Cet article a été publié dans le cadre du Blogathon sur la science des données
Science des données, apprentissage automatique, MLops, ingénierie des données, toutes ces frontières de données avancent avec rapidité et précision. L'avenir de la science des données est défini par de grandes entreprises comme Microsoft, Amazone, Les briques de données, Google et ces entreprises stimulent l'innovation dans ce domaine. En raison de ces changements rapides, il est logique d'obtenir une certification auprès de l'un de ces grands acteurs et de se renseigner sur leur offre de produits. En outre, avec les solutions de bout en bout fournies par ces plateformes, des lacs de données évolutifs aux clusters évolutifs, pour les tests et la production, simplifier la vie des professionnels des données. D'un point de vue commercial, a toutes les infrastructures sous un même toit, dans le cloud et à la demande, et de plus en plus d'entreprises se penchent ou, en outre, sont obligés de migrer vers le cloud en raison de la pandémie en cours.
Comment le DP-100 aide-t-il (Concevoir et mettre en œuvre une solution de science des données sur Azure) à un data scientist ou à toute personne travaillant avec des données?
En résumé, les entreprises collectent des données à partir de diverses sources, application mobile, Systèmes de point de vente, outils internes, Machines, etc., et tout cela se trouve dans divers départements ou différentes bases de données, cela est particulièrement vrai pour les grandes entreprises traditionnelles. L'un des principaux obstacles pour les scientifiques des données est de réunir des données pertinentes sous un même toit pour créer des modèles à utiliser en production.. Dans le cas d'Azure, toutes ces données sont déplacées dans un lac de données, la manipulation des données peut être effectuée à l'aide de groupes SQL ou Spark, nettoyage des données, prétraitement du modèle, construction de modèles à l'aide de clusters de test (bas coût), surveillance du modèle, modèle d'équité, dérive des données et déploiement à l’aide de grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois.... (coût évolutif plus élevé). Le data scientist peut se concentrer sur la résolution des problèmes et laisser Azure faire le gros du travail.
Un autre scénario de cas d'utilisation est le suivi de modèle à l'aide de mlflow (Projet open source Databricks). Quiconque a participé à un hackathon DS sait que le suivi des modèles, l'enregistrement des métriques et la comparaison des modèles est une tâche fastidieuse, si vous n'avez pas configuré de pipeline. En Azure, tout cela est facilité par l'utilisation d'expériences appelées, tous les modèles sont enregistrés, les métriques sont enregistrées, les artefacts sont enregistrés, tout en utilisant une seule ligne de code.
À propos d'Azure DP-100
Azure DP-100 (Concevoir et mettre en œuvre une solution de science des données sur Azure) est la certification en science des données de Microsoft pour tous les passionnés de données. C'est une expérience d'apprentissage à votre rythme, avec liberté et flexibilité. Après achèvement, on peut travailler en bleu sans problème et construire des modèles, suivre les expériences, construire des tuyaux, ajuster les hyperparamètres et Chemin AZUR.
Exigences
- Connaissance de base de Python, après avoir travaillé dessus pendant au moins 3-6 mois, facilite la préparation à l'examen.
- Connaissances de base en apprentissage automatique. Cela aide à comprendre les codes et à répondre aux questions sur les AA pendant l'examen..
- Avoir travaillé sur l'ordinateur portable Jupyter ou le laboratoire Jupyter, ce n'est pas un mandat, puisque tous les laboratoires sont sur l'ordinateur portable jupyter, c'est facile de travailler avec eux.
- La connaissance de Databricks et de mlflow peut être mise à profit pour obtenir de meilleurs résultats aux tests. Dès juillet 2021, ces concepts sont inclus dans le DP-100.
- Rs. 4500 frais d'examen.
- Inscrivez-vous pour un compte Azure gratuit, vous recevrez des crédits de 13.000 roupies avec lesquelles vous pouvez explorer Azure ML. C'est plus que suffisant. Mais Azure ML n'est gratuit que pour les premiers 30 jours. Alors faites bon usage de cet abonnement.
- La chose la plus importante est de fixer votre date d'examen dans 30 jours à partir d'aujourd'hui, paye le, c'est une bonne motivation.
Page d'examen du Dp 100

Ça vaut la peine?
Le coût de l'examen est d'environ 4.500 des roupies et peu d'entreprises s'attendent à une certification lors du recrutement, c'est bien de l'avoir, mais beaucoup, ni les recruteurs ne l'exigent ni ne le savent, alors la question se pose: Vaut-il la peine de payer? Est-ce que ça vaut mes week-ends? La réponse est oui, juste parce que, bien que l'on puisse être un excellent professeur d'apprentissage automatique ou un expert Python, mais le fonctionnement interne d'Azure est spécifique à Azure, de nombreuses méthodes sont spécifiques à Azure pour améliorer les performances. Vous ne pouvez pas simplement vider un code Python et vous attendre à ce qu'il offre des performances optimales. De nombreux processus sont automatisés dans azur, par exemple: le module automl crée des modèles avec une seule ligne de code, le réglage des hyperparamètres nécessite une ligne de code. No ML Code est un autre outil de glisser-déposer qui fait de la construction de modèles un jeu d'enfant. Conteneurs / stockage / coffres à clés / espace de travail / expériences / tous sont des outils et des types spécifiques de bleu. Lors de la création d'instances de calcul, travailler avec le pipeline, mlflow aide également à comprendre les concepts de Mlops. Certainement un avantage si vous travaillez dans Azure et que vous souhaitez explorer les moindres détails. En général, les récompenses l'emportent sur l'effort.
préparation
- L'examen est basé sur QCM avec environ 60 une 80 questions et le temps imparti est 180 minutes. Ce temps est plus que suffisant pour compléter et revoir toutes les questions.
