Vue d'ensemble
- L'ingénierie des fonctionnalités en PNL consiste à comprendre le contexte du texte.
- Dans ce blog, nous examinerons certaines des caractéristiques d'ingénierie courantes de la PNL.
- Nous comparerons les résultats d'une tâche de classification avec et sans ingénierie des fonctionnalités.
Table des matières
- introduction
- Présentation des tâches de la PNL
- Liste des fonctionnalités avec code
- Mise en œuvre
- Comparaison des résultats avec et sans ingénierie fonctionnelle
- conclusion
introduction
“Si il 80 pour cent de notre travail est la préparation de données, assurer la qualité des données est le travail important d'une équipe d'apprentissage automatique”. – André Ng

L'ingénierie fonctionnelle est l'une des étapes les plus importantes de l'apprentissage automatique. C'est le processus d'utilisation de la connaissance du domaine des données pour créer des caractéristiques qui font fonctionner les algorithmes d'apprentissage automatique.. Considérez l'algorithme d'apprentissage automatique comme un enfant qui apprend; plus les informations que vous fournissez sont précises, plus ils seront capables de bien interpréter l'information. Se concentrer d'abord sur nos données nous donnera de meilleurs résultats que de se concentrer uniquement sur les modèles. L'ingénierie des fonctionnalités nous aide à créer de meilleures données qui aident le modèle à bien les comprendre et à fournir des résultats raisonnables.
La PNL est un sous-domaine de l'intelligence artificielle dans lequel nous comprenons l'interaction humaine avec les machines en utilisant les langues naturelles. Pour comprendre une langue naturelle, il faut comprendre comment on écrit une phrase, comment nous exprimons nos pensées en utilisant des mots différents, panneaux, caractères spéciaux, etc., fondamentalement, nous devons comprendre le contexte de la phrase pour interpréter son sens.
Si nous pouvons utiliser ces contextes comme caractéristiques et les alimenter dans notre modèle, alors le modèle pourra mieux comprendre la phrase. Certaines des caractéristiques communes que nous pouvons extraire d'une phrase sont le nombre de mots, le nombre de mots majuscules, le nombre de points, le nombre de mots uniques, le nombre de mots vides, la durée moyenne de la peine, etc. Nous pouvons définir ces caractéristiques en fonction de notre ensemble de données que nous utilisons. Dans ce blog, nous utiliserons un ensemble de données Twitter afin de pouvoir ajouter d'autres caractéristiques comme le nombre de hashtags, le nombre de mentions, etc. Nous les aborderons en détail dans les sections suivantes..
Présentation des tâches de la PNL
Comprendre la tâche de l'ingénierie fonctionnelle en PNL, nous allons l'implémenter dans un ensemble de données Twitter. Nous utiliserons Ensemble de données de fausses nouvelles COVID-19. La tâche consiste à classer le tweet comme Faux O Vrai. L'ensemble de données est divisé en train, ensemble de validation et de test. Ci-dessous la répartition,
| Briser | Vrai | Faux | Total |
| Former | 3360 | 3060 | 6420 |
| Validation | 1120 | 1020 | 2140 |
| Test | 1120 | 1020 | 2140 |
Liste des fonctionnalités
Je vais énumérer un total de 15 fonctionnalités que nous pouvons utiliser pour l'ensemble de données ci-dessus, le nombre d'entités dépend totalement du type de jeu de données que vous utilisez.
1. Nombre de caractères
Compter le nombre de caractères présents dans un tweet.
def count_chars(texte):
retour len(texte)
2. Nombre de mots
Compter le nombre de mots présents dans un tweet.
def count_words(texte):
retour len(text.split())
3. Nombre de lettres majuscules
Compter le nombre de caractères majuscules présents dans un tweet.
def count_capital_chars(texte):
compte=0
pour moi dans le texte:
si je.isupper():
compte+=1
nombre de retours
4. Nombre de mots majuscules
Compter le nombre de mots majuscules présents dans un tweet.
def count_capital_words(texte):
somme de retour(carte(str.isupper,text.split()))
5. Compter le nombre de scores
Dans cette fonction, nous retournons un dictionnaire de 32 signes de ponctuation avec des chiffres, qui peuvent être utilisés en tant que fonctionnalités autonomes, dont je parlerai dans la section suivante.
def count_ponctuations(texte):
ponctuations="!"#$%&"()*+,-./:;<=>[email protégé][]^_`{|}~'
d=dict()
pour i dans les ponctuations:
ré[str(je)+' compter']=texte.compte(je)
retour d
6. Nombre de mots entre guillemets
Le nombre de mots entre guillemets simples et guillemets doubles.
