introduction
GraphLab a été une avancée inattendue dans mon plan d'apprentissage. Après tout, « De bonnes choses arrivent quand on en attend moins ». Tout a commencé avec la fin de Piratage des données du Black Friday. De 1200 participants, nous avons nos gagnants et leurs solutions intéressantes.
je les ai lus et analysés. J'ai réalisé que j'avais raté un formidable outil d'apprentissage automatique. Une analyse rapide m'a dit que cet outil a un potentiel immense pour réduire nos douleurs de modélisation d'apprentissage automatique. Ensuite, J'ai décidé de l'explorer plus loin. Maintenant, j'ai passé quelques jours à comprendre sa science et ses méthodes logiques d'utilisation. À ma surprise, ce n'était pas difficile à comprendre.
Essayiez-vous d'améliorer votre modèle d'apprentissage automatique? Mais a-t-il surtout échoué? Essayez cet outil avancé d'apprentissage automatique. Un mois d'essai est gratuit et l'abonnement à 1 année est disponible GRATUITEMENT pour une utilisation académique. Alors, vous pouvez acheter un abonnement pour les années suivantes.
Pour démarrer rapidement, voici un guide du débutant sur GraphLab en Python. Pour faciliter la compréhension, J'ai essayé d'expliquer ces concepts de la manière la plus simple possible.
Sujets couverts
- Comment tout a commencé ?
- Qu'est-ce que GraphLab?
- Avantages et limites de GraphLab
- Comment installer GraphLab?
- Premiers pas avec GraphLab
Comment tout a commencé ?
GraphLab a une histoire intéressante depuis ses débuts. Laissez-moi vous dire brièvement.
GraphLab, connu sous le nom de Dato est fondé par Carlos Guestrin. Carlos est titulaire d'un doctorat en informatique de l'Université de Stanford. C'est arrivé environ 7 ans. Carlos était professeur à l'Université Carnegie Mellon. Deux de ses étudiants travaillaient sur des algorithmes d'apprentissage automatique distribué à grande échelle. Ils ont exécuté leur modèle sur Hadoop et ont constaté que le calcul prenait beaucoup de temps. Les situations ne se sont même pas améliorées après l'utilisation IPM (bibliothèque informatique haute performance).
Ensuite, a décidé de construire un système pour écrire plus d'articles rapidement. Avec ça, GraphLab est né.
PD – GraphLab Create est un logiciel commercial de GraphLab. GraphLab Create est accessible en Python à l'aide de la bibliothèque “laboratoire de graphes”. Donc, dans cet article, 'GraphLab’ connota GraphLab Créer. Ne sois pas confus.
Qu'est-ce que GraphLab?
GraphLab est un nouveau framework parallèle pour l'apprentissage automatique écrit en C ++. Il s'agit d'un projet open source et a été conçu en tenant compte de l'échelle, variété et complexité des données du monde réel. Intègre plusieurs algorithmes de haut niveau tels que Stochastic Gradient Descent (EUR), Descente graduelle & Verrouillage pour offrir une expérience haute performance. Aide les data scientists et les développeurs à créer et installer facilement des applications à grande échelle.
Mais, Ce qui le rend incroyable? C'est la présence de bibliothèques ordonnées pour la transformation, manipulation et visualisation de modèles de données. En outre, est composé de boîtes à outils d'apprentissage automatique évolutives qui ont tout (presque) nécessaire pour améliorer les modèles d'apprentissage automatique. La boîte à outils comprend la mise en œuvre pour l'apprentissage en profondeur, machines à facteurs, modélisation de thème, regroupement, voisins les plus proches et plus.
Voici l'architecture complète de GraphLab Create.
