introduction
La mayoría de ustedes habría escuchado cosas emocionantes que suceden usando el l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé.... J’aurais également entendu dire que le Deep Learning a besoin de beaucoup de matériel.. J’ai vu des gens former un modèle simple d’apprentissage profond pendant des jours sur leurs ordinateurs portables. (généralement sans GPU), Ce qui donne l’impression que l’apprentissage profond nécessite de grands systèmes pour fonctionner.
Malgré cela, Ce n’est que partiellement vrai et crée un mythe autour de l’apprentissage profond qui crée un obstacle pour les débutants.. De nombreuses personnes m’ont demandé quel type de matériel serait le meilleur pour l’apprentissage profond.. Avec ce post, j’espère répondre.
Noter: Je suppose que vous avez une compréhension fondamentale des concepts d’apprentissage profond. Si ce n'est pas comme ça, Vous devriez lire cet article.
Table des matières
- Fait # 101: Besoins de DL
beaucoupMatériel - Formation à un modèle de deep learning
- Comment former votre modèle plus rapidement?
- CPU vs GPU
- Un bref historique des GPU: Comment en sommes-nous arrivés là ??
- Quel GPU utiliser aujourd’hui?
- L’avenir s’annonce passionnant
Fait # 101: Besoins d’apprentissage profond beaucoup Matériel
Quand j’ai été initié à l’apprentissage profond, Je pensais que l’apprentissage profond avait nécessairement besoin d’un grand centre de données pour fonctionner., et les « Experts en apprentissage profond » Ils se sont assis dans leurs salles de contrôle pour faire fonctionner ces systèmes..

C’est parce que dans chaque livre que j’ai mentionné ou dans chaque discours que j’ai entendu., L’auteur ou le conférencier commente toujours que l’apprentissage profond nécessite beaucoup de puissance de calcul pour fonctionner.. Mais quand j’ai construit mon premier modèle de deep learning sur ma petite machine, J’étais soulagée!! Je n’ai pas besoin de prendre le contrôle de Google pour être un expert en deep 😀 learning
C’est une erreur courante à laquelle tous les débutants sont confrontés lorsqu’ils plongent dans l’apprentissage profond.. Bien qu’il soit vrai que l’apprentissage profond nécessite un matériel considérable pour fonctionner efficacement., Vous n’avez pas besoin qu’il soit infini pour accomplir votre tâche. Vous pouvez même exécuter des modèles d’apprentissage profond sur votre ordinateur portable!!
Juste une petite clause de non-responsabilité; plus votre système est petit, Il faudra plus de temps pour obtenir un modèle formé qui fonctionne suffisamment bien. Simplement, Cela peut ressembler à ceci:

Posons-nous une question simple; Pourquoi nous avons besoin de plus de matériel pour le deep learning?
La solution est simple, L’apprentissage profond est un algorithme – Une version logicielle. Definimos una neuronal rougeLes réseaux de neurones sont des modèles computationnels inspirés du fonctionnement du cerveau humain. Ils utilisent des structures appelées neurones artificiels pour traiter et apprendre des données. Ces réseaux sont fondamentaux dans le domaine de l’intelligence artificielle, permettant des avancées significatives dans des tâches telles que la reconnaissance d’images, Traitement du langage naturel et prédiction de séries temporelles, entre autres. Leur capacité à apprendre des motifs complexes en fait des outils puissants.. artificial en nuestro lenguaje de programación favorito que posteriormente se convertiría en un conjunto de comandos que se ejecutan en la computadora.
Si vous deviez deviner quels composants de réseau neuronal vous pensez nécessiteraient des ressources matérielles intenses, Quelle serait votre réponse??
Certains des candidats que j’ai en tête sont:
- Prétraitement des données d’entrée
- Formation au modèle de deep learning
- Stockage du modèle d’apprentissage profond formé
- Déploiement du modèle
Parmi tous ces, La formation du modèle d’apprentissage profond est la tâche la plus intensive. Voyons en détail pourquoi c’est le cas.
