introduction
Qu'est-ce que le nettoyage des données? Suppression des enregistrements nuls, suppression des colonnes inutiles, le traitement des valeurs manquantes, rectification des valeurs indésirables ou des valeurs aberrantes, restructurer les données pour les éditer dans un format plus lisible, etc., c'est ce qu'on appelle le nettoyage des données.

L'un des exemples les plus courants de nettoyage des données est son application dans les entrepôts de données. Un entrepôt de données stocke une gamme de données provenant de nombreuses sources et les optimise pour l'analyse avant qu'un ajustement de modèle puisse être effectué.
Le nettoyage des données ne consiste pas seulement à supprimer des informations existantes pour ajouter de nouvelles informations, mais trouver un moyen de maximiser la précision d'un ensemble de données sans nécessairement abandonner les informations existantes. Différents types de données nécessiteront différents types de nettoyage, mais rappelez-vous toujours que la bonne approche est le facteur décisif.
Après avoir nettoyé les données, deviendra cohérent avec d'autres ensembles de données similaires dans le système.. Voyons les étapes pour nettoyer les données;
Effacer les enregistrements nuls / doublons
Si une ligne particulière manque une quantité importante de données, alors il vaudrait mieux supprimer cette ligne, car cela n'ajouterait aucune valeur à notre modèle. peut imputer la valeur; fournir un substitut approprié aux données manquantes. N'oubliez pas non plus de toujours effacer les valeurs en double / redondant de votre jeu de données, car ils pourraient entraîner un biais dans votre modèle.
Par exemple, considérer l'ensemble de données des élèves avec les enregistrements suivants.
| nom | But | adresse | la taille | poids |
| UNE | 56 | Aller à | 165 | 56 |
| B | 45 | Bombay | 3 | Soixante-cinq |
| C | 87 | Delhi | 170 | 58 |
| ré | ||||
| moi | 99 | Mysore | 167 | 60 |
Comme on voit qu'il correspond au nom de l'élève “ré”, la plupart des données sont manquantes, pour cela, nous rejetons cette ligne particulière.
étudiant_df.dropna() # supprime les lignes avec 1 ou plus de valeur Nan
#production
| nom | But | adresse | la taille | poids |
| UNE | 56 | Aller à | 165 | 56 |
| B | 45 | Bombay | 3 | Soixante-cinq |
| C | 87 | Delhi | 170 | 58 |
| moi | 99 | Mysore | 167 | 60 |
Supprimer les colonnes inutiles
Lorsque nous recevons des données des parties intéressées, en général c'est énorme. Il peut y avoir un enregistrement de données qui pourrait ne pas ajouter de valeur à notre modèle. Il est préférable de supprimer ces données, car il le ferait avec des ressources précieuses telles que la mémoire et le temps de traitement.
Par exemple, observer les performances des élèves à un test, le poids ou la taille des élèves n'ont rien à contribuer au modèle.
étudiant_df.drop(['la taille','poids'], axe = 1, en place = vrai) #La colonne Hauteur des gouttes forme le cadre de données
#Production
| nom | But | adresse |
| UNE | 56 | Aller à |
| B | 45 | Bombay |
| C | 87 | Delhi |
| moi | 99 | Mysore |
Renommer les colonnes
Il est toujours préférable de renommer les colonnes et de les formater au format le plus lisible que le data scientist et l'entreprise puissent comprendre.. Par exemple, dans l'ensemble de données des élèves, renommer la colonne “nom” Quoi “Sudent_Name” logique.
étudiant_df.renommer(colonnes={'Nom': 'Nom d'étudiant'}, inplace=Vrai) #renomme la colonne de nom en Student_Name
#Production
| Nom de l'étudiant | But | adresse |
| UNE | 56 | Aller à |
| B | 45 | Bombay |
| C | 87 | Delhi |
| moi | 99 | Mysore |
Traiter les valeurs manquantes
Il existe de nombreuses alternatives pour prendre en charge les valeurs manquantes dans un jeu de données. Il appartient au data scientist et à l'ensemble de données dont il dispose de sélectionner la méthode la plus appropriée. Les méthodes les plus utilisées sont l'imputation de l'ensemble de données avec la moyenne, moyen ou mode. Supprimer ces enregistrements particuliers avec une ou plusieurs valeurs manquantes et, dans certains cas, la création d'algorithmes d'apprentissage automatique comme la régression linéaire et le voisin le plus proche K est également utilisé pour traiter les valeurs manquantes.
| Nom de l'étudiant | But | adresse |
| UNE | 56 | Aller à |
| B | 45 | Bombay |
| C | Delhi | |
| moi | 99 | Mysore |
Étudiant_df['col_name'].remplir((Étudiant_df['col_name'].moyenne()), inplace=Vrai) # Les valeurs Na dans col_name sont remplacées par la moyenne
#Production
| Nom de l'étudiant | But | adresse |
| UNE | 96 | Aller à |
| B | 45 | Bombay |
| C | 66 | Delhi |
| moi | 99 | Mysore |
Détection de valeurs atypiques
Les valeurs aberrantes peuvent être considérées comme du bruit dans l'ensemble de données. Il peut y avoir plusieurs raisons pour les valeurs aberrantes, comme erreur de saisie de données, manuel d'erreur, erreur expérimentale, etc.
Par exemple, dans l'exemple suivant, note de l'élève “B” vous entrez 130, ce qui n'est clairement pas correct.
| Nom de l'étudiant | But | adresse | la taille | poids |
| UNE | 56 | Aller à | 165 | 56 |
| B | 45 | Bombay | 3 | Soixante-cinq |
| C | 66 | Delhi | 170 | 58 |
| moi | 99 | Mysore | 167 | 60 |
Tracer la hauteur sur une boîte à moustaches donne le résultat suivant
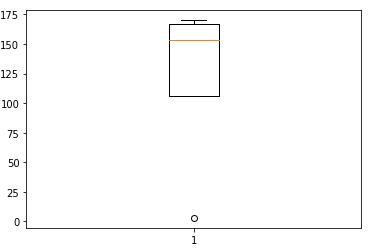
Toutes les valeurs extrêmes ne sont pas des valeurs aberrantes, certains peuvent également conduire à des découvertes intéressantes, mais c'est un sujet pour un autre jour. Des tests tels que le test Z-score peuvent être utilisés, la boîte à moustaches ou simplement tracer les données sur le graphique révélera les valeurs aberrantes.
Réforme / restructurer les données
La plupart des données commerciales fournies au data scientist ne sont pas dans le format le plus lisible. C'est notre travail de remodeler les données et de les mettre dans un format qui peut être utilisé pour l'analyse.. Par exemple, créer une nouvelle variable à partir de variables existantes ou combiner 2 ou plusieurs variables.
Notes de bas de page
Certainement, travailler avec des données propres présente de nombreux avantages, peu d'entre eux sont l'amélioration de la précision des modèles, meilleure prise de décision par les parties prenantes, la facilité de mise en œuvre du modèle et de réglage des paramètres, gain de temps et de ressources, et beaucoup plus. N'oubliez jamais de nettoyer les données comme la première et la plus importante étape avant d'adapter un modèle.
Les références
https://www.geeksforgeeks.org/
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





