Curva AUC-ROC: L'artiste vedette!
Vous avez créé votre modèle de machine learning, ensuite, suivant? Vous devez l'évaluer et valider à quel point (ou mauvais) il est, pour décider plus tard s'il faut le mettre en œuvre. C'est là qu'intervient la courbe AUC-ROC..
Le nom peut être une bouchée, mais il dit seulement que nous calculons le “Aire en bas de la courbe” (ASC) du “Opérateur de caractéristiques du récepteur” (ROC). Confus? je vous comprends! j'ai été à ta place. Mais ne t'inquiètes pas, Nous verrons en détail ce que signifient ces termes et tout sera du gâteau !!

Pour l'instant, sachez simplement que la courbe AUC-ROC nous aide à visualiser les performances de notre classificateur d'apprentissage automatique. Bien que cela ne fonctionne que pour les problèmes de classification binaire, nous verrons vers la fin comment nous pouvons l'étendre pour évaluer également des problèmes de classification de classes multiples.
Nous aborderons également des sujets tels que la sensibilité et la spécificité., car ce sont des problèmes clés derrière la courbe AUC-ROC.
Je suggère de lire l'article sur Matrice de confusion car il introduira quelques termes importants que nous utiliserons dans cet article.
Table des matières
- Quelles sont la sensibilité et la spécificité?
- Probabilité des prédictions
- Quelle est la courbe AUC-ROC?
- Comment fonctionne la courbe AUC-ROC?
- AUC-ROC en Python
- AUC-ROC pour la classification à classes multiples
Quelles sont la sensibilité et la spécificité?
Voici à quoi ressemble une matrice de confusion:
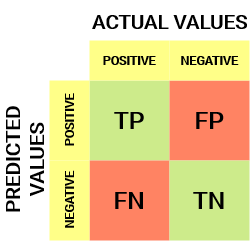
De la matrice de confusion, nous pouvons dériver des métriques importantes qui n'ont pas été discutées dans l'article précédent. Parlons d'eux ici.
Sensibilité / Taux de vrais positifs / Récupération
![]()
La sensibilité nous dit quelle proportion de la classe positive a été classée correctement.
Un exemple simple serait de déterminer quelle proportion des personnes malades réelles ont été correctement détectées par le modèle.
Taux de faux négatifs
![]()
Le taux de faux négatifs (FNR) nous dit quelle proportion de la classe positive a été mal classée par le classificateur.
Un TPR plus élevé et un FNR plus faible sont souhaitables car nous voulons classer correctement la classe positive.
Spécificité / Taux de vrais négatifs
![]()
La spécificité nous dit quelle proportion de la classe négative a été classée correctement.
Prenant le même exemple que dans Sensibilité, La spécificité signifierait déterminer la proportion de personnes en bonne santé qui ont été correctement identifiées par le modèle.
Taux de faux positifs
![]()
FPR nous dit quelle proportion de la classe négative a été mal classée par le classificateur.
Un TNR plus élevé et un FPR plus faible sont souhaitables car nous voulons classer correctement la classe négative.
De ces métriques, Sensibilité Oui Spécificité sont peut-être les plus importants et nous verrons plus tard comment ils sont utilisés pour construire une métrique d'évaluation. Mais avant ça, comprenons pourquoi la probabilité de prédiction est meilleure que de prédire directement la classe cible.
Probabilité des prédictions
Un modèle de classification d'apprentissage automatique peut être utilisé pour prédire directement la classe réelle du point de données ou prédire sa probabilité d'appartenir à différentes classes. Ce dernier nous donne plus de contrôle sur le résultat. Nous pouvons déterminer notre propre seuil pour interpréter le résultat du classificateur. C'est parfois plus sage que de simplement construire un tout nouveau modèle !!
La définition de différents seuils pour classer la classe positive pour les points de données modifiera par inadvertance la sensibilité et la spécificité du modèle.. Et l'un de ces seuils donnera probablement un meilleur résultat que les autres., selon que notre objectif est de réduire le nombre de faux négatifs ou de faux positifs.
