Pour chaque recrutement, les entreprises diffusent des annonces en ligne, références et les vérifier manuellement.
Les entreprises envoient généralement des milliers de CV pour chaque publication.
Quand les entreprises collectent des CV via des publicités en ligne, les classer selon vos besoins.
Après avoir récupéré les CV, les entreprises ferment les annonces et les portails de candidature en ligne.
Alors, envoyer les CV collectés à l'équipe de recrutement.
Il devient très difficile pour les équipes de recrutement de lire le curriculum vitae et de sélectionner le curriculum vitae en fonction du besoin, pas de problème s'il y a un ou deux CV, mais il est très difficile d'examiner les curriculum vitae de 1000 et sélectionnez le meilleur.
Pour résoudre ce problème, Aujourd'hui, dans cet article, nous allons lire et revoir le programme d'études en utilisant l'apprentissage automatique avec Python afin que nous puissions terminer les journées de travail en quelques minutes.
2. Qu'est-ce que l'évaluation du curriculum vitae?
Choisir les bonnes personnes pour le poste est la plus grande responsabilité de toutes les entreprises, car choisir le bon groupe de personnes peut accélérer la croissance de l'entreprise de façon exponentielle.
Nous analyserons ici un exemple d'entreprise de ce type, ce que nous savons en tant que service informatique. Nous savons que le service informatique ne suit pas les marchés en croissance.
En raison de nombreux grands projets avec de grandes entreprises, votre équipe n'a pas le temps de lire les CV et de choisir le meilleur CV en fonction de vos besoins.
Pour résoudre ce genre de problèmes, l'entreprise choisit toujours un tiers dont le travail consiste à rédiger le curriculum vitae selon l'exigence. Ces entreprises sont connues sous le nom de Hiring Service Organization. Ceci est l'écran récapitulatif des informations.
Le travail de sélection des meilleurs talents, affectations, concours de codage en ligne, parmi beaucoup d'autres, également connu sous le nom d'écran de reprise.
Par manque de temps, les grandes entreprises n'ont pas assez de temps pour ouvrir des CV, ils doivent donc recourir à l'aide de toute autre entreprise. Donc ils doivent payer de l'argent. Ce qui est un problème très grave.
Pour résoudre ce problème, l'entreprise souhaite démarrer seule le travail de l'écran de CV à l'aide d'un algorithme d'apprentissage automatique.
3. Criblage de CV à l'aide de l'apprentissage automatique
Dans cette section, nous verrons la mise en œuvre étape par étape du filtrage de CV en utilisant python.
3.1 Données utilisées
Nous avons des données disponibles publiquement de Kaggle. Vous pouvez télécharger les données en utilisant le lien suivant.
https://www.kaggle.com/gauravduttakiit/resume-dataset
3.2 L'analyse exploratoire des données
Jetons un coup d'œil aux données dont nous disposons.
resumeDataSet.head()

Il n'y a que deux colonnes que nous avons dans les données. Ci-dessous la définition de chaque colonne.
Catégorie: Type de travail pour lequel le curriculum vitae est adapté.
Reprendre: CV candidat
resumeDataSet.shape
Production:
(962, 2)
Il y a 962 observations que nous avons dans les données. Chaque observation représente les détails complets de chaque candidat, pour ce que nous avons 962 CV pour sélection.
Voyons quelles différentes catégories nous avons dans les données.
