Cet article a été publié dans le cadre du Blogathon sur la science des données
Les sections de votre mélodie principale sont une sorte de rayures dans la toile d'araignée !! Indépendamment, les mots « grattage web » impliquent généralement une connexion qui intègre l'informatisation. Quelques destinations pourraient le contourner lorsque des débogueurs personnalisés collectent vos données, tandis que d'autres s'en moquent.
En espérant que vous grattez délibérément une page pour des éléments d'information, tu n'auras probablement aucun problème. Prendre tout en compte, c'est une bonne idée de faire une évaluation isolée et de s'assurer que vous n'ignorez pas les conditions d'utilisation avant de commencer un projet de diplôme gigantesque. Pour se familiariser avec les éléments légaux du grattage Web, jetez un œil à Informations juridiques sur le grattage de données sur le Web moderne.
Pourquoi le web scraping?
Juste au moment où nous grattons le web, nous créons un code qui envoie une requête qui fonctionne avec la page que nous décidons. Le spécialiste retournera le code source – HTML, pour la plupart – de la page (ou pages) auquel nous avons fait référence.
Jusqu'à une date récente, fondamentalement, nous faisons plus qu'un programme Web: envoyer l'intérêt avec une URL spécifique et mentionner que le spécialiste renvoie le code pour cette page.
Dans tous les cas, contrairement à un programme web, notre code de grattage Web ne traduira pas le code source de la page et affichera la page ostensiblement. Prendre tout en compte, nous penserons à un code personnalisé qui passe par le code source de la page à la recherche de parties express que nous avons démontrées et en supprimant toute substance que nous lui avons appris à supprimer.
Par exemple, au cas où nous nous attendions à obtenir les données totales à l'intérieur d'un tableau apparaissant sur une page de site, notre code serait formé pour suivre ces méthodes dans la collecte:
1 Demande de substance (code source) à partir d'une URL spécifique au travailleur
2 Décharger la substance qui est retournée.
3 Distinguer les segments de la page qui sont fondamentaux pour le tableau dont nous avons besoin.
4 Concentrez-vous et (si c'est crucial) reformater ces segments dans un ensemble de données que nous pouvons démonter ou utiliser de la manière dont nous avons besoin.
Si tout ça a l'air particulièrement compliqué, Ne pousse pas! Python et Beautiful Soup ont des caractéristiques naturelles proposées pour rendre cela pour la plupart immédiat.
Une chose qu'il est essentiel de garder à l'esprit: du point de vue d'un spécialiste, référencer une page via le web scratch est comparable à l'empiler dans un programme web. Exactement quand nous utilisons du code pour saisir ces demandes, on pourrait être « empiler » pages beaucoup plus rapidement qu'un client standard, et ainsi consommer rapidement les ressources en main d'œuvre du propriétaire du site.
Web Scraping de données pour l'apprentissage automatique:
Au cas où vous gratteriez les données pour l'IA, promettez que vous avez vérifié les faibles concentrations avant d'aborder l'extraction de données.
Format des données:
Les modèles d'intelligence simulée peuvent simplement augmenter brusquement la popularité des données qui sont dans une association simple ou de type tableau. Dans ce sens, le grattage des données non structurées nécessitera, de cette manière, une plus grande liberté de prendre soin des données avant qu'elles ne puissent être utilisées.
Liste de données:
Puisque l'objectif principal est l'intelligence artificielle, lorsque vous avez les emplacements ou les pages de la page Web que vous souhaitez supprimer, vous devez faire un aperçu des centres de données ou des sources de données que vous souhaitez supprimer de chaque page du site. Si le cas a pour objectif final de manquer un grand nombre de centres de données pour chaque page du site, alors il faut réduire et choisir les data centers qui sont habituellement présents. La raison en est que tant de fonctionnalités NA ou vides réduiront la présentation et la précision du modèle d'IA. (ML) qui s'entraîne et teste avec les données.
Étiquetage des données:
La vérification des faits peut être une agonie cérébrale. Dans tous les cas, si vous pouvez accumuler les métadonnées nécessaires pendant que les données sont supprimées et les stocker en tant que point de données alternatif, bénéficiera aux étapes correspondantes du cycle de vie des données.