Jetez un œil au tableau suivant:
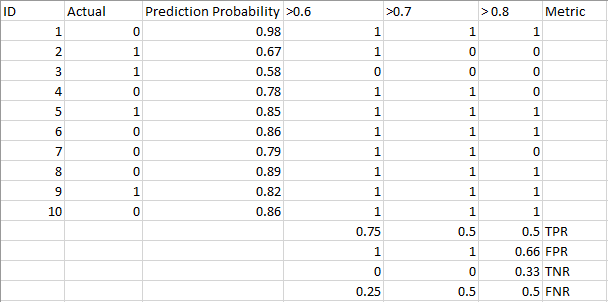
Les métriques changent avec les valeurs de seuil changeantes. Nous pouvons générer différentes matrices de confusion et comparer les différentes métriques dont nous avons discuté dans la section précédente.. Mais ce ne serait pas sage. En échange, ce que nous pouvons faire est de générer un graphique entre certaines de ces métriques afin que nous puissions facilement visualiser quel seuil nous donne un meilleur résultat.
La courbe AUC-ROC résout ce problème !!
Quelle est la courbe AUC-ROC?
Les Caractéristique de l'opérateur du récepteur (ROC) La courbe est une métrique d'évaluation pour les problèmes de classification binaire. C'est une courbe de probabilité qui trace le TPR contre FPR à différentes valeurs seuils et essentiellement séparer le 'signal’ de 'bruit’. Les Aire en bas de la courbe (ASC) est la mesure de la capacité d'un classificateur à distinguer les classes et est utilisé comme résumé de la courbe ROC.
Plus l'ASC est élevée, meilleure sera la performance du modèle pour distinguer les classes positives et négatives.
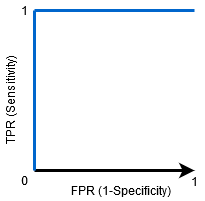
Quand ASC = 1, alors le classificateur peut parfaitement distinguer correctement tous les points de classe positifs et négatifs. Cependant, si l'AUC avait été 0, alors le classificateur prédirait tous les négatifs comme positifs et tous les positifs comme négatifs.
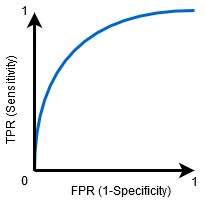
Lorsque 0.5 <ASC <1, il y a une forte probabilité que le classificateur puisse distinguer les valeurs de classe positives des valeurs de classe négatives. C'est parce que le classificateur peut détecter plus de nombres de vrais positifs et de vrais négatifs que de faux négatifs et de faux positifs..
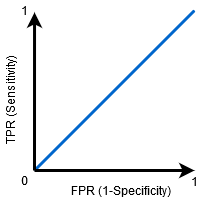
Quand ASC = 0.5, alors le classificateur ne peut pas faire la distinction entre les points de classe positifs et négatifs. Ce qui signifie que le classificateur prédit une classe aléatoire ou une classe constante pour tous les points de données.
Pourtant, plus la valeur AUC d'un classificateur est élevée, meilleure sera votre capacité à faire la distinction entre les classes positives et négatives.
Comment fonctionne la courbe AUC-ROC?
Dans une courbe ROC, une valeur d'axe X plus élevée indique un nombre plus élevé de faux positifs que de vrais négatifs. Alors qu'une valeur plus élevée sur l'axe Y indique un plus grand nombre de vrais positifs que de faux négatifs.. Donc, le choix du seuil dépend de la capacité à équilibrer les faux positifs et les faux négatifs.
Creusons un peu plus et comprenons à quoi ressemblerait notre courbe ROC pour différentes valeurs de seuil et comment la spécificité et la sensibilité varieraient..
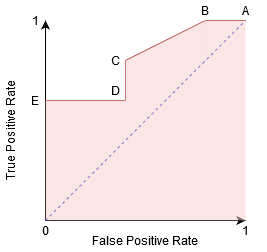
On peut essayer de comprendre ce graphe en générant une matrice de confusion pour chaque point correspondant à un seuil et parler des performances de notre classificateur:
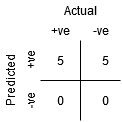
Le point A est l'endroit où la sensibilité est la plus élevée et la spécificité la plus faible.. Cela signifie que tous les points de classe positifs sont classés correctement et que tous les points de classe négatifs sont mal classés..
