Cet article a été publié dans le cadre du Blogathon sur la science des données.
Vue d'ensemble
devenu, vérité? Nous regroupons les points de données en 3 groupes en fonction de leur similitude ou de leur proximité.
Table des matières
1.Introduction à K signifie
2.K signifie ++ algorithme
3.Comment choisir la valeur K dans K signifie?
4.Considérations pratiques en moyenne K
5.Tendance des clusters
1. introduction
Comprenons simplement le regroupement des K-means avec des exemples de la vie quotidienne. nous savons que de nos jours, tout le monde aime regarder des séries Web ou des films sur Amazon Prime, Netflix. Avez-vous déjà observé quelque chose à chaque fois que vous ouvrez Netflix? c'est-à-dire, films de groupe en fonction de leur genre, c'est-à-dire, la criminalité, suspendu, etc., J'espère que vous l'avez observé ou que vous le connaissez déjà. le regroupement par genre Netflix est donc un exemple de regroupement facile à comprendre. comprenons plus sur k signifie algorithme de clustering.
Définition: Regrouper les points de données en fonction de leur similitude ou de leur proximité les uns avec les autres, en termes simples, l'algorithme doit trouver les points de données dont les valeurs sont similaires les unes aux autres et, donc, ces points appartiendraient au même groupe.
Ensuite, Comment l'algorithme trouve-t-il les valeurs entre deux points pour les regrouper? L'algorithme trouve les valeurs en utilisant la méthode 'Mesure de distance'. ici, la mesure de distance est « distance euclidienne’
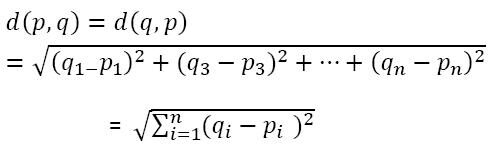
Les observations les plus proches ou similaires les unes aux autres auraient une faible distance euclidienne et seraient ensuite regroupées.
une autre formule que vous devez connaître pour comprendre les moyens de K est « Centroid ». L'algorithme k-means utilise le concept de centroïde pour créer des « groupes k ».
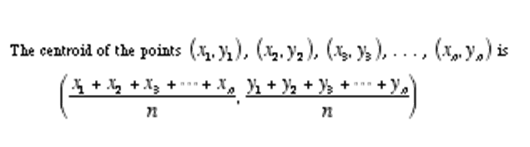
Alors maintenant, vous êtes prêt à comprendre les étapes de l'algorithme de clustering k-means.
Étapes dans K-means:
paso 1: choisissez la valeur k pour ex: k = 2
paso 2: initialiser au hasard les centroïdes
Paso 3: calculer la distance euclidienne des centroïdes à chaque point de données et former des groupes proches des centroïdes
paso 4: trouver le centroïde de chaque groupe et mettre à jour les centroïdes
paso: 5 répéter l'étape 3
Chaque fois que des groupes sont constitués, mise à jour des centroïdes, le centre de gravité mis à jour est le centre de tous les points qui tombent dans le groupe. Ce processus se poursuit jusqu'à ce que le centroïde ne change plus., c'est-à-dire, la solution converge.
Vous pouvez jouer avec l'algorithme K-means en utilisant le lien ci-dessous, essayez-le.
https://stanford.edu/class/engr108/visualizations/kmeans/kmeans.html
Ensuite, suivant? Comment choisissez-vous les centroïdes initiaux au hasard?
Voici le concept de l'algorithme k-Means ++.
2. Algoritmo K-Means ++:
Je ne vais pas te stresser pour ça, alors ne t'inquiète pas. C'est très facile à comprendre. Ensuite, Qu'est-ce que k-signifie ++ ??? Disons que nous voulons choisir deux centroïdes initialement (k = 2), vous pouvez choisir un centroïde au hasard ou vous pouvez choisir l'un des points de données au hasard. Simple vérité? Notre prochaine tâche consiste à choisir un autre centroïde, Comment le choisissez-vous? une idée?
Nous choisissons le prochain centroïde des points de données qui est à une grande distance du centroïde existant ou celui qui est à une grande distance d'un groupe existant qui a une forte probabilité de capture.
3.Comment choisir la valeur K dans les K-moyennes:
1.Méthode du coude
Pas:
Paso 1: calculer l'algorithme de clustering pour différentes valeurs de k.
par exemple k =[1,2,3,4,5,6,7,8,9,10]
paso 2: pour chaque k, calculer la somme des carrés dans le cluster (WCSS).
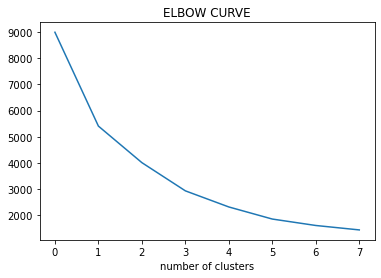
Paso 3: tracer la courbe WCSS en fonction du nombre de clusters.
Paso 4: L'emplacement de la courbe sur la parcelle est généralement considéré comme un indicateur du nombre approximatif de grappes.
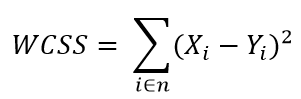
Considérations pratiques sur les K-means:
- Un certain nombre de clusters choisis à l'avance (K).
- Normalisation des données (escaladé).
- Données catégorielles (peut être résolu avec le mode K).
- Impact des centroïdes et des valeurs aberrantes initiales.
5. Tendance des clusters:
Avant d'appliquer un algorithme de clustering aux données données, il est important de vérifier si les données fournies ont des clusters significatifs ou non. Le processus d'évaluation des données pour vérifier si les données sont réalisables pour le regroupement ou non est connu sous le nom de « tendance de regroupement »., il ne faut donc pas appliquer aveuglément la méthode de regroupement et vérifier la tendance de regroupement. Comment?
Nous utilisons la « statistique Hopkins’ pour savoir s'il faut effectuer le clustering ou non pour un jeu de données donné. Examiner si les points de données diffèrent de manière significative des données uniformément réparties dans l'espace multidimensionnel.
Ceci conclut notre article sur l'algorithme de clustering k-means.. Dans mon prochain article, Je parlerai de l'implémentation Python de l'algorithme de clustering K-means.
Merci!
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