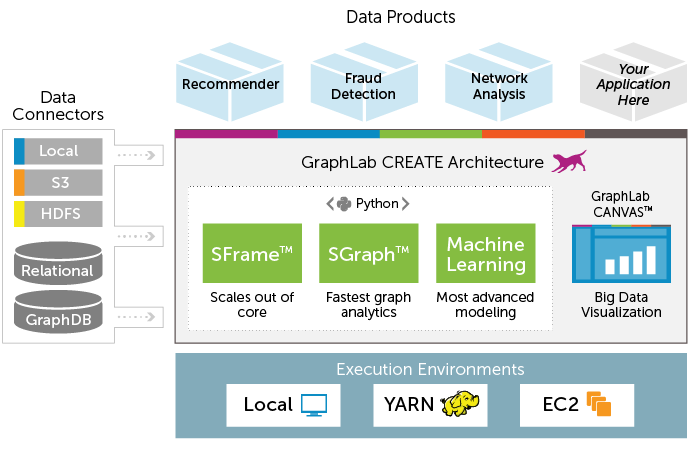
Quels sont les avantages d'utiliser GraphLab?
Il y a plusieurs avantages à utiliser GraphLab comme indiqué ci-dessous:
- Gérer les mégadonnées: La structure de données GraphLab peut gérer de grands ensembles de données, ce qui permet un apprentissage automatique évolutif. Regardons la structure de données de Graph Lab:
-
- SFrame: Il s'agit d'une structure de données tabulaire efficace sur disque qui n'est pas limitée par la RAM. Aide à mettre à l'échelle le traitement et l'analyse des données pour gérer de grands ensembles de données (Téra octet), même sur votre ordinateur portable. Il a une syntaxe similaire aux pandas ou aux trames de données R. Chaque colonne est une SArray, qui est une série d'éléments stockés sur disque. Cela rend les SFrames sur disque. J'ai discuté des méthodes de travail avec les "SFrames" dans les sections suivantes..
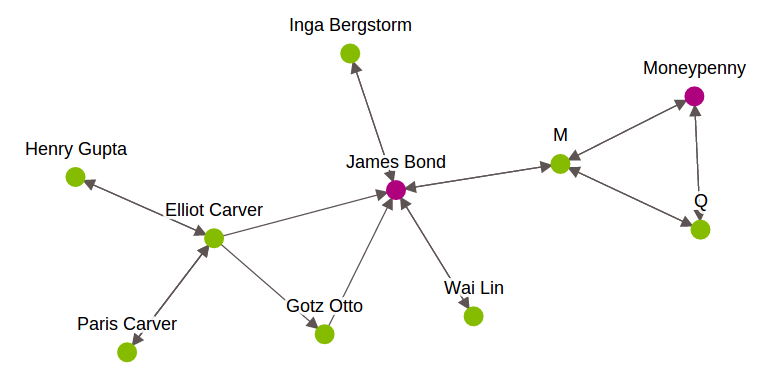
- SGraphique: Le graphique nous aide à comprendre les réseaux en analysant les relations entre les paires d'éléments. Chaque élément est représenté par un sommet dans le graphique. La relation entre les éléments est représentée par bords. En GraphLab, pour effectuer une analyse de données orientée graphique, les usages SGraphique objet. Il s'agit d'une structure de données de graphique évolutive qui stocke les sommets et les arêtes dans des SFrames. Pour en savoir plus à ce sujet, regarde ça Relier. Ci-dessous une représentation graphique des personnages de James Bond.

-
- Intégration avec diverses sources de données: GraphLab prend en charge diverses sources de données comme S3, ODBC, JSON, CSV, HDFS et bien d'autres.
- Explorer et visualiser des données avec GraphLab Canvas. GraphLab Canvas est une interface graphique interactive basée sur un navigateur qui vous permet d'explorer des données tabulaires, statistiques récapitulatives et graphiques bivariés. Avec cette fonction, passer moins de temps à coder l'exploration des données. Cela vous aidera à vous concentrer davantage sur la compréhension de la relation et de la distribution des variables.. J'ai parlé de cette partie dans les sections suivantes.
- Ingénierie fonctionnelle: GraphLab a une option intégrée pour créer de nouvelles fonctions utiles pour améliorer les performances du modèle. Il se compose de plusieurs options telles que la transformation, regroupement, imputation, un encodage à chaud, tf-idf, etc.
- La modélisation: GraphLab dispose de plusieurs ensembles d'outils pour offrir une solution rapide et facile aux problèmes de ML. Permet d'effectuer divers exercices de modélisation (régression, classification, regroupement) en moins de lignes de code. Vous pouvez travailler sur des problèmes comme le système de recommandation, la prédiction d'abandon, analyse des sentiments, analyse d'images et bien d'autres.
