Cet article a été publié dans le cadre du Blogathon sur la science des données
Les machines qui comprennent le langage me fascinent, et je me demande souvent quels algorithmes Aristote se serait habitué à construire une machine d'analyse rhétorique s'il en avait eu la chance. Si vous débutez en science des données, se lancer dans la PNL peut sembler compliqué, d'autant plus qu'il y a beaucoup d'avancées récentes dans le domaine. il est difficile de comprendre par où commencer.
Table des matières
1. Que peuvent comprendre les machines?
2.Projet 1: Mot nuage
3.Projet 2: Détection de spam
4.Projet 3: Analyse des sentiments
5. conclusion
Que peuvent comprendre les machines?
Alors qu'un ordinateur peut être assez bon pour trouver des modèles et résumer des documents, doit transformer les mots en nombres avant de les comprendre. Cette transformation est très nécessaire car les mathématiques ne fonctionnent pas très bien avec les mots et les machines. « ils apprennent » grâce aux maths. Avant la transformation des mots en nombres, le nettoyage des données est requis. Le nettoyage des données comprend la suppression de la ponctuation et des caractères spéciaux et leur modification de manière à les rendre plus cohérents et interprétables.
Projet 1: Mot nuage
1.Dépendances et import de données
Commencez par importer les dépendances et les données. Les données sont stockées sous forme de fichier de valeurs séparées par des virgules (CSV), donc je vais utiliser des pandas ‘ lire_csv () fonction pour l'ouvrir dans un DataFrame.
importer des pandas au format pd
importer sqlite3
importer regex en tant que re
importer matplotlib.pyplot en tant que plt
à partir de wordcloud importer WordCloud
#créer une trame de données à partir de csv
df = pd.read_csv('emails.csv')
df.head()
df.head()


2.Analyse exploratoire
Pour supprimer les lignes en double et définir des nombres de référence, il vaut mieux faire une analyse rapide des données. Ici, nous utilisons des pandas drop_duplicates pour supprimer les lignes en double.
imprimer("nombre de spams: " +str(longueur(df.loc[df.spam==1])))
imprimer("pas le nombre de spams: " +str(longueur(df.loc[df.spam==0])))
imprimer(df.forme)
df['pourriel'] = df['pourriel'].astype(entier)
df = df.drop_duplicates()
df = df.reset_index(en place = Faux)[['texte','pourriel']]
imprimer(df.forme)
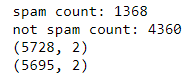
Compte et forme avant / après déduplication
Qu'est-ce qu'un nuage de mots?
Les nuages de mots permettent de comprendre facilement les fréquences des mots, c'est donc un moyen utile de visualiser les données textuelles. Les mots qui apparaissent les plus gros dans le cloud sont ceux qui apparaissent le plus fréquemment dans le texte de l'email. Les nuages de mots facilitent l'identification « mots-clés ».
