Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
¡Bien! Nous aimons tous les gâteaux. Si vous regardez de plus près le processus de cuisson, vous remarquerez comment la bonne combinaison des différents ingrédients et un agent de levure intelligent, levure chimique, vous pouvez décider de la montée et de la chute de votre gâteau.
“Cuire le gâteau” peut sembler déplacé dans le livre blanc, mais je pense que c'est assez relatable et une analogie délicieuse pour comprendre l'importance de l'EDA dans le processus de science des données.
Quand faire cuire le gâteau est pour le pipeline de science des données, Entonces Agent levant intelligent (levure chimique) est pour l'analyse exploratoire des données.
Avant que ta bouche ne salisse pour un gâteau comme le mien, comprenons.
Qu'est-ce exactement que l'analyse de données exploratoire?
L'analyse exploratoire des données est une approche de l'analyse des données qui utilise une variété de techniques pour:
- Obtenez un aperçu des données.
- Faire des contrôles de santé. (Pour être sûr que les informations que nous extrayons proviennent réellement du bon ensemble de données).
- Découvrez où les données sont manquantes.
- Vérifier les valeurs aberrantes.
- Résumer les données.
Prenez la célèbre étude de cas de “VENTES DU VENDREDI NOIR” pour comprendre, Pourquoi avons-nous besoin d'EDA?

Le problème central est de comprendre le comportement du client en prédisant le montant de l'achat. Mais, N'est-ce pas trop abstrait et vous laisse perplexe quant à ce qu'il faut faire avec les données, surtout quand vous avez tellement de produits différents avec différentes catégories?
Avant de continuer la lecture, réfléchissez un peu à cette question: Souhaitez-vous mettre tous les ingrédients disponibles dans la cuisine tels quels dans le four pour cuire le gâteau?
Évidemment, La réponse est non! Avant de prendre l'ensemble de données complet car il est en considération de le cuire dans le modèle d'apprentissage automatique, voudra
- Extraire des informations importantes
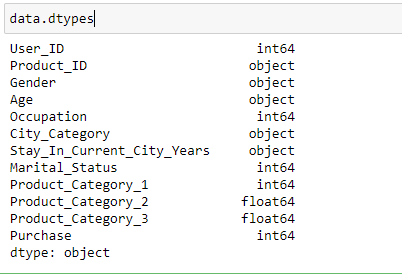
- Identification des variables (si les données contiennent des variables catégorielles ou numériques ou une combinaison des deux).
- Le comportement des variables (si les variables ont des valeurs de 0 une 10 ou de 0 une 1 million).
- Relation entre les variables (comment les variables dépendent les unes des autres).
-
Vérifier la cohérence des données
- Pour s'assurer que toutes les données sont présentes. (Si nous avons collecté des données pendant trois ans, les semaines manquantes peuvent être un problème dans les étapes ultérieures).
- Y a-t-il une valeur manquante présente?
- Y a-t-il des valeurs aberrantes dans l'ensemble de données? (par exemple: une personne avec 2000 ans est certainement une anomalie)
- Ingénierie fonctionnelle
- Ingénierie des fonctionnalités (pour créer de nouvelles entités à partir d'entités brutes existantes dans le jeu de données).
** AED, en substance, peut casser ou faire n'importe quel modèle d'apprentissage automatique. **
Étapes de l'analyse exploratoire des données

Il y a 5 étapes de l'EDA: ->
- Identification des variables: Dans cette étape, on identifie chaque variable en découvrant son type. Selon nos besoins, nous pouvons changer le type de données de n'importe quelle variable.

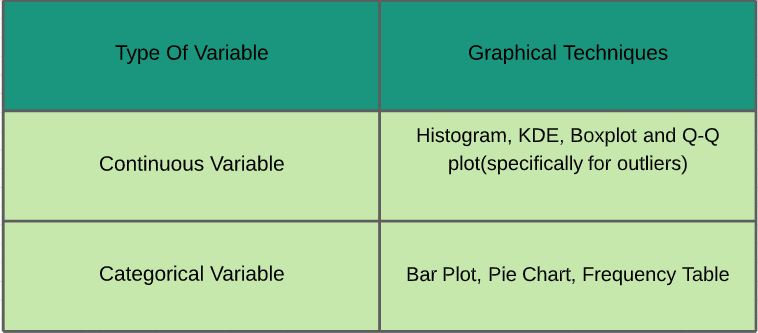
~ Les statistiques jouent un rôle important dans l'analyse des données. C'est un ensemble de règles et de concepts pour l'analyse et l'interprétation des données. Il existe différents types d'analyses à effectuer en fonction des besoins. ~ Étudions-les - Analyse univariée: En analyse univariée, nous étudions les caractéristiques individuelles de chaque caractéristique / variable disponible dans le jeu de données. Il existe deux types de fonctions: continu et catégorique. Dans l'image ci-dessous, J'ai donné une aide-mémoire de diverses techniques graphiques qui peuvent être appliquées pour les analyser.

