Dans mon article précédent, “Combiner des ensembles de données dans SAS – Simplifié”, nous analysons trois méthodes pour combiner des ensembles de données: attacher, concaténer et fusionner. Dans cet article, nous verrons la méthode la plus courante et la plus utilisée pour combiner des ensembles de données: FUSION ou UNION.
Le besoin de s'unir / fusionner des ensembles de données:
Avant d'entrer dans les détails, comprenons pourquoi nous avons vraiment besoin de nous réunir / fusionner. Chaque fois que nous avons des informations divisées et disponibles dans deux ou plusieurs ensembles de données et que nous voulons les combiner dans un seul ensemble de données, nous devons fusionner / rejoindre ces tables. L'une des principales choses à garder à l'esprit est que la fusion doit être basée sur des critères ou des champs communs. Par exemple, dans une entreprise de vente au détail, nous avons un tableau des transactions quotidiennes (le tableau contient les détails du produit, détails des ventes et détails du client) et un tableau d'inventaire (qui a les détails du produit et la quantité disponible). Maintenant bien, avoir les informations sur l'Inventaire ou la disponibilité d'un produit, Que devrions nous faire? Combinez la table Transaction avec la table Inventory basée sur Product_Code et soustrayez la quantité vendue de la quantité disponible.
La fusion / l'union peut être de divers types et dépend des exigences de l'entreprise et de la relation entre les ensembles de données. Premier, Examinons les différents types de relations que les ensembles de données peuvent avoir.
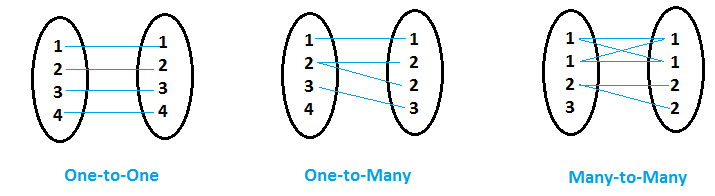
- Quand pour chaque valeur de variable commune (disons la variable 'x') dans le premier ensemble de données, le deuxième ensemble de données n'a qu'une seule valeur correspondante pour cette variable commune « x », alors ça s'appelle Douze cinquante-neuf relation amoureuse.
- Quand pour les valeurs de la variable commune (disons la variable 'y') dans le premier ensemble de données, d'autres ensembles de données ont plus d'une valeur correspondante pour cette variable commune « y », alors ça s'appelle Un à plusieurs relation amoureuse.
- Lorsque les deux ensembles de données ont plusieurs entrées pour la même valeur de variable commune, alors ça s'appelle Plusieurs à plusieurs relation amoureuse.
Et SAS, nous pouvons faire des syndicats / fusions sous diverses formes, ici, nous allons discuter des moyens les plus courants: Étape de données et PROC SQL. Dans l'étape Données, nous utilisons l'instruction Merge pour effectuer des jointures, tandis que dans PROC SQL, nous écrivons une requête SQL. Analysons d'abord le passage des données:
ÉTAPES DE DONNÉES
Syntaxe:- Ensemble de données; Fusionner l'ensemble de données1 l'ensemble de données2 l'ensemble de données3 ... l'ensemble de donnéesn; Par CommonVariable1 CommonVariable2......CommonVariablen; Courir;
Noter: – Les ensembles de données doivent être triés par variable (s) commun et nom, le type et la longueur de la variable commune doivent être les mêmes pour tous les ensembles de données d'entrée.
Examinons quelques scénarios pour chacune des relations entre les ensembles de données d'entrée.
relation UN à UN
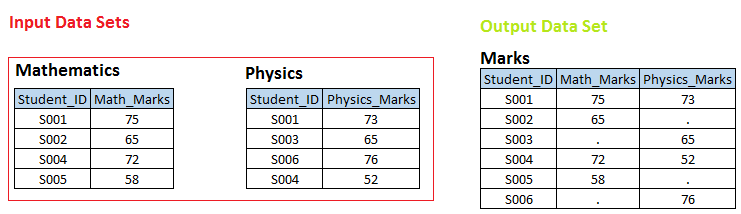
Organiser 1 Dans les ensembles de données d'entrée suivants, vous pouvez voir qu'il existe une relation un-à-un entre ces deux tables dans Carte d'étudiant. Maintenant, nous voulons créer un ensemble de données. MARQUES, où nous avons tous les student_ids uniques avec les notes respectives en mathématiques et en physique. Si student_id n'est pas disponible dans la table Math, donc math_marks devrait avoir une valeur manquante et vice versa.