def count_words_in_quotes(texte):
x = re.trouver("'.'|"."", texte)
compte=0
si x est Aucun:
revenir 0
autre:
pour i dans x:
t=je[1:-1]
count+=count_mots
nombre de retours
7. Nombre de phrases
Compter le nombre de phrases dans un tweet.
def count_sent(texte):
retour len(nltk.sent_tokenize(texte))
8. Compter le nombre de mots uniques.
Compter le nombre de mots uniques dans un tweet.
def count_unique_words(texte):
retour len(ensemble(text.split()))
9. Nombre de hashtags
Puisque nous utilisons l'ensemble de données Twitter, nous pouvons compter le nombre de fois que les utilisateurs ont utilisé le hashtag.
def count_htags(texte):
x = re.trouver(r'(#w[A-Za-z0-9]*)', texte)
retour len(X)
10. Nombre de mentions
Et Twitter, la plupart du temps, les gens répondent ou mentionnent quelqu'un dans leur tweet, compter le nombre de mentions peut aussi être traité comme une caractéristique.
def count_mentions(texte):
x = re.trouver(r'(@w[A-Za-z0-9]*)', texte)
retour len(X)
11. Nombre de mots vides
Ici, nous allons compter le nombre de mots vides utilisés dans un tweet.
def count_stopwords(texte):
stop_words = définir(mots.mots.mots('Anglais'))
word_tokens = word_tokenize(texte)
mots vides_x = [w pour w dans word_tokens si w dans stop_words]
retour len(mots vides_x)
12. Calculer la longueur moyenne des mots
Cela peut être calculé en divisant le nombre de caractères par le nombre de mots.
df['moy_wordlength'] = df['char_count']/df['word_count']
13. Calcul de la durée moyenne des peines
Cela peut être calculé en divisant le nombre de mots par le nombre de phrases.
df['moy_sentlength'] = df['word_count']/df['sent_count']
14. mots uniques vs fonction de comptage de mots
Cette caractéristique est essentiellement le rapport entre les mots uniques et le nombre total de mots.
df['unique_vs_words'] = df['unique_word_count']/df['word_count']
15. Arrêter le nombre de mots par rapport à la fonction de nombre de mots
Cette caractéristique est aussi le rapport entre le nombre de mots vides et le nombre total de mots.
df['stopwords_vs_words'] = df['stopword_count']/df['word_count']
Mise en œuvre
Vous pouvez télécharger l'ensemble de données à partir de ici. Après téléchargement, nous pouvons commencer à implémenter toutes les fonctions que nous avons définies ci-dessus. Nous nous concentrerons davantage sur l'ingénierie des fonctions, pour cela, nous garderons l'approche simple, en utilisant TF-IDF et un prétraitement simple. Tout le code sera disponible dans mon dépôt GitHub https://github.com/ahmadkhan242/Feature-Engineering-in-NLP.
-
Lecture de train, validation et suite de tests avec les pandas.
train = pd.read_csv("train.csv") val = pd.read_csv("validation.csv") test = pd.read_csv(testAvecLabel.csv") # Pour cette tâche, nous combinerons l'ensemble de données d'entraînement et de validation, puis utiliserons # test de train simple séparé de sklern. df = pd.concat([former, val]) df.head()
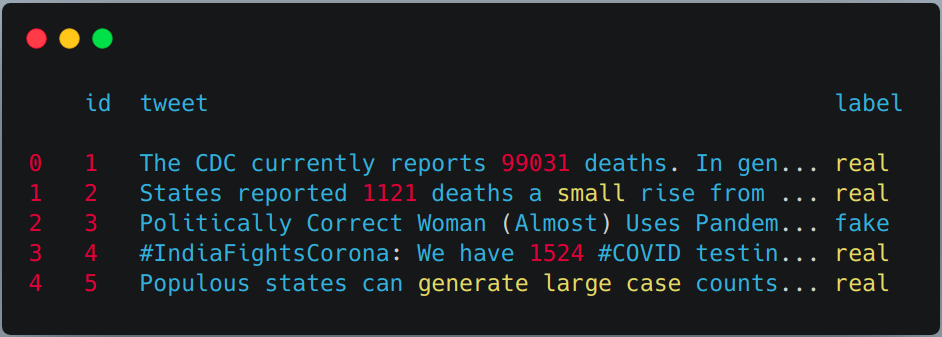
-
Appliquer l'extraction de caractéristiques précédemment définie sur le train et l'ensemble de test.