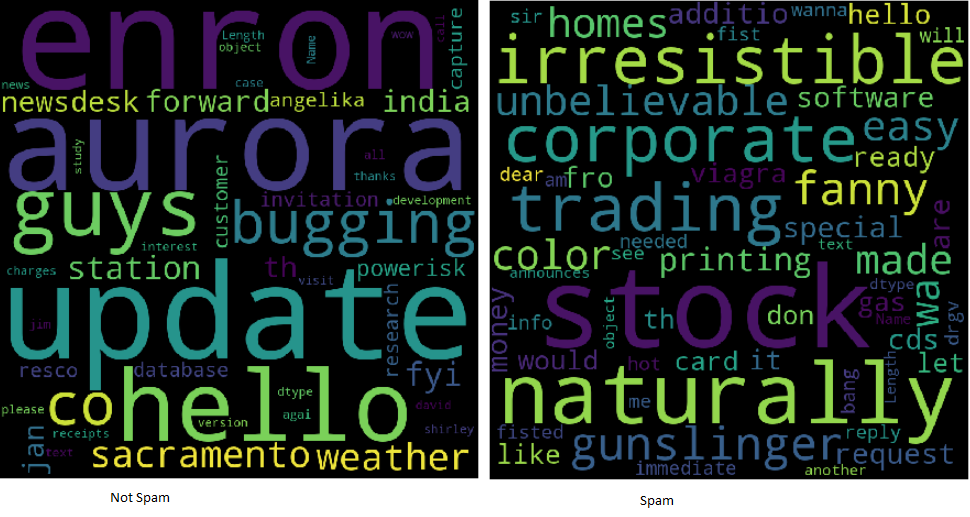
Exemples de nuages de mots
Tout le texte est en minuscules dans l'image de nuage de mots. Ne contient pas de ponctuation ni de caractères spéciaux. Le texte est maintenant appelé propre et prêt pour l'analyse. A l'aide d'expressions régulières, il est facile de nettoyer le texte à l'aide d'une boucle:
clean_desc = []
pour w dans la gamme(longueur(df.texte)):
desc = df['texte'][w].inférieur()
#supprimer la ponctuation
desc = re.sub('[^ a-zA-Z]', ' ', desc)
#supprimer les balises
desc=re.sub("</?.*?>"," <> ",desc)
#supprimer les chiffres et les caractères spéciaux
desc=re.sub("(ré|W)+"," ",desc)
clean_desc.append(desc)
#affecter les descriptions nettoyées au bloc de données
df['texte'] = clean_desc
df.head(3)

Remarquez ici que nous créons une liste vide clean_desc, alors on utilise un en boucle pour vérifier le texte ligne par ligne, le mettre en minuscule, supprimer la ponctuation et les caractères spéciaux et les ajouter à la liste. Ensuite, nous remplaçons la colonne de texte par les données de la liste clean_desc.
Pour les mots
Les mots vides sont les mots les plus courants comme « les » Oui « de ». Les supprimer du texte de l'e-mail permet de mettre au carré les mots fréquents les plus pertinents. L'élimination des mots vides peut être une technique courante !! Certaines bibliothèques Python comme NLTK sont préchargées avec une liste de mots vides, mais il est facile d'en former un à partir de zéro.
mots_arrêts = ['est','tu','ton','et', 'les', 'à', 'de', 'ou', 'JE', 'pour', 'faire', 'avoir', 'ne pas', 'ici', 'dans', 'je suis', 'ont', 'au', 'ré', 'Nouveau', 'matière']
Veuillez noter que j'inclus des mots liés aux e-mails, Quoi « ré » Oui « affaire ». C'est à l'analyste de voir quels mots doivent être inclus ou exclus. Parfois, il est avantageux d'incorporer tous les mots!
Construire le mot pourrait
Idéalement, il existe une bibliothèque python pour créer des nuages de mots. Il sera installé à l'aide de pip.
pip installer wordcloud
Lors de la construction du nuage de mots, es posible alinear varios paramètresLes "paramètres" sont des variables ou des critères qui sont utilisés pour définir, mesurer ou évaluer un phénomène ou un système. Dans divers domaines tels que les statistiques, Informatique et recherche scientifique, Les paramètres sont essentiels à l’établissement de normes et de standards qui guident l’analyse et l’interprétation des données. Leur sélection et leur manipulation correctes sont cruciales pour obtenir des résultats précis et pertinents dans toute étude ou projet.... como alto y ancho, mots vides et mots maximum. il est même possible de le façonner au lieu d'afficher le rectangle par défaut.
nuage de mots = nuage de mots(largeur = 800, hauteur = 800, background_color="le noir", mots vides = mots_arrêts, max_mots = 1000
, min_font_size = 20).produire(str(df1['texte']))
#tracer le nuage de mots
fig = plt.figure(taille de la figue = (8,8), couleur du visage = Aucun)
plt.imshow(mot nuage)
plt.axis('désactivé')
plt.show()
Pour enregistrer et afficher le nuage de mots. Matplotlib et show sont utilisés (). Peu importe qu'il s'agisse de spam, est le résultat de tous les enregistrements.