Nettoyer, préparer et stocker des données
Bien que ce mouvement puisse sembler fondamental, est généralement peut-être l'avancée la plus enchevêtrée et la plus triste. Ceci est le résultat direct d'une clarification claire: il n'y a pas de connexion unique. Cela dépend des données que vous avez supprimées et d'où vous les avez supprimées. Vous aurez besoin de stratégies rapides pour nettoyer les données.
Plus important encore, vous devez examiner les données pour comprendre quelles sont les dégradations dans les sources de données. Vous pouvez le faire en utilisant une bibliothèque comme Pandas (disponible en python). Au moment de votre évaluation, vous devez créer une substance pour éliminer les déformations dans les sources de données et normaliser les centres de données qui ne sont pas comme les autres. Alors, exécuterait de gros contrôles pour vérifier si les centres de données ont toutes les données dans un type de données singulier. Un fragment qui doit contenir des nombres ne peut pas avoir de ligne de données. Par exemple, celui qui devrait contenir des données dans dd config / mm / aaaa ne peut pas contenir de données dans une autre association. En dehors de ces contrôles de plan, fonctionnalités manquantes, les caractéristiques invalides et tout autre élément pouvant perturber le traitement des données, doit être perçu et corrigé.
Pourquoi Python pour le grattage Web?
Python est un appareil connu pour exécuter le web scratching. Le langage de programmation Python est également utilisé pour d'autres activités importantes identifiées avec la sécurité du réseau, tests d'entrée ainsi que des applications mesurables avancées. Utilisation de la programmation Python de base, le grattage Web peut être effectué sans utiliser aucun autre périphérique externe.
Le langage de programmation Python est de plus en plus répandu et les raisons qui font de Python un partenaire solide pour les projets de grattage Web sont les suivantes:
Simplicité de notation
Python a la construction la plus simple par rapport aux autres dialectes de programmation. Cet élément Python simplifie les tests et un ingénieur peut se concentrer sur une programmation supplémentaire.
Modules intégrés
Une autre justification de l'utilisation de Python pour gratter sur le Web est l'incorporation des précieuses bibliothèques externes dont il dispose.. Nous pouvons effectuer de nombreuses exécutions identifiées avec le web scratching en utilisant Python comme base de programmation.
Langage de programmation open source
Python a une grande aide de la région car c'est un langage de programmation open source.
Large gamme d'applications
Python peut être utilisé pour différentes tâches de programmation allant du contenu du petit shell aux applications Web de grande entreprise.
Modules Python pour le web scraping
Le grattage Web est la voie à suivre pour développer un spécialiste capable d'extraire, analyser, télécharger et coordonner les données précieuses du Web en conséquence. A la fin de la journee, au lieu de sauvegarder physiquement les informations des sites, la programmation de grattage Web chargera et concentrera les informations de différents sites en fonction de nos prérequis.
Application
C'est une simple bibliothèque de travail Web Python. C'est une puissante bibliothèque HTTP utilisée pour accéder aux pages. Avec l'aide de Requêtes, nous pouvons obtenir le code HTML brut des pages du site qui pourrait ensuite être analysé pour récupérer les informations.
Belle soupe
Beautiful Soup est une bibliothèque Python permettant d'extraire des informations à partir d'enregistrements HTML et XML. A tendance à être utilisé avec des exigences, puisque vous avez besoin d'une information (signaler l'URL) faire un objet de soupe, puisque vous ne pouvez pas récupérer une page du site sans l'aide de quelqu'un d'autre. Vous pouvez utiliser le contenu python joint pour assembler le titre de la page et les hyperliens.
