Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
machine. Il s'inspire du fonctionnement d'un cerveau humain et, donc, est un ensemble d'algorithmes de réseau neuronal qui essaie d'imiter le fonctionnement d'un cerveau humain et d'apprendre des expériences.
Dans cet article, nous allons apprendre comment fonctionne un réseau de neurones de base et comment il s'améliore pour faire les meilleures prédictions.
Table des matières
- Les réseaux de neurones et leurs composants
- Perceptron et perceptron multicouche
- Travail pas à pas du réseau de neurones
- La rétropropagation et son fonctionnement
- Bref sur les fonctions d'activation
Réseaux de neurones artificiels et leurs composants
Les réseaux de neurones est un système d'apprentissage informatique qui utilise un réseau de fonctions pour comprendre et traduire une entrée de données d'une manière en une sortie souhaitée, normalement sous une autre forme. Le concept de réseau de neurones artificiels a été inspiré par la biologie humaine et la façon dont neurones du cerveau humain travaillent ensemble pour comprendre les entrées des sens humains.
En mots simples, les réseaux de neurones sont un ensemble d'algorithmes qui tentent de reconnaître des modèles, relations de données et informations à travers le processus qui est inspiré et fonctionne comme le cerveau / biologie humaine.
Composants (modifier) / Architecture de réseau de neurones
Un réseau de neurones simple se compose de trois composants :
- Couche d'entrée
- Cape cachée
- Couche de sortie

La source: Wikipédia
Couche d'entrée: Également appelés nœuds d'entrée, sont les entrées / informations du monde extérieur qui sont fournies au modèle pour apprendre et tirer des conclusions. Les nœuds d'entrée transmettent les informations à la couche suivante, c'est-à-dire, couche cachée.
Cape cachée: La couche cachée est l'ensemble des neurones où tous les calculs sont effectués sur les données d'entrée. Il peut y avoir n'importe quel nombre de couches cachées dans un réseau de neurones. Le réseau le plus simple consiste en une seule couche cachée.
Couche de sortie: La couche de sortie est la sortie / conclusions du modèle dérivées de tous les calculs effectués. Il peut y avoir un ou plusieurs nœuds dans la couche de sortie. Si nous avons un problème de classification binaire, le nœud de sortie est 1, mais dans le cas d'une classification multiclasse, les nœuds de sortie peuvent être plus de 1.
Perceptron et perceptron multicouche
Perceptron est une forme simple de réseau de neurones et se compose d'une seule couche où tous les calculs mathématiques sont effectués.
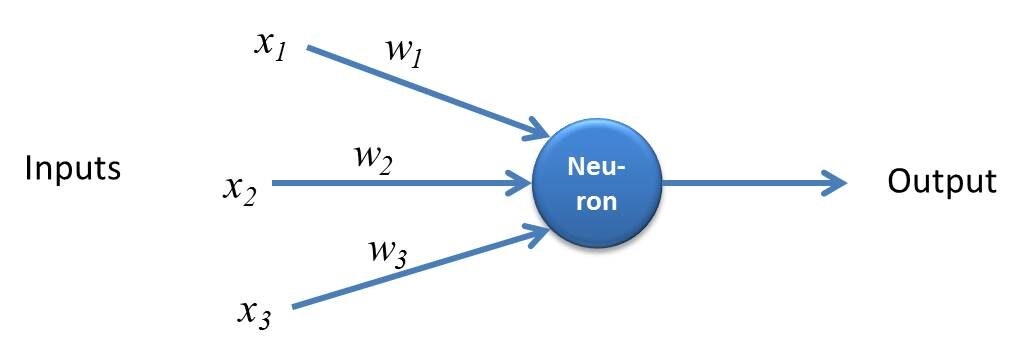
La source: kindonthegenius.com
Tandis que, Perceptron multicouche Aussi connu comme Réseaux de neurones artificiels Il se compose de plusieurs perceptions qui sont regroupées pour former un réseau neuronal multicouche.
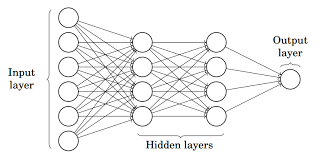
La source: Moitié
Dans l'image ci-dessus, le réseau de neurones artificiels se compose de quatre couches interconnectées:
- Une couche d'entrée, avec 6 nœuds d'entrée.