- Deux questions de laboratoire ou des questions de type étude de cas sont posées et ce sont des questions obligatoires et ne peuvent pas être ignorées.
- C'est un test supervisé, alors assurez-vous de préparer l'examen.
- Microsoft change le modèle environ deux fois par an, il vaut donc mieux vérifier la mise à jour modèle d'examen.
- C'est plus facile si la préparation à l'examen est divisée en 2 Pas, théorie et laboratoire.
- La théorie est assez détaillée et vous avez besoin d'au moins 1-2 semaines de préparation et de révision. Toutes les questions théoriques peuvent être étudiées de documents Microsoft. Une étude détaillée de ces documents suffira..
- Ce partie importante constitue le plus grand nombre de questions – Créer et exploiter des solutions de machine learning avec Azure Machine Learning.
- Les laboratoires sont également importants. Bien qu'aucune question pratique de laboratoire ne soit posée, il est utile de comprendre les classes et méthodes spécifiques à Azure. Et ceux-ci constituent la majorité des questions.
- Aucune question sur l'apprentissage automatique ne sera posée, par exemple, il ne demandera pas quel est le score R2. Ce que vous pouvez demander, c'est comment enregistrer le score R2 pour une expérience. Ensuite, L'application ML sur Azure devrait être au centre des préoccupations.
- Microsoft fournit un guide dirigé par un instructeur. cours payant aussi pour DP-100. je ne vois pas l'utilité d'aborder ça, puisque tout est fourni dans la doc MS.
- Laboratoires de pratique, autour de 14, pratiquer au moins une fois pour se familiariser avec l'espace de travail Azure.
- Réviser la théorie avant de passer les examens, pour ne pas se tromper lors de l'examen.
Compétences mesurées:
- Configurer un espace de travail Azure Machine Learning
- Exécutez des expériences et entraînez des modèles
- Optimiser et gérer les modèles
- Déployer et consommer des modèles
Clonez le référentiel pour vous entraîner aux laboratoires Azure:
git clone https://github.com/microsoftdocs/ml-basics
Quelques méthodes / classes Azure importantes:
## créer un espace de travail
ws = Espace de travail.get(nom="aml-espace de travail",
subscription_id='1234567-abcde-890-fgh...',
resource_group='aml-ressources')
## modèle de registre
model = Model.register(espace de travail=ws,
nom_modèle="modèle_classification",
model_path="modèle.pkl", # chemin local
description='Un modèle de classification',
balises={'format de données': 'CSV'},
model_framework=Modèle.Framework.SCIKITLEARN,
model_framework_version='0.20.3')
## Exécuter un fichier .py dans un pipeline
step2 = PythonScriptStep(nom="maquette de train",
répertoire_source = 'scripts',
nom_script="train_model.py",
calculate_target="aml-cluster")
# Définir la configuration de l'étape de l'étape d'exécution parallèle
parallel_run_config = ParallelRunConfig(
source_directory='batch_scripts',
script_entrée="batch_scoring_script.py",
mini_batch_size="5",
error_threshold=10,
action_sortie="ajouter_ligne",
environnement=bat_env,
compute_target=aml_cluster,
node_count=4)
# Créer l'étape d'exécution parallèle
parallelrun_step = ParallelRunStep(
nom="lot-score",
parallel_run_config=parallel_run_config,
entrées =[batch_data_set.as_named_input('batch_data')],
sortie=rép_sortie,
arguments=[],
allow_reuse=Vrai
)
Quelques notions importantes (liste non exhaustive):
- Créer un cluster de calcul pour les tests et les productions
- Créer des étapes de pipeline
- Connecter le cluster Databricks à l'espace de travail Azure ML
- Méthode de réglage des hyperparamètres
- Travailler avec des données: ensembles de données et entrepôt de données
- Dérive du modèle
- Confidentialité différentielle
- Détecter l'injustice du modèle (QCM questions)
- Explications du modèle à l'aide de l'explicateur de forme.