- Automatisation de la production: Les pipelines de données vous permettent d'assembler des tâches de code réutilisables en tâches. Alors, les exécuter automatiquement dans des environnements d'exécution courants (par exemple, Services Web Amazon, Hadoop).
- GraphLab Créer un SDK: Les utilisateurs avancés peuvent étendre les capacités de GraphLab Create à l'aide du SDK GraphLab Creat. Vous pouvez définir de nouveaux modèles / programmes d'apprentissage automatique et les intégrer au reste du package. Afficher le référentiel GitHub ici.
- Licence: A une limitation d'utilisation. Vous pouvez opter pour une période d'essai gratuite de 30 jours ou une licence d'un an pour l'édition académique. Pour prolonger votre abonnement, Tu seras chargé (voir structure d'abonnement ici).
Comment installer GraphLab?
Vous pouvez également utiliser GraphLab une fois que vous avez utilisé votre licence. Cependant, vous pouvez également commencer avec l'essai gratuit ou l'édition académique avec abonnement de 1 année. Donc, avant l'installation, votre machine doit répondre à la configuration système requise pour exécuter GraphLab.
Configuration requise pour GraphLab:

Si votre système ne répond pas aux exigences ci-dessus, Vous pouvez utiliser GraphLab Create dans l'offre gratuite d'AWS en outre.
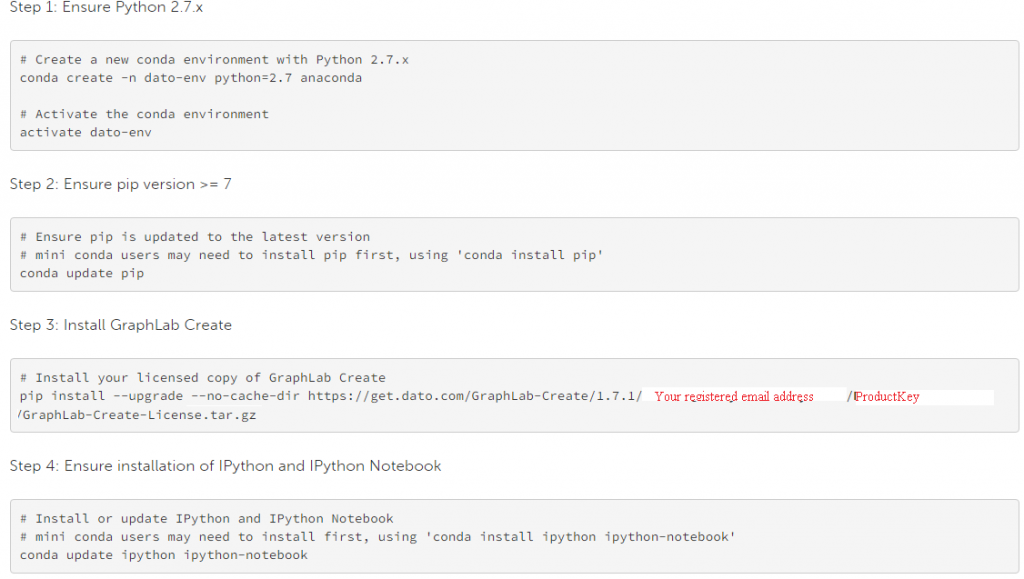
Étapes pour l'installation:
- Inscrivez vous pour libre parcours. Après inscription, vous recevrez une clé de produit.
- Sélectionnez votre système d’exploitation (la sélection automatique est activée) et suivez les instructions données
- Voici les instructions d’installation en ligne de commande (à “Environnement Python Anaconda”).
Premiers pas avec Graphlab
Une fois que vous avez installé GraphLab avec succès, vous pouvez y accéder en utilisant “importer ».
import graphlab
or
import graphlab as gl
Ici, Je démontrerai l’utilisation de GraphLab en résolvant un défi de science des données. J’ai l’ensemble de données tiré de Piratage des données du Black Friday.
