prenons chaque document comme une collection ou un sac qui contient tous les mots. L'idée est d'analyser les documents. Le document fait ici référence à une unité. Au cas où nous voudrions trouver tous les tweets négatifs pendant la pandémie, chaque tweet ici est un document. Pour obtenir le sac de mots, nous effectuons toujours toutes les étapes précédentes telles que le nettoyage, dérivation, lématisation, etc... Ensuite, nous générons un ensemble de tous les mots disponibles avant de l'envoyer au modèle.
“L'entrée est la meilleure partie du football” -> {'entrée', 'mieux', 'partie', 'football'}
Nous pouvons obtenir des mots répétés dans notre document. Une meilleure représentation est une forme vectorielle, qui peut nous dire combien de fois chaque mot peut apparaître dans un document. Ce qui suit est appelé la matrice de termes du document et est illustré ci-dessous:

La source: https://qphs.fs.quoracdn.net/main-qimg-27639a9e2f88baab88a2c575a1de2005
Il nous renseigne sur la relation entre un document et les termes. Chacune des valeurs du tableau fait référence au terme fréquence. Pour trouver la similitude, on choisit la mesure de similarité du cosinus.
TF-IDF:
Un problème que nous rencontrons avec l'approche du sac de mots est qu'elle traite tous les mots de la même manière., mais dans un document, il y a une forte probabilité que certains mots soient répétés plus fréquemment que d'autres. Dans un reportage sur la victoire de Messi en Copa América, le mot Messi serait répété plus fréquemment. Nous ne pouvons pas donner à Messi le même poids qu'à n'importe quel autre mot dans ce document. Dans le rapport, si on prend chaque phrase comme un document, on peut compter le nombre de documents à chaque fois que Messi apparaît. Cette méthode est appelée fréquence de document.
