introduction
Apprentissage par renforcement, a l'air intriguant, vérité? Ici, dans cet article, nous verrons ce que c'est et pourquoi il y a tant de discussions ces jours-ci. Cela agit comme un guide d'apprentissage par renforcement pour les débutants.. L'apprentissage par renforcement est certainement l'un des domaines de recherche évidents aujourd'hui qui a un bon boom pour émerger dans un proche avenir et sa popularité augmente de jour en jour.. Allons-y.
Fondamentalement, c'est le concept dans lequel les machines peuvent s'auto-apprendre en fonction des résultats de leurs propres actions.. Sans plus tarder, commençons.
Qu'est-ce que l'apprentissage par renforcement?
L'apprentissage par renforcement fait partie de l'apprentissage automatique. Ici, les agents se forment sur les mécanismes de récompense et de punition. Il s'agit de prendre la meilleure action ou chemin possible pour obtenir le maximum de récompenses et le minimum de punition grâce à des observations dans une situation spécifique.. Il agit comme un signal de comportements positifs et négatifs. Essentiellement, un agent est construit (ou plusieurs) qui peut percevoir et interpréter l'environnement dans lequel il se trouve, en outre, peut prendre des mesures et interagir avec lui.
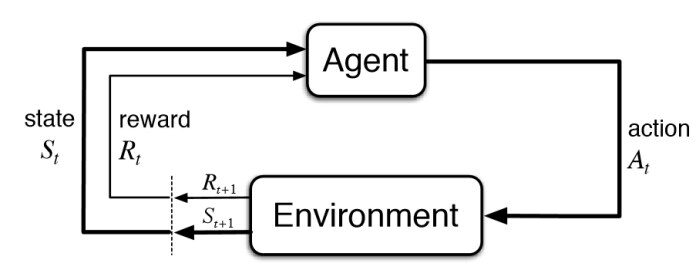
Diagramme d'apprentissage de renforcement de base – KDNuggets
Connaître le sens de l'apprentissage par renforcement, passons en revue la définition formelle.
Apprentissage renforcé, un type d'apprentissage automatique, dans lequel les agents agissent dans un environnement visant à maximiser leurs récompenses cumulatives – NVIDIA
Apprentissage par renforcement (RL) est basé sur la récompense des comportements souhaités ou la punition des comportements indésirables. Au lieu d'une entrée produisant une sortie, l'algorithme produit une variété de sorties et est capable de sélectionner la bonne en fonction de certaines variables: Gartner
Il s'agit d'un type de technique d'apprentissage automatique dans laquelle un agent informatique apprend à effectuer une tâche par le biais d'interactions répétées d'essais et d'erreurs avec un environnement dynamique.. Cette approche d'apprentissage permet à l'agent de prendre une série de décisions qui maximisent une métrique de récompense pour la tâche sans intervention humaine et sans être explicitement programmé pour accomplir la tâche.: Travaux de mathématiques
Cependant, les définitions ci-dessus sont techniquement fournies par des experts dans ce domaine pour quelqu'un qui débute avec l'apprentissage par renforcement, mais ces définitions peuvent sembler un peu difficiles. Comment ceci est un guide d'apprentissage par renforcement pour les débutants, facilitons notre définition de l'apprentissage par renforcement.
Définition simplifiée de l'apprentissage par renforcement
Grâce à une série de méthodes d'essais et d'erreurs, un agent continue d'apprendre continuellement dans un environnement interactif à partir de ses propres actions et expériences. Le seul objectif est de trouver un modèle d'action approprié qui augmente la récompense cumulative totale de l'agent.. Apprendre par l'interaction et la rétroaction.
Bon, c'est la définition de l'apprentissage par renforcement. À présent, comment est-on arrivé à cette définition, comment une machine apprend et comment elle peut résoudre des problèmes complexes dans le monde grâce à l'apprentissage par renforcement, c'est quelque chose que nous verrons plus en profondeur.
L'apprentissage par renforcement expliqué
Comment fonctionne l'apprentissage par renforcement? Bon, laisse moi t'expliquer avec un exemple.
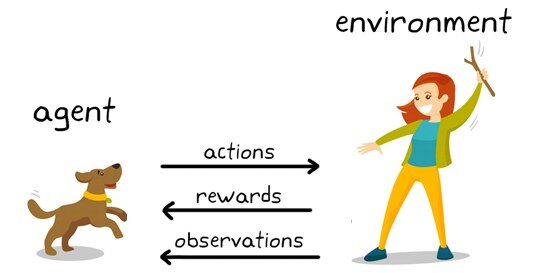
Exemple d'apprentissage par renforcement: KDNuggets
Ici, que voyez-vous?