En réalité, tout point sur la ligne bleue correspond à une situation où le taux de vrais positifs est égal au taux de faux positifs.
Tous les points au-dessus de cette ligne correspondent à la situation dans laquelle la proportion de points correctement classés appartenant à la classe Positif est supérieure à la proportion de points mal classés appartenant à la classe Négative.
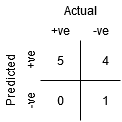
Bien que le point B ait la même sensibilité que le point A, a une spécificité plus élevée. Ce qui signifie que le nombre de points de classe incorrectement négatifs est moindre par rapport au seuil précédent. Cela indique que ce seuil est meilleur que le précédent.
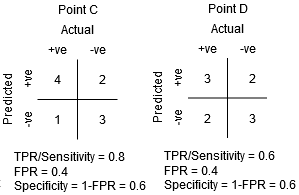
Entre les points C et D, la sensibilité au point C est plus élevée qu'au point D pour la même spécificité. Ceci signifie que, pour le même nombre de points de classe négatifs mal classés, le classificateur a prédit un plus grand nombre de points de classe positifs. Pourtant, le seuil au point C est meilleur qu'au point D.
À présent, en fonction du nombre de points mal classés que nous voulons tolérer pour notre classificateur, nous choisirions entre le point B ou C pour prédire si vous pouvez me battre dans PUBG ou non.
“Les faux espoirs sont plus dangereux que les peurs”. – JRR Tolkien

Le point E est l'endroit où la spécificité devient la plus élevée. Ce qui signifie qu'il n'y a pas de faux positifs classés par le modèle. Le modèle peut classer correctement tous les points de classe négatifs! Nous choisirions ce point si notre problème était de donner des recommandations de chansons parfaites à nos utilisateurs..