-
-
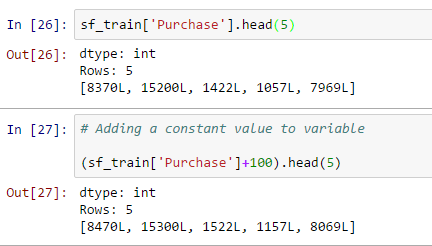
- Manipulation de données: vous pouvez également effectuer une opération de manipulation de données avec sframe, comment ajouter une valeur constante à toutes les valeurs, concaténer deux variables ou plus, créer une nouvelle variable de sortie basée sur une variable comme indiqué ci-dessous:
- Ajouter une valeur constante à la variable:

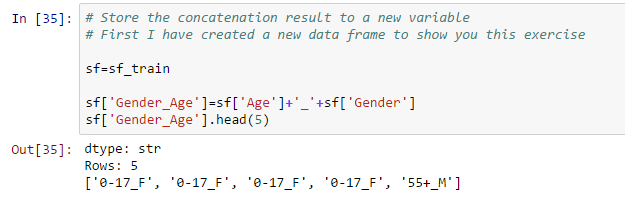
- Concaténer deux chaînes et les stocker dans une nouvelle variable:

- Mettre à jour les valeurs des variables existantes: cela peut être fait à l’aide de la fonction d’application. Dans cet ensemble de données, J’ai combiné des groupes d’âge supérieurs à 50 en utilisant le code suivant:
# Apporter une modification à la variable existante # Combiner tous les bacs d’âge supérieur à 50
def combine_age(âge): si âge=='51-55': return '50+' elif age=='55+': return '50+' else: âge de retour
Sf['Âge']=sf['Âge'].appliquer(combine_age)
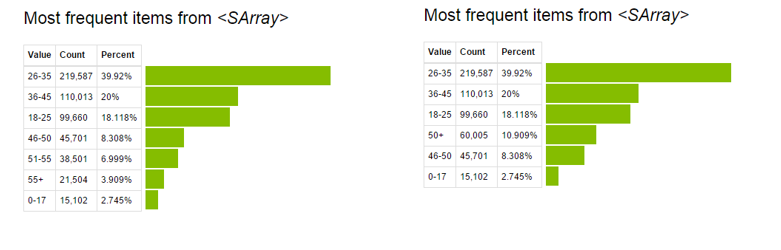
À présent, observer le pré- et post-affichage de la variable “Âge”.
 Pour plus de détails sur la manipulation des données avec GraphLab, regarde ça Relier.
Pour plus de détails sur la manipulation des données avec GraphLab, regarde ça Relier.
- Ajouter une valeur constante à la variable:
- Ingénierie fonctionnelle: L'ingénierie des caractéristiques est une méthode efficace pour améliorer les performances du modèle. Avec cette technique, nous pouvons créer de nouvelles variables après transformation ou manipulation de variables existantes. En réalité, GraphLab a automatisé ce processus. Ils ont plusieurs options de transformation pour les caractéristiques numériques, catégorique, texte et image. En outre, vous trouverez des options directes pour regrouper les fonctions, imputation, un encodage à chaud, seuil de comptage, TF-IDF, Hacheur, Tokenzing et autres. Regardons l'imputation caractéristique catégorique “Product_Category_2” basé sur “L'âge” Oui “Genre"De l'ensemble de données" Black Friday ".
# Créer les données # Variables en fonction desquelles nous voulons effectuer l'imputation et variable à imputer # Vous pouvez regarder les algorithmes derrière l'imputation ici. sf_impute = sf_train['Âge','Genre','Product_Category_2']
imputer = graphlab.feature_engineering. CategoricalImputer(fonctionnalité="Product_Category_2") # Fit and transform on the same data transformed_sf = imputer.fit_transform(sf_impute)#Retrieve the imputed values transformed_sf

Finalement, vous pouvez importer cette variable d’entrée dans le jeu de données d’origine.
sf_train[« Predicted_Product_Category_2 »]=transformed_sf[« predicted_feature_Product_Category_2 »]
de la même manière, vous pouvez appliquer d’autres opérations d’ingénierie d’entités au jeu de données en fonction de vos besoins. Vous pouvez vous référer à ceci Relier pour plus de détails.