- Couverture avant 1 caché, avec 4 nœuds cachés / 4 perceptrons
- Cape cachée 2, avec 4 nœuds cachés
- Couche de sortie avec 1 nœud de sortie
Pas à pas Working de la rouge neuronale artificielle
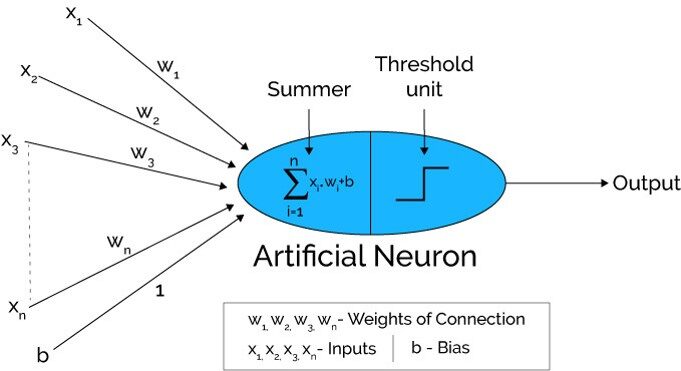
La source: Xenonstack.com
-
Dans la première étape Les unités d'entrée sont transmises, c'est-à-dire, les données sont transmises avec des poids attachés à la couche cachée.. Nous pouvons avoir n'importe quel nombre de couches cachées. Dans l'image ci-dessus, les entrées x1,X2,X3,….XNord est passé.
-
Chaque couche cachée est constituée de neurones. Toutes les entrées sont connectées à chaque neurone.
-
Après avoir transmis les billets, tout le calcul est fait dans la couche cachée (Ovale bleu sur la photo)
Le calcul effectué en couches cachées s'effectue en deux étapes qui sont les suivantes :
-
En premier lieu, toutes les entrées sont multipliées par leurs poids. Le poids est le gradient ou le coefficient de chaque variable. Montre la force de l'entrée particulière. Après avoir attribué les poids, une variable de biais est ajoutée. Biais est une constante qui aide le modèle à s'adapter de la meilleure façon possible.
AVEC1 = W1*Dans1 + W2*Dans2 + W3*Dans3 + W4*Dans4 + W5*Dans5 + b
W1, W2, W3, W4, W5 sont les poids affectés aux entrées In1, Dans2, Dans3, Dans4, Dans5, et b est le biais.
- Alors, dans la deuxième étape, les La fonction d'activation est appliquée à l'équation linéaire Z1. La fonction d'activation est une transformation non linéaire qui est appliquée à l'entrée avant de l'envoyer à la couche suivante de neurones. L'importance de la fonction d'activation est d'instiller la non-linéarité dans le modèle.
Il existe différentes fonctions d'activation qui seront énumérées dans la section suivante.
-
L'ensemble du processus décrit au point 3 effectué sur chaque couche cachée. Après avoir traversé chaque couche cachée, nous allons à la dernière couche, c'est-à-dire, notre couche de sortie qui nous donne la sortie finale.
Le processus expliqué ci-dessus est connu sous le nom de propagation vers l'avant.
-
Après avoir obtenu les prédictions de la couche de sortie, l'erreur est calculée, c'est-à-dire, la différence entre la production réelle et attendue.
Si l'erreur est grande, puis des mesures sont prises pour minimiser l'erreur et dans le même but, La propagation vers l'arrière est effectuée.
Qu'est-ce que la propagation en arrière et comment ça marche?
La propagation inverse est le processus de mise à jour et de recherche des valeurs optimales de poids ou de coefficients qui aide le modèle à minimiser l'erreur, c'est-à-dire, la différence entre les valeurs réelles et prévues.
Mais voici la question: Comment les poids sont-ils mis à jour et les nouveaux poids calculés ??
Les poids sont mis à jour à l'aide d'optimiseurs.. Les optimiseurs sont les méthodes / formulations mathématiques pour modifier les attributs des réseaux de neurones, c'est-à-dire, les poids pour minimiser l'erreur.