Formation à un modèle de deep learning
Lorsque vous entraînez un modèle de deep learning, Deux opérations principales sont effectuées:
- Advance Pass
- Balayez vers l’arrière
Dans le pas en avant, l’entrée passe par le réseau neuronal et, après le traitement de l’entrée, Une sortie est générée. Dans le col arrière, Nous mettons à jour les poids du réseau neuronal en fonction de l’erreur que nous obtenons dans la passe avant.
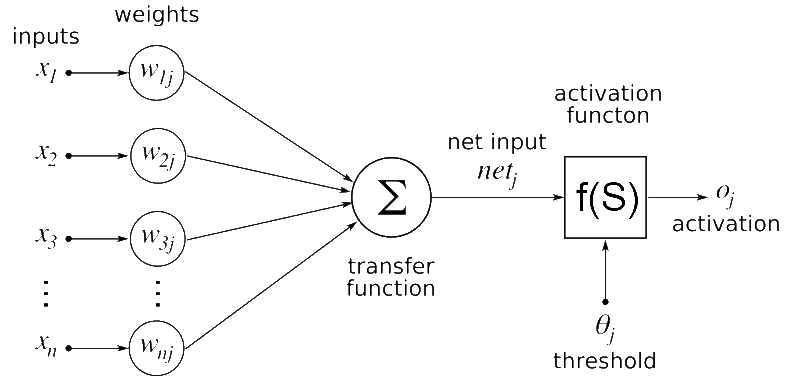
Les deux opérations sont essentiellement des multiplications matricielles.. Une simple multiplication matricielle peut être représentée avec l’image suivante
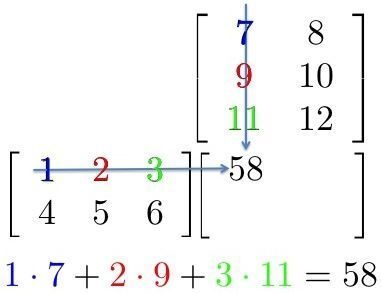
Ici, Nous pouvons voir que chaque élément d’une ligne de la première matrice est multiplié par une colonne de la deuxième matrice. Ensuite, dans un réseau neuronal, Nous pouvons considérer la première matrice comme entrée dans le réseau neuronal, et la deuxième matrice peut être considérée comme des poids de réseau.
Cela semble être une tâche simple.. À présent, Juste pour vous donner une idée du type d’échelle d’apprentissage profond: VGG16 (ongle convolucional neuronal rougeRéseaux de neurones convolutifs (CNN) sont un type d’architecture de réseau neuronal conçu spécialement pour le traitement de données avec une structure en grille, comme images. Ils utilisent des couches de convolution pour extraire des caractéristiques hiérarchiques, Ce qui les rend particulièrement efficaces dans les tâches de reconnaissance et de classification des formes. Grâce à sa capacité à apprendre à partir de grands volumes de données, Les CNN ont révolutionné des domaines tels que la vision par ordinateur.. de 16 Couches cachées souvent utilisées dans les applications de deep learning) A~ 140 millones de paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet....; Aussi connu sous le nom de poids et biais. Maintenant, pensez à toutes les multiplications matricielles que vous auriez à faire pour passer une seule entrée à ce réseau!! Il faudrait des années pour former de tels systèmes si nous adoptons des approches traditionnelles..
Comment entraîner votre réseau neuronal plus rapidement?
Nous avons vu que la partie informatique intensive du réseau neuronal est composée de multiples multiplications matricielles.. Ensuite, Comment pouvons-nous le faire plus rapidement?
Nous pouvons simplement le faire en faisant toutes les opérations en même temps au lieu de le faire l’une après l’autre.. Brièvement, c’est pourquoi nous utilisons des GPU (Unités de traitement graphique) au lieu d’un processeur (Unité centrale de traitement) pour former un réseau neuronal.
Pour vous donner une certaine intuition, nous remontons à l’histoire lorsque nous avons prouvé que les GPU étaient meilleurs que les CPU pour la tâche.
Avant le boom de l’apprentissage profond, Google avait un système extrêmement puissant pour faire son traitement., qu’ils avaient spécialement conçus pour former d’énormes réseaux. Ce système était monstrueux et avait un coût total de $ 5 mille millions, avec plusieurs groupes de CPU.
