Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
Apache Spark est un framework utilisé dans les environnements informatiques en cluster pour analyser les données volumineuses. Apache Spark peut fonctionner dans un environnement distribué sur un groupe d'ordinateurs dans un cluster pour traiter plus efficacement de grands ensembles de données. Ce moteur Spark open source prend en charge un large éventail de langages de programmation, y compris Scala, Java, Ry Python.
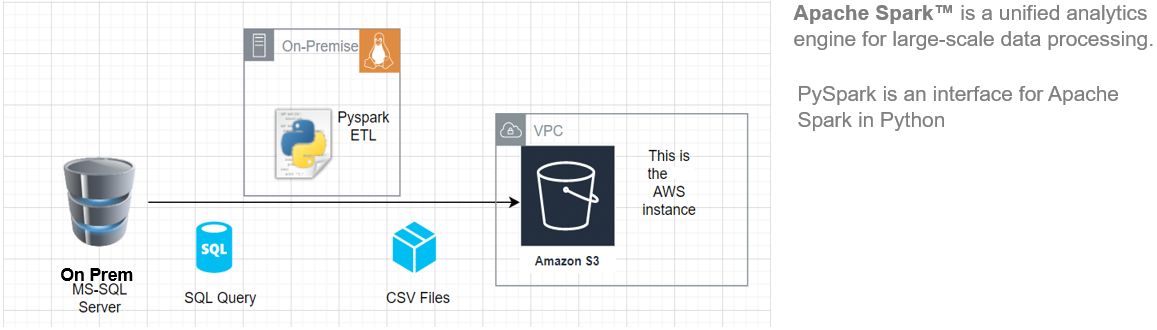
Dans cet article, Je vais vous montrer comment commencer à installer Pyspark sur votre Ubuntu machine, puis créez un pipeline ETL de base pour extraire les données de charge de transfert d'un système RDBMS distant vers un AWS S3 Baquet.
Cette architecture ETL peut être utilisée pour transférer des centaines de gigaoctets de données à partir de n'importe quel serveur de base de données SGBDR. (dans cet article, nous avons utilisé MS SQL Server) a un bucket de Amazon S3.
Principaux avantages de l'utilisation d'Apache Spark:
- Exécuter des charges de travail 100 fois plus rapide que Hadoop
- Compatible Java, Scala, Python, R y SQL
La source: Ceci est une image originale.
Exigences
Pour commencer, nous devons avoir les prérequis suivants:
- Un système sous Ubuntu 18.04 Ubuntu 20.04
- Un compte utilisateur avec des privilèges sudo
- Un compte AWS avec accès de téléchargement au compartiment S3
Avant de télécharger et de configurer Spark, vous devez installer les dépendances de package nécessaires. Assurez-vous que les packages suivants sont déjà configurés sur votre système.
Pour confirmer les dépendances installées en exécutant ces commandes:
java -version; git --version; python --version

Installer PySpark
Téléchargez la version de Spark souhaitée sur le site officiel d'Apache. Nous allons télécharger Spark 3.0.3 avec Hadoop 2.7 car c'est la version actuelle. Ensuite, utilisez la commande wget et l'URL directe pour télécharger le package Spark.
Changez votre répertoire de travail en / opter / étincelle.
cd /opt/étincelle
sudo wget https://downloads.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz

Extraire le package enregistré à l'aide de la commande tar. Une fois le processus d'épandage terminé, la sortie montre les fichiers qui ont été décompressés de l'archive.