Propagation descendante vers l'arrière
Gradient Descent est l'un des optimiseurs qui aide à calculer les nouveaux poids. Comprenons étape par étape comment Gradient Descent optimise la fonction de coût.
Dans l'image ci-dessous, la courbe est notre courbe de fonction de coût et notre objectif est de minimiser l'erreur telle que Jmin c'est-à-dire, les minimums mondiaux sont atteints.
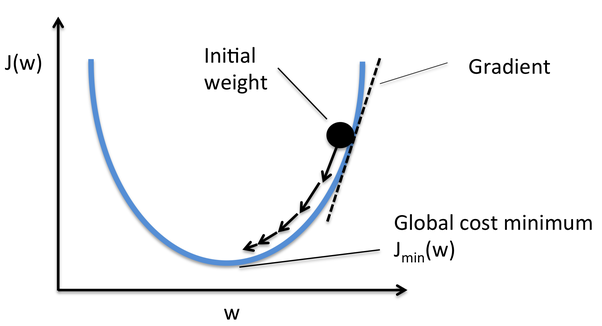
La source: Quora
Étapes pour atteindre les minimums mondiaux:
-
Premier, les poids sont initialisés de manière aléatoire c'est-à-dire, la valeur aléatoire du poids et les intersections sont affectées au modèle tandis que la propagation vers l'avant et les erreurs sont calculées après tout le calcul. (Comme discuté ci-dessus)
-
Alors lui la pente est calculée, c'est-à-dire, dérivé de l'erreur avec les poids actuels
-
Alors, les nouveaux poids sont calculés à l'aide de la formule suivante, où a est le taux d'apprentissage qui est le paramètre également connu sous le nom de taille de pas pour contrôler la vitesse ou les pas de la propagation arrière. Fournit un contrôle supplémentaire sur la vitesse à laquelle nous voulons nous déplacer dans la courbe pour atteindre les plus bas mondiaux.
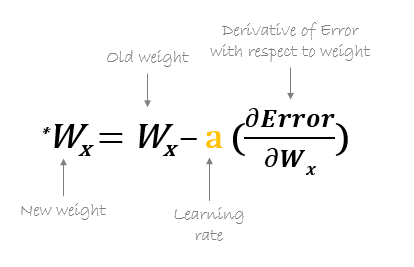
La source: hmkcode.com
4.Ce processus de calcul des nouveaux poids, puis les erreurs des nouveaux poids puis la mise à jour des poids. continue jusqu'à ce que nous atteignions les plus bas mondiaux et que la perte soit minimisée.
Un point à garder à l'esprit ici est que le taux d'apprentissage, c'est-à-dire, a dans notre mise à jour du poids L'équation doit être choisie judicieusement. Le taux d'apprentissage est la quantité de changement ou la taille de l'étape prise pour atteindre les minimums globaux. il ne doit pas être trop petit car il faudra du temps pour converger, aussi bien que ça ne doit pas être très gros qui n'atteint pas du tout les minimums mondiaux. Pourtant, le taux d'apprentissage est l'hyperparamètre que nous devons choisir en fonction du modèle.