Vous pouvez voir un chien et un maître. Imaginons que vous entraînez votre chien à ramasser le bâton. Chaque fois que le chien réussit à obtenir un bâton, tu lui offre un festin (un os, Disons). Éventuellement, le chien comprend le modèle, qu'à chaque fois que le professeur lance un bâton, vous devez l'obtenir dès que possible pour obtenir une récompense (un os) d'un enseignant en moins de temps.
Terminologies utilisées dans l'apprentissage par renforcement
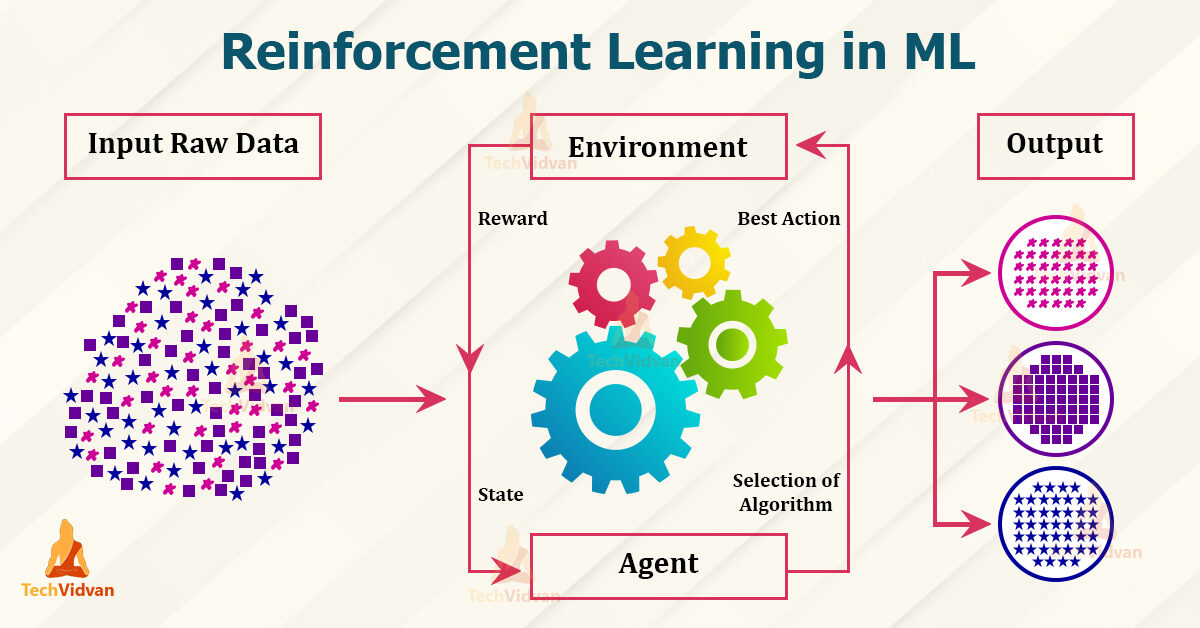
Terminologies en RL – Techvidvan
Agent – il est le seul qui prend les décisions et apprend
Environnement – un monde physique où un agent apprend et décide des actions à entreprendre
action – une liste d'actions qu'un agent peut effectuer
État – la situation actuelle de l'agent dans l'environnement
Récompense – Pour chaque action sélectionnée par l'agent, l'environnement récompense. Comme d'habitude, c'est une valeur scalaire et rien de plus que des commentaires d'environnement.
Politique – l'agent prépare la stratégie (prise de décisions) assigner des situations à des actions.
Fonction de valeur – La valeur de l'état montre la récompense obtenue de l'état jusqu'à ce que la politique soit exécutée.
Modèle – Chaque agent RL n'utilise pas de modèle de son environnement. La vue agent mappe les distributions de probabilité des paires état-action sur les états
Workflow d'apprentissage par renforcement
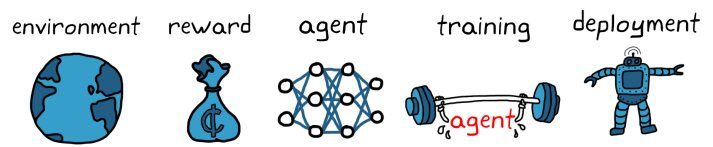
Workflow d'apprentissage renforcé – KDNuggets
– Créer l'environnement
– Définir la récompense
– Créer l'agent
– Former et valider l'agent
– Mettre en œuvre la politique
En quoi l'apprentissage par renforcement est-il différent de l'apprentissage supervisé?