Poussez l'exercice encore plus loin en divisant le cadre d'informations et en créant des nuages de deux mots pour aider à analyser la différence entre les mots-clés utilisés dans le spam et non dans le spam..
Projet 2: Détection de spam
Considérez-le comme un problème de classification binaire, puisqu'un e-mail peut être un spam signalé par « 1 » o dans les spams signalés par « 0 ». Je souhaite créer un modèle d'apprentissage automatique capable d'identifier si un e-mail peut être un spam ou non. Je visite la bibliothèque Python Scikit-Learn utilisée pour explorer les algorithmes de tokenisation, vectorisation et classification statistique.

Importer des dépendances
Importer la fonctionnalité de Scikit-Learn dont nous aimerions modifier et modéliser les informations. Je vais utiliser CountVectorizer, train_test_split, modèles d'ensemble et quelques métriques.
de sklearn.feature_extraction.text importer CountVectorizer de sklearn.model_selection importer train_test_split de l'ensemble d'importation sklearn à partir de sklearn.metrics importer classification_report, score_précision
Transformer du texte en nombres
Dans le projet 1, le texte a été nettoyé. une fois que vous regardez un nuage de mots, notez qu'il s'agit principalement de mots simples. Plus le mot est gros, plus sa fréquence est élevée. Pour empêcher le nuage de mots de générer des phrases, le texte passe par un processus appelé tokenisation. est la méthode de division d'une phrase en mots individuels. Les mots individuels sont appelés jetons.
Avec CountVectorizer () de SciKit-Learn, il est facile de retravailler le corps du texte en une matrice clairsemée de nombres que l'ordinateur peut transmettre aux algorithmes d'apprentissage automatique. Pour simplifier le concept de vectorisation de comptage, imaginez que vous avez deux phrases:
Le chien est blanc
Le chat est noir
La conversion des phrases en un modèle spatial vectoriel les transformerait de telle sorte qu'il examine les mots de toutes les phrases, puis représente les mots de la phrase avec un nombre.
Le chien chat est blanc noir
Le chien est blanc = [1,1,0,1,1,0] Le chat est noir = [1,0,1,1,0,1] Nous pouvons également montrer cela en utilisant le code. Je vais ajouter une troisième phrase pour montrer qu'il compte les jetons. #liste de phrases texte = ["le chien est blanc", "le chat est noir", "le chat et le chien sont amis"] #instancier la classe cv = CountVectorizer() #tokeniser et construire du vocabulaire cv.fit(texte) imprimer(cv.vocabulaire_) #transformer le texte vecteur = cv.transformer(texte) imprimer(vecteur.toarray())
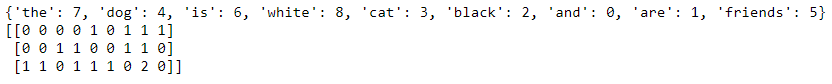
La matrice clairsemée du nombre de mots.
Notez que dans le dernier vecteur, vous verrez un 2 puisque le mot « les » apparaît deux fois. CountVectorizer compte les jetons et me permet de construire le tableau clairsemé contenant les mots transformés en nombres.
Méthode du sac de mots
Parce que le modèle ne prend pas en compte l'emplacement des mots et, à sa place, Il les mélange comme des jetons dans un jeu de scrabble, c'est ce qu'on appelle souvent la méthode du sac de mots. Je visite pour créer la matrice creuse, puis divisez les informations à l'aide de SK-learn train_test_split ().
text_vec = CountVectorizer().fit_transformer(df['texte']) X_train, X_test, y_train, y_test = train_test_split(text_vec, df['pourriel'], taille_test = 0.45, état_aléatoire = 42, aléatoire = vrai)
Remarquez que j'ai défini le tableau clairsemé text_vec sur X et le df['pourriel'] colonne à Y. Je mélange et prends une taille de test du 45%.