Variable continue:
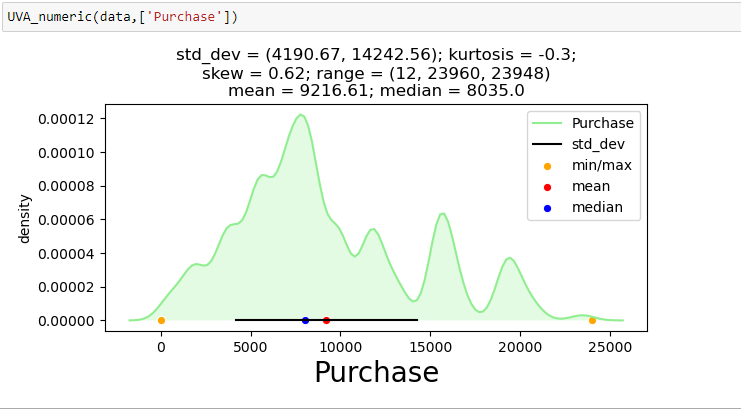
Pour afficher une analyse univariée sur l'une des variables continues de l'ensemble de données de vente du Black Friday: “Acheter”, J'ai créé une fonction qui prend des données en entrée et dessine un graphique KDE qui explique les caractéristiques de la fonction.


Variable catégorielle
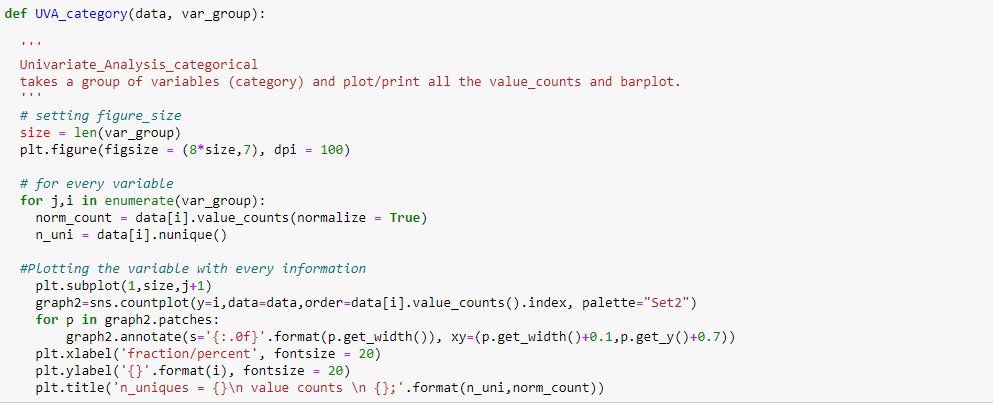
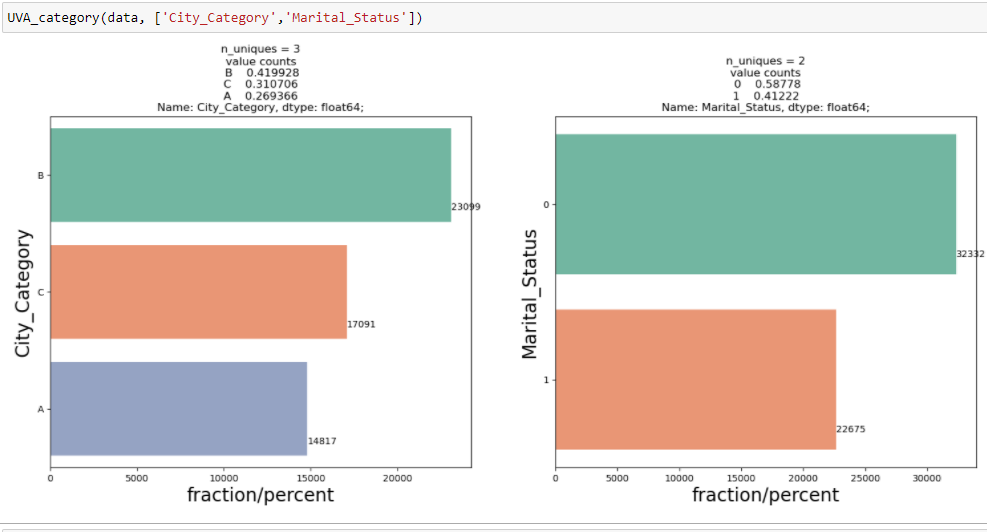
Pour afficher une analyse univariée sur des variables catégorielles dans l'ensemble de données de vente Black Friday: `Catégorie_Ville` y` État_Martial`, J'ai créé une fonction qui prend des données et des caractéristiques en entrée qui renvoie un graphique de comptage expliquant la fréquence des catégories dans la caractéristique.