En apprentissage supervisé, le modèle est entraîné avec un ensemble de données d'entraînement qui a une clé de réponse correcte. La décision est prise sur la base de l'entrée initiale donnée, car il dispose de toutes les données nécessaires pour entraîner la machine. Les décisions sont indépendantes les unes des autres, donc chaque décision est représentée par une étiquette. Exemple: reconnaissance d'objet
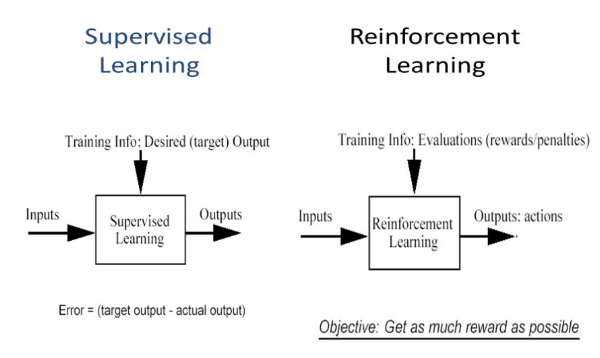
Différence entre apprentissage supervisé et apprentissage renforcé – étude pure
En apprentissage par renforcement, il n'y a pas de réponse et l'agent de sauvegarde décide quoi faire pour effectuer la tâche requise. Comme l'ensemble de données d'entraînement n'est pas disponible, l'agent a dû apprendre de son expérience. Il s'agit de collecter les décisions de manière séquentielle. Pour le dire plus simplement, la sortie est basée sur l'état actuel de l'entrée et l'entrée suivante est basée sur la sortie de l'entrée précédente. Nous étiquetons la séquence de décisions dépendantes. Les décisions dépendent. Exemple: jeu d'échecs
Caractéristiques d'apprentissage par renforcement
– Non supervisé, juste une valeur réelle ou un signal de récompense
– La prise de décision est séquentielle
– Le temps joue un rôle important dans les problèmes de renforcement.
– La rétroaction n'est pas rapide mais retardée
– Les données suivantes que vous recevez sont déterminées par les actions de l'agent
Algorithmes d'apprentissage par renforcement
Il y a 3 approches pour mettre en œuvre des algorithmes d'apprentissage par renforcement
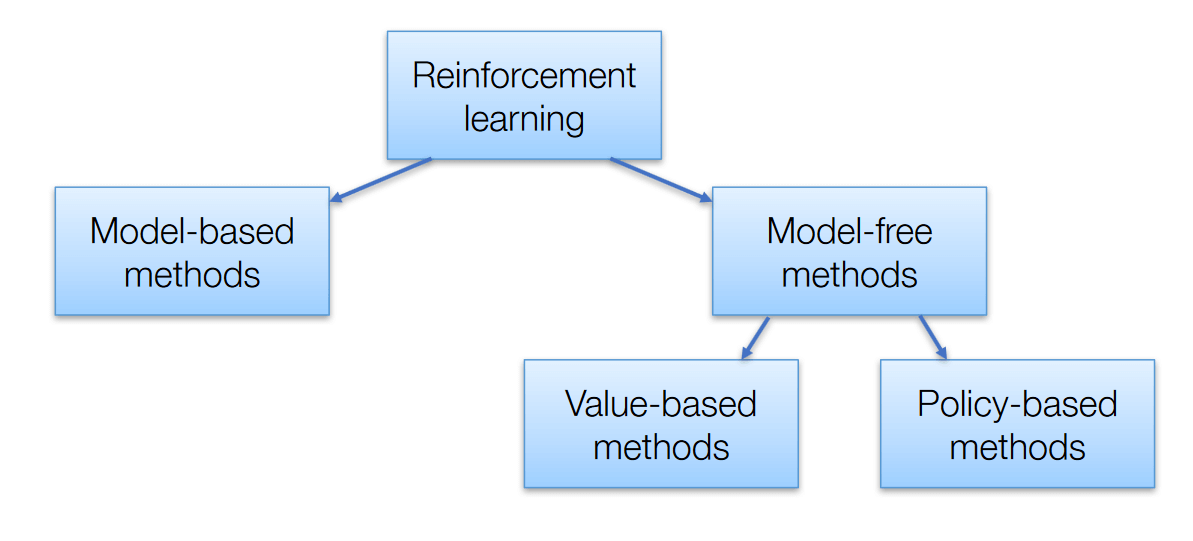
Algorithmes d'apprentissage par renforcement – AISété
Basé sur la valeur – L'objectif principal de cette méthode est de maximiser une fonction de valeur. Ici, un agent par le biais d'une politique s'attend à un retour à long terme des états actuels.
