introduction
Une image vaut mieux que mille mots!
Dans l'environnement concurrentiel d'aujourd'hui, les entreprises veulent un processus décisionnel plus rapide, s'assurer qu'ils restent en tête de la course.
La visualisation des données aide à deux étapes critiques du processus de décision basé sur les données (Comme le montre la figure suivante):
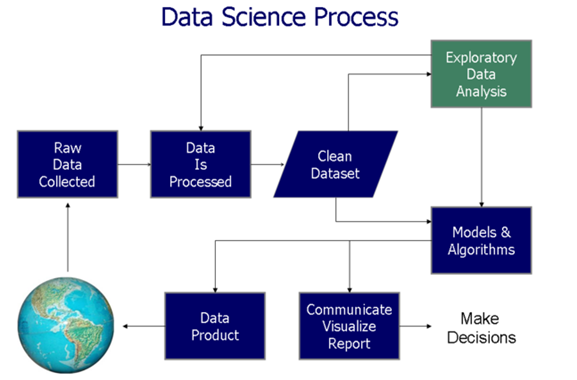
Dans cet article, nous allons explorer le 4 applications de visualisation de données et leur implémentation en SAS. Pour une meilleure compréhension, nous avons pris des exemples d'ensembles de données pour créer cette visualisation. Ensuite, les principaux aspects de la visualisation des données sont présentés:
- Faire une comparaison: Comprend un graphique à barres, graphique linéaire, graphique à barres, histogramme, histogramme à barres groupées.
- Relation d'étude: Comprend un graphique à bulles, nuage de points
- Étudier la distribution: Comprend un histogramme, Diagramme de dispersion,
- Comprendre la composition: Comprend un graphique à colonnes empilées

Commençons!
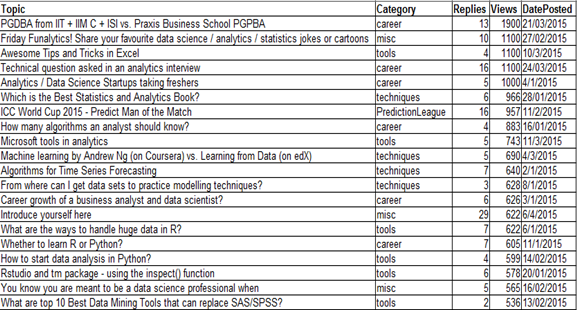
A des fins d'illustration, nous utiliserons un ensemble de données 'pour discuter’ tiré de la Vidhya analytique Discuter. Les données contiennent le sujet de discussion, la catégorie, le nombre de réponses à la publication et le nombre total de vues. Les données contiennent les 20 sujets principaux:
1. Faire une comparaison
une) Graphique à barres
UNE graphique à barres, Aussi connu comme graphique à barres représente des données regroupées à l'aide de barres rectangulaires de longueurs proportionnelles aux valeurs qu'elles représentent. Les barres peuvent être dessinées verticalement ou horizontalement. Un histogramme vertical est parfois appelé histogramme à colonnes.
Illustration
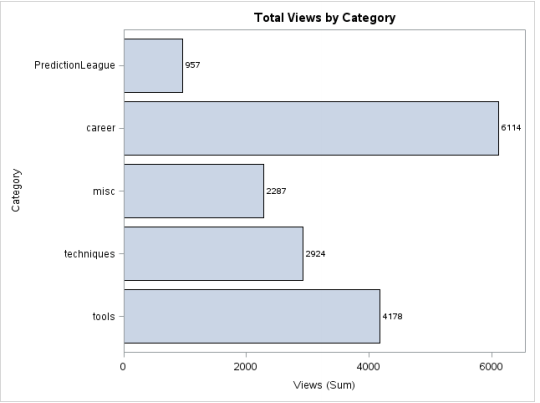
Cibler: On veut connaître le nombre de vues de chaque catégorie représentée graphiquement à travers un histogramme.
Code:
données proc sgplot = discuter;
hbar category/response = views stat = sum
datalabel datalabelattrs=(poids=gras);
titre 'Nombre total de vues par catégorie';
Cours;
Production:
B) Graphique à colonnes
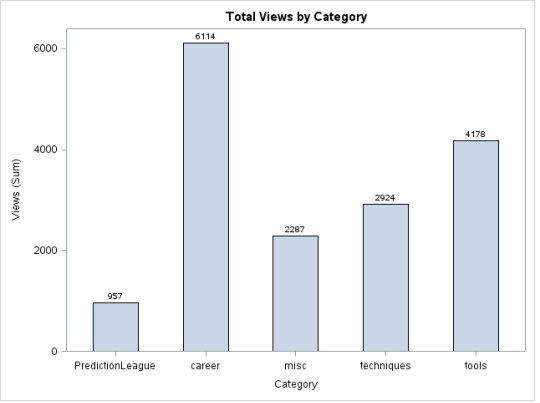
Les histogrammes sont souvent explicites. Ils sont simplement la version verticale d'un graphique à barres où la longueur des barres est égale à l'amplitude de la valeur qu'elles représentent. Voici une manoeuvre: transformer le graphique ci-dessus en -90 degrés, deviendra un histogramme.