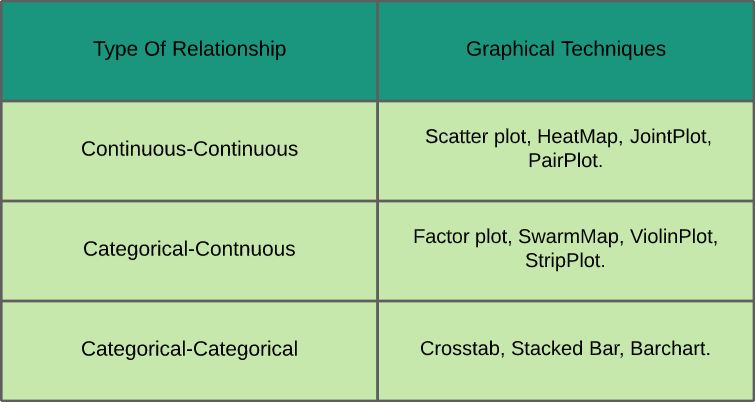
- Analyse bivariée: En analyse bivariée, nous étudions la relation entre deux variables quelconques qui peuvent être catégoriques-continues, catégorique-catégorique ou continu-continu (comme indiqué dans la fiche de référence ci-dessous avec les techniques graphiques utilisées pour les analyser).

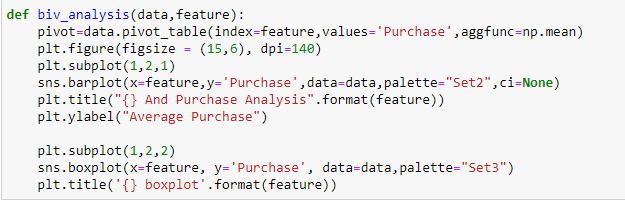
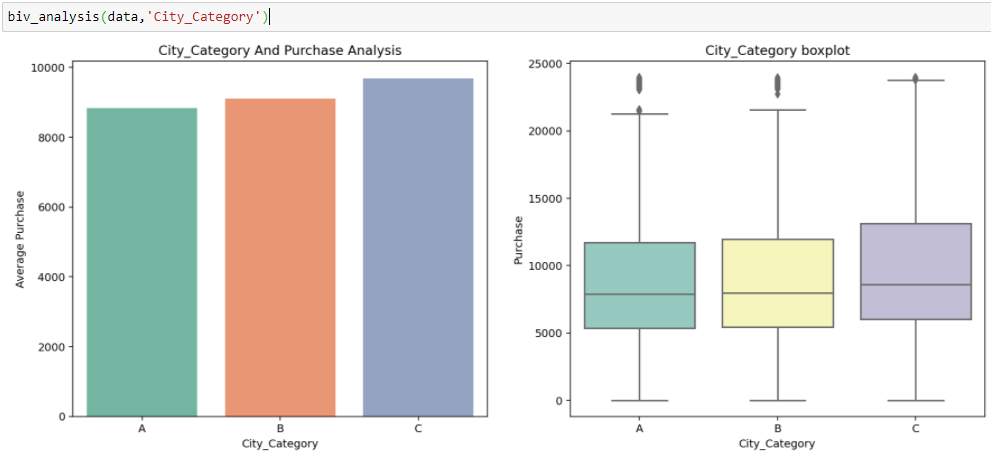
En Soldes du Vendredi fou, nous avons des variables indépendantes catégorielles et des variables cibles continues, afin que nous puissions faire une analyse catégorique continue pour comprendre la relation entre eux.

Inférence:
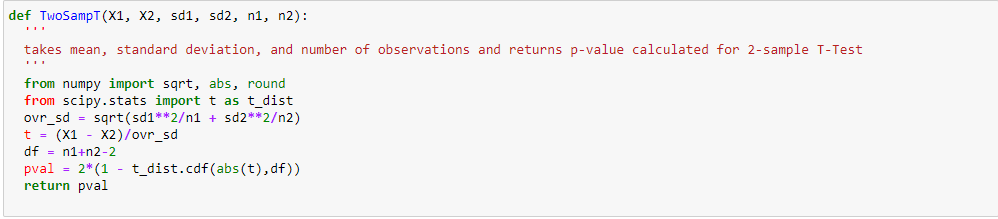
D'après les deux analyses précédentes, Nous avons observé dans l'analyse univariée que le nombre de clients est maximum dans la catégorie de ville B. Mais l'analyse bivariée lorsqu'elle est effectuée entre « City_Category » et « Achat » montre une histoire différente selon laquelle l'achat moyen est le maximum de la catégorie de ville C Par conséquent, ces inférences peuvent nous donner une meilleure intuition sur les données, ce qui à son tour aide à une meilleure préparation des données et à l'ingénierie des fonctionnalités des fonctionnalités.Il est important de noter que le simple fait de se fier à une analyse univariée et bivariée peut être assez trompeur., donc pour vérifier les inférences tirées de ces deux, vous pouvez valider avec Tests d'hypothèses. On peut faire un test, test du chi carré, Anova qui nous permet de quantifier si deux échantillons sont significativement similaires ou différents l'un de l'autre. Ici, j'ai créé une fonction pour analyser les relations continues et catégorielles qui renvoient la valeur de la statistique t.


