Vue d'ensemble:
- Découvrez ce qu'est le Big Data et sa pertinence dans le monde d'aujourd'hui
- Connaître les caractéristiques du Big Data
introduction
Le terme “Big Data” c'est un abus de langage, car cela implique que les données préexistantes sont en quelque sorte petites (ils ne le sont pas) ou que le seul défi est sa grande taille (la taille est l'un d'entre eux, mais il y a souvent plus ).
En résumé, le terme Big Data s'applique aux informations qui ne peuvent pas être traitées ou analysées à l'aide de processus ou d'outils traditionnels.

Chaque fois plus, les organisations sont aujourd'hui confrontées à de plus en plus de défis liés au big data. Ils ont accès à une mine d'informations, mais ils ne savent pas comment en tirer de la valeur car c'est dans sa forme la plus grossière ou dans un format semi-structuré ou non structuré; et comme résultat, ils ne savent même pas si ça vaut la peine de le garder (ou même s'ils peuvent le garder).
Dans cet article, nous analysons le concept de big data et de quoi il s'agit.
Table des matières
- Qu'est-ce que le Big Data?
- Caractéristiques du Big Data
- Volume de données
- La variété des données
- Vitesse des données
Qu'est-ce que le Big Data?
Nous en faisons partie, tous les jours!
Une enquête d'IBM a révélé que plus de la moitié des chefs d'entreprise d'aujourd'hui se rendent compte qu'ils n'ont pas accès aux informations dont ils ont besoin pour faire leur travail. Les entreprises sont confrontées à ces défis dans un climat où elles ont la capacité de tout stocker et génèrent des données comme jamais auparavant dans l'histoire.; combiné, cela représente un véritable défi d'information.

C'est une énigme: les entreprises d'aujourd'hui ont plus que jamais accès aux informations potentielles, cependant, alors que cette mine d'or potentielle de données s'accumule, le pourcentage de données que l'entreprise peut traiter est rapidement réduit. En peu de mots, l'ère du Big Data bat son plein aujourd'hui parce que le monde change.
Grâce à l'instrumentation, nous pouvons ressentir plus de choses et, si on peut le sentir, nous avons tendance à essayer de le stocker (ou au moins une partie). Grâce aux progrès de la technologie des communications, les gens et les choses sont de plus en plus interconnectés, et pas seulement parfois, mais tout le temps. Cette redevance d'interconnectivité est un train en fuite. Généralement connu sous le nom de machine à machine (M2M), l'interconnectivité est responsable des taux de croissance des données à deux chiffres d'une année sur l'autre (année après année).
Finalement, parce que les petits circuits intégrés sont maintenant si peu coûteux, nous pouvons ajouter de l'intelligence à presque tout. Même quelque chose d'aussi banal qu'un wagon de train a des centaines de capteurs. Dans un wagon de chemin de fer, ces capteurs suivent des choses comme les conditions rencontrées par le wagon, l'état des pièces individuelles et les données GPS pour le suivi et la logistique d'expédition. Après des déraillements de train qui ont fait de nombreuses victimes, les gouvernements ont introduit des réglementations pour que ce type de données soit stocké et analysé afin de prévenir de futures catastrophes.
Les wagons deviennent aussi plus intelligents: des processeurs ont été ajoutés pour interpréter les données des capteurs sur les pièces sujettes à l'usure, comme des roulements, pour identifier les pièces qui doivent être réparées avant qu'elles ne tombent en panne et causent d'autres dommages, ou pire encore, un désastre. Mais il n'y a pas que les wagons qui sont intelligents, les vrais rails ont des capteurs tous les quelques pieds. En outre, les exigences de stockage des données concernent l'ensemble de l'écosystème: automobiles, des rails, capteurs de passage à niveau, les conditions météorologiques provoquant des mouvements ferroviaires, etc.
Ajoutez maintenant ceci pour suivre la charge d'un wagon de train, heures d'arrivée et de départ, et vous pouvez voir très rapidement que vous avez un problème Big Data sur vos mains. Même si chaque bit de ces données était relationnel (et ce n'est pas), ils seront tous bruts et auront des formats très différents, ce qui rend leur traitement dans un système relationnel traditionnel peu pratique ou impossible. Les wagons ne sont qu'un exemple, mais où que l'on regarde, nous voyons les domaines avec la vitesse, volume et variété qui se combinent pour créer le problème du big data.
Quelles sont les caractéristiques du Big Data?
Trois caractéristiques définissent le Big Data: le volume, variété et rapidité.
Joints, ces caractéristiques définissent "Big Data". Ils ont créé le besoin d'une nouvelle classe de capacités pour augmenter la façon dont les choses sont faites aujourd'hui pour offrir une meilleure visibilité et un meilleur contrôle sur nos domaines de connaissances existants et la capacité d'agir sur eux..