Code:
données proc sgplot = discuter;
catégorie/réponse hbar = statistiques de vues = somme
datalabel datalabelattrs=(poids=gras) largeur de barre = 0.5; /* Attribuer de la largeur aux barres*/
title 'Total des vues par catégorie';
Cours;
Production:
-> Explication du code du graphique à barres et du graphique à colonnes:
- Catégorie: la variable selon laquelle les données doivent être regroupées.
- Réponse = vues: les statistiques spécifiées par stat = option sont calculées pour les vues de variables regroupées par variable de catégorie.
- L'option Datalabel spécifie que nous voulons que les valeurs calculées soient affichées pour chaque barre.
- L'option Poids = gras spécifie que les étiquettes de données pour chaque barre seront affichées en gras.
- L'option largeur de barre est utilisée pour attribuer une largeur aux barres. La valeur par défaut est 0.8 et la gamme est 0.1-1.
c) Graphique à barres / histogramme groupé
Ce type de représentation est utile lorsque l'on veut visualiser la répartition des données en deux catégories.
Cibler: Nous voulons analyser les vues totales des sujets dans le forum de discussion par catégorie et date de publication.
Code:
données discussion_date;
discuter;
mois = mois(Date postée);
nom_mois=PUT(Date postée,monnom.);
mettre nom_mois= @;
Cours;
proc sgplot data=discuss_date;
vbar category/ response=views group=month_name groupdisplay=cluster
datalabel datalabelattrs = (poids = gras) dataskin=brillant; grille de l'axe des y;
Cours;
Production:
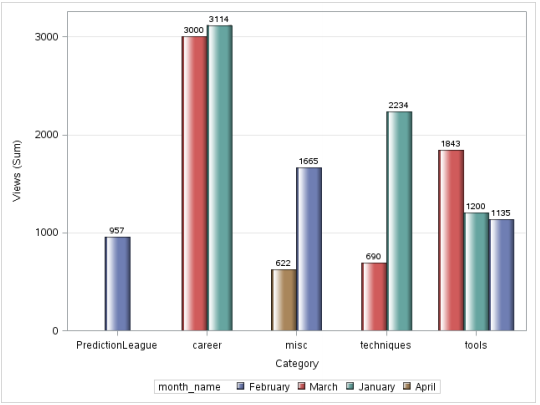
Cependant, il y a un problème avec cette image, les mois ne sont pas dans l'ordre chronologique. Pour résoudre ce, nous utilisons PROC FORMAT.
Coder avec PROC FORMAT:
données discussion_date; discuter; mois = mois(Date postée); num_mois = entrée(mois,5.); Cours;
FORMAT PROC;
VALEUR moisfmt
1 = 'Janvier'
2 = 'Février'
3 = 'Mars'
4 = 'Avril';
COURS;
proc sgplot data=discuss_date;
vbar category/ response=views group = month_num groupdisplay=cluster datalabel
datalabelattrs = (poids = gras) dataskin=gloss grouporder= ascendant;
format month_num monthfmt.;
grille de l'axe des y;
Cours;
Production:
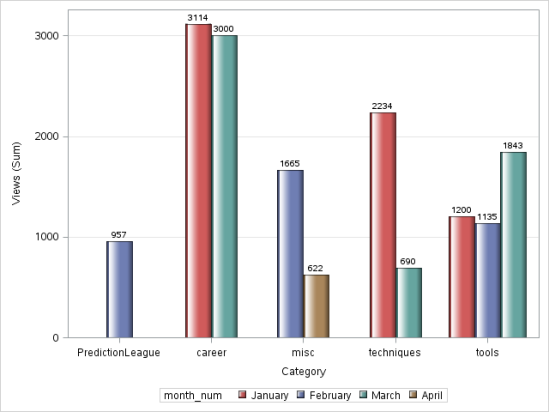
ré) Graphique linéaire
UNE Graphique linéaire O graphique linéaire est un type de graphique qui affiche des informations sous la forme d'une série de points de données appelés “signets” reliés par des segments de droite. Un graphique linéaire est souvent utilisé pour visualiser les tendances des données sur des intervalles de temps., une série temporelle, donc la ligne est souvent tracée chronologiquement. Dans ces cas, ils sont appelés exécuter des graphiques.