df['char_count'] = df["tweeter"].appliquer(lambda x:count_chars(X)) df['word_count'] = df["tweeter"].appliquer(lambda x:count_words(X)) df['sent_count'] = df["tweeter"].appliquer(lambda x:count_sent(X)) df['capital_char_count'] = df["tweeter"].appliquer(lambda x:count_capital_chars(X)) df['capital_word_count'] = df["tweeter"].appliquer(lambda x:count_capital_words(X)) df['quoted_word_count'] = df["tweeter"].appliquer(lambda x:count_words_in_quotes(X)) df['stopword_count'] = df["tweeter"].appliquer(lambda x:count_stopwords(X)) df['unique_word_count'] = df["tweeter"].appliquer(lambda x:count_unique_words(X)) df['htag_count'] = df["tweeter"].appliquer(lambda x:count_htags(X)) df['mention_compte'] = df["tweeter"].appliquer(lambda x:count_mentions(X)) df['punct_count'] = df["tweeter"].appliquer(lambda x:count_ponctuations(X)) df['moy_wordlength'] = df['char_count']/df['word_count'] df['moy_sentlength'] = df['word_count']/df['sent_count'] df['unique_vs_words'] = df['unique_word_count']/df['word_count'] df['stopwords_vs_words'] = df['stopword_count']/df['word_count'] # DE MÊME, VOUS POUVEZ LES APPLIQUER SUR L'ENSEMBLE DE TEST
-
ajouter quelques fonctionnalités supplémentaires en utilisant le nombre de points
Nous allons créer un DataFrame à partir du dictionnaire renvoyé par la fonction "punct_count" puis nous le fusionnerons avec le jeu de données principal.
df_punct = pd.DataFrame(liste(df.punct_count)) test_punct = pd.DataFrame(liste(test.punct_count)) # Fusionner le DataFrame de pnctuation avec le DataFrame principal df = pd.merge(df, df_ponct, left_index=Vrai, right_index=Vrai) test = pd.merge(test, test_ponct,left_index=Vrai, right_index=Vrai)
# Nous pouvons laisser tomber "punt_count" colonne de df et test DataFrame df.drop(colonnes=['punct_count'],inplace=Vrai) test.drop(colonnes=['punct_count'],inplace=Vrai) df.colonnes
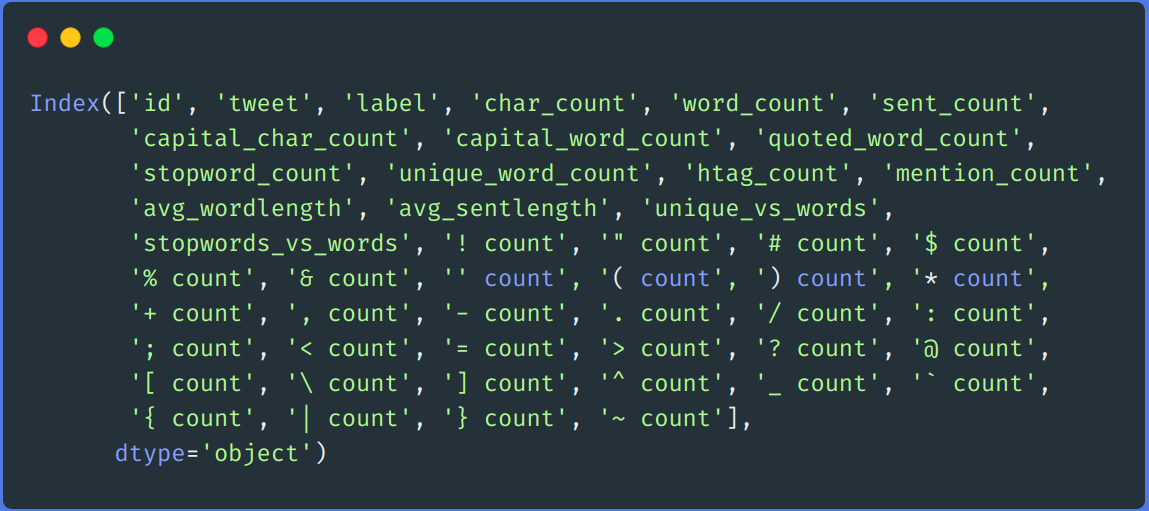
-
retraitement
Nous effectuons une étape simple avant le traitement, comment supprimer des liens, supprimer le nom d'utilisateur, nombres, double espace, ponctuation, minuscule, etc.