Solution utilisant les étapes de données: –
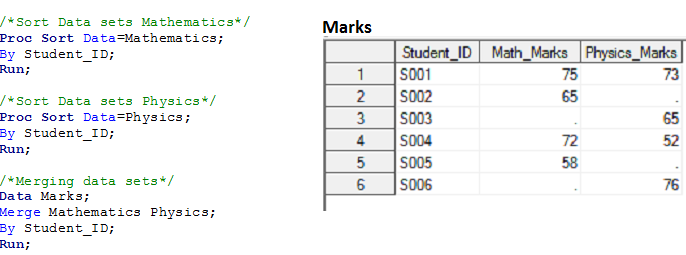
Comment ça marche:-
- SAS compare les deux ensembles de données et crée un point de vente (Vecteur de données de programme) pour toutes les variables uniques et les initialise avec les valeurs manquantes (le vecteur de données de programme est un intermédiaire entre les ensembles de données d'entrée et de sortie). Dans l'exemple actuel, Je créerais un POV comme celui-ci:

- Lisez la première observation à partir des ensembles de données d'entrée et comparez les valeurs de la variable BY dans les deux ensembles de données:
- si les valeurs sont égales, elle est comparée à la valeur de la variable BY dans POS.
- sinon le même, les variables POV sont réinitialisées avec les valeurs manquantes et la valeur d'observation actuelle est copiée dans le POV tandis que l'autre observation reste perdue
- Si c'est pareil, Les variables POS ne sont pas réinitialisées. La valeur disponible de l'observation actuelle est mise à jour dans le POS
- Après cela, le pointeur d'enregistrement passe à l'observation suivante dans les deux ensembles de données et, pendant l'exécution de l'instruction RUN, Les valeurs PDV sont transmises à l'ensemble de données de sortie.
- Si la valeur de la variable By ne correspond pas, l'observation de l'ensemble de données avec la valeur la plus faible est copiée dans le POS. Le pointeur d'enregistrement de l'ensemble de données qui a une valeur de variable BY inférieure est déplacé vers l'observation et l'étape suivantes 2 (une) répète à nouveau.
- si les valeurs sont égales, elle est comparée à la valeur de la variable BY dans POS.
- Les étapes ci-dessus sont répétées jusqu'à ce que l'EOF des deux ensembles de données soit atteint.
Vous pouvez exécuter un essai pour évaluer l'ensemble de données de résultat.
Organiser 2: – Sur la base des ensembles de données d'entrée du scénario 1, nous voulons créer les ensembles de données de sortie suivants.
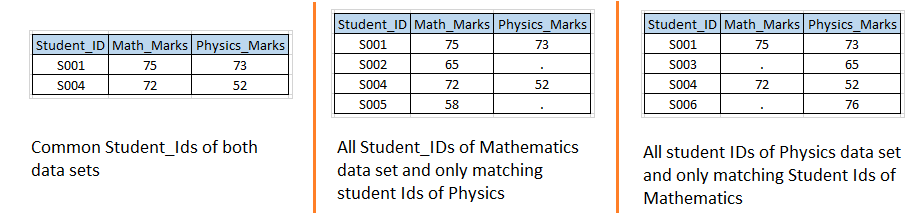
Solution utilisant des étapes de données: – Écrivons un code similaire au scénario 1 avec l'option IN. 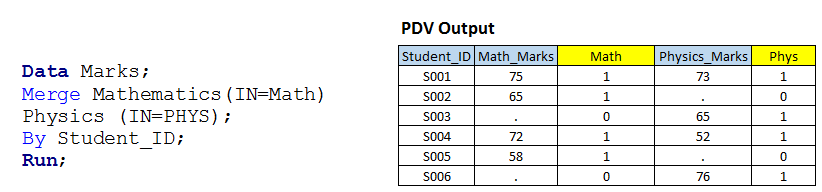 Dessus, vous pouvez voir que nous avons utilisé l'option IN avec les deux ensembles de données d'entrée et les valeurs attribuées aux variables temporaires MATH et PHYS car ce sont des variables temporaires, nous ne pouvons donc pas les voir dans l'ensemble de données de sortie.
Dessus, vous pouvez voir que nous avons utilisé l'option IN avec les deux ensembles de données d'entrée et les valeurs attribuées aux variables temporaires MATH et PHYS car ce sont des variables temporaires, nous ne pouvons donc pas les voir dans l'ensemble de données de sortie.
je t'ai montré le tableau (Données PDV) qui a une valeur variable pour toutes les observations avec les variables temporaires. À présent, en fonction de la valeur de ces variables, nous pouvons écrire du code pour la sous-configuration et les opérations JOIN selon nos besoins:
- Si MATH et PHYS ont une valeur 1, créera le premier jeu de données de sortie et il s'appellera INNER JOIN.
- Si MATH a 1, créera un deuxième ensemble de données de sortie et il s'appellera LEFT JOIN.
- Si PHYS a 1, créera un troisième ensemble de données de sortie et il sera appelé RIGHT JOIN
- Si MATH et PHYS ont 1, fonctionnera comme FULL JOIN, a également été résolu à l'étape 1.