goudron xvf spark-*
ls -lrt étincelle-*

Configurer l'environnement Spark
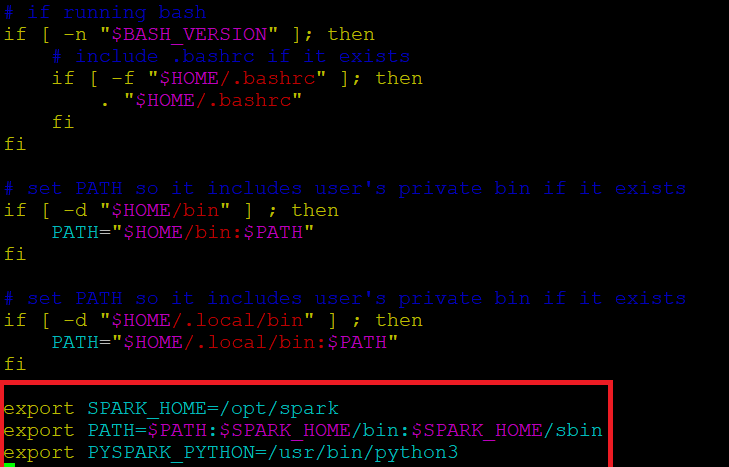
Avant de démarrer un serveur Spark, nous devons définir des variables d'environnement. Il y a des répertoires Spark que nous devons ajouter au profil par défaut. Utilisez l'éditeur vi ou tout autre éditeur pour ajouter ces trois lignes à .profile:
vi ~ / .profil
Insérez ces 3 lignes à la fin du fichier .profile.
export SPARK_HOME=/opt/spark export CHEMIN=$CHEMIN:$SPARK_HOME/bin:$SPARK_HOME/sbin exporter PYSPARK_PYTHON=/usr/bin/python3
Enregistrez les modifications et quittez l'éditeur. Lorsque vous avez fini de modifier le fichier, charger le .profil fichier sur la ligne de commande en tapant. Alternativement, nous pouvons quitter le serveur et nous reconnecter pour que les modifications prennent effet.
source ~/.profil
Début / Arrêtez Spark Master & Ouvrier
Allez dans le répertoire d'installation de Spark / opter / étincelle / étincelle *. Il a tous les scripts nécessaires pour démarrer / arrêter les services Spark.
Exécutez cette commande pour démarrer Spark Master.
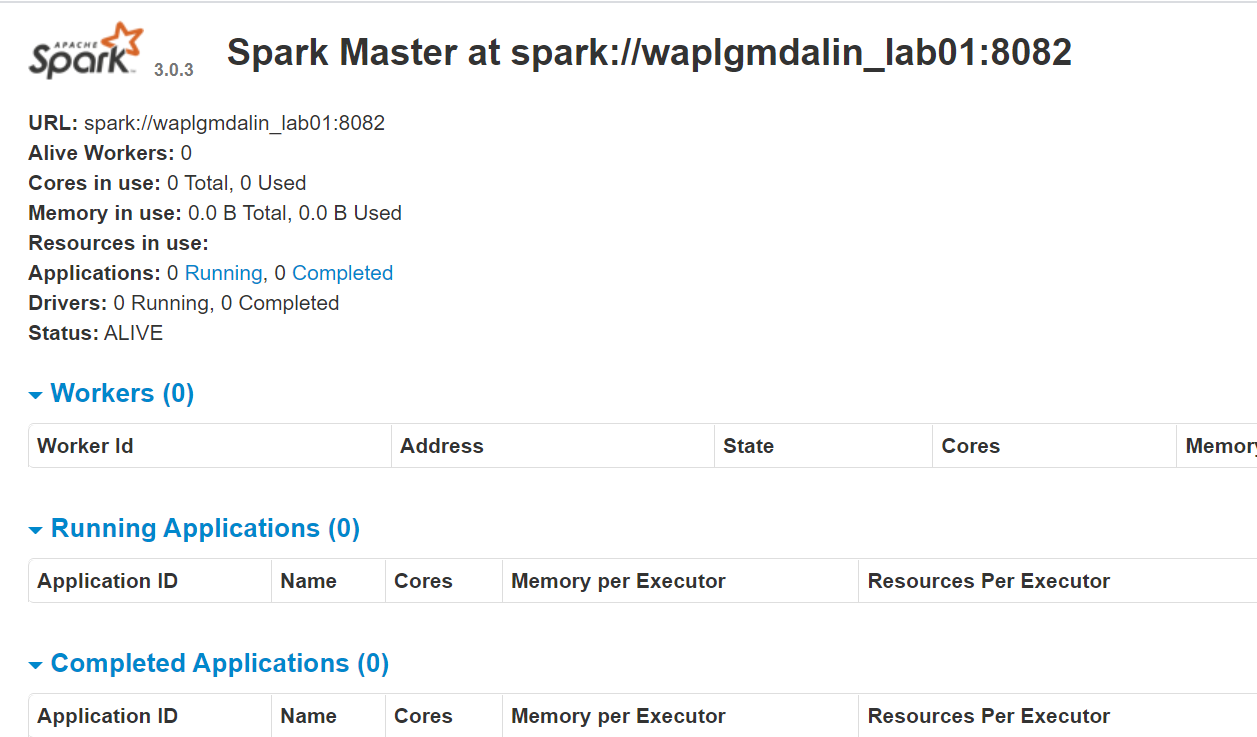
start-master.shPour afficher l'interface Web Spark, ouvrez un navigateur Web et entrez l'adresse IP de l'hôte local dans le port 8080. (C'est le port par défaut que Spark utilise si vous devez le changer, faites-le dans le script start-master.sh). Alternativement, peut remplacer 127.0.0.1 avec l'adresse IP réseau réelle de votre machine hôte.