Basé sur des politiques – Dans les politiques basées sur des politiques, vous permet de concevoir une stratégie qui aide à obtenir le maximum de récompenses à l'avenir grâce aux actions possibles menées dans chaque état. Deux types de méthodes basées sur les politiques sont déterministes et stochastiques.
Basé sur des modèles – Dans cette méthode, nous devons créer un modèle virtuel pour l'agent afin de l'aider à apprendre à fonctionner dans chaque environnement spécifique.
Types d'apprentissage par renforcement
Il y a deux sortes :
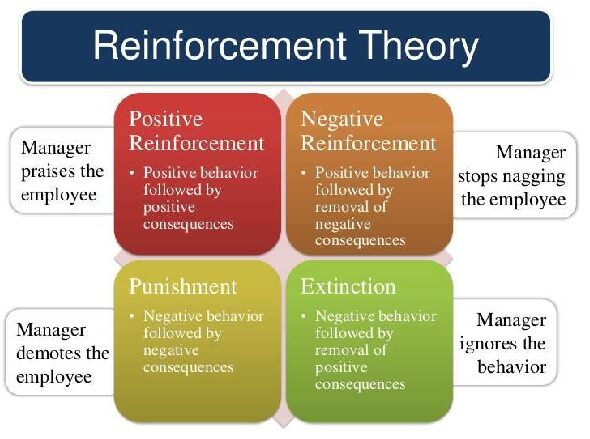
Exemple de théorie de renforcement – Tutorielspoint
1. Renforcement positif
Le renforcement positif est défini comme lorsqu'un événement, en raison d'un comportement particulier, augmente la force et la fréquence du comportement. A un impact positif sur le comportement.
avantage
– Maximiser la performance d'un stock.
– Conservez la monnaie plus longtemps
Désavantage
– Un renforcement excessif peut conduire à une surcharge d'état qui minimiserait les résultats.
2. Renforcement négatif
Le renforcement négatif est représenté comme le renforcement d'un comportement. D'autres manières, lorsqu'une condition négative est interdite ou évitée, essayez d'arrêter cette action à l'avenir.
avantage
– Comportement maximisé
– Fournir un niveau de performance décent au minimum
Désavantage
– Il est simplement assez limité pour répondre à un comportement minimal.
Modèles largement utilisés pour l'apprentissage par renforcement.
1. Processus de décision de Markov (MDP) – sont des cadres mathématiques pour cartographier des solutions dans RL. L'ensemble de paramètres qui comprend Ensemble d'états finis – S, Ensemble d'actions possibles dans chaque état – UNE, Récompense – R, Modèle – T, Politique – Pi. Le résultat de la mise en œuvre d'une action dans un état ne dépend pas des actions ou états précédents, mais de l'action et de l'état en cours.