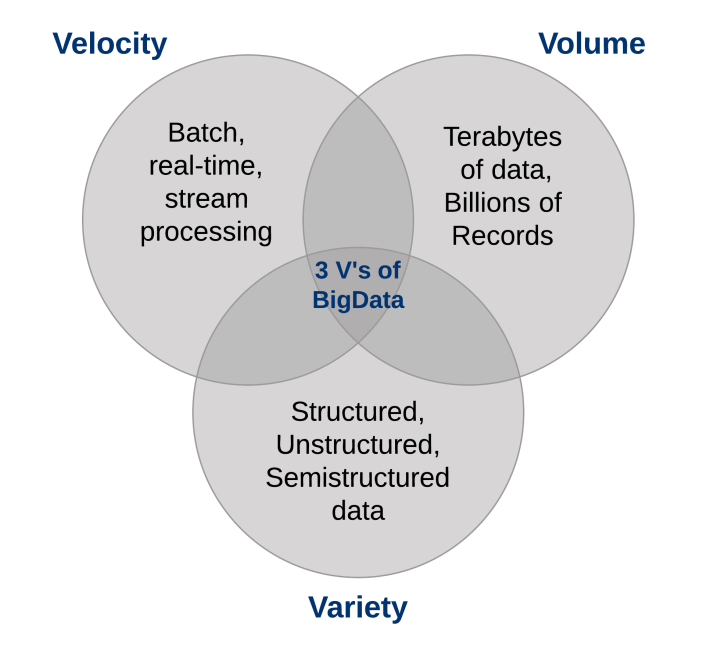
1. Volume de données
Le volume de données stockées aujourd'hui monte en flèche. Dans l'année 2000, ils ont été stockés 800.000 pétaoctets (PB) de données dans le monde. Bien sûr, une grande partie des données qui sont créées aujourd'hui ne sont pas du tout analysées et c'est un autre problème qui doit être pris en compte. Ce nombre devrait atteindre 35 zettaoctets (Par exemple.) à 2020. Twitter ne génère que plus de 7 téraoctets (TB) de données chaque jour, Facebook 10 TB et certaines entreprises génèrent des téraoctets de données chaque heure de chaque jour de l'année. Il n'est plus rare que des entreprises individuelles disposent de clusters de stockage contenant des pétaoctets de données.

Quand tu t'arrêtes et que tu y penses, c'est un peu bizarre qu'on se noie dans les données. Nous stockons tout: données environnementales, données financières, données médicales, données de surveillance et la liste s'allonge encore et encore. Par exemple, sortir son smartphone de son étui génère un événement; quand la porte de votre train de banlieue s'ouvre pour embarquer, C'est un événement; s'inscrire pour prendre l'avion, entrer au travail, acheter une chanson sur iTunes, changer de chaîne de télévision, emprunter un itinéraire à péage électronique: chacune de ces actions génère des données.
D'accord, tu obtiens le point: il y a plus de données que jamais et tout ce que vous avez à faire est de regarder le taux de pénétration de téraoctets pour les ordinateurs personnels à domicile comme un signe révélateur. Nous avions l'habitude de conserver une liste de tous les magasins de données que nous connaissions et qui dépassaient le téraoctet il y a près de dix ans; il suffit de dire que les choses ont changé en ce qui concerne le volume.
Comme le terme l'indique “Big Data”, les organisations sont confrontées à d'énormes volumes de données. Les organisations qui ne savent pas gérer ces données en sont submergées. Mais l'opportunité existe, avec la bonne plateforme technologique, pour analyser presque toutes les données (ou au moins plusieurs d'entre eux identifiant les données qui vous sont utiles) pour mieux comprendre votre entreprise, vos clients et le marché. Et cela conduit à l'énigme actuelle à laquelle sont confrontées les entreprises d'aujourd'hui dans toutes les industries..
Au fur et à mesure que la quantité de données disponibles pour l'entreprise augmente, le pourcentage de données qu'il peut traiter, comprendre et analyser diminue, créant ainsi la zone aveugle.
Qu'y a-t-il dans cette zone aveugle?
Tu ne le sais pas: ça peut être quelque chose de génial ou peut-être rien du tout, mais le "je ne sais pas" est le problème (ou l'opportunité, selon la façon dont vous le regardez). La conversation sur les volumes de données est passée des téraoctets aux pétaoctets avec un passage inévitable aux zettaoctets, et toutes ces données ne peuvent pas être stockées dans vos systèmes traditionnels.
2. La variété des données
Le volume associé au phénomène Big Data apporte de nouveaux défis pour les centres de données qui tentent d'y faire face: sa variété.
Avec l'explosion des capteurs et des appareils intelligents, ainsi que les technologies de collaboration sociale, les données dans une entreprise sont devenues complexes, car ils n'incluent pas seulement des données relationnelles traditionnelles, mais aussi des données brutes, pages Web semi-structurées et non structurées, fichiers de blog (y compris les données de parcours de navigation), index de recherche, forums de médias sociaux, courrier électronique, documents, données de capteurs des systèmes actifs et passifs, etc.
En outre, Les systèmes traditionnels peuvent avoir des difficultés à stocker et à effectuer les analyses nécessaires pour comprendre le contenu de ces enregistrements, car la plupart des informations générées ne se prêtent pas aux technologies de base de données traditionnelles.. Dans mon expérience, même si certaines entreprises avancent, en général, la plupart commencent tout juste à comprendre les opportunités du big data.