http://127.0.0.1:8080/La page Web affiche l'URL Spark Master, nœuds de travail, Utilisation des ressources CPU, la mémoire, applications en cours d'exécution, etc.
À présent, exécutez cette commande pour démarrer une instance de travail Spark.
start-slave.sh étincelle://0.0.0.0:8082
O
start-slave.sh étincelle://waplgmdalin_lab01:8082
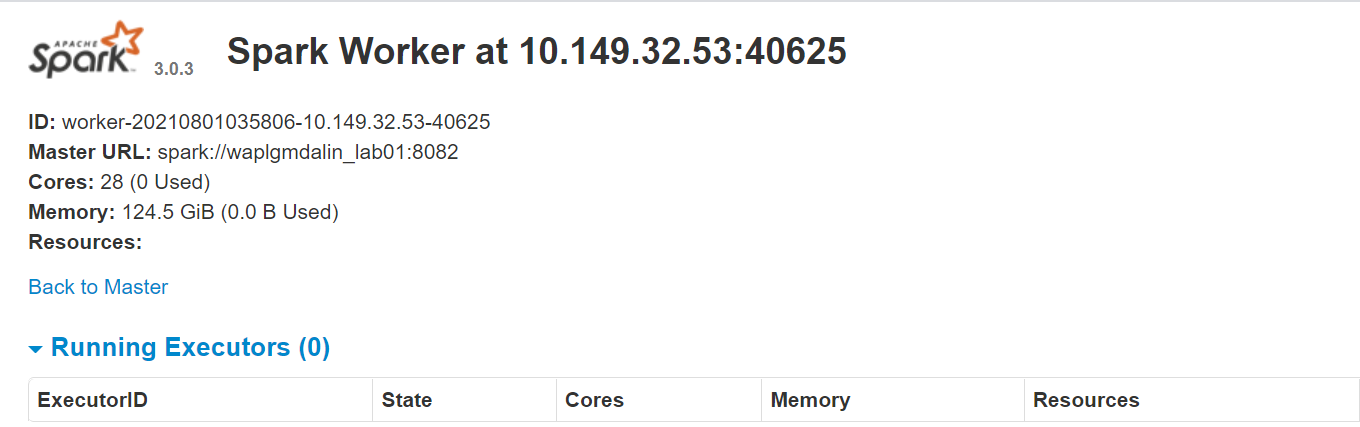
Le site Web du travailleur fonctionne sur http://127.0.0.1:8084/ mais il doit être lié à l'enseignant. C'est pourquoi nous passons l'url du master Spark en paramètre au script start-slave.sh. Pour confirmer si le worker est correctement lié au master, ouvrir le lien dans un navigateur.
Affectation de ressources au Worker Spark
Par défaut, lorsque vous démarrez une instance de travail, utilise tous les cœurs disponibles sur la machine. Cependant, pour des raisons pratiques, vous voudrez peut-être limiter le nombre de cœurs et la quantité de RAM allouée à chaque travailleur.
start-slave.sh étincelle://0.0.0.0:8082 -c 4 -m 512M
Ici, nous avons attribué 4 noyaux Oui 512 Mo RAM au travailleur. Confirmons cela en redémarrant l'instance de travail.
