Réflexes
- La tokenisation est un aspect clé (et obligatoire) de travailler avec des données textuelles
- Nous discuterons des différentes nuances de la tokenisation, y compris comment gérer les mots en dehors du vocabulaire (OOV)
introduction
La langue est une belle chose. Mais maîtriser une nouvelle langue à partir de zéro est une perspective assez écrasante.. Si vous avez déjà appris une langue qui n’était pas votre langue maternelle, vous vous identifierez à cela!! Il y a tellement de couches à supprimer et de syntaxe à prendre en compte, c’est un défi.
Et c’est exactement comme ça avec nos machines. Pour que notre ordinateur comprenne n’importe quel texte, nous devons décomposer ce mot d’une manière que notre machine peut comprendre.. C’est là que le concept de tokenisation entre en jeu dans le traitement du langage naturel. (PNL).
En peu de mots, nous ne pouvons pas travailler avec des données texte si nous n’effectuons pas de tokenisation. Oui, c’est vraiment si important!

Et voici la chose intrigante à propos de la tokenisation.: ce n'est pas solo sur la décomposition du texte. La tokenisation joue un rôle important dans la gestion des données textuelles. Ensuite, dans cet article, nous explorerons les profondeurs de la tokenisation dans le traitement du langage naturel et comment vous pouvez l’implémenter en Python.
Je recommande de prendre le temps d’examiner la ressource suivante si elle est nouvelle sur NLP:
Table des matières
- Un résumé rapide de la tokenisation
- Les vraies raisons de la tokenisation
- Quelle tokenisation (mot, caractère ou sous-mot) nous devrions utiliser?
- Mise en œuvre de la tokenisation: codage de paires d’octets en Python
Un résumé rapide de la tokenisation
La tokenisation est une tâche courante dans le traitement du langage naturel (PNL). C’est une étape fondamentale dans les méthodes NLP traditionnelles telles que Count Vectorizer et les architectures basées sur l’apprentissage profond avancé telles que Transformers.
Les jetons sont les éléments constitutifs du langage naturel.
La tokenisation est un moyen de séparer un morceau de texte en unités plus petites appelées jetons.. Ici, les jetons peuvent être des mots, caractères ou sous-mots. Donc, la tokenisation peut être largement classée en 3 les types: tokenisation de mots, caractère et sous-mot (Caractères n-gram).
Par exemple, envisager la prière: « N’abandonnez jamais ».
La façon la plus courante de former des jetons est basée sur l’espace. En supposant que l’espace est un délimiteur, la tokenisation de la phrase entraîne 3 jetons: N’abandonnez jamais. Comment chaque jeton est un mot, devient un exemple de tokenisation Word.
de la même manière, les jetons peuvent être des caractères ou des sous-mots. Par exemple, considérons « Intelligente »:
- Cartes de personnages: Intelligente
- Jetons de sous-mots: Intelligente
Mais alors est-ce nécessaire ?? Avons-nous vraiment besoin de tokenisation pour faire tout cela ??
Noter: Si vous débutez en PNL, consultez notre Cours de NLP en ligne
Les vraies raisons de la tokenisation
Puisque les jetons sont les composants de base du langage naturel, la façon la plus courante de traiter le texte brut se produit au niveau du jeton.
Par exemple, Modèles basés sur des transformateurs, las arquitecturas de l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé... de vanguardia (VALET) en NLP, traiter le texte brut au niveau du jeton. de la même manière, les architectures de deep learning les plus populaires pour NLP telles que RNN, GRU et LSTM traitent également le texte brut au niveau du jeton.
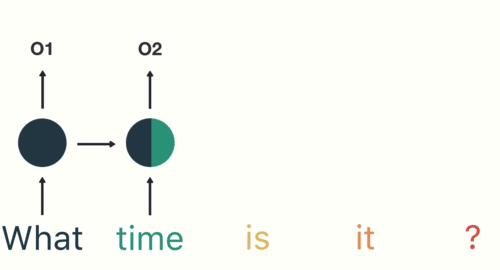
Funcionamiento de la récurrence neuronale rougeRéseaux de neurones récurrents (RNN) sont un type d’architecture de réseau neuronal conçu pour traiter des flux de données. Contrairement aux réseaux de neurones traditionnels, Les RNN utilisent des connexions internes qui permettent de mémoriser les informations des entrées précédentes. Cela les rend particulièrement utiles dans des tâches telles que le traitement du langage naturel, Traduction automatique et analyse de séries chronologiques, où le contexte et la séquence sont au cœur de la...
