Cet article a été publié dans le cadre de la Blogathon sur la science des données.
introduction

Dans ce billet, Nous essaierons d’atténuer cela en utilisant le apprentissage par renforcementL’apprentissage par renforcement est une technique d’intelligence artificielle qui permet à un agent d’apprendre à prendre des décisions en interagissant avec un environnement. Par le biais de commentaires sous forme de récompenses ou de punitions, L’agent optimise son comportement pour maximiser les récompenses accumulées. Cette approche est utilisée dans une variété d’applications, Des jeux vidéo à la robotique en passant par les systèmes de recommandation, se démarquant par sa capacité à apprendre des stratégies complexes.....
Techniques que nous pouvons utiliser pour prédire les cours des actions
Comme il s’agit d’une prédiction de valeurs continues, Tout type de technique de régression peut être utilisé:
- La régression linéaire vous aidera à prédire les valeurs continues
- Les modèles de séries chronologiques sont des modèles qui peuvent être utilisés pour des données temporelles.
- ARIMA est l’un de ces modèles qui est utilisé pour prédire les prédictions futuristes associées à la météo.
- LSTM est également l’une de ces techniques qui a été utilisée pour les prévisions de cours des actions. LSTM fait référence à la mémoire à long terme et utilise des réseaux neuronaux pour prédire des valeurs continues. Les LSTM sont très puissants et sont connus pour conserver la mémoire à long terme.
Malgré cela, Il existe une autre technique qui peut être utilisée pour les prédictions du cours des actions et c’est l’apprentissage par renforcement.
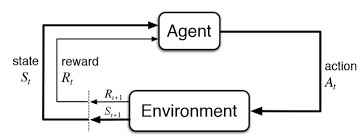
Qu'est-ce que l'apprentissage par renforcement?
L’apprentissage par renforcement est un autre type d’apprentissage automatique en même temps que l’apprentissage enseignement superviséL’apprentissage supervisé est une approche d’apprentissage automatique dans laquelle un modèle est formé à l’aide d’un ensemble de données étiquetées. Chaque entrée du jeu de données est associée à une sortie connue, permettre au modèle d’apprendre à prédire les résultats pour de nouvelles entrées. Cette méthode est largement utilisée dans des applications telles que la classification d’images, Reconnaissance vocale et prédiction de tendances, soulignant son importance dans... et sans surveillance. Il s’agit d’un système d’apprentissage basé sur un agent dans lequel l’agent effectue des actions dans un environnement où l’objectif est de maximiser l’inscription. L’apprentissage par renforcement n’a pas besoin d’utiliser des données étiquetées en tant qu’apprentissage supervisé.
L’apprentissage par renforcement fonctionne très bien avec moins de données historiques. Il utilise la fonction value et la calcule en fonction de la politique décidée pour cette action.
L’apprentissage par renforcement est modélisé comme une procédure de décision de Markov (MDP):
-
Un environnement E et des états d’agent S
-
Un ensemble d’actions menées par l’agent.
-
P (s, s ‘) => P (St + 1 = s’ | st = s, at = a) est la probabilité de transition d’un état ‘
-
R (s, s ‘): Récompense immédiate pour toute action
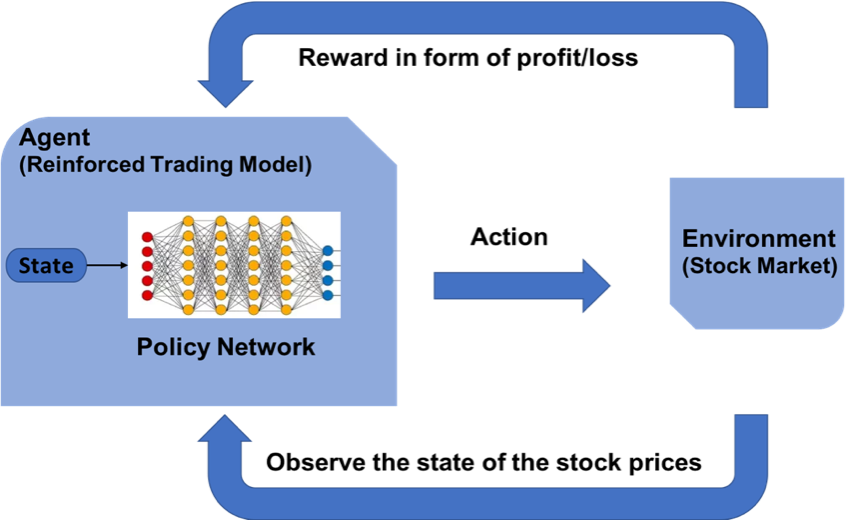
Comment prédire les cours des actions à l’aide de l’apprentissage par renforcement ??