- Méthode à retenir
- Scriptrunconfig
- PipelineData
- ParallelRunConfig
- Point de terminaison du pipeline
- Exécuter la configuration
- init () Cours ()
- PubliéPipeline
- ComputeTarget.attach
- Méthodes de base de donnéesUn "base de données" ou ensemble de données est une collection structurée d’informations, qui peut être utilisé pour l’analyse statistique, Apprentissage automatique ou recherche. Les ensembles de données peuvent inclure des variables numériques, catégorique ou textuelle, Et leur qualité est cruciale pour des résultats fiables. Son utilisation s’étend à diverses disciplines, comme la médecine, Économie et sciences sociales, faciliter la prise de décision éclairée et l’élaboration de modèles prédictifs.... / magasin de données
Séance de préparation à l'examen Azure DP-100
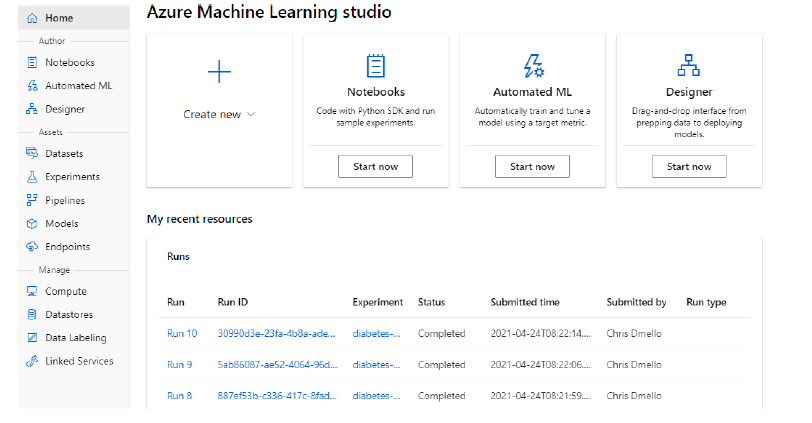
Espace de travail Azure Machine Learning:
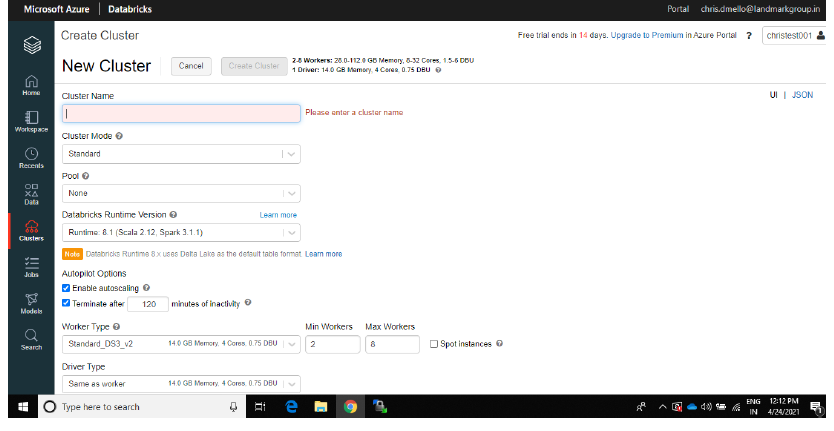
Azure DatabricksAzure Databricks est une plateforme d’analyse de données basée sur Apache Spark, Conçu pour faciliter la collaboration entre les data scientists et les ingénieurs. Fournit un environnement intégré qui permet l’ingestion, Traitement et analyse de grands volumes de données. Grâce à son évolutivité et à ses outils d’IA avancés, Azure Databricks rationalise le flux de travail et accélère la prise de décision sur des projets de données complexes.... Créer un cluster:
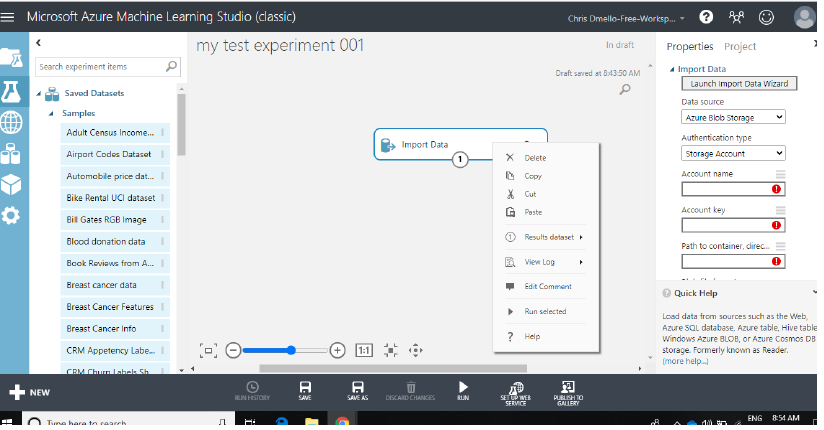
Concepteur Azure:
Jour d'examen
- Assurez-vous de tester votre système la veille. Les ordinateurs portables professionnels causent parfois des problèmes, il est donc préférable d'utiliser des ordinateurs portables personnels.
- Les livres ne sont pas autorisés / papiers / stylos ou autre papeterie.
- Le surveillant effectue les vérifications de base initiales et vous permet de commencer l'examen.
- Une fois l'examen soumis, les scores sont fournis à l'écran puis dans un e-mail. Alors n'oubliez pas de vérifier votre courrier.
- La certification n'est valable que pour 2 ans.
Bonne chance! Votre prochain objectif devrait être DP-203 (Ingénierie des données dans Microsoft Azure).
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