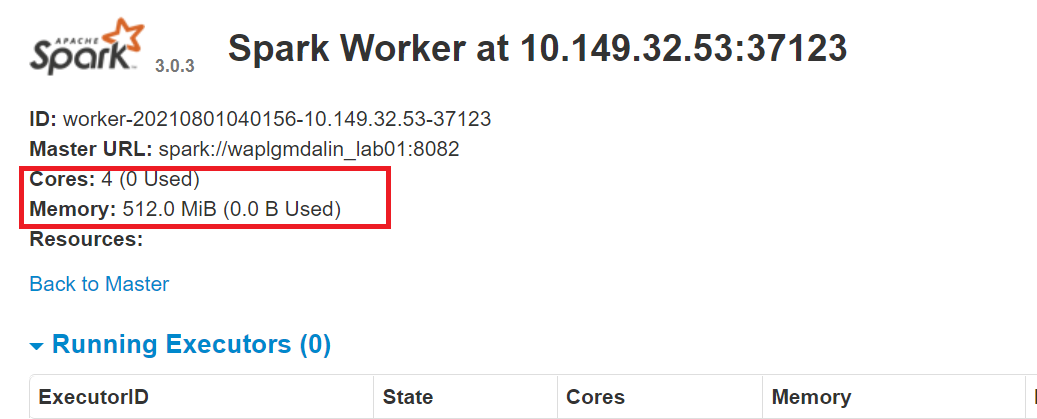
Pour arrêter le maître instance démarrée en exécutant le script ci-dessus, Cours:
stop-master.shPour arrêter un nœud de calcul en cours d'exécution traiter, entrez cette commande:
stop-slave.shConfigurer la connexion MS SQL
Dans cet ETL PySpark, nous allons nous connecter à une instance de serveur MS SQL en tant que système source et exécuter des requêtes SQL pour obtenir des données. Ensuite, nous devons d'abord télécharger les dépendances nécessaires.
Téléchargez le fichier jar MS-SQL (mssql-jdbc-9.2.1.jre8) depuis le site Web de Microsoft et copiez-le dans le répertoire “/ opter / étincelle / bocaux”.
https://www.microsoft.com/en-us/download/details.aspx?id=11774
Téléchargez le fichier jar Spark SQL (chispa-sql_2.12-3.0.3.jar) depuis le site de téléchargement Apache et copiez-le dans le répertoire '/ opt / étincelle / pots ».
https://jar-download.com/?search_box=org.apache.spark+spark.sql
Modifier le .profil, ajouter les classes PySpark et Py4J au chemin Python:
export PYTHONPATH=$SPARK_HOME/python/:$CHEMIN PYTHON export PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:$CHEMIN PYTHON
Configurer la connexion AWS S3
Pour se connecter à une instance AWS, nous devons télécharger les trois fichiers jar et les copier dans le répertoire “/ opter / étincelle / bocaux”. Vérifiez la version de Hadoop que vous utilisez actuellement. Vous pouvez l'obtenir à partir de n'importe quel pot présent dans votre installation Spark. Si la version Hadoop est 2.7.4, télécharger le fichier jar pour la même version. Kit de développement logiciel pour Java, vous devez télécharger la même version qui a été utilisée pour générer le package Hadoop-aws.
Assurez-vous que les versions sont les plus récentes.
- hadoop-aws-2.7.4.jar
- aws-java-sdk-1.7.4.jar
- jets3t-0.9.4.pot
sudo wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk/1.11.30/aws-java-sdk-1.7.4.jar sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/2.7.3/hadoop-aws-2.7.4.jar sudo wget https://repo1.maven.org/maven2/net/java/dev/jets3t/jets3t/0.9.4/jets3t-0.9.4.jar
Développement Python
Créez un répertoire de travail appelé 'scripts’ pour stocker tous les scripts python et fichiers de configuration. Créer un fichier appelé “sqlfile.py” qui contiendra les requêtes SQL que nous voulons exécuter sur le serveur de base de données distant.
vi sqlfile.py
Insérez la requête SQL suivante dans le fichier sqlfile.py qui extraira les données. Avant cette étape, il est recommandé de lancer un test de cette requête SQL sur le serveur pour avoir une idée du nombre d'enregistrements renvoyés.
requête1 = """(sélectionner * à partir des données de vente où date >= '2021-01-01' et statut="Complété")"""
Enregistrer et quitter le fichier.