Le concept d’apprentissage par renforcement peut être appliqué à la prévision du cours d’une action spécifique, puisqu’il utilise les mêmes principes fondamentaux d’exiger des données historiques mineures, Travailler sur un système basé sur des agents pour prédire des rendements plus élevés en fonction de l’environnement actuel. Nous allons voir un exemple de prédiction du prix d’une action pour une certaine action en suivant le modèle d’apprentissage par renforcement. Il utilise le concept d’apprentissage Q expliqué plus en détail.
Les étapes de conception d’un modèle d’apprentissage par renforcement sont les suivantes:
- Importation de bibliothèques
- Créez l’agent qui prendra toutes les décisions.
- Définir les fonctions de base pour la mise en forme des valeurs, Fonction sigmoïde, Lire le fichier de données, etc.
- Former l’agent
- Examiner les performances de l’agent
Établir l’environnement d’apprentissage amélioré
MDP pour la prévision du cours de l’action:
- Agent: un agent A travaillant dans l’environnement E
- action – Acheter / Commercialiser / Maintenir
- États: Valeurs des données
- Récompenses: Bénéfices / pertes
Le rôle de Q – Apprentissage
Q-learning est un algorithme d’apprentissage par renforcement sans modèle permettant de connaître la qualité des actions et d’indiquer à un agent quelle action entreprendre dans quelles circonstances. Le Q-learning trouve une politique optimale dans le sens de maximiser la valeur attendue de la récompense totale dans n’importe quelle étape successive, À partir de l’état actuel.
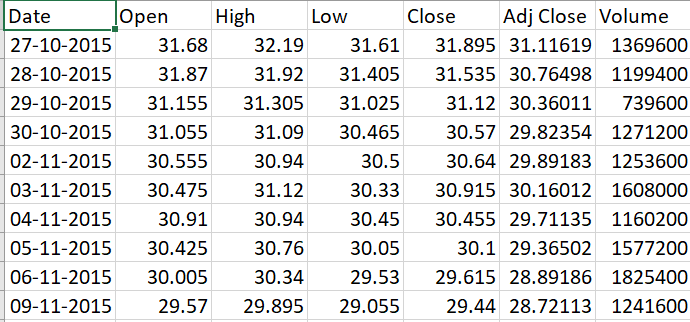
Collecte de données
-
Aller à Yahoo Finance
-
Tapez le nom de l’entreprise, par exemple. Banc HDFC
-
Sélectionnez la période pour, par exemple, 5 ans
-
Cliquez sur Télécharger pour télécharger le fichier CSV
Déployons notre modèle en Python
Importation de bibliothèques
Pour créer le modèle d’apprentissage par renforcement, importer les librairies Python indispensables à la modélisation des couches de la neuronal rougeLes réseaux de neurones sont des modèles computationnels inspirés du fonctionnement du cerveau humain. Ils utilisent des structures appelées neurones artificiels pour traiter et apprendre des données. Ces réseaux sont fondamentaux dans le domaine de l’intelligence artificielle, permettant des avancées significatives dans des tâches telles que la reconnaissance d’images, Traitement du langage naturel et prédiction de séries temporelles, entre autres. Leur capacité à apprendre des motifs complexes en fait des outils puissants.. et la librairie NumPy pour certaines opérations de base.
import keras
from keras.models import Sequential
from keras.models import load_model
from keras.layers import Dense
from keras.optimizers import Adam
import math
import numpy as np
import random
from collections import deque
Création de l’agent
Le code de l’agent commence par quelques initialisations de base pour les différents paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet..... Certaines variables statiques sont définies comme gamma, Epsilon, epsilon_min et epsilon_decay. Il s’agit de valeurs seuils constantes qui sont utilisées pour piloter l’ensemble de la procédure d’achat et de vente d’actions et maintenir les paramètres calmes. Ces valeurs minimales et de chute servent de valeurs de seuil dans la distribution normale.