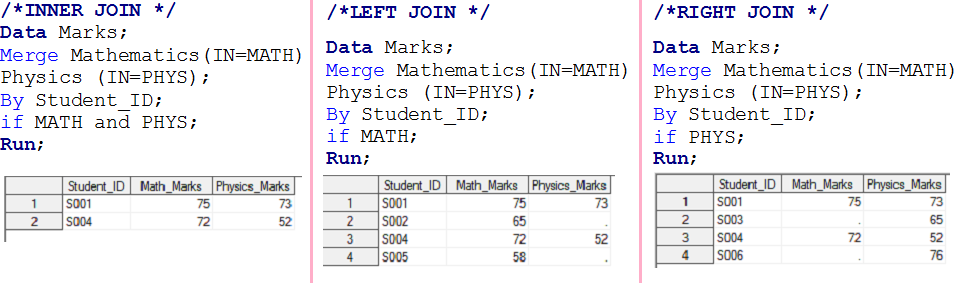
Relation UN à PLUSIEURS
Organiser – 3 Ici, nous avons deux ensembles de données, Étudiant Oui Examen et nous voulons créer un ensemble de données de sortie Marques.
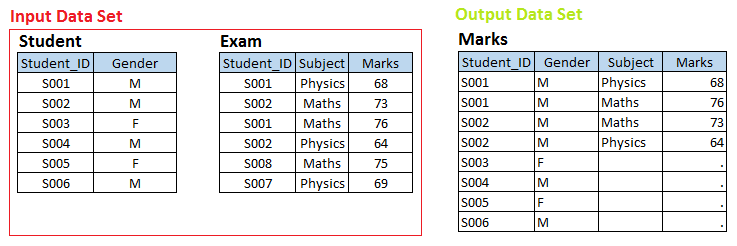
Au-dessus des ensembles de données d'entrée, il existe une relation un-à-plusieurs entre l'étudiant et l'examen. À présent, si vous souhaitez créer des notes d'ensemble de données de sortie avec une observation individuelle pour chaque examen d'étudiant, ceux-ci appartiennent à l'ensemble de données STUDENT, c'est-à-dire, Union à gauche.
Solution utilisant les étapes de données: –
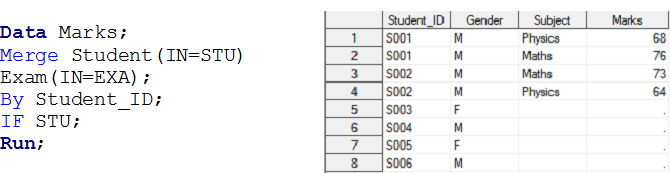
de la même manière, nous pouvons effectuer des opérations pour la jointure interne, droit et plein pour une relation un-à-plusieurs utilisant l'opérateur IN.
Ratio BEAUCOUP à BEAUCOUP
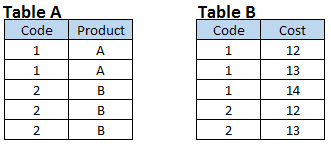
Organiser 4: Créer des ensembles de données de sortie qui ont toutes les jointures basées sur un champ commun. Vous pouvez également voir que les deux ensembles de données d'entrée ont une relation plusieurs-à-plusieurs.
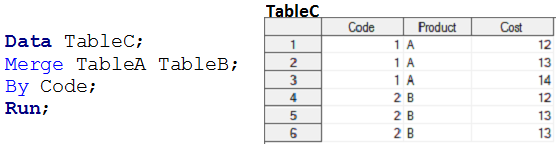
Les étapes de données ne créent pas de relation MANY à MANY, car ils ne fournissent pas de sortie en tant que produit cartésien. Lorsque nous fusionnons la table A et la table B en utilisant des étapes de données, la sortie est similaire à l'instantané suivant.
 Nous avons déjà vu, Comment pouvons-nous utiliser les étapes de données pour fusionner deux ensembles de données ou plus qui ont l'une des relations, sauf BEAUCOUP à BEAUCOUP? Nous allons maintenant voir les méthodes PROC SQL pour avoir une solution pour des exigences similaires.
Nous avons déjà vu, Comment pouvons-nous utiliser les étapes de données pour fusionner deux ensembles de données ou plus qui ont l'une des relations, sauf BEAUCOUP à BEAUCOUP? Nous allons maintenant voir les méthodes PROC SQL pour avoir une solution pour des exigences similaires.
PROC SQL
Pour comprendre la méthodologie de jointure en SQL, il faut d'abord comprendre le produit cartésien. Le produit cartésien est une requête qui a plusieurs tables dans la clause from et produit toutes les combinaisons possibles de lignes à partir des tables d'entrée. Si nous avons deux tables avec 2 Oui 4 enregistre respectivement, en utilisant le produit cartésien, nous avons une table avec 2 X 4 = 8 enregistrements.