Le classificateur
Il est fortement recommandé d'expérimenter avec plusieurs classificateurs et de déterminer celui qui fonctionne le mieux pour ce scénario.. pendant cet exemple, J'utilise le modèle GradientBoostingClassifier () de la collection Scikit-Learn Ensemble.
classifier = ensemble.GradientBoostingClassifier( n_estimateurs = 100, #combien d'arbres de décision construire taux_apprentissage = 0.5, #taux d'apprentissage profondeur_max = 6 )
Chaque algorithme aura son propre ensemble de paramètres que vous pouvez modifier. c'est ce qu'on appelle le réglage des hyperparamètres. soumettre à la documentation pour en savoir plus sur chacun des paramètres utilisés dans les modèles.
Générer des prédictions
Finalement, nous ajustons les informations, nous appelons prédire et générons le rapport de classification. Lors de l'utilisation de classification_report (), facile de créer un rapport texte montrant la plupart des mesures de classement.
classificateur.fit(X_train, y_train) prédictions = classifier.predict(X_test) imprimer(classement_rapport(y_test, prédictions))
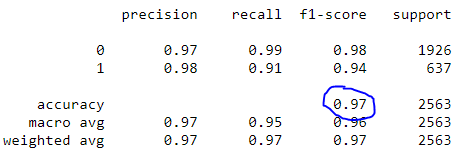
Rapport de classement
Notez que notre modèle atteint une précision de la 97%.
Projet 3: Analyse des sentiments
L'analyse des sentiments est, en outre, une sorte de problème de classement. Le texte est essentiellement en visite pour refléter un sentiment positif, neutre ou négatif. qui est perceptible en raison de la polarité du texte. Il est également possible de déterminer et de rendre compte de la subjectivité du texte! Il existe de nombreuses ressources intéressantes couvrant la spéculation derrière l'analyse des sentiments..
Au lieu de construire un autre modèle, ce projet utilise un outil simple et prêt à l'emploi pour enquêter sur le sentiment appelé TextBlob. J'utiliserai TextBlob pour présenter des colonnes d'opinion dans le DataFrame afin qu'elles soient souvent analysées.

Qu'est-ce que TextBlob?
Construit sur NLTK et modèle, la bibliothèque TextBlob pour Python 2 et trois tentatives pour simplifier diverses tâches de traitement de texte. Fournit des outils de classification, marquer une partie du discours, extraction de phrases, analyse des sentiments et plus. Installez-le en utilisant pip.
pip install -U textblob python -m textblob.download_corpora
Sentiment par TextBlob
Utilisation de la propriété sentiment, TextBlob renvoie un tuple nommé de la forme Sentiment (polarité, subjectivité). La polarité peut flotter dans la plage [-1.0, 1.0] où -1 est le plus négatif et 1 est le plus positif. La subjectivité pourrait flotter à portée [0.0, 1.0] où 0.0 est extrêmement objectif et 1.0 c'est extrêmement subjectif.
blob = TextBlob("Ceci est un bon exemple de TextBlob")
imprimer(goutte)blob.sentiment
#Sentiment(polarité=0.7, subjectivité=0.6000000000000001)
Appliquer TextBlob
Lors de l'utilisation de listes de compréhension, il est facile de charger la colonne de texte en tant que TextBlob, donc créez deux nouvelles colonnes pour stocker la polarité et la subjectivité.
#charger les descriptions dans textblob email_blob = [TextBlob(texte) pour le texte en df['texte']] #ajouter les métriques de sentiment au dataframe df['tb_Pol'] = [b.sentiment.polarity pour b dans email_blob] df['tb_Subj'] = [b.sentiment.subjectivity pour b dans email_blob] #afficher la trame de données df.head(3)

TextBlob facilite l'obtention d'un score de sentiment de base pour la polarité et la subjectivité. Pour booster encore plus cet utilisateur, voyez si vous pouvez ajouter ces nouvelles fonctionnalités au modèle de détection de spam pour augmenter la précision.
conclusion:
Bien que le traitement de la communication linguistique puisse sembler un sujet intimidant, les pièces fondamentales ne semblent pas si difficiles à comprendre. De nombreuses bibliothèques facilitent l'exploration de la science des données et de la PNL. La réalisation de ces trois projets:
Mot nuage
Détection de spam
Analyse des sentiments
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