Pour cette illustration, nous utiliserons les données de PGDBA de IIT + IIM C + ISI frente a Praxis Business School PGPBA.
Code:
données proc sgplot = clics;
vline date/réponse = PGDBA_IIM_ ;
vline date/réponse = PGPBA_Praxis_;
étiquette de l'axe des y = "Clics";
Cours;
Production:
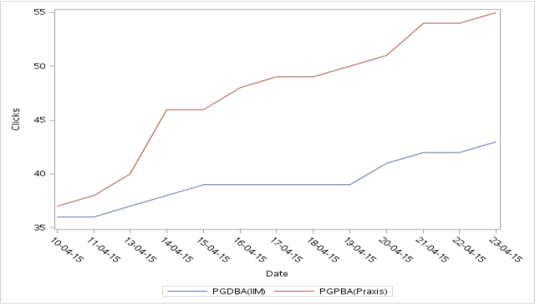
e) Graphique à barres
Ce graphique combiné combine les fonctionnalités du graphique à barres et du graphique en courbes. Affiche les données à l'aide d'une série de barres et / ou des lignes, dont chacun représente une catégorie particulière. Une combinaison de barres et de lignes dans la même visualisation peut être utile lors de la comparaison de valeurs dans différentes catégories.
Cibler: Nous voulons comparer les ventes projetées avec les ventes réelles pour différentes périodes.
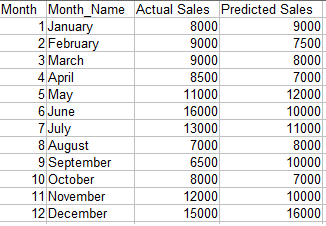
Code:
proc sgplot data=barline;
vbar month/ response=actual_sales datalabel datalabelattrs = (poids = gras)
remplissage = (couleur = bronzage);
vline mois/réponse=predicted_sales
lineattrs =(épaisseur = 3) Marqueurs;
étiquette xaxis= "Mois";
étiquette de l'axe des y = "Ventes";
légende clé / emplacement=à l'intérieur position=en haut à gauche à travers=1;
Cours;
Noter: Les données doivent être ordonnées par la variable de l'axe des x.
Production:
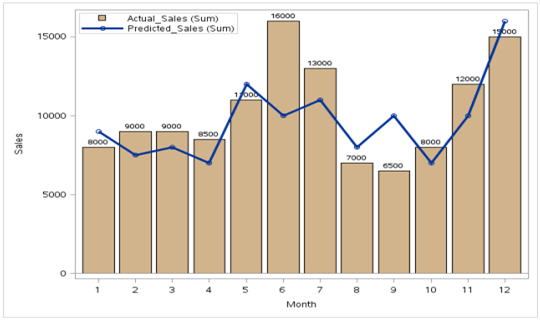
2) Étudier la relation
une) Graphique à bulles
Un graphique à bulles est un type de graphique qui affiche trois dimensions de données. Chaque entité avec son triplet (v1, v2, v3) les données associées sont tracées sous la forme d'un disque exprimant deux des vje valeurs sur le disque xy emplacement et le troisième pour sa taille. – La source: Wikipédia.
Données pour le système d'exploitation:
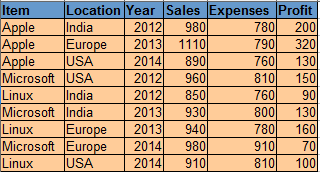
Code:
données proc sgplot = os;
bulle X=dépenses Y=taille des ventes=bénéfice
/fillattrs=(couleur = sarcelle) étiquette de données = Emplacement;
Cours;
Production:
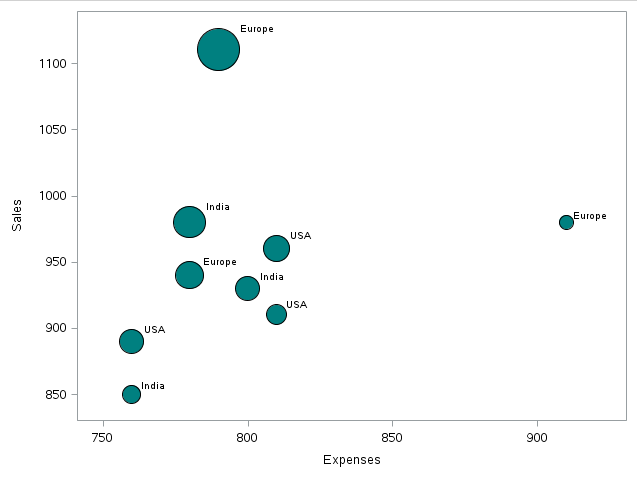
Comme nous pouvons le voir, il existe un enregistrement pour lequel les ventes et les bénéfices sont les plus élevés tandis que les dépenses comparatives sont inférieures à certains autres points de données.