L’agent conçoit le modèle de réseau de neurones en couches pour effectuer les actions d’achat, vente ou conservation. Ce type d’action s’effectue en observant votre prédiction précédente ainsi que l’état de l’environnement actuel. La méthode de l’acte est utilisée pour prédire la prochaine action à entreprendre. Si la mémoire se remplit, il existe une autre méthode appelée expReplay conçue pour réinitialiser la mémoire.
Agent de classe:
def __init__(soi, state_size, is_eval=Faux, nom_modèle=""):
self.state_size = state_size # normalized previous days
self.action_size = 3 # S’asseoir, acheter, sell
self.memory = deque(maxlen=1000)
self.inventory = []
self.model_name = model_name
self.is_eval = is_eval
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.model = load_model(nom du modèle) si is_eval autre self._model()
défendre _model(soi):
modèle = Séquentiel()
model.ajouter(Dense(unités=64, input_dim=self.state_size, activation="reprendre"))
model.ajouter(Dense(unités=32, activation="reprendre"))
model.ajouter(Dense(unités=8, activation="reprendre"))
model.ajouter(Dense(self.action_size, activation="linéaire"))
modèle.compile(perte ="mse", optimiseur=Adam(lr=0.001))
return model
def act(soi, Etat):
si ce n’est pas self.is_eval et random.random()<= self.epsilon:
renvoyer random.randrange(self.action_size)
options = self.model.predict(Etat)
retour np.argmax(Options[0])
def expReplay(soi, taille du lot):
mini_batch = []
l = len(self.memory)
pour moi à portée(je - taille du lot + 1, je):
mini_batch.append(self.memory[je])
pour l’état, action, récompense, next_state, Fait en mini_batch:
target = reward
if not done:
Objectif = Récompense + self.gamma * np.amax(auto.modèle.prédire(next_state)[0])
target_f = self.model.predict(Etat)
target_f[0][action] = target
self.model.fit(Etat, target_f, époques=1, verbeux=0)
si self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
Définir les fonctions de base
Le formatprice () est écrit pour structurer le format de la monnaie. GetStockDataVec () apportera les données boursières à Python. Définir la fonction sigmoïde comme un calcul mathématique. GetState () est encodé de telle manière qu’il fournit l’état actuel des données.
def formatPrix(m):
revenir("-Rs." si n<0 autre "Rs.")+"{0:.2F}".format(abdos(m))
def getStockDataVec(clé):
VEC = []
lignes = ouvert(clé+".csv","r").lire().lignes de division()
pour ligne en lignes[1:]:
#imprimer(ligne)
#imprimer(flotter(ligne.split(",")[4]))
Voir Ajouter(flotter(ligne.split(",")[4]))
#imprimer(VEC)
return vec
def sigmoid(X):
revenir 1/(1+math.exp(-X))
def getState(Les données, t, m):
d = t - m + 1
bloc = données[ré:t + 1] si d >= 0 else -d * [Les données[0]] + Les données[0:t + 1] # pad with t0
res = []
pour moi à portée(m - 1):
res.append(sigmoïde(bloquer[je + 1] - bloquer[je]))
retourner np.array([res])
Formation de l’agent
En fonction de l’action prédite par le modèle, L’appel d’achat / Venta suma o resta dinero. Se entrena por medio de múltiples episodios que son los mismos que épocas en el l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé.... Ensuite, el modelo se guarda posteriormente.
