[*]
Cet article a été publié dans le cadre du Blogathon sur la science des données
introduction
L'un des principaux problèmes auxquels tout le monde est confronté lors de la première tentative de streaming structuré est la configuration de l'environnement nécessaire pour diffuser ses données.. Nous avons des tutoriels en ligne sur la façon dont nous pouvons configurer cela. La plupart d'entre eux se concentrent sur vous demander d'installer une machine virtuelle et le système d'exploitation Ubuntu, puis de configurer tous les fichiers requis en modifiant le fichier bash.. Cela fonctionne bien, mais pas pour tout le monde. Une fois que nous utilisons une machine virtuelle, parfois nous devrons peut-être attendre longtemps si nous avons des machines avec moins de mémoire. Le processus pourrait se bloquer en raison de problèmes de décalage de mémoire. Ensuite, pour une meilleure façon de le faire et une utilisation facile, Je vais vous montrer comment configurer le streaming structuré dans notre système d'exploitation Windows.
Outils d'occasion
Pour la configuration, nous utilisons les outils suivants:
1. Kafka (pour la transmission de données, agit en tant que producteur)
2. gardien de zoo
3. Pyspark (générer les données transmises, agit en tant que consommateur)
4. Cahier Jupyter (éditeur de code)
Variables d'environnement
Il est important de noter qu'ici, J'ai ajouté tous les fichiers dans le lecteur C. En outre, le nom doit être le même que celui des fichiers que vous installez en ligne.
Nous devons définir les variables d'environnement lors de l'installation de ces fichiers. Veuillez vous référer à ces images lors de l'installation pour une expérience sans tracas.
La dernière image est le chemin des variables système.
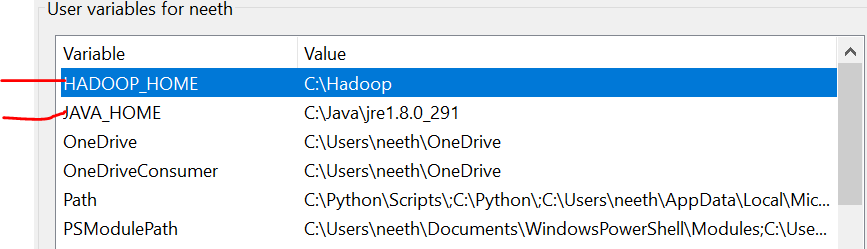
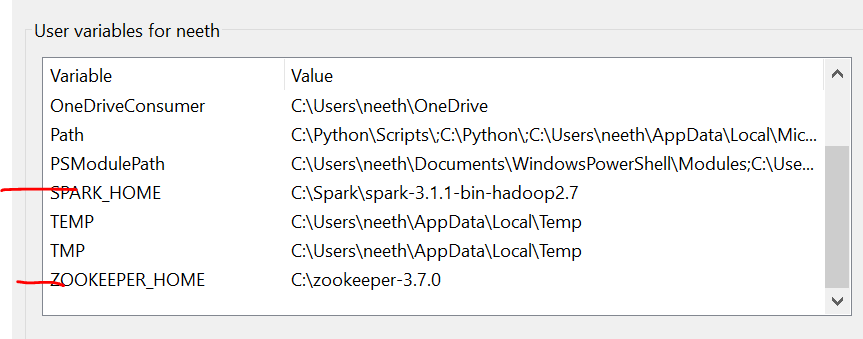
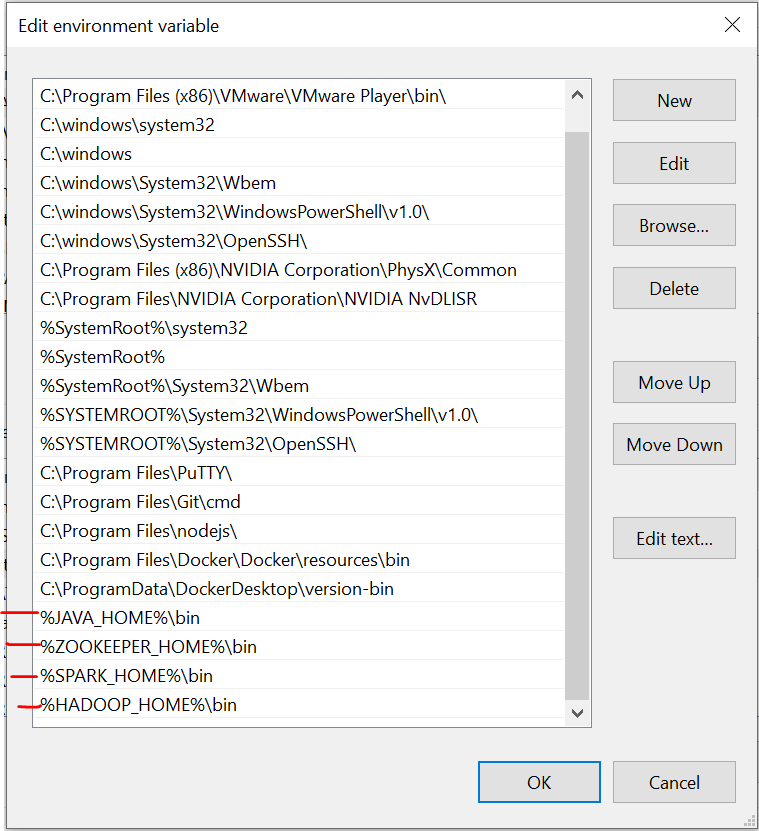
Fichiers requis
https://drive.google.com/drive/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw?usp=partage
Installation de Kafka
La première étape consiste à installer Kafka sur notre système. Pour cela il faut aller sur ce lien:
https://dzone.com/articles/running-apache-kafka-on-windows-os
Nous devons installer Java 8 initialement et définir les variables d'environnement. Vous pouvez obtenir toutes les instructions à partir du lien.