Ensuite, nous divisons la fréquence du terme par la fréquence du document de ce mot. Cela nous aide avec la fréquence d'apparition des termes dans ce document et inversement au nombre de documents dans lesquels il apparaît. Donc, nous avons le TF-IDF. L'idée est d'attribuer des poids particuliers aux mots qui nous disent à quel point ils sont importants dans le document.
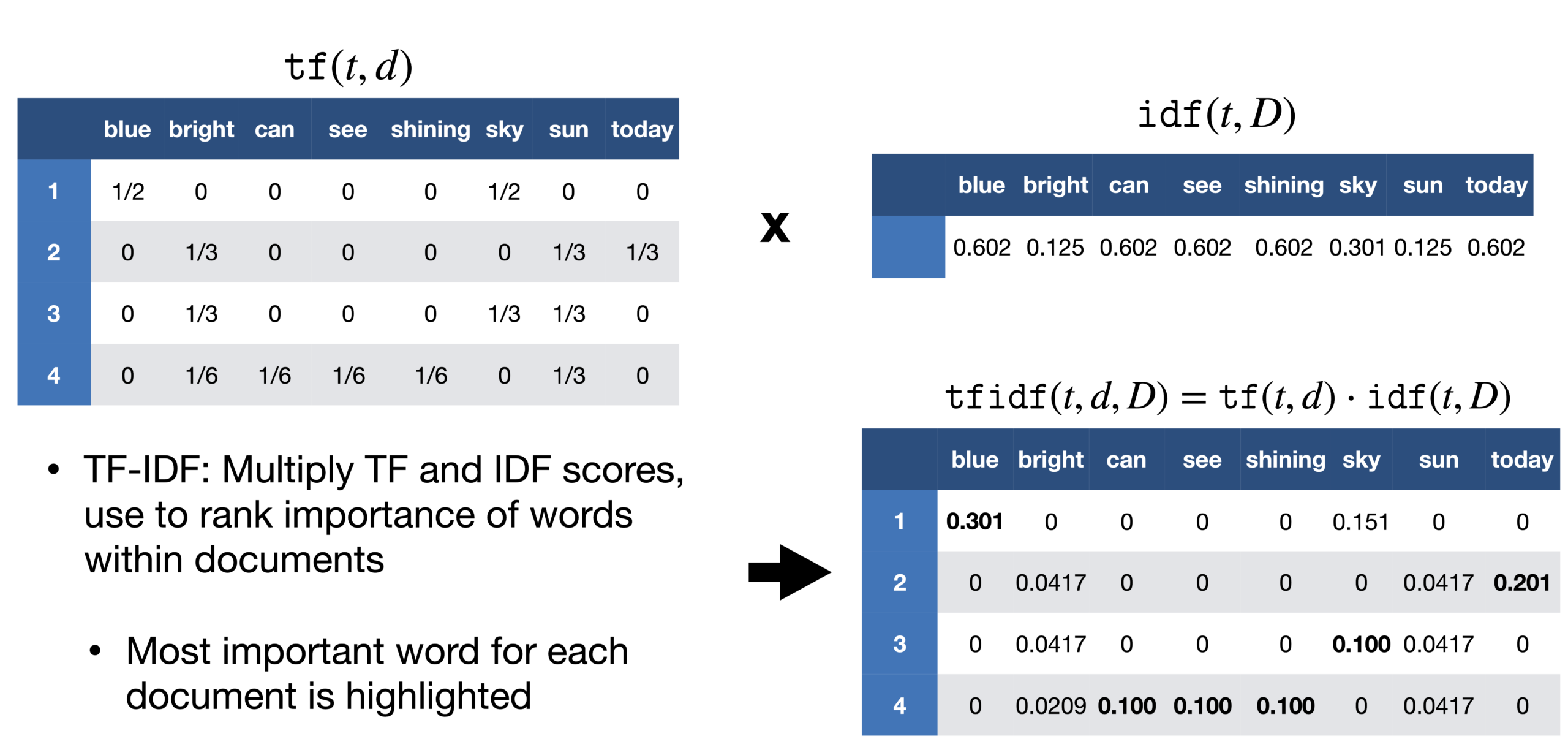
La source: https://sci2lab.github.io/ml_tutorial/tfidf/
Encodage à chaud:
Pour une meilleure analyse du texte que nous voulons traiter, nous devons créer une représentation numérique de chaque mot. Cela peut être corrigé en utilisant la méthode d'encodage One-hot. Ici, nous traitons chaque mot comme une classe et dans un document, partout où est le mot, nous assignons 1 dans le tableau et tous les autres mots de ce document obtiennent 0. Ceci est similaire au sac de mots, mais ici nous gardons juste chaque mot dans un sac.
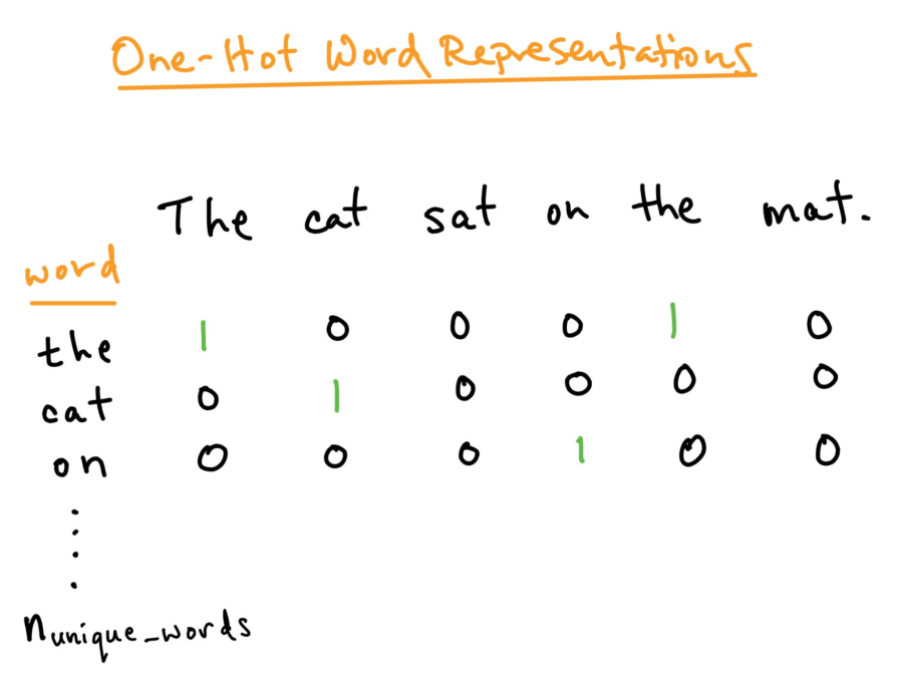
La source: https: //versdatascience.com/word-embedding-in-nlp-one-hot-encoding-and-skip-gram-neural-network-81b424da58f2
Incorporation de mots:
L'encodage à chaud fonctionne bien lorsque nous avons un petit ensemble de données. Quand il y a un vocabulaire énorme, nous pouvons le coder en utilisant cette méthode car la complexité augmente beaucoup. Nous avons besoin d'une méthode qui peut contrôler la taille des mots que nous représentons. Nous le faisons en le limitant à un vecteur de taille fixe. Nous voulons trouver une incrustation pour chaque mot. Nous voulons que vous nous montriez quelques propriétés. Par exemple, si deux mots sont similaires, doivent être plus proches les uns des autres dans la représentation, et deux mots opposés si leurs paires existent, les deux doivent avoir la même différence de distance. Ceux-ci nous aident à trouver des synonymes, analogies, etc.