En suivant cette logique, Pouvez-vous deviner où serait le point correspondant à un classificateur parfait sur le graphique?
Oui! Ce serait dans le coin supérieur gauche du graphique ROC correspondant à la coordonnée (0, 1) dans le plan cartésien. C'est là que la sensibilité et la spécificité seraient les plus élevées et que le classificateur classerait correctement tous les points de classe Positif et Négatif..
Comprendre la courbe AUC-ROC en Python
À présent, nous pouvons tester manuellement la sensibilité et la spécificité pour chaque seuil ou laisser sklearn faire le travail pour nous. Nous allons certainement avec le dernier!
Créons nos données arbitraires en utilisant la méthode sklearn make_classification:
Je vais tester les performances de deux classificateurs sur cet ensemble de données:
Sklearn a une méthode roc_curve très puissante () qui calcule le ROC de votre classificateur en quelques secondes. Renvoie les valeurs de seuil, TPR et FPR:
Le score AUC peut être calculé en utilisant la méthode roc_auc_score () de sklearn:
0.9761029411764707 0.9233769727403157
Essayez ce code dans la fenêtre d'encodage en direct ci-dessous:
Nous pouvons également tracer les courbes ROC pour les deux algorithmes en utilisant matplotlib:
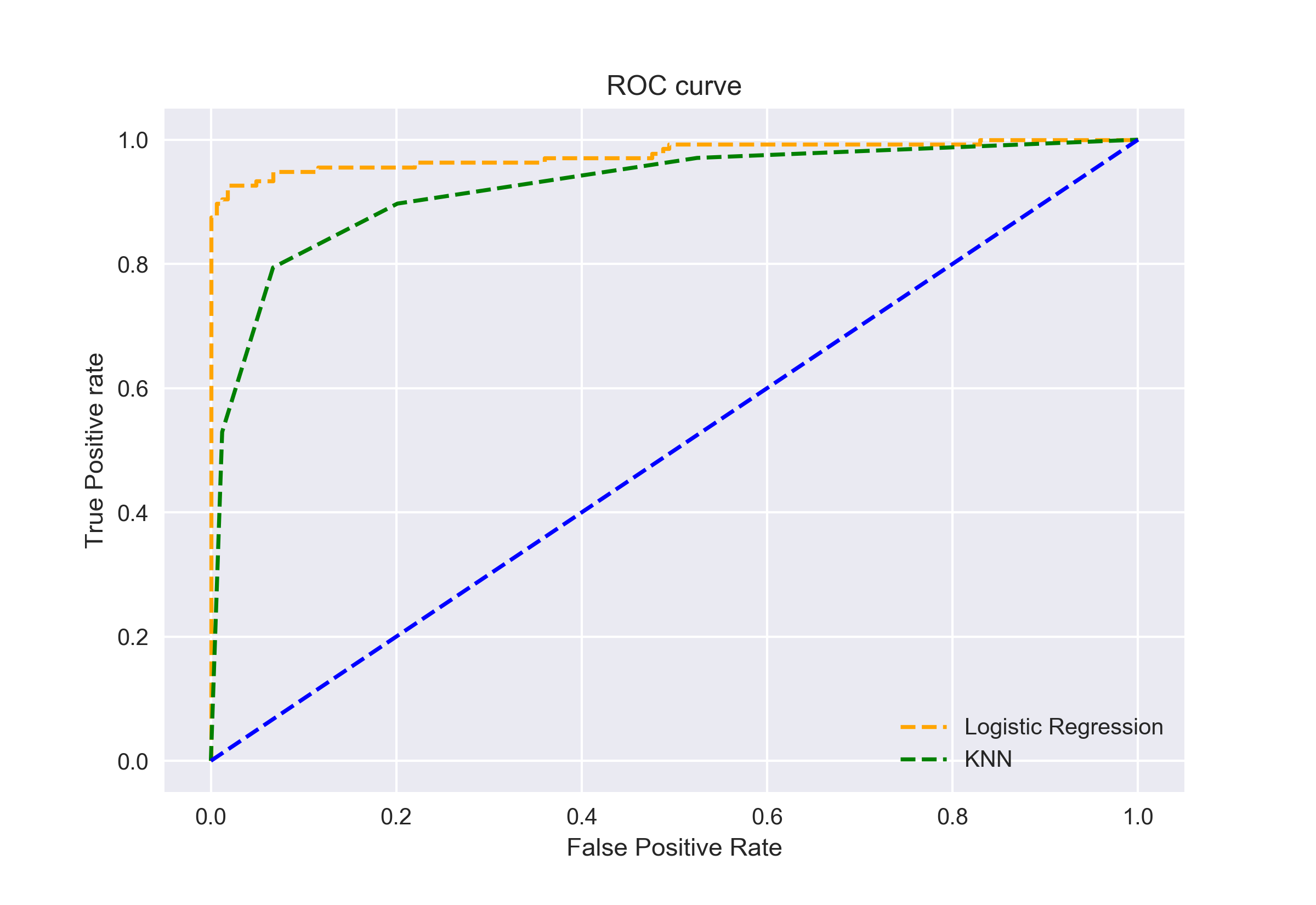
Il ressort du graphique que l'AUC de la courbe ROC de régression logistique est supérieure à celle de la courbe KNN ROC.. Donc, on peut dire que la régression logistique a mieux classé la classe positive dans l'ensemble de données.
