introduction
Aujourd'hui, les organisations gèrent une grande quantité et une grande variété de données: appels clients, vos e-mails, tweets, données d'applications mobiles et plus. Il faut beaucoup d'efforts et de temps pour que ces données soient utiles. L'une des compétences de base pour extraire des informations à partir de données textuelles est le traitement du langage naturel. (PNL).
Traitement du langage naturel (PNL) c'est l'art et la science qui nous aident à extraire des informations du texte et à les utiliser dans nos calculs et algorithmes. Compte tenu de l'augmentation des contenus sur Internet et les réseaux sociaux, est l'un des incontournables pour tous les data scientists.
Que vous connaissiez la PNL ou non, ce guide devrait vous aider en tant que référence prête pour vous. Grâce à ce guide, Je vous ai fourni des ressources et des codes pour exécuter les tâches les plus courantes en PNL.
Une fois que vous avez lu ce guide, n'hésitez pas à jeter un oeil à notre cours vidéo sur le traitement du langage naturel (PNL).

Pourquoi ai-je créé ce guide?
Après avoir travaillé sur des problèmes de PNL pendant un certain temps, J'ai rencontré diverses situations où j'avais besoin de consulter des centaines de sources différentes pour étudier les derniers développements sous forme d'articles de recherche, blogs et concours pour certaines des tâches courantes de la PNL. .
Ensuite, J'ai décidé de rassembler toutes ces ressources en un seul endroit et d'en faire une solution unique pour les ressources les plus récentes et les plus importantes pour ces tâches courantes de PNL.. Vous trouverez ci-dessous la liste des tâches couvertes dans cet article ainsi que leurs ressources pertinentes.. Commençons.
Table des matières
- Dérivé
- Lématisation
- Incrustations de mots
- Étiqueter une partie du discours
- Désambiguïsation de l'entité nommée
- Reconnaissance d'entité nommée
- Analyse des sentiments
- Similitude de texte sémantique
- Identification de la langue
- Résumé du texte
1. Dérivé
Qu'est-ce que Stemming ?: La dérivation est le processus de réduction des mots (généralement modifié ou dérivé) à sa racine ou racine du mot. Le but de la racine est de réduire les mots liés à la même racine, même si la racine n'est pas un mot du dictionnaire. Par exemple, en langue anglaise-
- hermosa Oui magnifiquement sont dérivés de belle
- mieux Oui mieux sont dérivés de mieux Oui mieux respectivement
Papier: Les article original de Martin Porter dans l'algorithme de Porter pour dériver.
Algorithme: Voici l'implémentation Python de l'algorithme de dérivation Porter2.
Mise en œuvre: C'est ainsi que vous pouvez dériver un mot à l'aide de l'algorithme Porter2 à partir du dérive Une bibliothèque.
2. Lématisation
Qu'est-ce que la racine ?: La racine est le processus de réduction d'un groupe de mots à sa devise ou à sa forme de dictionnaire. Il prend en compte des choses comme POS (Parties du discours), le sens du mot dans la phrase, le sens du mot dans les phrases proches, etc. avant de réduire le mot à ta devise. Par exemple, en langue anglaise-
- hermosa Oui magnifiquement Ce sont des slogans pour hermosa Oui magnifiquement respectivement.
- bien, mieux Oui mieux Ce sont des slogans pour bien, bien Oui bien respectivement.
Document 1: Ce papier discute les différentes méthodes de lemmatisation en détail. A lire absolument si vous voulez savoir comment fonctionnent les stemmers traditionnels.
Document 2: C'est un excellent travail qui aborde le problème du stemming pour les langages riches en variations utilisant le Deep Learning.
Base de données: Ceci est le lien pour le jeu de données Treebank-3 que vous pouvez utiliser si vous souhaitez créer votre propre Lemmatiser.
Mise en œuvre: Vous trouverez ci-dessous une implémentation d'un lemmatiseur anglais utilisant spacy.
#!pip install spacy#python -m spacy download enimport spacynlp=spacy.load("en")doc="good better best"
for token in nlp(doc): print(token,token.lemma_)
3. Incrustations de mots
Que sont les incorporations de mots ?: Word Embeddings est le nom des techniques utilisées pour représenter le langage naturel sous forme vectorielle de nombres réels. Ils sont utiles en raison de l'incapacité des ordinateurs à traiter le langage naturel. Ensuite, ces incrustations de mots capturent l'essence et la relation entre les mots en langage naturel en utilisant des nombres réels. Et l'intégration de mots, una palabra o frase se representa en un vector de dimension"Dimension" C’est un terme qui est utilisé dans diverses disciplines, comme la physique, Mathématiques et philosophie. Il s’agit de la mesure dans laquelle un objet ou un phénomène peut être analysé ou décrit. En physique, par exemple, On parle de dimensions spatiales et temporelles, alors qu’en mathématiques, il peut faire référence au nombre de coordonnées nécessaires pour représenter un espace. Sa compréhension est fondamentale pour l’étude et... fija de longitud, Disons 100.
Par exemple-
Un mot « homme » peut être représenté dans un vecteur de 5 dimensions comme
![]()
où chacun de ces nombres est la grandeur du mot dans une direction particulière.
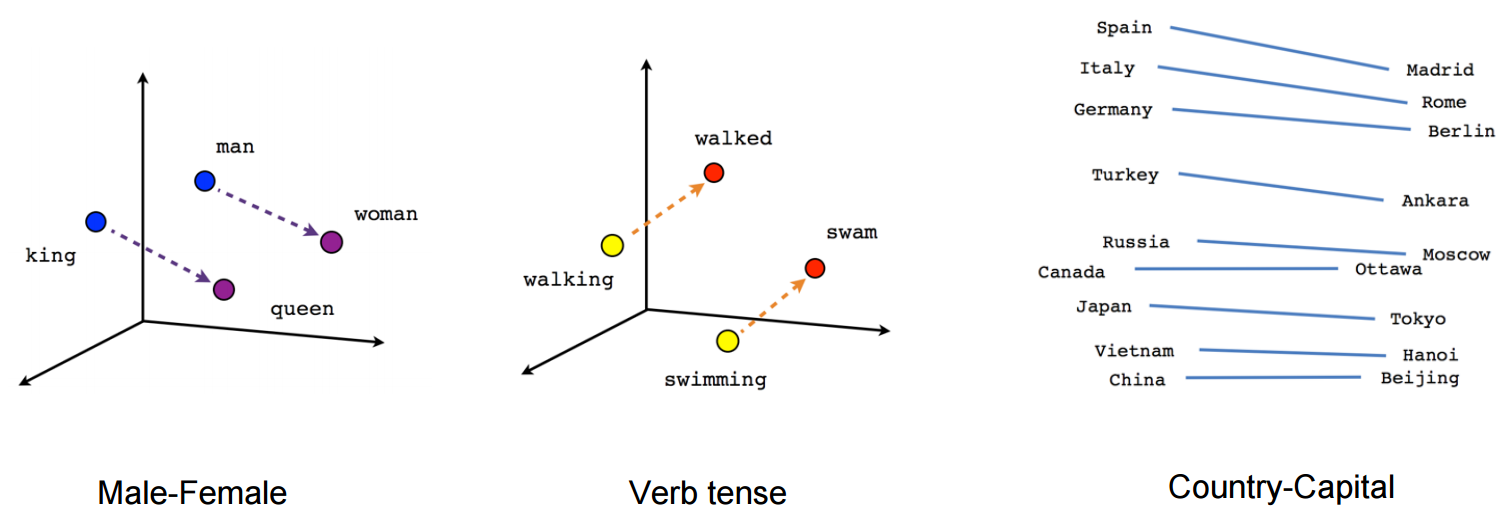
Blog: Voici un article qui explique les intégrations de Word en détail.
Papier: Un très bon rôle qui explique les vecteurs de mots en détail. A lire absolument pour une compréhension approfondie des vecteurs de mots.
Outil: Un navigateur basé outil pour visualiser les vecteurs de mots.
Vecteurs de mots pré-entraînés: Voici une liste exhaustive de Vecteurs de mots pré-entraînés dans 294 langues par facebook.
Mise en œuvre: Voici comment vous pouvez obtenir un vecteur de mot pré-entraîné en utilisant le package gensim.
Téléchargez le Vecteurs de mots préalablement formés dans Google News à partir d'ici.
#!pip install gensimfrom gensim.models.keyedvectors import KeyedVectorsword_vectors=KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin',binary=True)word_vectors['human']
Mise en œuvre: Voici comment vous pouvez former vos propres vecteurs de mots en utilisant gensim
sentence=[['first','sentence'],['second','sentence']]model = gensim.models.Word2Vec(sentence, min_count=1,size=300,workers=4)
4. Étiqueter une partie du discours
Qu'est-ce que l'étiquetage partiel de la parole ?: En termes simplistes, L'étiquetage des parties du discours est le processus de marquage des mots dans une phrase comme noms, verbes, adjectifs, les adverbes, etc.. Par exemple, dans la phrase-
« Ashok a tué le serpent avec un bâton »
Les parties du discours sont identifiées comme:
Ashok PROPN
délicat VERBE
Les LES
serpent NOM
avec ADP
une LES
palo NOM
. POINT
Test 1: Ce rôle de choi bien intitulé L'essence ultime à la pointe de la technologie introduit une nouvelle méthode appelée Dynamic Feature Induction qui atteint l'état de l'art dans la tâche d'étiquetage POS
Document 2: Ce papier Présente l'étiquetage POS sans surveillance à l'aide de modèles de Markov cachés par ancre.
Mise en œuvre: Voici comment nous pouvons effectuer le balisage POS en utilisant spacy.
#!pip install spacy#!python -m spacy download en nlp=spacy.load('en')sentence="Ashok killed the snake with a stick"for token in nlp(sentence): print(token,token.pos_)
5. Désambiguïsation de l'entité nommée
Qu'est-ce que la désambiguïsation d'entité nommée ?: La désambiguïsation de l'entité nommée est le processus d'identification des mentions d'entité dans une phrase. Par exemple, dans la phrase-
« Apple a réalisé un chiffre d'affaires de 200 milliards de dollars en 2016 »
C'est la tâche de la désignation des entités nommées d'inférer qu'Apple dans la phrase est la société Apple et non un fruit..
Entité nommée, en général, nécessite une base de connaissances des entités que vous pouvez utiliser pour lier les entités de la phrase à la base de connaissances.
Document 1: Cet article de Huang utilise des modèles de relations sémantiques profondes basés sur un réseau de neurones profonds en conjonction avec la base de connaissances pour obtenir un résultat de pointe dans la désambiguïsation des entités nommées.
Document 2: Cet article de Ganea et Hofmann utiliser l'attention neuronale locale avec Word embeds et sans fonctions créées manuellement.
6. Reconnaissance d'entité nommée
Qu'est-ce que la reconnaissance d'entité nommée ?: La reconnaissance d'entité nommée est la tâche d'identifier les entités dans une phrase et de les classer en catégories comme une personne, organisation, Date, Lieu, temps, etc. Par exemple, un NER prendrait une phrase comme:
« Bélier d'Apple Inc. s'est rendu à Sydney le 5 octobre 2017 »
et renvoie quelque chose comme
RAM
de
Pomme ORG
C. ORG
voyagé
à
Sydney GPE
sur
Cinquième DATE
octobre DATE
2017 DATE
Ici, ORG signifie Organisation et GPE signifie Emplacement.
Le problème avec les NER actuels est que même les NER de nouvelle génération ont tendance à sous-performer lorsqu'ils sont utilisés dans un domaine de données différent des données sur lesquelles le NER a été formé..

Papier: Cet excellent papier utilise des LSTM bidirectionnels et combine des méthodes d'apprentissage supervisées et non supervisées pour obtenir un résultat de pointe dans la reconnaissance d'entités nommées dans 4 langues.
Mise en œuvre: Ensuite, explique comment vous pouvez effectuer la reconnaissance d'entités nommées à l'aide de spacy.
import spacynlp=spacy.load('en')sentence="Ram of Apple Inc. travelled to Sydney on 5th October 2017"for token in nlp(sentence): print(token, token.ent_type_)
7. Analyse des sentiments
Qu'est-ce que l'analyse des sentiments ?: L'analyse des sentiments est un large éventail d'analyses subjectives qui utilise des techniques de traitement du langage naturel pour effectuer des tâches telles que l'identification du sentiment d'un avis client., sentiment positif ou négatif dans une phrase, juger de l'humeur à l'aide de l'analyse de la parole ou de l'analyse de texte écrit, etc. Par exemple:
"Je n'ai pas aimé la glace au chocolat" – c'est une expérience négative de la crème glacée.
« je n'ai pas détesté la glace au chocolat »: peut être considérée comme une expérience neutre
Il existe un large éventail de méthodes utilisées pour effectuer une analyse des sentiments, du comptage des mots négatifs et positifs dans une phrase à l'utilisation de LSTM avec des incrustations de mots.
Blog 1: Cet article se concentre sur la conduite d'une analyse des sentiments sur les tweets de films
Blog 2: Cet article se concentre sur la conduite d'une analyse des sentiments des tweets pendant l'inondation de Chennai.
Document 1: Ce papier adopta el enfoque del método de enseignement superviséL’apprentissage supervisé est une approche d’apprentissage automatique dans laquelle un modèle est formé à l’aide d’un ensemble de données étiquetées. Chaque entrée du jeu de données est associée à une sortie connue, permettre au modèle d’apprendre à prédire les résultats pour de nouvelles entrées. Cette méthode est largement utilisée dans des applications telles que la classification d’images, Reconnaissance vocale et prédiction de tendances, soulignant son importance dans... con el método Naive Bayes para clasificar las revisiones de IMDB.
Document 2: Ce papier utiliza el método de Apprentissage non superviséL’apprentissage non supervisé est une technique d’apprentissage automatique qui permet aux modèles d’identifier des modèles et des structures dans des données sans étiquettes prédéfinies. Grâce à des algorithmes tels que les k-moyennes et l’analyse en composantes principales, Cette approche est utilisée dans une variété d’applications, comme la segmentation de la clientèle, Détection d’anomalies et compression de données. Sa capacité à révéler des informations cachées en fait un outil précieux dans le... con LDA para identificar aspectos y sentimientos de las opiniones generadas por los usuarios. Ce document est remarquable en ce qu'il aborde le problème du manque d'avis commentés..
Dépôt: C'est un super référentiel de travaux de recherche et de mise en œuvre d'analyse des sentiments dans différentes langues.
Base de données 1: Ensemble de données de sentiment provenant de plusieurs domaines, version 2.0
Base de données 2: Ensemble de données d'analyse des sentiments Twitter
Faites vous-même l'analyse des sentiments sur Twitter.
8. Similitude de texte sémantique
Qu'est-ce que la similarité de texte sémantique ?: La similarité sémantique du texte est le processus d'analyse de la similitude entre deux morceaux de texte en ce qui concerne le sens et la substance du texte au lieu d'analyser la syntaxe des deux morceaux de texte. En outre, la similitude est différente de la relation.
Par exemple –
La voiture et le bus sont similaires, mais la voiture et le carburant sont liés.
Document 1: Ce papier présente les différentes approches pour mesurer la similarité de texte en détail. Un article à lire absolument pour en savoir plus sur les approches existantes en un seul endroit.
Document 2: Ce papier présente le CNN pour classer une paire de deux textes courts
Document 3: Ce papier utilise Tree-LSTM qui permet d'obtenir un résultat de pointe dans la relation sémantique des textes et la classification sémantique.
9. Identification de la langue
Qu'est-ce que l'identification de la langue ?: L'identification de la langue est la tâche d'identifier la langue dans laquelle se trouve le contenu. Il utilise les propriétés statistiques et syntaxiques du langage pour effectuer cette tâche. Il peut également être considéré comme un cas particulier de classification de texte.
Blog: Dans cet article de blog fastText, introduire un nouvel outil qui permet d'identifier 170 langues avec 1 Mo d'utilisation de la mémoire.
Document 1: Ce papier analyser 7 méthodes d'identification de la langue 285 langues.
Document 2: Ce papier décrit comment les réseaux de neurones profonds peuvent être utilisés pour obtenir des résultats de pointe dans l'identification automatique des langues.
10. Résumé du texte
Qu'est-ce qu'un résumé de texte ?: Le résumé de texte est le processus consistant à raccourcir un texte en identifiant les points importants du texte et en créant un résumé en utilisant ces points. L'objectif du résumé du texte est de conserver le maximum d'informations ainsi que le raccourcissement maximum du texte sans altérer le sens du texte.
Document 1: Ce papier décrit une approche basée sur un modèle d'attention neuronale pour résumer des phrases abstraites.
Document 2: Ce papier décrit comment les RNN séquence par séquence peuvent être utilisés pour obtenir des résultats de pointe dans la synthèse de texte.
Dépôt: Ce référentiel Google Brain L'équipe a les codes pour utiliser un modèle séquence par séquence personnalisé pour le résumé du texte. Le modèle est entraîné sur un ensemble de données Gigaword.
Application: Le robot autotldr sur Reddit utiliser un résumé de texte pour résumer les articles dans les commentaires d'un article. Cette fonctionnalité s'est avérée très célèbre parmi les utilisateurs de Reddit..
Mise en œuvre: c'est ainsi que vous pouvez rapidement résumer votre texte à l'aide du package gensim.
from gensim.summarization import summarizesentence="Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.Automatic data summarization is part of machine learning and data mining. The main idea of summarization is to find a subset of data which contains the information of the entire set. Such techniques are widely used in industry today. Search engines are an example; others include summarization of documents, image collections and videos. Document summarization tries to create a representative summary or abstract of the entire document, by finding the most informative sentences, while in image summarization the system finds the most representative and important (i.e. salient) images. For surveillance videos, one might want to extract the important events from the uneventful context.There are two general approaches to automatic summarization: extraction and abstraction. Extractive methods work by selecting a subset of existing words, phrases, or sentences in the original text to form the summary. In contrast, abstractive methods build an internal semantic representation and then use natural language generation techniques to create a summary that is closer to what a human might express. Such a summary might include verbal innovations. Research to date has focused primarily on extractive methods, which are appropriate for image collection summarization and video summarization."summarize(sentence)
Remarques finales
Il s'agissait donc des tâches les plus courantes de la PNL ainsi que de ses ressources pertinentes sous forme de blogs., articles de recherche, référentiels et applications, etc. Si tu le crois, il y a une excellente ressource sur l'un de ces 10 tâches que j'ai manquées ou que vous souhaitez suggérer d'ajouter une autre tâche, alors n'hésitez pas à commenter vos suggestions et commentaires.
Nous avons aussi un excellent cours, PNL utilisant Python, pour vous si vous souhaitez devenir praticien en PNL.
Bon apprentissage!