À présent, los investigadores de Stanford construyeron el mismo sistema en términos de computación para entrenar sus redes profundasLas redes profundas, también conocidas como redes neuronales profundas, son estructuras computacionales inspiradas en el funcionamiento del cerebro humano. Estas redes están compuestas por múltiples capas de nodos interconectados que permiten aprender representaciones complejas de datos. Son fundamentales en el ámbito de la inteligencia artificial, especialmente en tareas como el reconocimiento de imágenes, procesamiento de lenguaje natural y conducción autónoma, mejorando así la capacidad de las máquinas para comprender y... usando GPU. Et devinez quoi; Réduction des coûts à seulement $ 33K! Ce système a été construit avec des GPU et a fourni la même puissance de traitement que le système de Google.. Assez impressionnant, vérité?
| Stanford | ||
| Nombre de cœurs | Processeur 1K = cœurs 16K | 3GPU = 18K cœurs |
| Coût | $ 5 mille millions | $ 33 mille |
| Tiempo de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... | la semaine | la semaine |
Nous pouvons voir que les GPU gouvernent. Mais, quelle est exactement la différence entre un CPU et un GPU?
Différence entre CPU et GPU
Comprendre la différence, Nous prenons une analogie classique qui explique intuitivement la différence..
Supposons que vous deviez transférer des marchandises d’un endroit à un autre. Vous avez la possibilité de choisir entre une Ferrari et un camion cargo.
Ferrari serait extrêmement rapide et vous aiderait à transférer un lot de marchandises en un rien de temps.. Mais la quantité de marchandises qu’il peut transporter est faible et la consommation de carburant serait très élevée..
Un camion de fret serait lent et prendrait beaucoup de temps à transférer des marchandises. Mais la quantité de marchandises qu’il peut transporter est plus élevée par rapport à Ferrari.. En même temps, est plus économe en carburant, donc l’utilisation est plus faible.
Ensuite, Lequel choisiriez-vous pour votre travail?
Évidemment, Tout d’abord, vous verrez quelle est la tâche; Si vous devez aller chercher votre petite amie de toute urgence, Je choisirais certainement une Ferrari plutôt qu’un camion cargo. Mais si vous déménagez votre maison, utiliserait un camion de fret pour transférer les meubles.
Voici comment vous différencieriez techniquement les deux:

Voici une autre vidéo qui clarifierait davantage votre concept.
Noter: Le GPU est principalement utilisé pour les jeux complexes et les simulations. Ces tâches et principalement des calculs graphiques, donc GPU est une unité de traitement graphique. Si le GPU est utilisé pour un traitement non graphique, sont appelés GPGPU: Unité de traitement graphique à usage général
Un bref historique des GPU: Comment en sommes-nous arrivés là ??
À présent, vous vous demandez peut-être pourquoi les GPU sont si chauds en ce moment.. Voyageons à travers une brève histoire du développement GPU.
Simplement, Un GPGPU est une configuration de programmation parallèle impliquant des GPU et des CPU qui peuvent traiter et analyser des données d’une manière équivalente à une image ou à une autre manière graphique.. Les GPU ont été conçus pour un traitement graphique meilleur et plus général, Mais on a découvert plus tard qu’ils étaient bien adaptés au calcul scientifique.. En effet, la plupart des traitements graphiques impliquent l’application d’opérations sur de grandes baies..
L’utilisation de GPGPU pour le calcul scientifique a commencé en 2001 avec la mise en œuvre de la multiplication matricielle. L’un des premiers algorithmes courants à être implémenté plus rapidement sur les GPU a été la factorisation LU dans 2005. Mais, en ce moment, Les chercheurs devaient coder tous les algorithmes sur un GPU et devaient comprendre le traitement graphique de bas niveau..
Dans 2006, Nvidia a introduit un langage CUDA de haut niveau, qui vous aide à écrire des programmes à partir de processeurs graphiques dans un langage de haut niveau. C’était probablement l’un des changements les plus importants dans la façon dont les chercheurs interagissent avec les GPU..