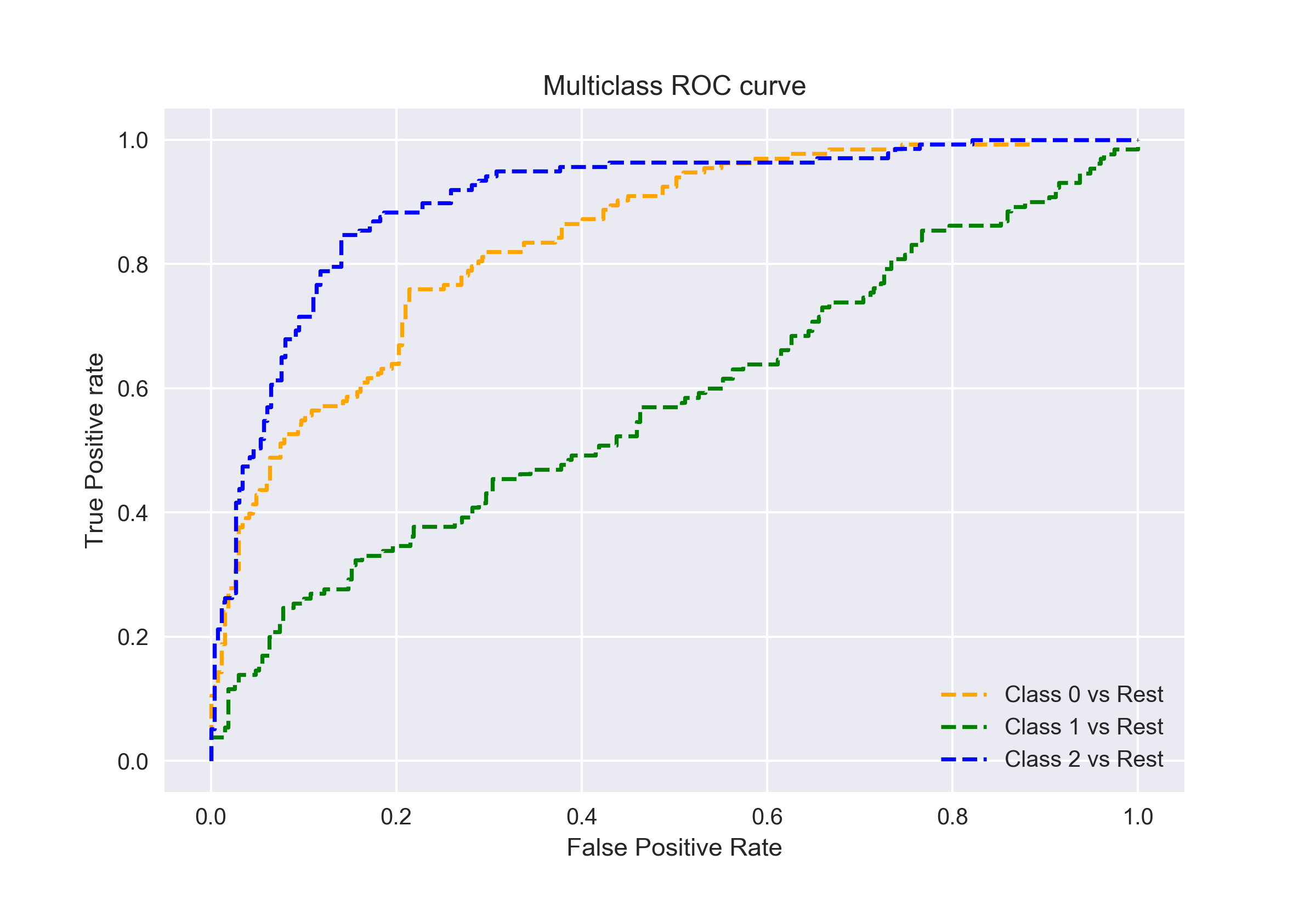
AUC-ROC pour la classification à classes multiples
Comme j'ai dit avant, la courbe AUC-ROC est uniquement pour les problèmes de classification binaire. Mais nous pouvons l'étendre aux problèmes de classification multiclasse en utilisant la technique One Against All..
Ensuite, si nous avons trois classes 0, 1 Oui 2, le ROC de la classe 0 sera généré en classant 0 contre non 0, c'est-à-dire, 1 Oui 2. Le ROC pour la classe 1 sera généré en classant 1 contre non 1, etc.
La courbe ROC pour les modèles de classification à classes multiples peut être déterminée comme suit:
Remarques finales
J'espère que cet article vous a été utile pour comprendre à quel point la métrique de la courbe AUC-ROC est puissante pour mesurer les performances d'un classificateur. Vous l'utiliserez beaucoup dans l'industrie et même dans les hackathons de science des données ou de machine learning. Mieux vaut s'y familiariser!
Aller plus loin, Je recommanderais les cours suivants qui vous aideront à développer votre sens de la science des données:





