introduction
L'apprentissage en profondeur gagne rapidement du terrain alors que de plus en plus d'articles de recherche sortent du monde entier.. Sans doute, ces documents contiennent beaucoup d'informations, mais ils peuvent souvent être difficiles à analyser. Et pour les comprendre, vous devrez peut-être revoir ce document plusieurs fois (Et peut-être même d'autres documents dépendants!).
C'est vraiment une tâche ardue pour les non-universitaires comme nous..

Personnellement, Je trouve la tâche de réviser un article de recherche, interpréter le nœud derrière et mettre en œuvre le code comme une compétence importante que tout passionné et praticien de l'apprentissage en profondeur devrait posséder. La mise en œuvre pratique des idées de recherche fait ressortir le processus de réflexion de l'auteur et aide également à transformer ces idées en applications industrielles réelles..
Ensuite, dans cet article (et la série d'articles suivante) ma raison d'écrire est double:
- Laissez les lecteurs suivre les recherches de pointe en décomposant les articles de deep learning en concepts compréhensibles.
- Apprendre à coder des idées de recherche pour moi-même et encourager les gens à le faire simultanément.
Cet article suppose que vous avez une bonne compréhension des bases de l'apprentissage en profondeur.. Au cas où vous n'en auriez pas besoin, ou juste besoin d'un rafraîchissement, vérifiez d'abord les éléments ci-dessous, puis revenez ici bientôt:
Table des matières
- Résumé du document “Plongez dans les circonvolutions”
- Objectif du travail
- Détails architecturaux proposés
- Méthodologie de la formation
- Implémentation de GoogLeNet dans Keras
Résumé du document “Plongez dans les circonvolutions”
Cet article se concentre sur le papier “Creusez plus profondément avec les circonvolutions” d'où vient l'idée distinctive du homenet. Le réseau domestique était autrefois considéré comme une architecture (le modèle) Deep learning de nouvelle génération pour résoudre les problèmes de reconnaissance et de détection d'images.
Performances révolutionnaires en vedette dans le défi de reconnaissance visuelle ImageNet (dans 2014), qui est une plate-forme renommée pour l'analyse comparative des algorithmes de reconnaissance et de détection d'images. avec ça, de nombreuses recherches ont été lancées sur la création de nouvelles architectures d'apprentissage en profondeur avec des idées innovantes et percutantes.
Nous allons passer en revue les principales idées et suggestions proposées dans le document mentionné ci-dessus et essayer de comprendre les techniques qu'il contient. Dans les mots de l'auteur:
“Dans cet article, nous nous concentrerons sur une architecture de réseau de neurones profonds efficace pour la vision par ordinateur, dont le nom de code est Inception, qui tire son nom de (…) le célèbre mème Internet” Nous devons aller plus loin “.

Cela semble intriguant, non? Bon, Continuez à lire alors!
Objectif du travail
Il existe un moyen simple mais puissant de créer de meilleurs modèles d'apprentissage en profondeur. Vous pouvez simplement faire un modèle plus grand, soit en profondeur, c'est-à-dire, nombre de couches, ou le nombre de neurones dans chaque couche. Mais comment peux-tu imaginer, cela peut souvent créer des complications:
- Plus le modèle est grand, plus enclin à sur-ajuster. Ceci est particulièrement visible lorsque les données d'entraînement sont petites..
- L'augmentation du nombre de paramètres signifie que vous devez augmenter vos ressources de calcul existantes
Une solution pour cela, comme le suggère le document, est de passer à des architectures de réseau faiblement connectées qui remplaceront les architectures de réseau entièrement connectées, surtout dans les couches convolutives. Cette idée peut être conceptualisée dans les images suivantes:
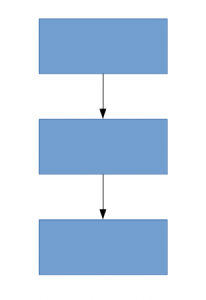
Architecture densément connectée
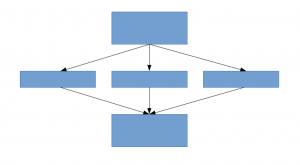
Architecture peu connectée
Cet article propose une nouvelle idée de création d'architectures profondes. Cette approche vous permet de maintenir “budget de calcul”, tout en augmentant la profondeur et la largeur du filet. Cela semble trop beau pour être vrai! Voici à quoi ressemble l'idée conceptualisée:
Regardons l'architecture proposée un peu plus en détail.
Détails architecturaux proposés
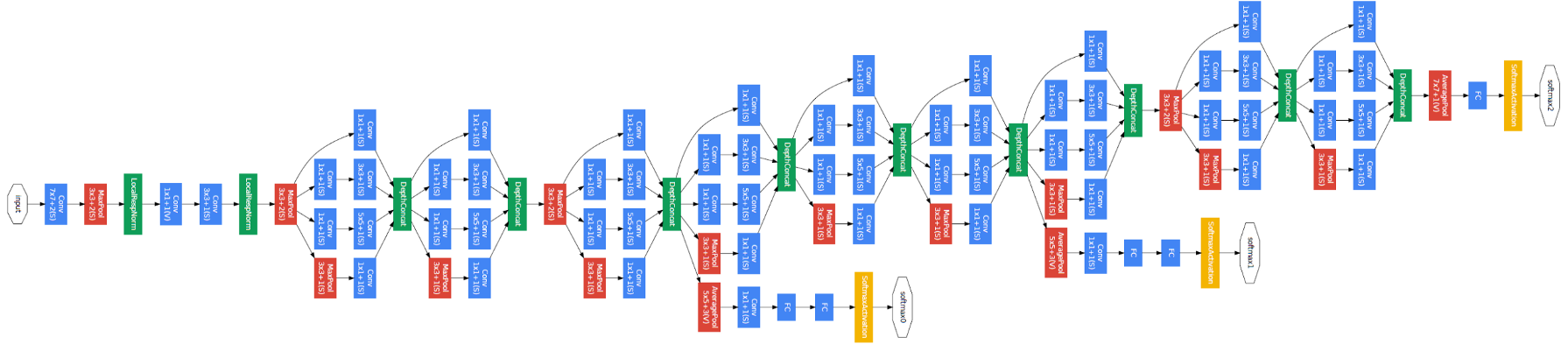
Le document propose un nouveau type d'architecture: GoogLeNet ou Inception v1. Il s'agit essentiellement d'un réseau de neurones convolutifs (CNN) Qu'est ce qui ne va pas avec ça 27 couches profondes.. Ci-dessous le résumé du modèle:

Remarquez dans l'image ci-dessus qu'il y a un calque appelé le calque de départ. C'est en fait l'idée principale derrière le focus du document. La couche initiale est le concept central d'une architecture mal connectée.
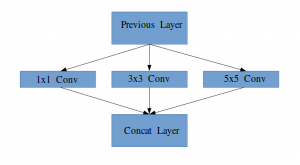
Idée d'un module de démarrage
Laissez-moi vous expliquer un peu plus en détail ce qu'est une couche de démarrage. Extrait de l'article:
“(Couche de départ) c'est une combinaison de toutes ces couches (c'est-à-dire, couverture convolutive 1 × 1, couverture convolutive 3 × 3, couverture convolutive 5 × 5) avec leurs bancs de filtres de sortie concaténés en un seul vecteur de sortie qui constitue l'entrée du scénario suivant.”
Avec les couches mentionnées ci-dessus, il y a deux plugins principaux dans la couche de démarrage d'origine:
- couverture convolutive 1 × 1 avant d'appliquer une autre couche, qui est principalement utilisé pour la réduction de dimensionnalité
- Une couche de regroupement maximale parallèle, qui fournit une autre option à la couche de départ
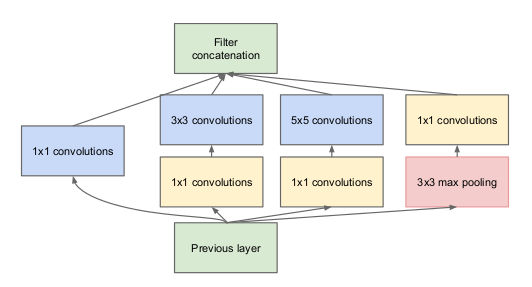
Couche de départ
Comprendre l'importance de la structure de la couche initiale, l'auteur s'inspire du principe hebbien de l'apprentissage humain. Ceci dit que “des neurones qui se déclenchent ensemble, ils se connectent ensemble”. L'auteur suggère que Lors de la création d'une couche de publication dans un modèle d'apprentissage en profondeur, Il faut prêter attention aux apprentissages de la couche précédente.
Supposer, par exemple, qu'une couche de notre modèle d'apprentissage en profondeur a appris à se concentrer sur des parties individuelles d'un visage. La couche suivante du réseau se concentrerait probablement sur la face générale de l'image pour identifier les différents objets qui y sont présents. À présent, pour faire ceci, le calque doit avoir les tailles de filtre appropriées pour détecter différents objets.
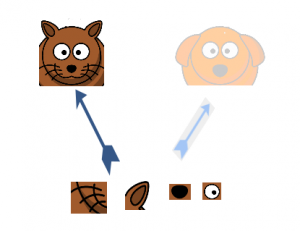
C'est là que la couche initiale vient au premier plan. Permet aux couches internes de choisir quelle taille de filtre sera pertinente pour connaître les informations requises. Ensuite, même si la taille du visage sur la photo est différente (comme on le voit sur les photos ci-dessous), la cape fonctionne en conséquence pour reconnaître le visage. Pour la première image, vous auriez probablement besoin d'une taille de filtre plus élevée, alors que j'en prendrais un plus bas pour la deuxième image.

Architecture générale, avec toutes les spécifications, ça ressemble à ça:
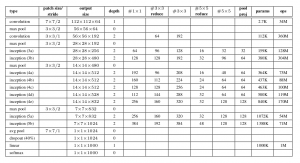
Méthodologie de la formation
Notez que cette architecture est née en grande partie du fait que les auteurs ont participé à un défi de détection et de reconnaissance d'images.. Donc, il y a plein “cloches et sifflets” qu'ils ont expliqué dans le document. Ceux-ci inclus:
- Le matériel utilisé pour entraîner les modèles.
- La technique d'augmentation de données pour créer l'ensemble de données d'entraînement.
- Les hyperparamètres du réseau de neurones, tels que la technique d'optimisation et le programme de taux d'apprentissage.
- Formation auxiliaire requise pour former le modèle.
- Techniques d'assemblage utilisées pour construire la présentation finale.
Entre ces, la formation auxiliaire dispensée par les auteurs est assez intéressante et originale par nature. Nous allons donc nous concentrer là-dessus pour le moment.. Les détails du reste des techniques peuvent être tirés de l'article lui-même, ou dans la mise en œuvre que nous verrons ci-dessous.
Pour éviter que la partie médiane du réseau ne "disparaisse", les auteurs ont introduit deux classificateurs auxiliaires (les carrés violets dans l'image). Essentiellement, softmax appliqué aux sorties de deux des modules de démarrage et calculé une perte auxiliaire sur les mêmes étiquettes. La fonction de perte totale est une somme pondérée de la perte auxiliaire et de la perte réelle. La valeur de poids utilisée sur le papier était 0,3 pour chaque perte auxiliaire.
Implémentation de GoogLeNet dans Keras
Maintenant que vous avez compris l'architecture GoogLeNet et l'intuition qui la sous-tend, Il est temps de lancer Python et de mettre en œuvre nos apprentissages à l'aide de Keras !! Nous utiliserons l'ensemble de données CIFAR-10 à cette fin.

CIFAR-10 est un ensemble de données de classification d'images populaire. Cela consiste en 60.000 images de 10 cours (chaque classe est représentée par une ligne dans l'image ci-dessus). L'ensemble de données est divisé en 50.000 images de formation et 10.000 images de test.
Gardez à l'esprit que vous devez avoir les bibliothèques nécessaires installées pour implémenter le code que nous verrons dans cette section. Cela inclut Keras et TensorFlow (comme backend pour Keras). Vous pouvez vérifier le guide d'installation officiel au cas où Keras n'est pas déjà installé sur votre machine.
Maintenant que nous avons pris soin des prérequis, nous pouvons enfin commencer à coder la théorie que nous avons couverte dans les sections précédentes. La première chose que nous devons faire est d'importer toutes les bibliothèques et modules nécessaires que nous utiliserons tout au long du code.
importer dur
de hard.layers.core importer Couche
importer keras.backend comme K
importer tensorflow comme tf
de jeux.de.données.dur importer cifar10
de modèles.durs importer Modèle
de les.couches.dures importer Conv2D, MaxPool2D,
Abandonner, Dense, Saisir, enchaîner,
GlobalMoyennePooling2D, MoyennePooling2D,
Aplatir
importer cv2
importer numpy comme par exemple
de jeux.de.données.dur importer cifar10
de dur importer back-end comme K
de hard.utils importer np_utils
importer math
de hard.optimizers importer EUR
de rappels.forts importer Planificateur de taux d'apprentissage
Ensuite, nous chargerons l'ensemble de données et effectuerons quelques étapes de prétraitement. Il s'agit d'une tâche critique avant que le modèle d'apprentissage en profondeur ne soit formé.