- La modélisation: À ce stade, nous faisons des prédictions à partir de données passées. GraphLab crée facilement des modèles pour les tâches courantes, Quoi:
UNE) Prédiction des grandeurs numériques
B) Systèmes de recommandation de bâtiments
C) Données et documents du groupe
ré) Analyse graphique
- Manipulation de données: vous pouvez également effectuer une opération de manipulation de données avec sframe, comment ajouter une valeur constante à toutes les valeurs, concaténer deux variables ou plus, créer une nouvelle variable de sortie basée sur une variable comme indiqué ci-dessous:
-
 Pour plus de détails sur la manipulation des données avec GraphLab, regarde ça
Pour plus de détails sur la manipulation des données avec GraphLab, regarde ça 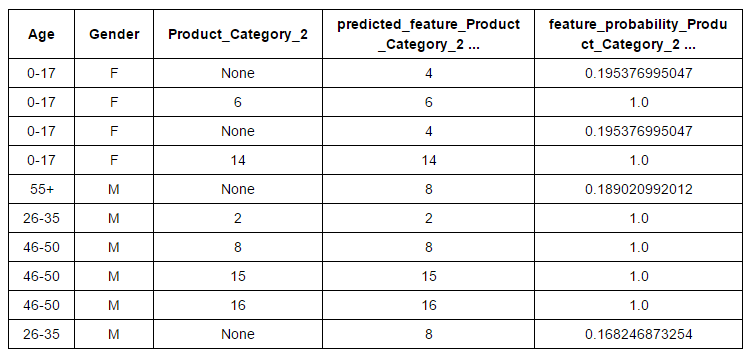
Dans le Black Friday Challenge, nous sommes obligés de prédire des quantités numériques “Acheter”, c'est-à-dire, nous avons besoin d’un modèle de régression pour prédire le “Acheter”.
En GraphLab, tenemos tres tipos de modelos de regresión:
UNE) Régression linéaire
B) Régression de forêt aléatoire
C) Regresión impulsada por gradientes
Si tiene alguna confusión en la selección del algoritmo, GraphLab se encarga de eso. Ne t'inquiète pas. Selecciona el modelo de regresión correcto automáticamente.
# Make a train-test split
train_data, validate_data = sf_train.random_split(0.8)
# Choisit automatiquement le bon modèle en fonction de vos données. modèle = graphlab.regression.create(train_données, cible="Achat", caractéristiques = ['Genre','Âge',« Profession »,« City_Category »,« Stay_In_Current_City_Years », « Marital_Status »,« Product_Category_1 »])
# Save predictions to an SArray
predictions = model.predict(validate_data)
# Evaluate the model and save the results into a dictionary
results = model.evaluate(validate_data)
résultats
Production:
{« max_error »: 13377.561969523947, 'rmse': 3007.1225949345117}
#Do prediction on test data set
final_predictions = model.predict(sf_test)
Pour en savoir plus sur d'autres techniques de modélisation telles que le regroupement, classification, système de recommandation, analyse de texte, analyse graphique, systèmes de recommandation, tu peux vérifier ça Relier. Alternativement, voici le complet Guide de l'utilisateur par données.
Remarques finales
Dans cet article, nous avons appris “GraphLab Créer”, qui permet de gérer un grand ensemble de données tout en créant des modèles d'apprentissage automatique. Nous analysons également la structure de données de Graphlab qui lui permet de gérer de grands ensembles de données tels que "SFrame" et "SGraph". Je vous recommande d'utiliser GraphLab. Vous adorerez ses fonctionnalités automatisées comme l'exploration de données (Toile, outil interactif d'exploration de données Web), ingénierie fonctionnelle, sélection de modèles adaptés et mise en œuvre.
Pour une meilleure compréhension, J'ai également fait la démonstration d'un exercice de modélisation à l'aide de GraphLab. Dans mon prochain article sur GraphLab, Je me concentrerai sur l'analyse des graphiques et le système de recommandation.
Trouvez-vous utile cet article ? Partagez avec nous votre expérience avec GraphLab.