def remove_links(tweeter): '''Prend une chaîne et en supprime les liens Web''' tweet = re.sub(r'httpS+', '', tweeter) # supprimer les liens http tweet = re.sub(r'bit.ly/S+', '', tweeter) # rempve bitly liens tweet = tweet.bande('https://www.analyticsvidhya.com/blog/2021/04/a-guide-to-feature-engineering-in-nlp/ ') # supprimer [liens] retour tweet def remove_users(tweeter): '''Prend une chaîne et supprime le retweet et les informations @user''' tweet = re.sub('([email protégé][A-Za-z]+[A-Za-z0-9-_]+)', '', tweeter) # supprimer les retweets tweet = re.sub('(@[A-Za-z]+[A-Za-z0-9-_]+)', '', tweeter) # supprimer tweeté à retour tweet ma_ponctuation = '!"$%&'()*+,-./:;<=>?[]^_`{|}~•@' def prétraitement(envoyé): envoyé = remove_users(envoyé) envoyé = remove_links(envoyé) envoyé = envoyé.inférieur() # minuscule envoyé = re.sub('['+ma_ponctuation + ']+', ' ', envoyé) # bande de ponctuation envoyé = re.sub('s+', ' ', envoyé) #supprimer le double interligne envoyé = re.sub('([0-9]+)', '', envoyé) # supprimer des numéros sent_token_list = [mot pour mot dans sent.split(' ')] envoyé=" ".rejoindre(liste_sent_token) retour envoyé df['tweeter'] = df['tweeter'].appliquer(lambda x: prétraiter(X)) test['tweeter'] = tester['tweeter'].appliquer(lambda x: prétraiter(X))
-
Encodage de texte
Nous encoderons nos données textuelles en utilisant TF-IDF. Nous adaptons d'abord la transformation à notre colonne de tweets de train et à notre ensemble de tests, puis nous les fusionnons avec toutes les colonnes de fonctionnalités..
vectoriseur = TfidfVectorizer() train_tf_idf_features = vectorizer.fit_transform(df['tweeter']).faire un tableau() test_tf_idf_features = vectorizer.transform(test['tweeter']).faire un tableau() # Conversion de la liste ci-dessus en DataFrame train_tf_idf = pd.DataFrame(train_tf_idf_features) test_tf_idf = pd.DataFrame(test_tf_idf_features) # Séparer les étiquettes de train et de test de toutes les fonctionnalités train_Y = df['étiqueter'] test_Y = test['étiqueter'] #Liste de toutes les fonctionnalités caractéristiques = ['char_count', 'word_count', 'sent_count', 'capital_char_count', 'capital_word_count', 'quoted_word_count', 'stopword_count', 'unique_word_count', 'htag_count', 'mention_compte', 'moy_wordlength', 'moy_sentlength', 'unique_vs_words', 'stopwords_vs_words', '! compter', '" compter', '# compter', '$ compte', '% compter', '& compter', '' compter', '( compter', ') compter', '* compter', '+ compter', ', compter', '- compter', '. compter', '/ compter', ': compter', '; compter', '< compter', '= compter', '> compter', '? compter', '@ compter', '[ compter', ' compter', '] compter', '^ compter', '_ compter', « compter », '{ compter', '| compter', '} compter', '~ compter'] # Enfin fusionner toutes les fonctionnalités avec TF-IDF ci-dessus. train = pd.merge(train_tf_idf,df[caractéristiques],left_index=Vrai, right_index=Vrai) test = pd.merge(test_tf_idf,test[caractéristiques],left_index=Vrai, right_index=Vrai) -
Entraînement
Pour s'entraîner, nous utiliserons l'algorithme de forêt aléatoire de la bibliothèque d'apprentissage sci-kit.
X_train, X_test, y_train, y_test = train_test_split(former, train_Y, taille_test=0.2, état_aléatoire = 42) # Classificateur de forêt aléatoire clf_model = RandomForestClassifier(n_estimateurs = 1000, min_samples_split = 15, état_aléatoire = 42) modèle_clf.ajuster(X_train, y_train) _RandomForestClassifier_prediction = clf_model.predict(X_test) val_RandomForestClassifier_prediction = clf_model.predict(test)
Comparaison des résultats
En comparaison, nous formons d'abord notre modèle sur l'ensemble de données ci-dessus en utilisant des techniques d'ingénierie de caractéristiques, puis sans utiliser de techniques d'ingénierie de caractéristiques. Dans les deux approches, nous avons prétraité l'ensemble de données en utilisant la même méthode que celle décrite ci-dessus et TF-IDF a été utilisé dans les deux approches pour coder les données textuelles. Vous pouvez utiliser n'importe quelle technique d'encodage que vous voulez, comme word2vec, gant, etc.