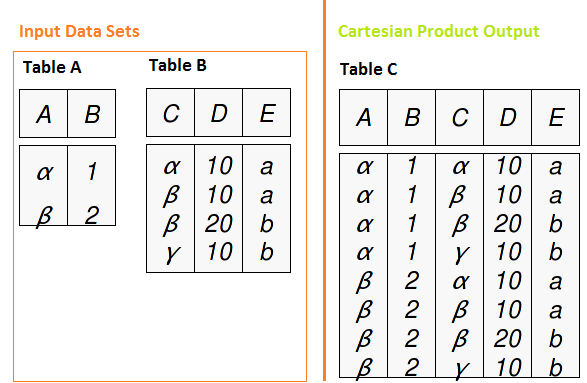
Les jointures SQL fonctionnent pour chacune des relations entre les ensembles de données (un à un, un à plusieurs et plusieurs à plusieurs). Voyons comment cela fonctionne avec les types de jointures.
Syntaxe:-
Veuillez sélectionner Colonne-1, Colonne-2,… Colonne-n du tableau1 JOINT INTÉRIEUR / GAUCHE / DROITE / COMPLET tcapaz2 SUR Condition de jointure ;
Noter:-
- Les tableaux peuvent ou non être classés par variables communes.
- Le nom des variables communes peut ne pas être similaire, mais il doit être similaire en longueur et en type.
- Fonctionne avec un maximum de deux tables.
Résolvons les exigences ci-dessus en utilisant PROC SQL.
Organiser 1 :- C'était un exemple de FULL Join, où tous les Student_ID étaient requis dans l'ensemble de données de sortie avec les indicateurs MATH et PHYSICS respectifs.

En haut dans l'ensemble de données de sortie, vous pouvez voir que Student_ID est manquant pour les étudiants qui se sont présentés à l'examen de physique uniquement. Pour le résoudre, nous utiliserons une fonction COALESCE. Renvoie la valeur du premier argument qui ne manque pas dans les variables données.
Syntaxe:-
SE FONDRE (argument-1, argument-2,… ..argument-n)
Modifions le code ci-dessus: –
Organiser 2: – C'était un exemple de INTÉRIEUR, Rejoindre Gauche et Droite. Ici, nous résolvons pour Inner Join. De la même manière, nous pouvons faire pour la jonction gauche et droite.
De la même manière, nous pouvons faire pour la jonction gauche et droite.
Organiser -3 Il s'agissait d'un problème de jointure gauche pour une relation ONE à MANY.
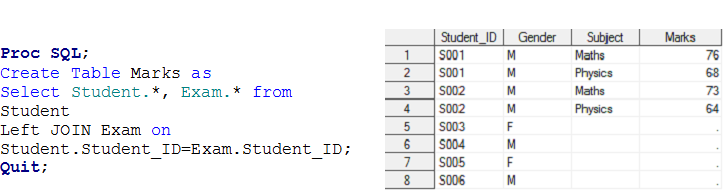
Organiser -4 C'était un problème de relation plusieurs à plusieurs. Nous avons déjà discuté du fait que SQL peut produire un produit cartésien qui contient toutes les combinaisons d'enregistrements entre deux tables.

Ci-dessus, nous avons vu Proc SQL se joindre / fusionner des ensembles de données.
Note finale: –
Dans cette série d'articles sur la combinaison d'ensembles de données dans SAS, nous analysons diverses méthodes pour combiner des ensembles de données telles que l'ajout, concaténer, fusionner, fusible. Surtout dans cet article, nous en discutons en fonction de la relation entre les ensembles de données, différents types de jointures et comment nous pouvons les résoudre en fonction de différents scénarios. Nous avons utilisé deux méthodes (Étapes de données et PROC SQL) pour obtenir des résultats. Nous verrons l'efficacité de ces méthodes dans un des prochains articles..
Cette série vous a-t-elle été utile? Nous avons simplifié un sujet complexe comme la combinaison d'ensembles de données et essayé de le présenter de manière compréhensible. Si vous avez besoin de plus d'aide pour combiner des ensembles de données, n'hésitez pas à poser vos questions via les commentaires ci-dessous.
PS Avez-vous rejoint? Vidhya analytique Discuter encore? Si ce n'est pas comme ça, beaucoup de débats sur la science des données sont perdus. Ce sont quelques-unes des discussions qui ont lieu dans SAS:
1. Sélectionnez les variables et transférez-les vers un nouvel ensemble de données dans SAS
2. Importer le premier 20 enregistrements d'Excel vers SAS
3. Lorsque la déclaration ne fonctionne pas dans SAS