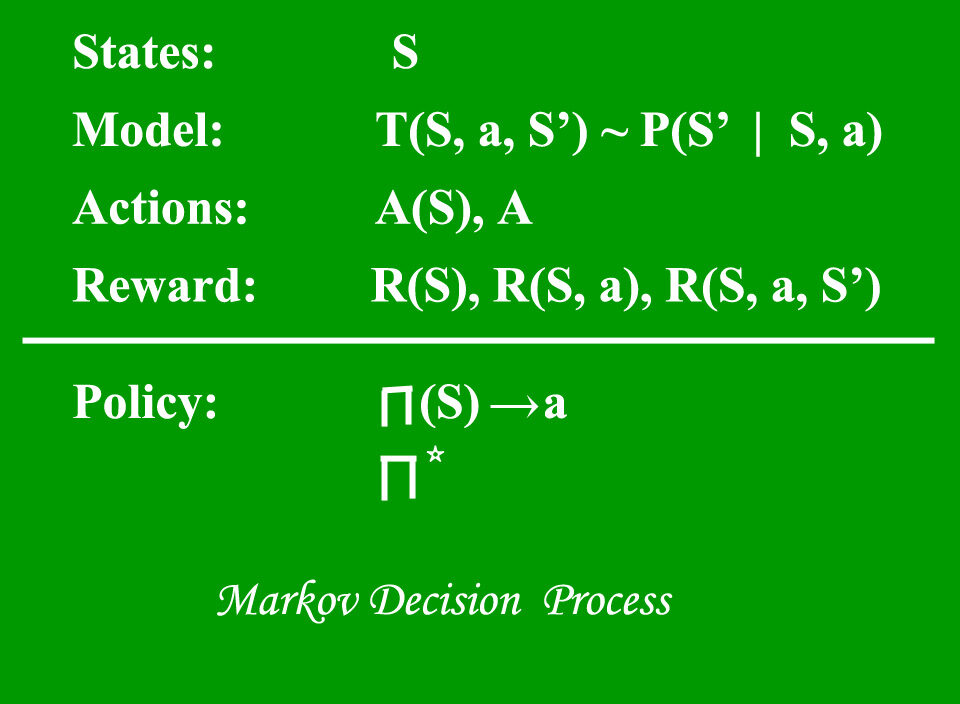
Processus de décision de Markov – Geeks4geeks
2. Q apprentissage – Il s'agit d'une approche sans modèle basée sur la valeur pour fournir des informations pour indiquer quelle action un agent doit entreprendre. Il s'articule autour de la notion de mise à jour des valeurs de Q montrant la valeur d'effectuer l'action A dans l'état S. La règle de mise à jour des valeurs est l'aspect principal de l'algorithme Q-learning.
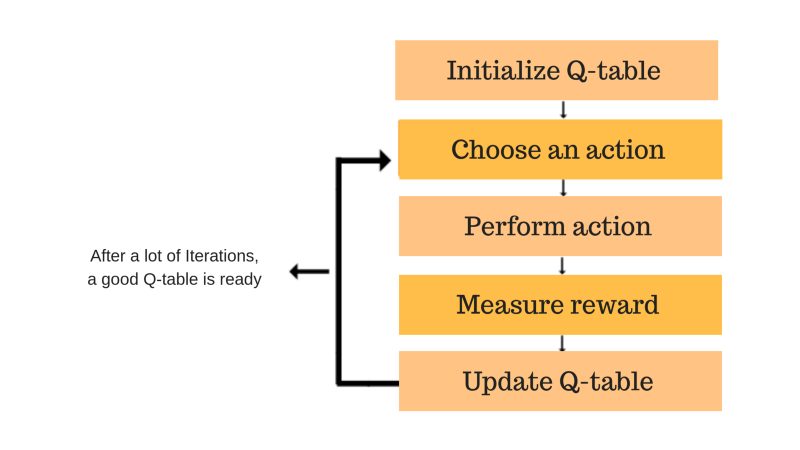
QApprentissage – Freecodecamp
Applications pratiques de l'apprentissage par renforcement
– Robotique pour l'automatisation industrielle
– Moteurs de synthèse de texte, agents de dialogue (texte, voix), Jeux
– Voitures autonomes autonomes
– Apprentissage automatique et traitement des données
– Système de formation qui émettrait des instructions et du matériel personnalisés concernant les exigences des étudiants.
– Boîtes à outils d'IA, fabrication, automobile, assainissement et bots
– Contrôle d'avion et contrôle de mouvement de robot
– Construire l'intelligence artificielle pour les jeux informatiques.
conclusion
La conclusion de ce sujet est simplement de nous aider à découvrir quelle action pourrait produire le plus de récompenses le plus longtemps.. Les environnements réalistes peuvent avoir une observabilité partielle et être également non stationnaires. Il n'est pas très utile de postuler quand on a suffisamment de données pratiques pour résoudre le problème grâce à un apprentissage supervisé. Le principal défi de cette méthode est que les paramètres peuvent affecter la vitesse d'apprentissage.
J'espère que vous connaissez et comprenez maintenant un certain niveau de la description de l'apprentissage par renforcement. Merci pour ton temps.
Sur moi
Soja Prathima Kadari, un ancien ingénieur intégré travaillant pour exploiter mes connaissances et améliorer mes compétences.
S'il vous plait, n'hésitez pas à me contacter sur https://www.linkedin.com/in/prathima-kadari
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