En peu de mots, la variété représente tous les types de données: un changement fondamental par rapport aux exigences d'analyse de données structurées traditionnelles pour inclure des données brutes, semi-structuré et non structuré dans le cadre du processus de connaissance et de prise de décision. Les plateformes d'analyse traditionnelles ne peuvent pas gérer la variété. Cependant, le succès d'une organisation dépendra de sa capacité à extraire des connaissances des différents types de données disponibles, qui comprennent à la fois traditionnels et non traditionnels.
Quand on revient sur nos carrières dans les bases de données, il est parfois humiliant de voir que nous passons plus de temps à 20 pourcentage de données: le type relationnel qui est parfaitement formaté et s'intègre bien dans nos schémas stricts. Mais la vérité est que le 80 pour cent des données mondiales (et de plus en plus de ces données sont responsables de l'établissement de nouveaux records de vitesse et de volume) ne sont pas structurés ou, Dans le meilleur des cas, semi-structurés. Si vous regardez un fil Twitter, vous verrez la structure dans son format JSON, mais le texte réel n'est pas structuré et la compréhension peut être enrichissante.
Les images vidéo et les images ne sont pas stockées facilement ou efficacement dans une base de données relationnelle, certaines informations d'événement peuvent changer dynamiquement (comme les conditions météorologiques), qui ne convient pas aux schémas stricts, et de plus. Pour capitaliser sur l'opportunité Big Data, les entreprises doivent pouvoir analyser tous types de données, à la fois relationnel et non relationnel: texte, données du capteur, l'audio, vidéo, transactionnel et plus.
3. Vitesse des données
Tout comme le volume et la variété des données que nous collectons ont changé et le magasin, la vitesse à laquelle ils sont générés et doivent être manipulés a également changé. Une compréhension conventionnelle de la vitesse considère généralement à quelle vitesse les données arrivent et se stockent, et leurs taux de récupération associés. Bien que gérer tout ça rapidement, c'est bien, et les volumes de données que nous voyons sont une conséquence de la vitesse à laquelle les données arrivent.
Pour s'adapter à la vitesse, une nouvelle façon de penser un problème doit commencer au point de départ des données. Au lieu de limiter l'idée de vitesse aux taux de croissance associés à vos référentiels de données, nous vous suggérons d'appliquer cette définition aux données en mouvement: la vitesse à laquelle les données circulent.
Après tout, nous convenons que les entreprises d'aujourd'hui ont affaire à des pétaoctets de données plutôt qu'à des téraoctets, et la montée des capteurs RFID et d'autres flux d'informations a conduit à un flux constant de données à un taux qui a rendu impossible pour les systèmes traditionnels. manipuler. Parfois, Gagner un avantage sur la concurrence peut signifier repérer une tendance, problème ou opportunité quelques secondes, ou même des microsecondes, avant quelqu'un d'autre.
En outre, de plus en plus de données produites aujourd'hui ont une durée de conservation très courte, les organisations doivent donc être en mesure d'analyser ces données en temps quasi réel si elles s'attendent à trouver des informations précieuses dans ces données.. En transformation traditionnelle, vous pouvez penser à exécuter des requêtes avec des données relativement statiques: par exemple, la consultation “Montrez-moi toutes les personnes qui vivent dans la zone inondable ABC” se traduirait par un seul ensemble de résultats qui serait utilisé comme une liste d'avertissements météorologiques entrants. Modèle. Avec le calcul de flux, vous pouvez exécuter un processus similaire à une requête continue qui identifie les personnes actuellement “dans les zones inondables ABC”, mais vous obtenez des résultats mis à jour en permanence car les informations de localisation des données GPS sont mises à jour en temps réel.
Traiter efficacement le Big Data vous oblige à effectuer une analyse par rapport au volume et à la variété des données alors qu'elles sont encore en mouvement., non seulement après qu'ils soient au repos. Considérez des exemples allant du suivi de la santé néonatale aux marchés financiers; dans tous les cas, nécessitent de gérer le volume et la variété des données de manière nouvelle.
Remarques finales
Vous ne pouvez pas vous permettre d'examiner toutes les données dont vous disposez dans vos processus traditionnels; c'est trop de données avec trop peu de valeur connue et trop de coûts mis en jeu. Les plateformes Big Data vous offrent un moyen de stocker et de traiter à moindre coût toutes ces données et de découvrir ce qui est précieux et ce qui vaut la peine d'être exploité. En outre, puisqu'on parle d'analyse de données au repos et de données en mouvement, les données réelles à partir desquelles vous pouvez trouver de la valeur ne sont pas seulement plus larges, ils peuvent également les utiliser et les analyser plus rapidement en temps réel.
Je vous recommande de lire ces articles pour vous familiariser avec les outils du big data:
Faites-nous part de vos réflexions dans les commentaires ci-dessous..
Référence
Comprendre le Big Data: Analytique pour Hadoop de classe entreprise et données de streaming.