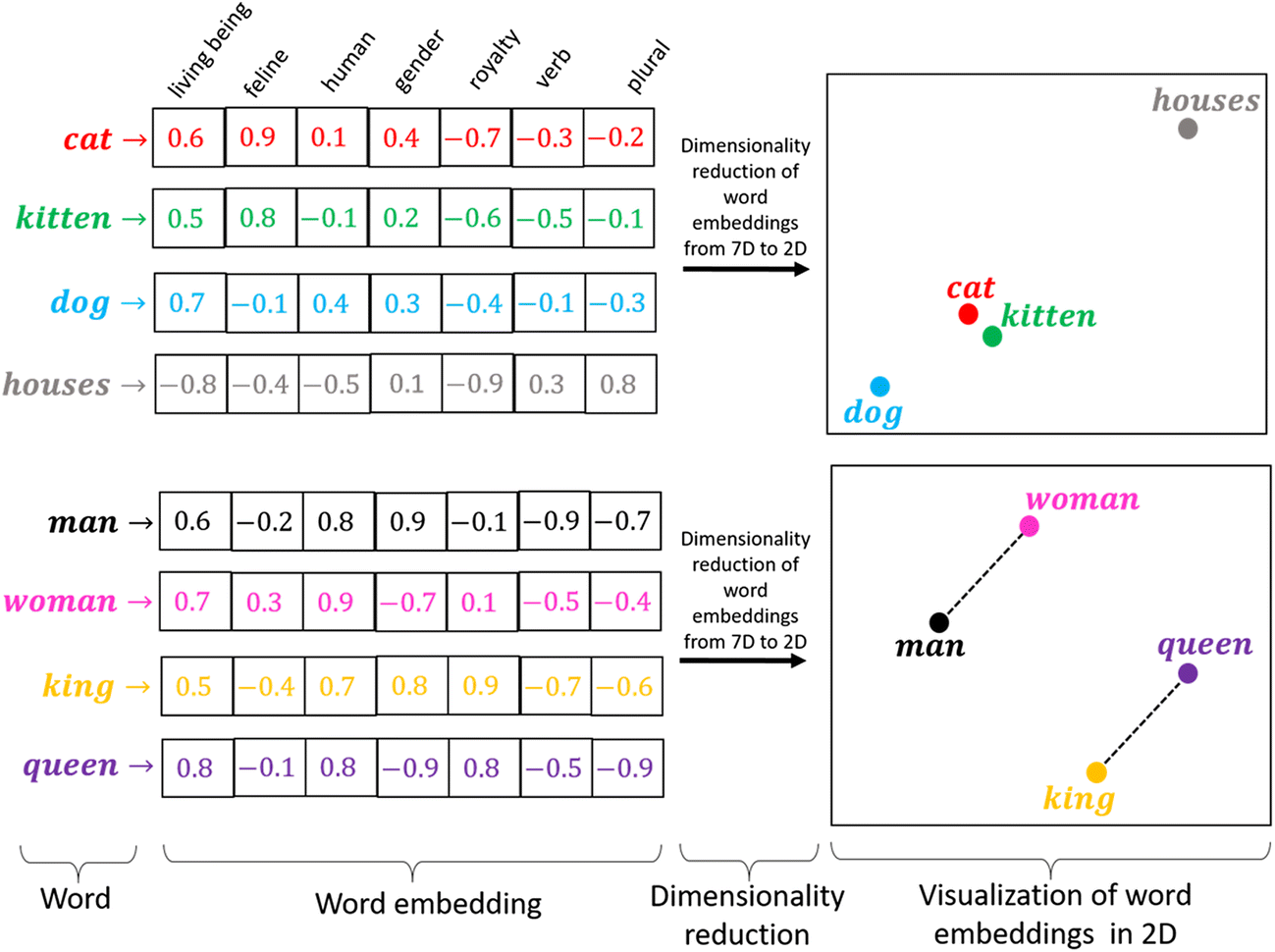
La source: https://miro.medium.com/max/1400/1*sAJdxEsDjsPMioHyzlN3_A.png
Word2Vec:
Word2Vec est largement utilisé dans la plupart des modèles de PNL. Transformer le mot en vecteurs. Word2vec est un réseau à deux couches qui traite du texte avec des mots. L'entrée est dans le corpus de texte et la sortie est un ensemble de vecteurs: les vecteurs caractéristiques représentent les mots de ce corpus. Alors que Word2vec n'est pas un réseau de neurones profonds, convertir le texte en une forme de calcul non ambiguë pour les réseaux de neurones profonds. Le but et l'avantage de Word2vec est de collecter des vecteurs des mêmes mots dans l'espace vectoriel. C'est-à-dire, trouver des similitudes mathématiques. Word2vec crée des vecteurs qui sont distribués à l'aide d'affichages numériques d'éléments verbaux, caractéristiques telles que le contexte de mots individuels. Il le fait sans intervention humaine.
Avec suffisamment de données, utilisation et conditions, Word2vec peut faire les prédictions les plus précises sur la signification d'un mot en fonction des apparences passées. Cette conjecture peut être utilisée pour former des combinaisons de mots et de mots (par exemple, "super", c'est-à-dire, "Grand" pour dire que "petit" est "petit"), ou grouper les textes et les séparer par thème. Ces collections peuvent constituer la base de la recherche, analyse émotionnelle et recommandations dans divers domaines, comme la recherche scientifique, découverte légale, e-commerce et gestion de la relation client. Le résultat du réseau Word2vec est un glossaire où chaque élément a un vecteur attaché, qui peut être intégré dans un réseau de lecture en profondeur ou simplement demandé de trouver la relation entre les mots.