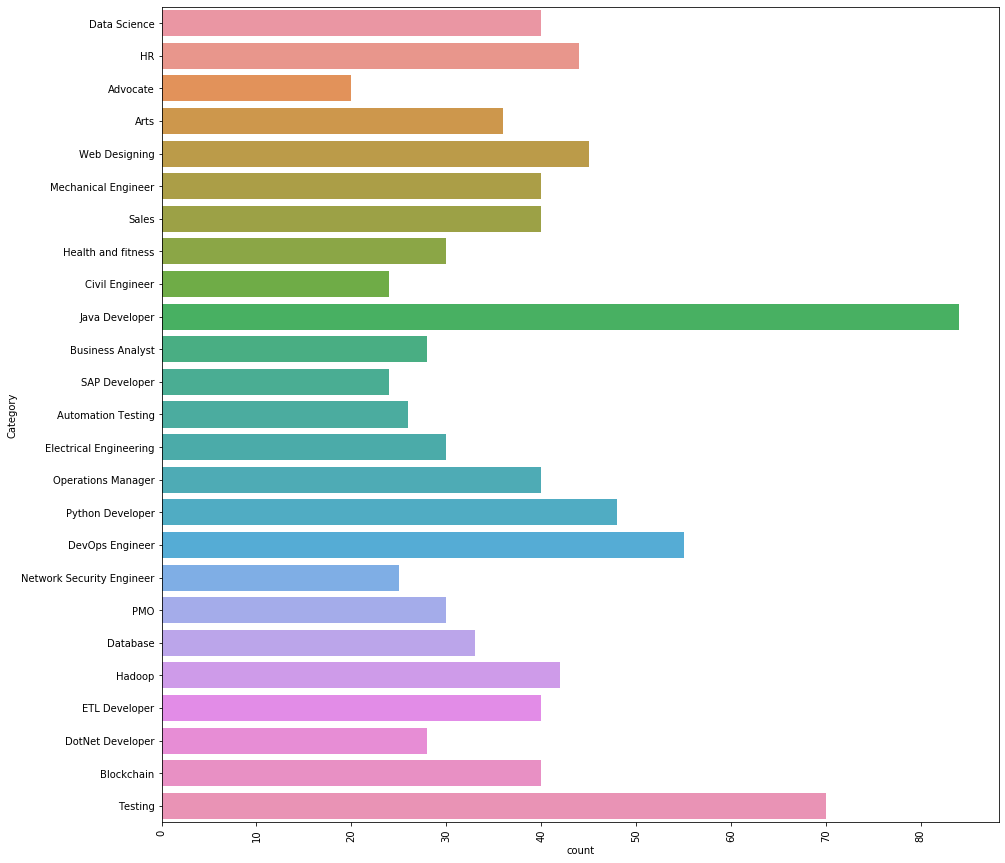
Il y a 25 différentes catégories que nous avons dans les données. Le 3 Les principales catégories d'emploi que nous avons dans les données sont les suivantes.
Développeur Java, Ingénieur tests et DevOps.
Au lieu du nombre ou de la fréquence, Nous pouvons également visualiser la répartition des catégories de travail en pourcentage comme indiqué ci-dessous:
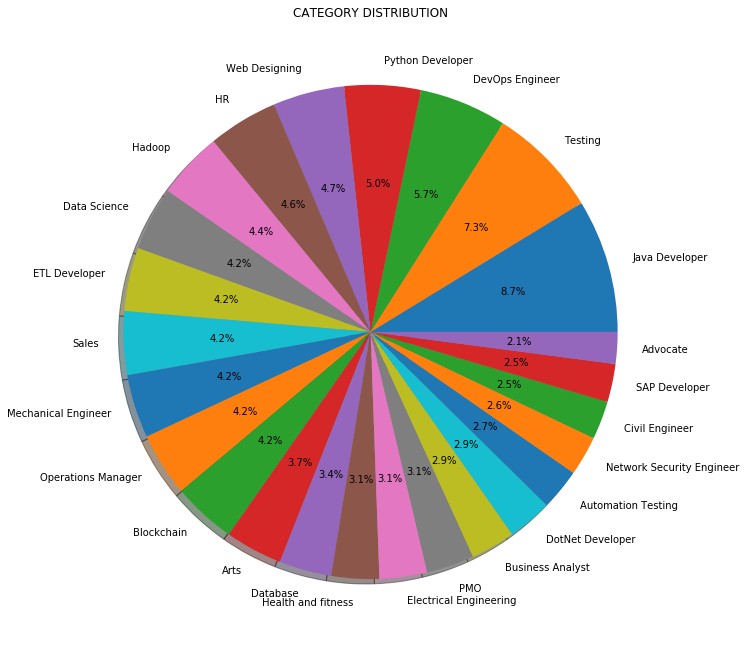
3.3 Prétraitement des données
Paso 1: Limpiar la columna ‘Reprendre’
Dans cette étape, nous supprimons toutes les informations inutiles des CV comme l'URL, hashtags et caractères spéciaux.
def cleanReprendre(reprendreTexte):
resumeText = re.sub('httpS+s*', ' ', reprendreTexte) # supprimer des URL
resumeText = re.sub('RT|cc', ' ', reprendreTexte) # supprimer RT et cc
resumeText = re.sub('#S+', '', reprendreTexte) # supprimer les hashtags
resumeText = re.sub('@S+', ' ', reprendreTexte) # supprimer les mentions
resumeText = re.sub('[%s]' % re.échapper("""!"#$%&'()*+,-./:;<=>[email protégé][]^_`{|}~"""), ' ', reprendreTexte) # supprimer les ponctuations
resumeText = re.sub(r'[^x00-x7f]',r' ', reprendreTexte)
resumeText = re.sub('s+', ' ', reprendreTexte) # supprimer les espaces supplémentaires
retour résuméTexte
resumeDataSet['cleaned_resume'] = resumeDataSet.Resume.apply(lambda x: nettoyerReprendre(X))
Paso 2: codificación de ‘Catégorie’
À présent, codificaremos la columna ‘Catégorie’ Usando LabelEncoding. Aunque la columna ‘Catégorie’ sont des données ‘Nominales’, estamos usando LabelEncong porque la columna ‘Catégorie’ es nuestra columna ‘objectif’. Al realizar LabelEncoding, chaque catégorie deviendra une classe et nous créerons un modèle de classification multiclasse.