nombre_classes = 10
déf load_cifar10_data(img_rows, img_cols):
# Charger les ensembles de formation et de validation cifar10
(X_train, Y_train), (X_valide, Y_valide) = cifar10.load_data()
# Redimensionner les images d'entraînement
X_train = par exemple.déployer([cv2.redimensionner(img, (img_rows,img_cols)) pour img dans X_train[:,:,:,:]])
X_valide = par exemple.déployer([cv2.redimensionner(img, (img_rows,img_cols)) pour img dans X_valide[:,:,:,:]])
# Transformer les cibles au format compatible Keras
Y_train = np_utils.à_catégorique(Y_train, nombre_classes)
Y_valide = np_utils.à_catégorique(Y_valide, nombre_classes)
X_train = X_train.astype('float32')
X_valide = X_valide.astype('float32')
# prétraiter les données
X_train = X_train / 255.0
X_valide = X_valide / 255.0
revenir X_train, Y_train, X_valide, Y_valide
X_train, y_train, X_test, y_test = load_cifar10_data(224, 224)
À présent, nous définirons notre architecture de deep learning. Nous allons rapidement définir une fonction pour faire cela, Quoi, quand on vous donne les informations nécessaires, renvoie toute la couche de départ.
déf module_de_création(X,
filtres_1x1,
filtres_3x3_reduce,
filtres_3x3,
filtres_5x5_reduce,
filtres_5x5,
filtres_pool_proj,
Nom=Rien):
conv_1x1 = Conv2D(filtres_1x1, (1, 1), rembourrage='même', Activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(X)
conv_3x3 = Conv2D(filtres_3x3_reduce, (1, 1), rembourrage='même', Activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(X)
conv_3x3 = Conv2D(filtres_3x3, (3, 3), rembourrage='même', Activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_3x3)
conv_5x5 = Conv2D(filtres_5x5_reduce, (1, 1), rembourrage='même', Activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(X)
conv_5x5 = Conv2D(filtres_5x5, (5, 5), rembourrage='même', Activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_5x5)
pool_proj = MaxPool2D((3, 3), foulées=(1, 1), rembourrage='même')(X)
pool_proj = Conv2D(filtres_pool_proj, (1, 1), rembourrage='même', Activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(pool_proj)
sortir = enchaîner([conv_1x1, conv_3x3, conv_5x5, pool_proj], axe=3, Nom=Nom)
revenir sortir
Ensuite, nous allons créer l'architecture GoogLeNet, comme mentionné dans le document.
kernel_init = dur.initialiseurs.glorot_uniform()
bias_init = dur.initialiseurs.Constant(valeur=0.2)
couche_entrée = Saisir(forme=(224, 224, 3))
X = Conv2D(64, (7, 7), rembourrage='même', foulées=(2, 2), Activation='relu', Nom='conv_1_7x7/2', kernel_initializer=kernel_init, bias_initializer=bias_init)(couche_entrée)
X = MaxPool2D((3, 3), rembourrage='même', foulées=(2, 2), Nom='max_pool_1_3x3/2')(X)
X = Conv2D(64, (1, 1), rembourrage='même', foulées=(1, 1), Activation='relu', Nom='conv_2a_3x3/1')(X)
X = Conv2D(192, (3, 3), rembourrage='même', foulées=(1, 1), Activation='relu', Nom='conv_2b_3x3/1')(X)
X = MaxPool2D((3, 3), rembourrage='même', foulées=(2, 2), Nom='max_pool_2_3x3/2')(X)
X = module_de_création(X,
filtres_1x1=64,
filtres_3x3_reduce=96,
filtres_3x3=128,
filtres_5x5_reduce=16,
filtres_5x5=32,
filtres_pool_proj=32,
Nom='création_3a')
X = module_de_création(X,
filtres_1x1=128,
filtres_3x3_reduce=128,
filtres_3x3=192,
filtres_5x5_reduce=32,
filtres_5x5=96,
filtres_pool_proj=64,
Nom='création_3b')
X = MaxPool2D((3, 3), rembourrage='même', foulées=(2, 2), Nom='max_pool_3_3x3/2')(X)
X = module_de_création(X,
filtres_1x1=192,
filtres_3x3_reduce=96,
filtres_3x3=208,
filtres_5x5_reduce=16,
filtres_5x5=48,
filtres_pool_proj=64,
Nom='création_4a')
x1 = MoyennePooling2D((5, 5), foulées=3)(X)
x1 = Conv2D(128, (1, 1), rembourrage='même', Activation='relu')(x1)
x1 = Aplatir()(x1)
x1 = Dense(1024, Activation='relu')(x1)
x1 = Abandonner(0.7)(x1)