Créez un fichier de configuration appelé “config.ini” qui stockera les identifiants de connexion et les paramètres de la base de données.
vi config.ini
Insérez les paramètres de connexion AWS et MSSQL suivants dans le fichier. Notez que nous avons créé des sections distinctes pour stocker les paramètres de connexion AWS et MSSQL. Vous pouvez créer autant d'instances de connexion DB que nécessaire, tant que chacun est conservé dans sa propre section (mssql1, mssql2, aws1, aws2, etc.).
[aws]
ACCESS_KEY=BBIYYTU6L4U47BGGG&^CF SECRET_KEY=Uy76BBJabczF7h6vv+BFssqTVLDVkKYN/f31puYHtG BUCKET_NAME=s3-nom-seau DIRECTORY=répertoire-données-ventes [mssql] URL = jdbc:serveur SQL://PPPP24888S08YTA.APAC.PAD.COMPANY-DSN.COM:1433;databaseName=Transactions base de données = Transactions utilisateur = MSSQL-USER mot de passe = MSSQL-Mot de passe dbtable = ventes-données nom de fichier = extrait_données.csv
Enregistrer et quitter le fichier.
Créez un script Python appelé “Extraction de données.py”.
Importer des bibliothèques pour Spark et Boto3
Spark est implémenté dans Scala, un langage qui s'exécute dans la JVM, mais puisque nous travaillons avec Python, nous utiliserons PySpark. La version actuelle de PySpark est 2.4.3 et ça marche avec python 2.7, 3.3 et plus haut. Vous pouvez considérer PySpark comme un conteneur basé sur Python au-dessus de l'API Scala.
Ici, Kit de développement logiciel AWS pour Python (Boto3) pour créer, configurer et gérer les services AWS, comme Amazon EC2 et Amazon S3. Le SDK fournit une API orientée objet, ainsi qu'un accès de bas niveau aux services AWS.
Importer les bibliothèques Python pour démarrer une session Spark, query1 de sqlfile.py et boto3.
à partir de pyspark.sql importer SparkSession Importer un arrêt importer le système d'exploitation importation globale importer boto3 à partir de la requête d'importation sqlfile1 de configparser importer ConfigParser
Créer une session Spark
SparkSession fournit un point d'entrée unique pour interagir avec le moteur Spark sous-jacent et permet la programmation Spark avec les API DataFrame et Dataset. Plus important encore, il restreint le nombre de concepts et de builds avec lesquels un développeur doit travailler lorsqu'il interagit avec Spark.. En ce point, vous pouvez utiliser le ‘Étincelle – étincelle’ variable comme objet d'instance pour accéder à vos méthodes et instances publiques pendant la durée de votre travail Spark. Donnez un nom à l'application.
Nom de l'application = "Exemple d'ETL PySpark - via MS-SQL JDBC"
maître = "local"
étincelle = SparkSession
.constructeur
.Maître(Maître)
.nom de l'application(nom de l'application)
.configuration("spark.driver.extraClassPath","/opt/spark/jars/mssql-jdbc-9.2.1.jre8.jar")
.obtenirOuCréer()
Lire le fichier de configuration
Nous avons stocké les paramètres dans un fichier “config.ini” séparer les paramètres statiques du code Python. Cela permet d'écrire un code plus propre sans aucun codage. Module Este implémente un langage de configuration de base qui fournit une structure similaire à ce que nous voyons dans les fichiers Microsoft Windows .ini.