Quel GPU utiliser aujourd’hui?
Ici, je vais rapidement vous donner quelques connaissances techniques avant d’acheter un GPU pour le deep learning.
Organiser 1:
La première chose que vous devez déterminer est le type de ressource dont vos tâches ont besoin.. Si vos tâches seront petites ou peuvent s’intégrer dans un traitement séquentiel complexe, Vous n’avez pas besoin d’un gros système pour fonctionner. Vous pouvez même ignorer complètement l’utilisation du GPU. Pour cela, Si vous envisagez de travailler principalement dans d'« autres » domaines / Algorithmes ML, vous n’avez pas nécessairement besoin d’un GPU.
Organiser 2:
Si votre tâche est un peu intensive et que vous disposez de données gérables, un GPU raisonnable serait un meilleur choix pour vous. J’utilise généralement mon ordinateur portable pour travailler sur des problèmes de jouets., qui a un GPU légèrement obsolète (une Nvidia GT 740M de 2 Go). Avoir un ordinateur portable avec des GPU m’aide à exécuter des choses partout où je vais. Il existe des ordinateurs portables haut de gamme (et devraient être lourds) avec Nvidia GTX 1080 (une VRAM de 8 FR) que vous pouvez interroger à la fin.
Organiser 3:
Si vous travaillez régulièrement sur des problèmes complexes ou si vous êtes une entreprise qui tire parti de l’apprentissage profond, probablemente sería mejor que creara un sistema de aprendizaje profundo o utilizara un servicio en la nubeLe "servicio en la nube" se refiere a la entrega de recursos informáticos a través de Internet, permitiendo a los usuarios acceder a almacenamiento, procesamiento y aplicaciones sin necesidad de infraestructura física local. Este modelo ofrece flexibilidad, escalabilidad y ahorro de costos, ya que las empresas solo pagan por lo que utilizan. En outre, facilita la colaboración y el acceso a datos desde cualquier lugar, mejorando la eficiencia operativa en diversas... como AWS o FloydHub. Chez DataPeaker, nous créons un système d’apprentissage profond pour nous, pour lesquels nous partageons nos spécifications. Voici l’article.
Organiser 4:
Si vous êtes Google, Vous aurez probablement besoin d’un autre centre de données à maintenir. Blagues à part, Si vos devoirs sont à plus grande échelle que d’habitude et que vous avez assez d’argent de poche pour couvrir les coûts; vous pouvez choisir pour un grappeUn cluster est un ensemble d’entreprises et d’organisations interconnectées qui opèrent dans le même secteur ou la même zone géographique, et qui collaborent pour améliorer leur compétitivité. Ces regroupements permettent le partage des ressources, Connaissances et technologies, favoriser l’innovation et la croissance économique. Les grappes peuvent couvrir une variété d’industries, De la technologie à l’agriculture, et sont fondamentaux pour le développement régional et la création d’emplois.... de GPU y hacer computación con múltiples GPU. En outre, certaines options pourraient être disponibles dans un proche avenir., TPU et FPGA plus rapides, Cela lui faciliterait la vie.
L’avenir s’annonce passionnant
Comme mentionné précédemment, Il y a beaucoup de recherche et de travail actif pour réfléchir à des alternatives pour accélérer l’informatique.. Google devrait introduire les unités de traitement Tensorflow (TPU) Plus tard cette année, Une accélération prometteuse au-dessus des GPU actuels.
Équivalent, Intel travaille à la création de FPGA plus rapides, qui peut accorder une plus grande flexibilité dans les prochains jours. En même temps, Les offres des fournisseurs de services cloud (par exemple, AWS) Ils sont également en augmentation.. Nous verrons chacun d’entre eux émerger dans les mois à venir..
Remarques finales
Dans ce billet, Nous avons couvert les motivations de l’utilisation d’un GPU pour les applications d’apprentissage profond et avons vu comment les choisir pour votre tâche.. J’espère que cet article vous a été utile. Si vous avez des questions spécifiques sur le sujet, N’hésitez pas à commenter ci-dessous ou à demander sur portail de discussion.