Comme montré ici, RNN reçoit et traite chaque jeton dans un pas de temps particulier.
Donc, la tokenisation est l’étape la plus importante lors de la modélisation de données textuelles. La tokenisation se fait dans le corpus pour obtenir des tokens. les onglets suivants sont ensuite utilisés pour préparer un vocabulaire. Le vocabulaire fait référence à l’ensemble des jetons uniques dans le corpus. Rappelez-vous que le vocabulaire peut être construit en considérant chaque jeton unique dans le corpus ou en considérant les mots K les plus fréquents..
La création de vocabulaire est le but ultime de la tokenisation.
L’une des astuces les plus simples pour améliorer les performances du modèle NLP est de créer un vocabulaire à partir des mots K les plus fréquents...
À présent, comprendre l’utilisation du vocabulaire dans les méthodes de NLP traditionnelles et avancées basées sur l’apprentissage profond.
- Approches traditionnelles de l’NLP, tels que Count Vectorizer et TF-IDF, utiliser le vocabulaire comme caractéristiques. Chaque mot du vocabulaire est traité comme une caractéristique unique:
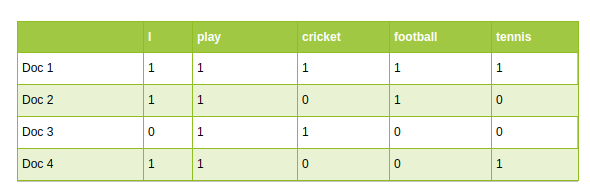
NLP traditionnelle: Count Vectorizer
- Dans NLP architectures basées sur le deep learning avancé, le vocabulaire est utilisé pour créer les phrases d’entrée tokenisées. Finalement, les jetons de ces phrases sont passés en tant qu’entrées du modèle.
Quelle tokenisation devez-vous utiliser?
Comme mentionné précédemment, la tokenisation peut être effectuée au niveau du mot, caractère ou sous-mot. C’est une question courante: Quelle tokenisation devrions-nous utiliser lors de la résolution d’une tâche NLP?? Abordons cette question ici.
Tokenisation des mots
La tokenisation word est l’algorithme de tokenisation le plus utilisé. Divise un morceau de texte en mots individuels en fonction d’un délimiteur donné. Selon les délimiteurs, différents jetons de niveau mot sont formés. Les intégrations de mots précédemment entraînées telles que Word2Vec et GloVe sont incluses dans la tokenisation de mots.
Mais cela présente certains inconvénients.
Inconvénients de la tokenisation des mots
L’un des principaux problèmes avec les jetons de mots est de traiter avec Mots sans vocabulaire (OOV). Les mots OOV font référence aux nouveaux mots trouvés dans les tests. Ces nouveaux mots n’existent pas dans le vocabulaire. Donc, ces méthodes ne parviennent pas à gérer les mots OOV.
Mais attendez, ne sautez pas encore aux conclusions !!
- Une petite astuce peut sauver les tokenizers de mots des mots OOV. El truco consiste en formar el vocabulario con las K palabras frecuentes más frecuentes y reemplazar las palabras raras en los datos de entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... avec inconnu jetons (L’UNK). Cela aide le modèle à apprendre la représentation des mots OOV en termes de jetons UNK.
- Donc, pendant le temps d’essai, tout mot qui n’est pas présent dans le vocabulaire sera affecté à un jeton UNK. Voici comment nous pouvons aborder le problème OOV dans les tokenizers de mots.
- Le problème avec cette approche est que toutes les informations de mots sont perdues lorsque nous mappons OOV aux jetons UNK.. La structure du mot peut être utile pour le représenter avec précision. Et un autre problème est que chaque mot OOV a la même représentation.

Un autre problème avec les jetons de mots est lié à la taille du vocabulaire. Généralement, les modèles pré-entraînés sont formés sur un grand volume du corpus de texte. Ensuite, imaginez construire du vocabulaire avec tous les mots uniques dans un si grand corpus. Cela exploite le vocabulaire !!