b) Nuage de points pour la relation
Un simple diagramme de dispersion entre deux variables peut nous donner une idée de la relation entre elles: direct, exponentiel, etc. Cette information peut être utile lors d'une analyse ultérieure.
Code:
données proc sgplot = os;
titre « Relation du profit avec les ventes »;
scatter X= ventes Y = profit/
marqueurattrs=(symbole=taille encerclée=15);
Cours;
Production:
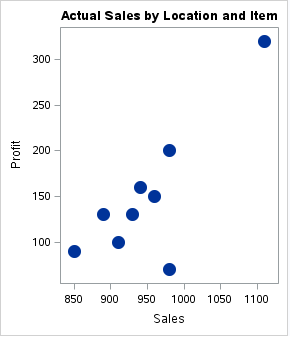
3. Étudier la répartition
une) Histogramme
UNE histogramme est une représentation graphique de la distribution des données numériques. C'est une estimation de la distribution de probabilité d'une variable continue. Pour construire un histogramme, la première étape est “Grouper” la plage de valeurs, c'est-à-dire, diviser toute la plage de valeurs en une série de petits intervalles, puis compter combien de valeurs tombent dans chaque intervalle. Les bacs sont généralement spécifiés comme des intervalles consécutifs, non chevauchement d'une variable. Les conteneurs (intervalles) doit être adjacent et, comme d'habitude, la même taille. Les rectangles d'un histogramme sont dessinés de manière à se toucher pour indiquer que la variable d'origine est continue.
Code:
données proc sgplot = sashelp.cars;
histogramme msrp/fillattrs=(couleur = acier)échelle = proportion;
densité msrp;
Cours;
Production:
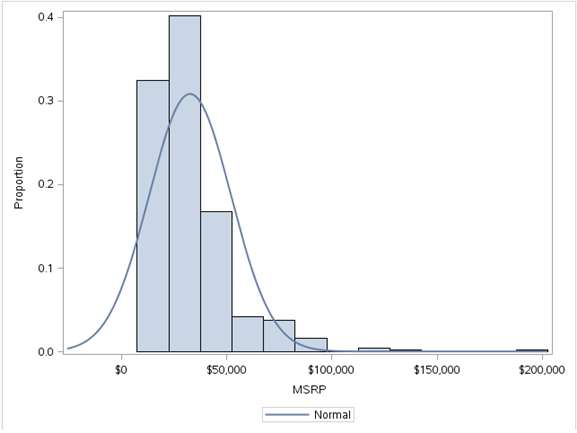
Nous avons utilisé l'ensemble de données sashelp.mtcars ici. Un histogramme de la variable MSRP nous donne le chiffre précédent. Cela nous indique que la variable MSRP est asymétrique vers la droite, indiquant que la plupart des points de données sont en dessous $ 50,000. Des informations significatives peuvent être trouvées à partir des histogrammes.
b) Diagramme de dispersion
en un nuage de points les données sont affichées comme une collection de points, chacun avec la valeur d'une variable qui détermine la position sur l'axe horizontal et la valeur de l'autre variable qui détermine la position sur l'axe vertical. Il peut être utilisé à la fois pour voir la distribution des données. et accéder à la relation entre les variables.