import sys stock_name = input("Entrez stock_name, window_size, Episode_count") window_size = entrée() episode_count = entrée() stock_name = force(stock_name) window_size = int(window_size) episode_count = int(episode_count) agent = Agent(window_size) data = getStockDataVec(stock_name) l = len(Les données) - 1 taille_bat = 32 pour e dans la plage(episode_count + 1): imprimer("Épisode " + str(e) + "/" + str(episode_count)) state = getState(Les données, 0, window_size + 1) total_profit = 0 agent.inventaire = [] pour t dans la gamme(je): action = agent.acte(Etat) # sit next_state = getState(Les données, t + 1, window_size + 1) récompense = 0 si action == 1: # buy agent.inventory.append(Les données[t]) imprimer("Acheter: " + formatPrix(Les données[t])) action elif == 2 et len(agent.inventaire) > 0: # sell bought_price = window_size_price = agent.inventory.pop(0) Récompense = Max(Les données[t] - bought_price, 0) total_profit += données[t] - bought_price print("Vendre: " + formatPrix(Les données[t]) + " | Bénéfice: " + formatPrix(Les données[t] - bought_price)) done = Vrai si t == l - 1 else False agent.memory.append((Etat, action, récompense, next_state, Fait)) state = next_state if done: imprimer("--------------------------------") imprimer("Bénéfice total: " + formatPrix(total_profit)) imprimer("--------------------------------") si len(agent.mémoire) > taille du lot: agent.expReplay(taille du lot) si e % 10 == 0: agent.model.save(str(e))
Départ de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... à la fin du premier épisode:
Bénéfice total: Roupies 340,03
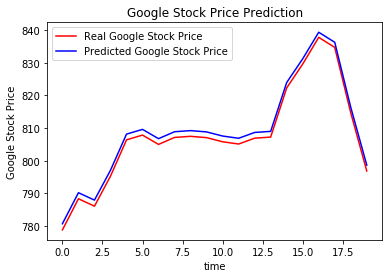
Évaluation du modèle
Une fois que le modèle a été formé sur la base des nouvelles données, Vous pourrez tester le modèle pour établir les gains / pertes qu’il offre. En conséquence, Vous pouvez examiner la crédibilité du modèle.
stock_name = entrée("Entrez Stock_name, Model_name")
model_name = entrée()
modèle = load_model(nom du modèle)
window_size = model.layers[0].input.shape.as_list()[1]
agent = Agent(window_size, Vrai, nom du modèle)
data = getStockDataVec(stock_name)
imprimer(Les données)
l = len(Les données) - 1
taille_bat = 32
state = getState(Les données, 0, window_size + 1)
imprimer(Etat)
total_profit = 0
agent.inventaire = []
imprimer(je)
pour t dans la gamme(je):
action = agent.acte(Etat)
imprimer(action)
# sit
next_state = getState(Les données, t + 1, window_size + 1)
récompense = 0
si action == 1: # buy
agent.inventory.append(Les données[t])
imprimer("Acheter: " + formatPrix(Les données[t]))
action elif == 2 et len(agent.inventaire) > 0: # sell
bought_price = agent.inventory.pop(0)
Récompense = Max(Les données[t] - bought_price, 0)
total_profit += données[t] - bought_price
print("Vendre: " + formatPrix(Les données[t]) + " | Bénéfice: " + formatPrix(Les données[t] - bought_price))
done = Vrai si t == l - 1 else False
agent.memory.append((Etat, action, récompense, next_state, Fait))
state = next_state
if done:
imprimer("--------------------------------")
imprimer(stock_name + " Bénéfice total: " + formatPrix(total_profit))
imprimer("--------------------------------")
imprimer ("Le bénéfice total est de:",formatPrix(total_profit))
Remarques finales
L’apprentissage par renforcement donne des résultats positifs pour les prédictions de valeur. Grâce à l’utilisation de l’apprentissage Q, Différentes expériences peuvent être réalisées. D’autres recherches sur l’apprentissage par renforcement permettront d’appliquer l’apprentissage par renforcement à un stade plus sûr.
Vous pouvez contacter