var_mod = ['Catégorie']
le = LabelEncoder()
pour moi dans var_mod:
resumeDataSet[je] = le.fit_transform(resumeDataSet[je])
Paso 3: preprocesamiento de la columna ‘clean_resume’
Aquí preprocesaremos y convertiremos la columna ‘clean_resume’ en vecteurs. Il y a plusieurs façons de le faire, Quoi ‘Sac de mots’, ‘Tf-Idf’, ‘Word2Vec’ y una combinación de estos métodos.
Usaremos el método ‘Tf-Idf’ para obtener los vectores en este enfoque.
requiredText = resumeDataSet['cleaned_resume'].values requiredTarget = resumeDataSet['Catégorie'].values word_vectorizer = TfidfVectorizer( sublinear_tf=Vrai, stop_words="Anglais", max_features=1500) word_vectorizer.fit(obligatoireTexte) WordFeatures = word_vectorizer.transform(obligatoireTexte)
Ont ‘Fonctionnalités de Word’ como vectores y ‘Cible requise’ et cible après cette étape.
3.4 Construction de maquettes
Usaremos el método ‘One vs Rest’ avec ‘KNeighboursClassifier’ pour construire ce modèle de classification multiclasse.
nous utiliserons 80% de datos para entraînementLa formation est un processus systématique conçu pour améliorer les compétences, connaissances ou aptitudes physiques. Il est appliqué dans divers domaines, Comme le sport, Éducation et développement professionnel. Un programme d’entraînement efficace comprend la planification des objectifs, Pratique régulière et évaluation des progrès. L’adaptation aux besoins individuels et la motivation sont des facteurs clés pour obtenir des résultats réussis et durables dans toutes les disciplines.... Oui 20% données pour validation. Divisons maintenant les données en ensemble d'entraînement et de test.
X_train,X_test,y_train,y_test = train_test_split(Fonctionnalités de Word,Cible requise,état_aléatoire=0, taille_test=0.2) imprimer(X_train.shape) imprimer(X_test.shape)
Production:
(769, 1500) (193, 1500)
Comme nous avons maintenant des données de test et d'entraînement, construisons le modèle.
clf = OneVsRestClassifier(KNeighboursClassifier()) clf.fit(X_train, y_train) prédiction = clf.predict(X_test)
3.5 Résultats
Veamos los resultados que tenemos.
imprimer(« Précision du classificateur KNeighbors sur le plateau d’entraînement: {:.2F}'.format(clf.score(X_train, y_train)))
imprimer(« Précision du classificateur KNeighbors sur l’ensemble de test: {:.2F}'.format(clf.score(X_test, y teste)))
Production:
Précision du classificateur KNeighbors sur l'ensemble de formation: 0.99 Précision du classificateur KNeighbors sur l'ensemble de test: 0.99
Nous pouvons voir que les résultats sont étonnants. Nous pouvons classer chaque catégorie d'un CV donné avec un 99% précision.
Nous pouvons également consulter le rapport de classement détaillé pour chaque classe ou catégorie.
imprimer(metrics.classification_report(y teste, prédiction))
Production:
rappel de précision support f1-score
0 1.00 1.00 1.00 3
1 1.00 1.00 1.00 3
2 1.00 0.80 0.89 5
3 1.00 1.00 1.00 9
4 1.00 1.00 1.00 6
5 0.83 1.00 0.91 5
6 1.00 1.00 1.00 9
7 1.00 1.00 1.00 7
8 1.00 0.91 0.95 11
9 1.00 1.00 1.00 9
10 1.00 1.00 1.00 8
11 0.90 1.00 0.95 9
12 1.00 1.00 1.00 5
13 1.00 1.00 1.00 9
14 1.00 1.00 1.00 7
15 1.00 1.00 1.00 19
16 1.00 1.00 1.00 3
17 1.00 1.00 1.00 4
18 1.00 1.00 1.00 5
19 1.00 1.00 1.00 6
20 1.00 1.00 1.00 11
21 1.00 1.00 1.00 4
22 1.00 1.00 1.00 13
23 1.00 1.00 1.00 15
24 1.00 1.00 1.00 8
précision 0.99 193
moyenne macro 0.99 0.99 0.99 193
moyenne pondérée 0.99 0.99 0.99 193
Où, 0, 1, 2…. sont les catégories d'emploi. Nous obtenons les balises réelles de l'encodeur de balises que nous utilisons.