Cela ouvre la porte à la tokenisation des caractères.
Tokenisation des caractères
La tokenisation de caractères divise chaque texte en un jeu de caractères. Surmontez les inconvénients que nous avons vus plus tôt sur la tokenisation des mots.
- Les tokeniseurs de caractères gèrent les mots OOV de manière cohérente en préservant les informations de mots. Divisez le mot OOV en caractères et représentez le mot en termes de ces caractères.
- Cela limite également la taille du vocabulaire. Voulez-vous deviner la taille du vocabulaire? 26 parce que le vocabulaire contient un ensemble unique de caractères
Inconvénients de la tokenisation des caractères
les onglets de caractères résolvent le problème oov, pero la longitud de las oraciones de entrada y salida aumenta rápidamente a mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique.... que representamos una oración como una secuencia de caracteres. Par conséquent, cela devient un défi d’apprendre la relation entre les personnages pour former des mots significatifs..
Cela nous amène à une autre tokenisation connue sous le nom de tokenisation de sous-mot., qui se situe entre une tokenisation des mots et des caractères.
Tokenisation des sous-mots
La tokenisation des sous-mots divise le fragment de texte en sous-mots (ou caractères n-gram). Par exemple, des mots comme inférieur peuvent être segmentés comme inférieur, plus intelligent que plus intelligent, etc.
Modèles basés sur la transformation, SOTA en NLP, s’appuyer sur des algorithmes de tokenisation de sous-mots pour préparer le vocabulaire. À présent, Je vais discuter de l’un des algorithmes de tokenisation de sous-mots les plus populaires connu sous le nom de Byte Pair Encoding (BPE).
Bienvenue dans l’encodage Byte Pair (BPE)
Codage des paires d’octets (BPE) est une méthode de tokenisation largement utilisée parmi les modèles basés sur des transformateurs. BPE résout le problème des tokeniseurs de caractères et de mots:
- BPE traite efficacement oOV. Segmente OOV en tant que sous-mots et représente le mot en termes de ces sous-mots.
- La longueur des phrases d’entrée et de sortie après BPE est plus courte par rapport à la tokenisation de caractères
BPE es un algoritmo de segmentationLa segmentation est une technique de marketing clé qui consiste à diviser un large marché en groupes plus petits et plus homogènes. Cette pratique permet aux entreprises d’adapter leurs stratégies et leurs messages aux spécificités de chaque segment, améliorant ainsi l’efficacité de vos campagnes. Le ciblage peut se faire sur des critères démographiques, Psychographique, géographique ou comportementale, Faciliter une communication plus pertinente et personnalisée avec le public cible.... de palabras que fusiona los caracteres o secuencias de caracteres que ocurren con más frecuencia de forma iterativa. Voici un guide étape par étape pour apprendre bpE.
Étapes pour apprendre BPE
- Divisez les mots du corpus en caractères après avoir ajouté
- Initialiser le vocabulaire avec des caractères uniques dans le corpus.
- Calculer la fréquence d’une paire de caractères ou de séquences de caractères dans le corpus
- Fusion de la paire la plus fréquente dans le corpus
- Gardez la meilleure correspondance dans le vocabulaire
- Répétez les étapes 3 une 5 pour un certain nombre d’itérations
Nous comprendrons les étapes avec un exemple.