URL = config.get('mssql-onprem', 'URL')
utilisateur = config.get('mssql-onprem', 'utilisateur')
mot de passe = config.get('mssql-onprem', 'le mot de passe')
dbtable = config.get('mssql-onprem', 'dbtable')
nom de fichier = config.get('mssql-onprem', 'nom de fichier')
ACCESS_KEY=config.get('aws', 'CLÉ D'ACCÈS')
SECRET_KEY=config.get('aws', 'CLEF SECRÈTE')
BUCKET_NAME=config.get('aws', "BUCKET_NAME")
RÉPERTOIRE=config.get('aws', 'ANNUAIRE')
Exécuter l'extraction de données
Spark inclut une source de données qui peut lire les données d'autres bases de données à l'aide de JDBC. Exécutez SQL sur la base de données distante en vous connectant à l'aide du pilote JDBC Microsoft SQL Server et des paramètres de connexion. En option “mettre en doute”, si tu veux lire tout un tableau, fournir le nom de la table; au contraire, si vous voulez exécuter la requête select, préciser la même chose. Les données renvoyées par SQL sont stockées dans une trame de données Spark.
jdbcDF = spark.read.format("jdbc")
.option("URL", URL)
.option("mettre en doute", requête2)
.option("utilisateur", utilisateur)
.option("le mot de passe", le mot de passe)
.option("conducteur", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.charge()
jdbcDF.show(5)
Enregistrer le bloc de données en tant que fichier CSV
La trame de données peut être stockée sur le serveur sous forme de fichier. Archive CSV. Quelque chose, cette étape est facultative au cas où vous voudriez écrire la trame de données directement dans un compartiment S3, cette étape peut être sautée. PySpark, par défaut, créer plusieurs partitions, pour éviter cela, nous pouvons l'enregistrer en tant que fichier unique en utilisant la fonction de fusion (1). Ensuite, nous déplaçons le fichier dans le dossier de sortie désigné. En option, supprimer le répertoire de sortie créé si vous souhaitez simplement enregistrer la trame de données dans le compartiment S3.
chemin="sortir"
jdbcDF.coalesce(1).écriture.option("entête","vrai").option("SEP",",").mode("écraser").csv(chemin)
Shutil.move(glob.glob(os.getcwd() + '/' + chemin + '/' + r '*.csv')[0], os.getcwd()+ '/' + nom de fichier )
Shutil.rmtree(os.getcwd() + '/' + chemin)
Copier la trame de données dans le compartiment S3
Premier, créer une 'session boto3’ en utilisant l'accès AWS et les valeurs de clé secrète. Récupérez les valeurs du compartiment et du sous-répertoire S3 où vous souhaitez télécharger le fichier. Les Téléverser un fichier() accepte un nom de fichier, un nom de compartiment et un nom d'objet. La méthode gère les gros fichiers en les divisant en morceaux plus petits et en chargeant chaque morceau en parallèle.
session = boto3.Session(
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
)
bucket_name=BUCKET_NAME
s3_output_key=RÉPERTOIRE + nom de fichier
s3 = session.ressource('s3')
# Nom de fichier - Fichier à télécharger
# Baquet - Bucket à télécharger (le répertoire de niveau supérieur sous AWS S3)
# Clé - Nom de l'objet S3 (peut contenir des sous-répertoires). Si non spécifié alors file_name est utilisé
s3.meta.client.upload_file(Nom de fichier=nom de fichier, Seau=nom_seau, Clé=s3_output_key)
Nettoyage des fichiers
Après avoir téléchargé le fichier dans le compartiment S3, supprimer tous les fichiers laissés sur le serveur; au contraire, j'ai renvoyé une erreur.
si os.path.isfile(nom de fichier):
supprime(nom de fichier)
autre:
imprimer("Erreur: %fichier s introuvable" % nom de fichier)
conclusion
Apache Spark est un framework informatique en cluster open source avec des capacités de traitement en mémoire. Il a été développé dans le langage de programmation Scala. Spark offre de nombreuses fonctionnalités et capacités qui en font un framework Big Data efficace. Performance et vitesse sont les principaux avantages de Spark. Vous pouvez charger les téraoctets de données et les traiter en douceur en mettant en place un cluster multi-nœuds. Cet article donne une idée de la façon d'écrire un ETL basé sur Python.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