x1 = Dense(10, Activation='softmax', Nom='auxilliary_output_1')(x1)
X = module_de_création(X,
filtres_1x1=160,
filtres_3x3_reduce=112,
filtres_3x3=224,
filtres_5x5_reduce=24,
filtres_5x5=64,
filtres_pool_proj=64,
Nom='création_4b')
X = module_de_création(X,
filtres_1x1=128,
filtres_3x3_reduce=128,
filtres_3x3=256,
filtres_5x5_reduce=24,
filtres_5x5=64,
filtres_pool_proj=64,
Nom='création_4c')
X = module_de_création(X,
filtres_1x1=112,
filtres_3x3_reduce=144,
filtres_3x3=288,
filtres_5x5_reduce=32,
filtres_5x5=64,
filtres_pool_proj=64,
Nom='création_4d')
x2 = MoyennePooling2D((5, 5), foulées=3)(X)
x2 = Conv2D(128, (1, 1), rembourrage='même', Activation='relu')(x2)
x2 = Aplatir()(x2)
x2 = Dense(1024, Activation='relu')(x2)
x2 = Abandonner(0.7)(x2)
x2 = Dense(10, Activation='softmax', Nom='auxilliary_output_2')(x2)
X = module_de_création(X,
filtres_1x1=256,
filtres_3x3_reduce=160,
filtres_3x3=320,
filtres_5x5_reduce=32,
filtres_5x5=128,
filtres_pool_proj=128,
Nom='création_4e')
X = MaxPool2D((3, 3), rembourrage='même', foulées=(2, 2), Nom='max_pool_4_3x3/2')(X)
X = module_de_création(X,
filtres_1x1=256,
filtres_3x3_reduce=160,
filtres_3x3=320,
filtres_5x5_reduce=32,
filtres_5x5=128,
filtres_pool_proj=128,
Nom='création_5a')
X = module_de_création(X,
filtres_1x1=384,
filtres_3x3_reduce=192,
filtres_3x3=384,
filtres_5x5_reduce=48,
filtres_5x5=128,
filtres_pool_proj=128,
Nom='création_5b')
X = GlobalMoyennePooling2D(Nom='moy_pool_5_3x3/1')(X)
X = Abandonner(0.4)(X)
X = Dense(10, Activation='softmax', Nom='sortir')(X)
maquette = Modèle(couche_entrée, [X, x1, x2], Nom='création_v1')
Résumons notre modèle pour vérifier si notre travail jusqu'à présent s'est bien passé.
Le modèle a l'air bien, comment pouvez-vous mesurer à partir de la sortie ci-dessus. Nous pouvons ajouter quelques touches finales avant de former notre modèle. Nous définirons ce qui suit:
- Fonction de perte pour chaque couche de sortie
- Poids attribué à cette couche de sortie
- Fonction d'optimisation, qui est modifié pour inclure une diminution de poids après chaque 8 époques.
- Métrique d'évaluation
époques = 25
taux_initial = 0.01
déf carie(époque, pas=100):
taux_initial = 0.01
tomber = 0.96
epochs_drop = 8
taux = taux_initial * math.pow(tomber, math.sol((1+époque)/epochs_drop))
revenir taux
sgd = EUR(g / D=taux_initial, élan=0.9, nesterov=Faux)
lr_sc = Planificateur de taux d'apprentissage(carie, verbeux=1)
maquette.compiler(perte=['categorical_crossentropy', 'categorical_crossentropy', 'categorical_crossentropy'], perte_poids=[1, 0.3, 0.3], optimiseur=sgd, métrique=['précision'])
Notre modèle est maintenant prêt! Essayez-le pour voir comment cela fonctionne.
l'histoire = maquette.ajuster(X_train, [y_train, y_train, y_train], validation_données=(X_test, [y_test, y_test, y_test]), époques=époques, taille du lot=256, rappels=[lr_sc])
Voici le résultat que j'ai obtenu lors de l'entraînement du modèle:
Notre modèle a donné une précision impressionnante de la 80% + dans l'ensemble de validation, ce qui montre que cette architecture de modèle vaut vraiment le détour.
Remarques finales
C'était un très bel article à écrire et j'espère que vous l'avez trouvé tout aussi utile. Inception v1 était le point central de cet article, dans lequel j'ai expliqué les détails de ce framework et montré comment le mettre en œuvre à partir de zéro dans Keras.
Dans les prochains articles, Je me concentrerai sur les avancées des architectures Inception. Ces avancées ont été détaillées dans des articles ultérieurs., a savoir, Création v2, Création v3, etc. Et si, ils sont aussi intrigants que son nom l'indique, Alors restez à l'écoute!
Si vous avez des suggestions / commentaire lié à l'article, postez-le dans la section commentaire ci-dessous.