Considérons un corpus: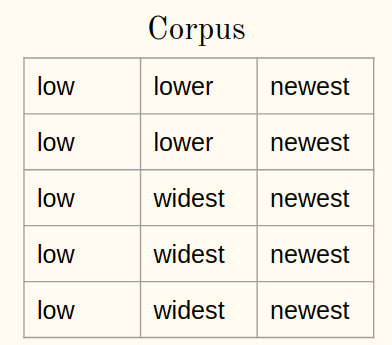
1une) Ajouter le symbole à la fin du mot (dis-le ) à chaque mot du corpus:
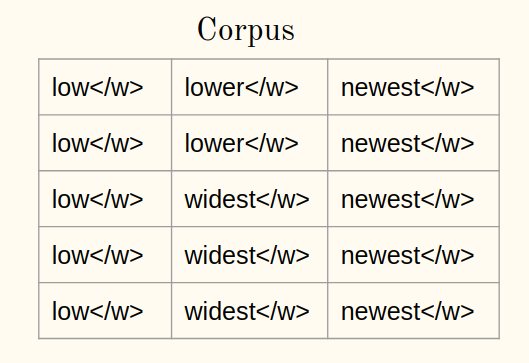
1b) Tokeniser les mots d’un corpus en caractères:
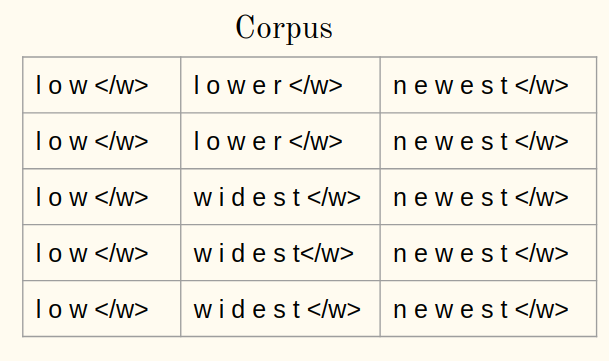
2. Initialiser le vocabulaire:

Itération 1:
3. Calculer la fréquence:

4. Fusionner la paire la plus fréquente:
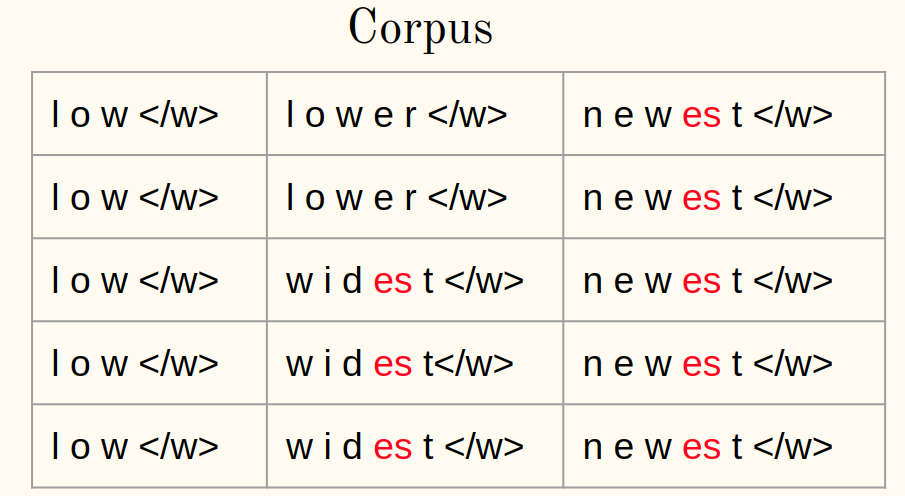
5. Enregistrez la meilleure paire:

Répétez les étapes 3-5 pour chaque itération à partir de maintenant. Permettez-moi d’illustrer une autre itération.
Itération 2:
3. Calculer la fréquence:

4. Fusionner la paire la plus fréquente:
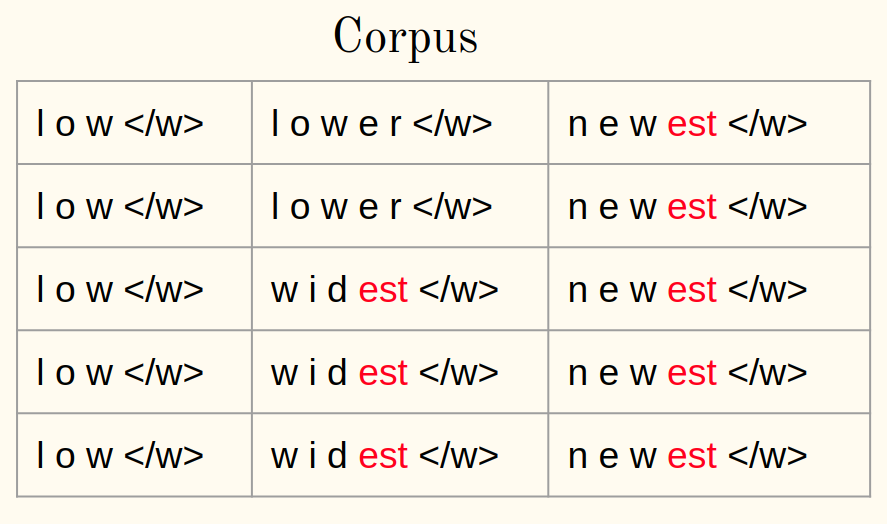
5. Enregistrez la meilleure paire:

Après que 10 itérations, Les opérations de fusion BPE ressemblent à ceci:

Assez simple, vérité?