Word2Vec peut très bien saisir le sens contextuel des mots. Il y a deux saveurs. Dans l'une des méthodes, on nous donne les mots voisins appelés sac continu de mots (CBoW), et dans lequel on nous donne le mot du milieu appelé skip-gram et on prédit les mots voisins. Une fois que nous obtenons un ensemble de poids préalablement entraînés, nous pouvons l'enregistrer et cela peut être utilisé plus tard pour la vectorisation de mots sans avoir besoin de transformer à nouveau. Nous les stockons dans une table de correspondance.
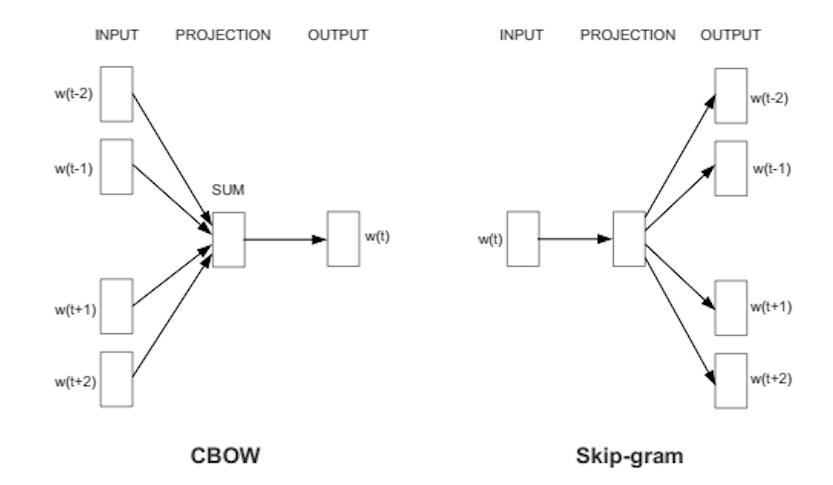
La source: https://wiki.pathmind.com/word2vec
Gant:
Gant – vecteur global pour la représentation des mots. Un algorithme d'apprentissage non supervisé de Stanford est utilisé pour générer des mots intégrés en combinant une matrice de mots pour la co-occurrence de mots de la matrice du corpus.. Le texte intégré contextuel affiche une mise en forme de ligne attrayante pour un mot dans l'espace vectoriel. Le modèle GloVe est entraîné sur la matrice de cooccurrence globale de niveau zéro, qui montre combien de fois des mots sont trouvés dans un corpus particulier. Remplir cette matrice nécessite un passage par société entière pour collecter des statistiques. Pour un grand corpus, cette transaction peut coûter un ordinateur, mais c'est une dépense ponctuelle dans le futur. La formation post-suivi est beaucoup plus rapide car le nombre d'entrées non matricielles est généralement bien inférieur au nombre total d'entrées dans le corpus.