1. Sans utiliser les techniques d'ingénierie des fonctions
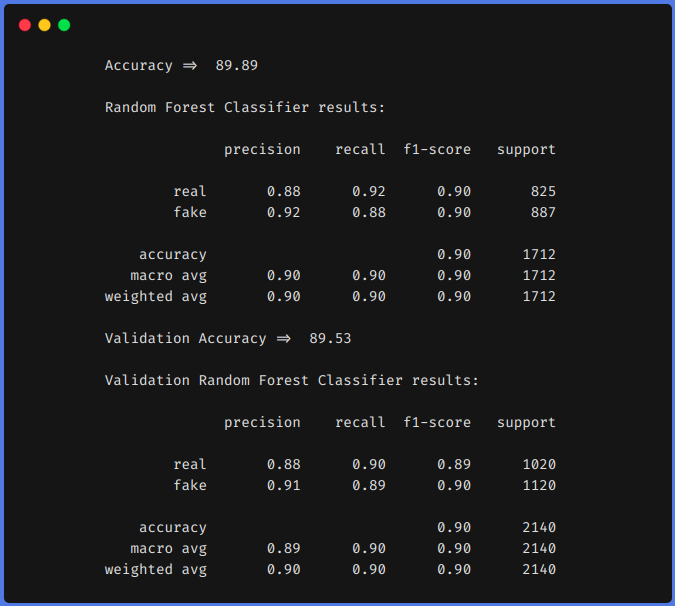
2. Utilisation des techniques d'ingénierie des fonctions
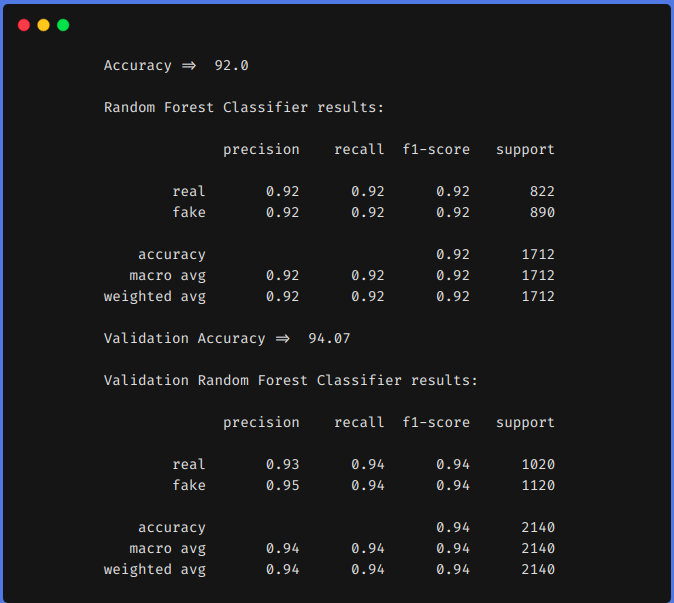
D'après les résultats précédents, nous pouvons voir que les techniques d'ingénierie des fonctionnalités nous ont aidés à augmenter notre f1 de 0,90 jusqu'à 0,92 dans le train et de 0,90 jusqu'à 0,94 dans l'équipe de test.
conclusion
Les résultats ci-dessus montrent que si nous effectuons une ingénierie de fonction, nous pouvons atteindre une plus grande précision en utilisant des algorithmes d'apprentissage automatique classiques. L'utilisation d'un modèle basé sur un transformateur est un algorithme long et gourmand en ressources. Si nous faisons de l'ingénierie fonctionnelle de la bonne manière, c'est-à-dire, après avoir analysé notre jeu de données, nous pouvons obtenir des résultats comparables.
Nous pouvons également faire d'autres fonctionnalités d'ingénierie, comment compter le nombre d'emojis utilisés, le type d'émojis utilisé, quelles fréquences de mots uniques, etc. Nous pouvons définir nos caractéristiques en analysant l'ensemble de données. J'espère que vous avez appris quelque chose de ce blog, le partager avec d'autres. Consultez mon blog personnel sur l'apprentissage automatique (https://code-ml.com/) pour obtenir du contenu nouveau et passionnant dans différents domaines du ML et de l'IA.
A propos de l'auteur
Mohamed Ahmad (B.Tech) LinkedIn - https://www.linkedin.com/in/mohammad-ahmad-ai/ Blogue personnel - https://code-ml.com/ GitHub - https://github.com/ahmadkhan242 Twitter - https://twitter.com/ahmadkhan_242
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