le.classes_
Production:
['Avocat', 'Art', « Tests d'automatisation », 'Blockchain','Analyste d'affaires', 'Ingénieur civil', « science des données », 'Base de données','Ingénieur DevOps', 'Développeur DotNet', 'Développeur ETL','Ingénierie électrique', 'HEURE', 'Hadoop', 'Santé et remise en forme','Développeur Java', 'Ingénieur mécanique',« Ingénieur en sécurité réseau », 'Directeur des opérations', 'PMO',"Développeur Python", 'Développeur SAP', 'Ventes', 'Essai','Conception web']
Ici ‘Abogado’ c'est la classe 0, ‘Artes’ c'est la classe 1, et ainsi de suite …
4. Code
Ici vous pouvez voir la mise en œuvre complète ....
#Chargement des bibliothèques
avertissements d'importation
warnings.filterwarnings('ignorer')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.gridspec import GridSpec
import re
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from scipy.sparse import hstack
from sklearn.multiclass import OneVsRestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
#Loading Data
resumeDataSet = pd.read_csv('.. /input/ResumeScreeningDataSet.csv' ,encodage='utf-8')
#EDA plt.figure(taille de la figue=(15,15)) plt.xticks(rotation=90) sns.countplot(y ="Catégorie", data=resumeDataSet) plt.savefig('.. /output/jobcategory_details.png') #Pie-chart targetCounts = resumeDataSet['Catégorie'].value_counts().reset_index()['Catégorie'] targetLabels = resumeDataSet['Catégorie'].value_counts().reset_index()['indice'] # Make square figures and axes plt.figure(1, taille de la figue=(25,25)) the_grid = GridSpec(2, 2) plt.sous-intrigue(the_grid[0, 1], aspect=1, titre="DISTRIBUTION DES CATÉGORIES") source_pie = plt.pie(targetCounts, labels=targetLabels, autopct="%1.1F%%", ombre=Vrai, ) plt.savefig('.. /output/category_dist.png')
#Data Preprocessing def cleanResume(reprendreTexte): resumeText = re.sub('httpS+s*', ' ', reprendreTexte) # supprimer des URL resumeText = re.sub('RT|cc', ' ', reprendreTexte) # supprimer RT et cc resumeText = re.sub('#S+', '', reprendreTexte) # supprimer les hashtags resumeText = re.sub('@S+', ' ', reprendreTexte) # supprimer les mentions resumeText = re.sub('[%s]' % re.échapper("""!"#$%&'()*+,-./:;<=>[email protégé][]^_`{|}~"""), ' ', reprendreTexte) # supprimer les ponctuations resumeText = re.sub(r'[^x00-x7f]',r' ', reprendreTexte) resumeText = re.sub('s+', ' ', reprendreTexte) # supprimer les espaces supplémentaires retour résuméTexte resumeDataSet['cleaned_resume'] = resumeDataSet.Resume.apply(lambda x: nettoyerReprendre(X)) var_mod = ['Catégorie'] le = LabelEncoder() pour moi dans var_mod: resumeDataSet[je] = le.fit_transform(resumeDataSet[je]) requiredText = resumeDataSet['cleaned_resume'].values requiredTarget = resumeDataSet['Catégorie'].values word_vectorizer = TfidfVectorizer( sublinear_tf=Vrai, stop_words="Anglais", max_features=1500) word_vectorizer.fit(obligatoireTexte) WordFeatures = word_vectorizer.transform(obligatoireTexte)
#Model Building
X_train,X_test,y_train,y_test = train_test_split(Fonctionnalités de Word,Cible requise,état_aléatoire=0, taille_test=0.2)
imprimer(X_train.shape)
imprimer(X_test.shape)
clf = OneVsRestClassifier(KNeighboursClassifier())
clf.fit(X_train, y_train)
prédiction = clf.predict(X_test)
#Results
print(« Précision du classificateur KNeighbors sur le plateau d’entraînement: {:.2F}'.format(clf.score(X_train, y_train)))
imprimer(« Précision du classificateur KNeighbors sur l’ensemble de test: {:.2F}'.format(clf.score(X_test, y teste)))
imprimer("n Rapport de classification pour le classificateur %s:n%sn" % (clf, metrics.classification_report(y teste, prédiction)))
5. conclusion
Dans cet article, Nous avons appris comment l'apprentissage automatique et le traitement du langage naturel peuvent être appliqués pour améliorer notre vie quotidienne grâce à l'exemple de la détection de CV. Nous venons de trier presque 1000 reprend en quelques minutes dans leurs catégories respectives avec un 99% précision.
Veuillez contacter la section commentaire si vous avez des questions.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