Code –
importer urllib.request depuis urllib.request importer urlopen, Demander de bs4 import BeautifulSoup wiki= "https://www.thestar.com.my/search/?q=VIH&qsort=le plus ancien&qrec=10&qcodestock =&pgno = 1" html=urlopen(wiki) bs= BelleSoupe(html,'lxml') bs Beautiful Soup est utilisé pour extraire la page du site
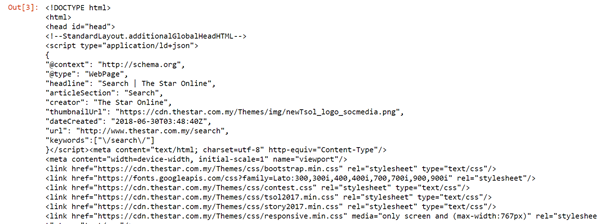
(source d'images: cahier jupyter)
Code-
de bs4 import BeautifulSoup
base_url="https://www.thestar.com.my/search/?q=VIH&qsort=le plus ancien&qrec=10&qcodestock =&pgno ="
# Ajouter 1 parce que la gamme Python.
liste_url = ["{}{}".format(base_url, str(page)) pour la page dans la plage(1, 408)]
s=[]
pour l'url dans url_list:
imprimer (URL)
ajouter(URL)
Production-
Le code ci-dessus répertorie le nombre de pages Web dans la plage de 1 une 407.
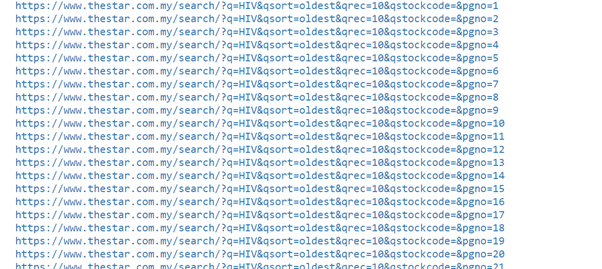
(source d'images: cahier jupyter)
Code –
données = []
données1= []
importer csv
depuis urllib.request importer urlopen, Erreur HTTP
à partir de datetime importer datetime, timedelta
pour pg en s:
# interrogez le site Web et renvoyez le code html à la variable 'page'
page = urllib.request.urlopen(page)
essayer:
search_response = urllib.request.urlopen(page)
sauf urllib.request.HTTPError:
passe
# analyser le html à l'aide d'un beau savon et le stocker dans la variable "soupe"
soupe = BelleSoupe(page, 'html.parser')
# Sortez le <div> du nom et obtenir sa valeur
ls = [x.get_text(bande=Vrai) pour x dans soup.find_all("h2", {"classer": "f18"})]
ls1 = [x.get_text(bande=Vrai) pour x dans soup.find_all("envergure", {"classer": "Date"})]
# enregistrer les données en tuple
data.append((ls))
data1.append(ls1)
Production-
Le code ci-dessus prendra toutes les données à l'aide d'une belle soupe et les enregistrera dans le tuple.
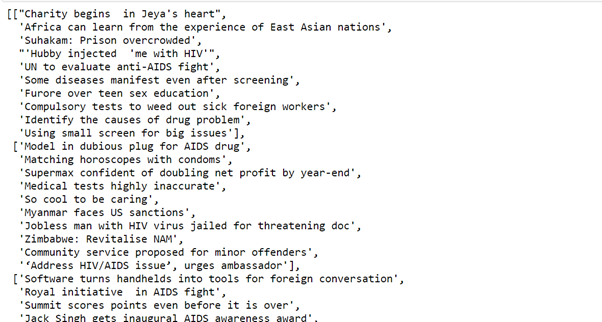
(source d'images: cahier jupyter)
Code
importer des pandas en tant que p df=p.DataFrame(F,colonnes=['Sujet de l'article']) df['Date']= f1
Production-
Pandas
Pandas est un instrument de recherche et de contrôle d'informations open source rapide, incroyable, adaptable et simple d'utilisation, basé sur le langage de programmation Python.
Le code ci-dessus stocke la valeur dans la trame de données.

(source d'images: cahier jupyter)
J'espère que vous apprécierez le code.
Petite présentation
Je, Sonia Singla, J'ai fait une maîtrise en bioinformatique de l'Université de Leicester, Royaume-Uni. J'ai également réalisé des projets sur la science des données du CSIR-CDRI. Il est actuellement membre consultatif du comité de rédaction d'IJPBS.
Linkedin – https://www.linkedin.com/in/soniasinglabio/
Les médias présentés dans cet article sur la mise en œuvre de modèles d'apprentissage automatique qui tirent parti de CherryPy et de Docker ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