Ce qui suit est une représentation visuelle des incrustations de mots:
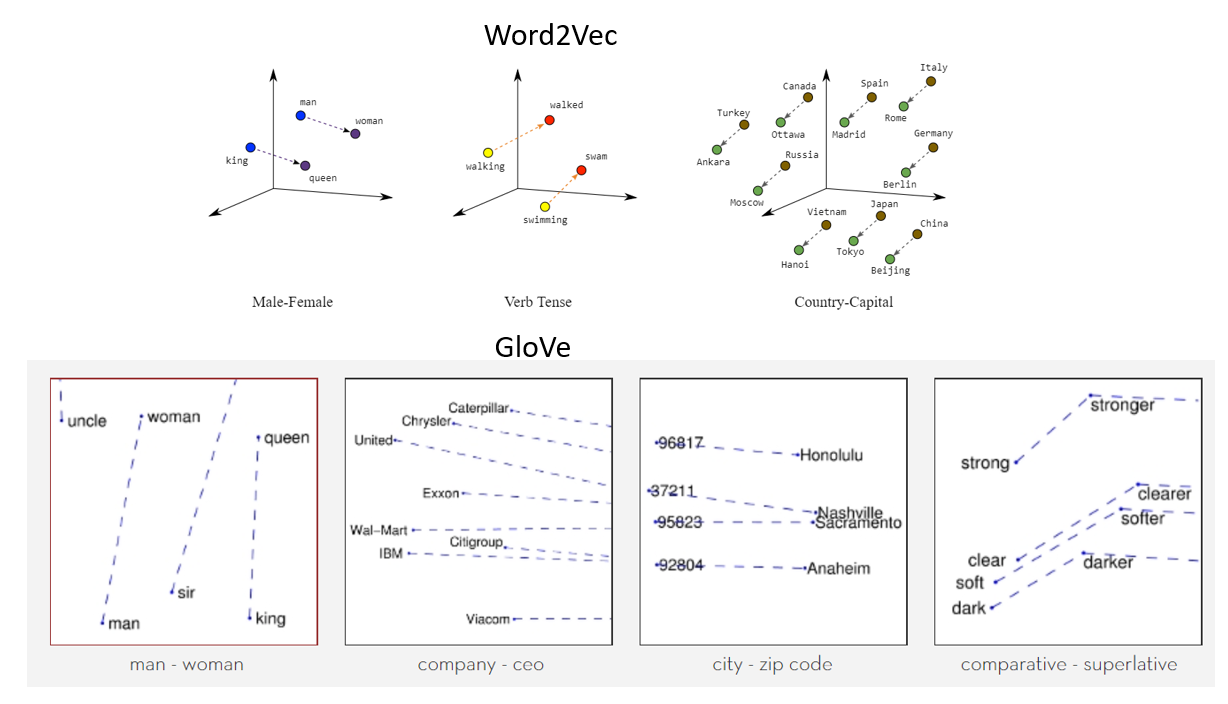
La source: https://miro.medium.com/max/1400/1*gcC7b_v7OKWutYN1NAHyMQ.png
Les références:
1. Image – https://www.develandoo.com/blog/do-robots-read/
2. https://nlp.stanford.edu/projects/glove/
3. https://wiki.pathmind.com/word2vec
4. https://www.udacity.com/course/natural-language-processing-nanodegree–nd892
conclusion:

La source: https: //medium.com/datatobiz/the-past-present-and-the-future-of-natural-language-processing-9f207821cbf6
Sur moi: Je suis un étudiant chercheur intéressé par le domaine de l'apprentissage en profondeur et du traitement du langage naturel et je suis actuellement en train de faire un diplôme de troisième cycle en Intelligence Artificielle..
N'hésitez pas à me contacter sur:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698