Appliquer BPE aux mots OOV
Mais, comment pouvons-nous représenter le mot OOV au moment des tests à l’aide des opérations apprises BPE? Quelques idées? Répondons à cette question maintenant.
Au moment de l’essai, le mot oov est divisé en séquences de caractères. Alors, les opérations apprises sont appliquées pour fusionner des caractères en symboles connus plus grands.
– Traduction automatique neuronale de mots rares avec des unités de sous-mots, 2016
Ensuite, montre une procédure étape par étape pour le rendu des mots oov:
- Divisez le mot OOV en caractères après l’ajout
- Calculer une paire de caractères ou des séquences de caractères dans un mot
- Sélectionnez les paires présentes dans les métiers appris
- Fusionner la paire la plus fréquente
- Répétez les étapes 2 Oui 3 jusqu’à ce qu’il soit possible de fusionner
Voyons tout cela en action ci-dessous!!
Mise en œuvre de la tokenisation: codage de paires d’octets en Python
Nous sommes maintenant conscients du fonctionnement de BPE: apprendre et appliquer les mots OOV. Ensuite, il est temps d’implémenter nos connaissances en Python.
Le code Python pour BPE est maintenant disponible dans le document d’origine (Traduction automatique neuronale de mots rares avec des unités de sous-mots, 2016)
Corpus de lecture
Nous envisagerons un corpus simple pour illustrer l’idée de BPE. Cependant, la même idée s’applique également à un autre corpus:
Préparation des textes
Tokeniser les mots en caractères dans le corpus et ajouter à la fin de chaque mot:
Apprentissage BPE
Calculer la fréquence de chaque mot du corpus:
Production:
![]()
Définissons une fonction pour calculer la fréquence d’une paire de caractères ou de séquences de caractères. Accepte le corpus et renvoie la paire avec sa fréquence:
À présent, la tâche suivante consiste à fusionner la paire la plus fréquente du corpus. Nous allons définir une fonction qui accepte le corpus, meilleure paire et renvoie le corpus modifié:
Ensuite, il est temps d’apprendre les opérations BPE. Comme BPE est une procédure itérative, nous effectuerons et comprendrons les étapes d’une itération. Calculons la fréquence des bigramas:
Production:
Trouvez la paire la plus fréquente:
Production: (‘e’, ‘s’)
Finalement, combinez la meilleure paire et enregistrez-la dans le vocabulaire:
Production:![]()
Nous suivrons des étapes similaires pour certaines itérations:
Production:![]()
La partie la plus intéressante est encore à venir!! C’est appliquer BPE aux mots OOV.
Appliquer BPE au mot OOV
À présent, nous verrons comment segmenter le mot OOV en sous-mots à l’aide d’opérations apprises. Considérez le mot OOV comme « baisser »:
L’application de BPE à un mot OOV est également un processus itératif. Nous mettrons en œuvre les étapes décrites plus haut dans l’article:
Production:
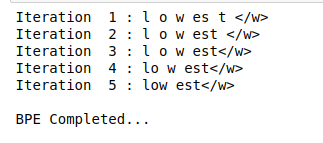
Comme vous pouvez le voir ici, le mot inconnu « baisser » est segmenté comme inférieur.
Remarques finales
La tokenisation est un moyen puissant de traiter les données textuelles. Nous avons vu un regard sur cela dans cet article et avons également implémenté la tokenisation à l’aide de Python.
Allez-y et testez cela sur n’importe quel jeu de données textuel que vous avez. Plus vous pratiquez, mieux sera votre compréhension du fonctionnement de la tokenisation (et pourquoi il s’agit d’un concept NLP si critique). N’hésitez pas à me contacter dans les commentaires ci-dessous si vous avez des questions ou des idées sur cet article..