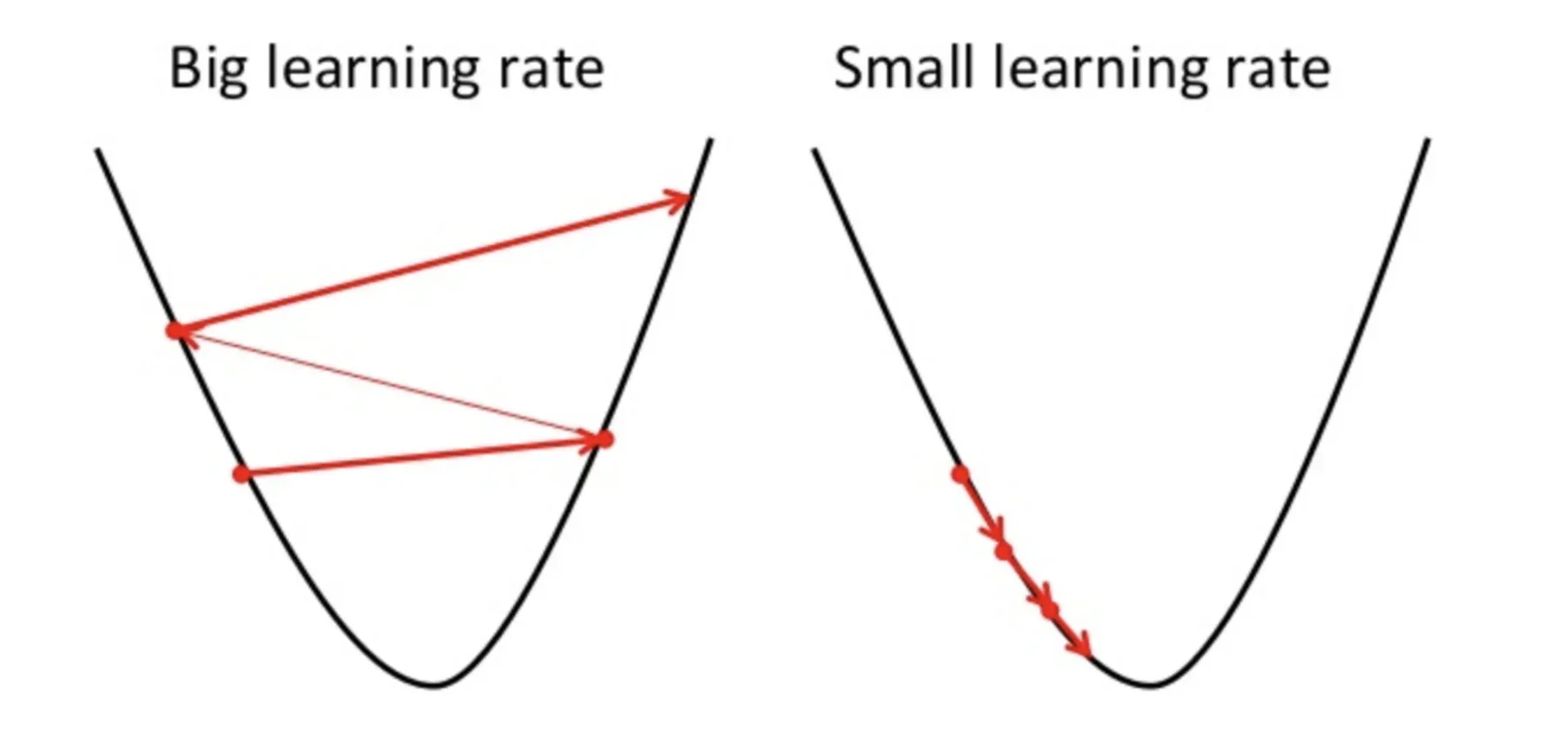
La source: Educatif.io
Connaître les mathématiques détaillées et la règle de la chaîne de rétropropagation, voir pièce jointe Didacticiel.
Bref sur les fonctions d'activation
Fonctions de déclenchement sont attachés à chaque neurone et sont des équations mathématiques qui déterminent si un neurone doit se déclencher ou non selon que l'entrée du neurone est pertinente ou non pour la prédiction du modèle. Le but de la fonction d'activation est d'introduire une non-linéarité dans les données.
Différents types de fonctions de déclenchement sont:
- Fonction d'activation sigmoïde
- Fonction d'activation TanH / Tangente hyperbolique
- Fonction unité linéaire rectifiée (reprendre)
- Fuite ReLU
- Softmax
Consultez ce blog pour une explication détaillée des fonctions d'activation.
Remarques finales
Ici, je conclus mon explication étape par étape du premier réseau de neurones d'apprentissage profond qui est ANA. J'ai essayé d'expliquer le processus de propagation de propagation et de rétropropagation de la manière la plus simple possible. J'espère que cet article valait la peine d'être lu
S'il vous plait, n'hésitez pas à me contacter sur LinkedIn et partagez votre précieuse contribution. S'il vous plait, consultez mes autres articles ici.
A propos de l'auteur
Soja Deepanshi Dhingra, Je travaille actuellement en tant que chercheur en science des données et j'ai une formation en analytique, l'analyse exploratoire des données, apprentissage automatique et apprentissage profond.
Les médias présentés dans cet article sur le réseau de neurones artificiels ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