Noter: pour illustration, nous utiliserons un ensemble de données 'pour discuter’ tiré de la Vidhya analytique Discuter
Code:
données proc sgplot = discuter;
scatter X= dateposted Y = vues/groupe=catégorie
marqueurattrs=(symbole=taille encerclée=15);
Cours;
Production:
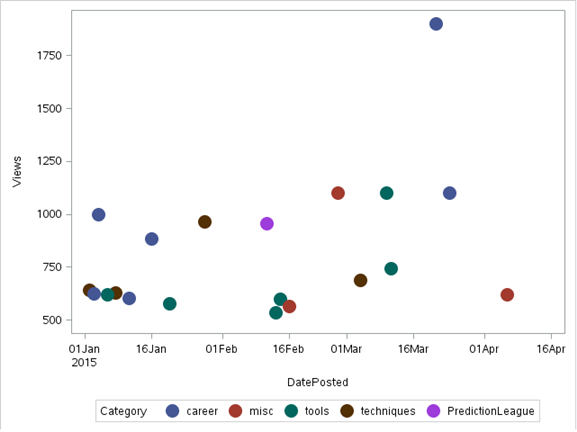
Les SGSCATTER La procédure peut également être utilisée pour les nuages de points. Il a l'avantage de pouvoir produire plusieurs diagrammes de dispersion. Ci-dessous se trouve la sortie utilisant sgcscatter:
Code:
proc sgscatter data = discuter;
comparer y = vues x = (catégorie de réponses)
/groupe = marqueur de moisattrs=(symbole = taille du cercle = 10);
Cours;
Production:
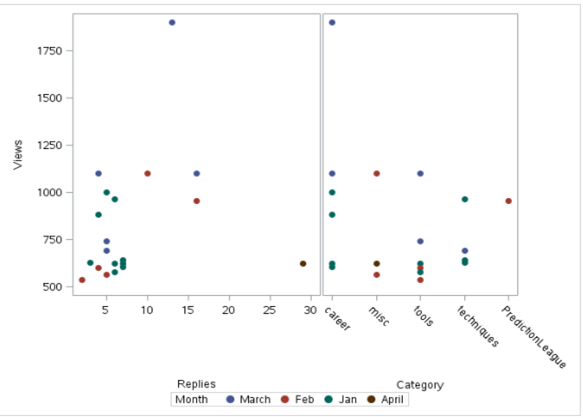
Une utilisation importante du nuage de points est l'interprétation des résidus de la régression linéaire. Un nuage de points des résidus par rapport aux valeurs prédites de la variable prédite nous aide à déterminer si les données sont hétéroscédastiques ou homoscédastiques..
HÉTÉROSQUEDASTIQUE HOMOSQUEDASTIQUE
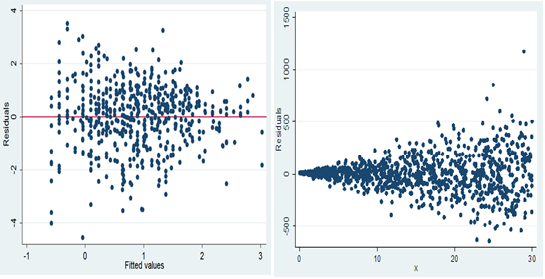
4) Composition
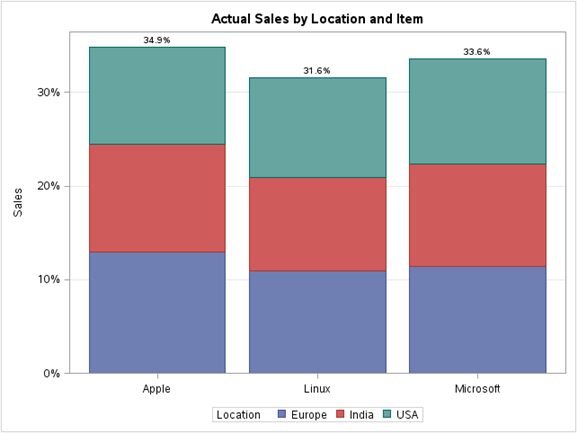
une) Graphique à colonnes empilées:
Sur un graphique à barres empilées, les barres empilées représentent différents groupes les uns sur les autres. La hauteur de la barre résultante montre le résultat combiné des groupes.
Par exemple, si nous voulons voir les ventes totales par article regroupées par emplacement dans les données totales de l'ensemble de données du système d'exploitation, nous pouvons utiliser le graphique à colonnes empilées. Ci-dessous l'illustration:
Code:
données proc sgplot = os; titre 'Ventes réelles par emplacement et article'; Article vbar / response=Sales group=Location stat=pourcentage datalabel; affichage de l'axe des x=(pas de label); étiquette de grille yaxis="Ventes"; Cours;
Production:
Remarques finales:
Les visualisations deviennent un moyen naturel de comprendre les données en masse. Ils véhiculent facilement des informations et facilitent l'échange d'idées avec les autres. Dans cet article, nous analysons quelques visualisations de base qui peuvent être réalisées via SAS base. Ceux-ci peuvent être un excellent moyen de résumer nos données, obtenir des informations, trouver des relations, etc.
Avez-vous trouvé cet article utile? Y a-t-il d'autres visualisations que vous avez utilisées que vous pouvez partager avec notre public? N'hésitez pas à les partager à travers les commentaires ci-dessous..