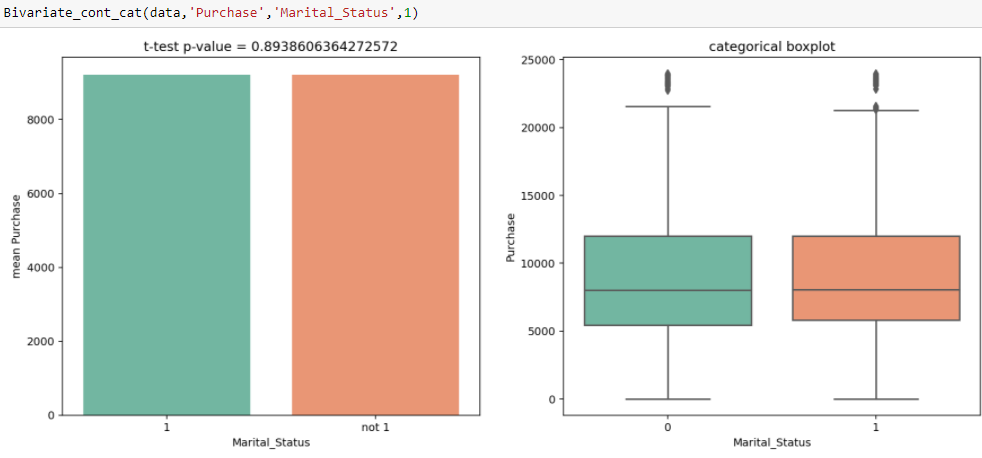
 En analyse univariée, nous observons qu'il existe une différence significative entre le nombre de clients mariés et non mariés. Du test t, on obtient la valeur de la statistique t 0.89, qui est supérieur au seuil de signification, c'est-à-dire, 0.05, ce qui montre qu'il n'y a pas de différence significative entre l'achat moyen des célibataires et des mariés.
En analyse univariée, nous observons qu'il existe une différence significative entre le nombre de clients mariés et non mariés. Du test t, on obtient la valeur de la statistique t 0.89, qui est supérieur au seuil de signification, c'est-à-dire, 0.05, ce qui montre qu'il n'y a pas de différence significative entre l'achat moyen des célibataires et des mariés. - Traitement de la valeur perdue : La raison principale de cette étape est de savoir s'il existe une raison spécifique pour laquelle ces valeurs sont manquantes et comment nous les traitons.. Parce que si on ne les traite pas, peut interférer avec le modèle qui s'exécute sur les données, ce qui peut à son tour dégrader les performances du modèle. Certaines des façons dont les valeurs manquantes peuvent être traitées sont: – Remplissez-les de médias, médian, mode et peut utiliser des imputres.
- Suppression des valeurs aberrantes : Il est essentiel que nous comprenions la présence de valeurs aberrantes, car certains des modèles prédictifs y sont sensibles et nous devons les traiter en conséquence.

 En analyse univariée, nous observons qu'il existe une différence significative entre le nombre de clients mariés et non mariés. Du test t, on obtient la valeur de la statistique t 0.89, qui est supérieur au seuil de signification, c'est-à-dire, 0.05, ce qui montre qu'il n'y a pas de différence significative entre l'achat moyen des célibataires et des mariés.
En analyse univariée, nous observons qu'il existe une différence significative entre le nombre de clients mariés et non mariés. Du test t, on obtient la valeur de la statistique t 0.89, qui est supérieur au seuil de signification, c'est-à-dire, 0.05, ce qui montre qu'il n'y a pas de différence significative entre l'achat moyen des célibataires et des mariés.Remarques finales
Dans cet article, J'ai brièvement discuté de l'importance de l'EDA dans le pipeline de la science des données et des étapes impliquées dans une analyse appropriée. J'ai également montré à quel point une analyse incorrecte ou incomplète peut être assez trompeuse et peut affecter considérablement les performances des modèles d'apprentissage automatique..
“Si vous ne brunissez pas vos données, tu es juste une autre personne avec une opinion”;)