Une fois que nous avons terminé avec Java, nous devons installer un gardien de zoo. J’ai ajouté des fichiers zoo guardian dans Google Drive. N’hésitez pas à l’utiliser ou suivez simplement toutes les instructions données dans le lien. Si vous avez installé zookeeper correctement et configuré la variable d’environnement, vous pouvez voir ce résultat lorsque vous exécutez zkserver en tant qu’administrateur à l’invite de commandes.
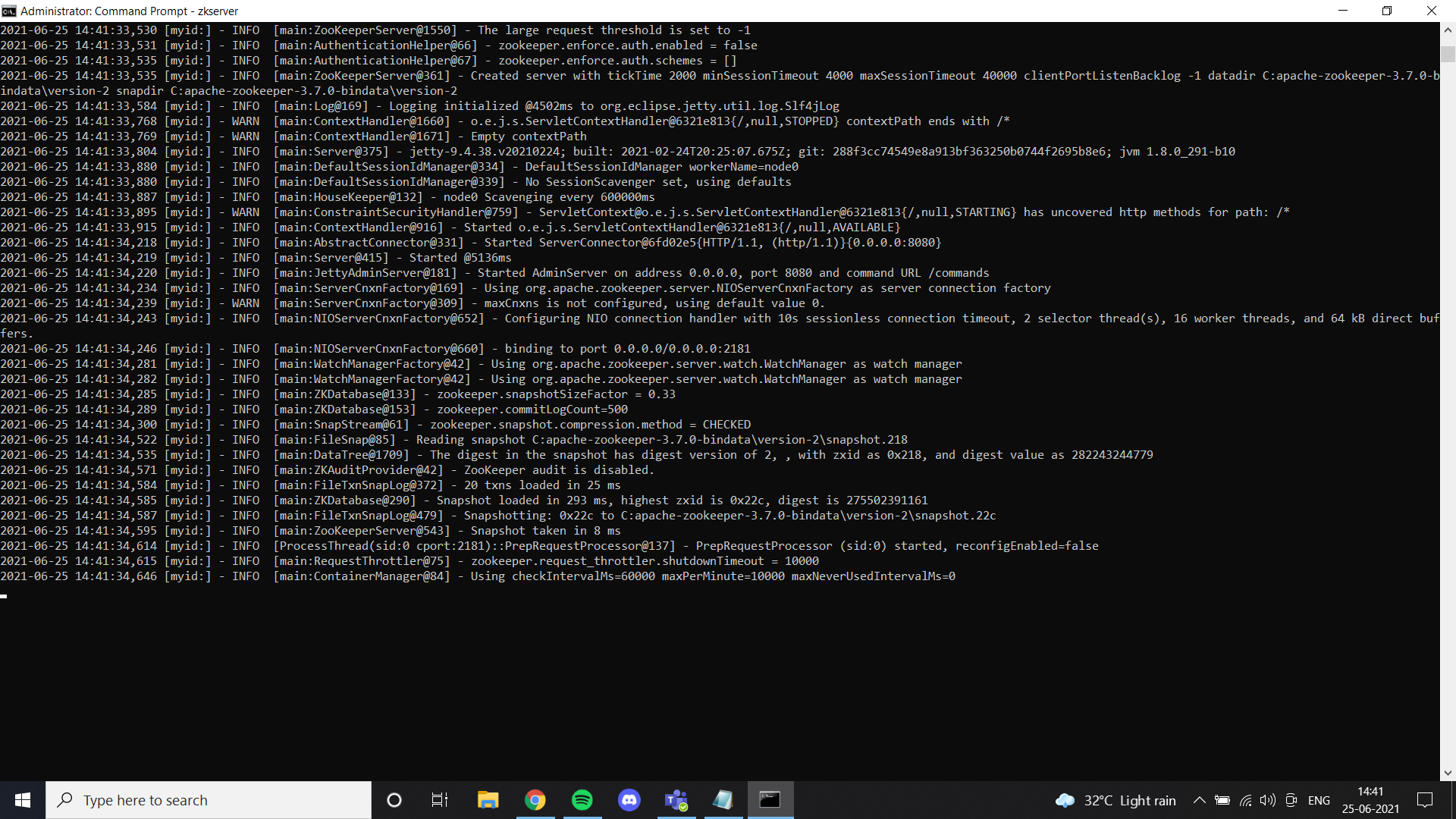
Ensuite, installer Kafka selon les instructions de liaison et l’exécuter avec la commande spécifiée.
.binwindowskafka-server-start.bat .configserver.properties
Une fois que tout est mis en place, essayez de créer un thème et vérifiez s'il fonctionne correctement. Si c'est ainsi, vous aurez terminé l'installation de Kafka.
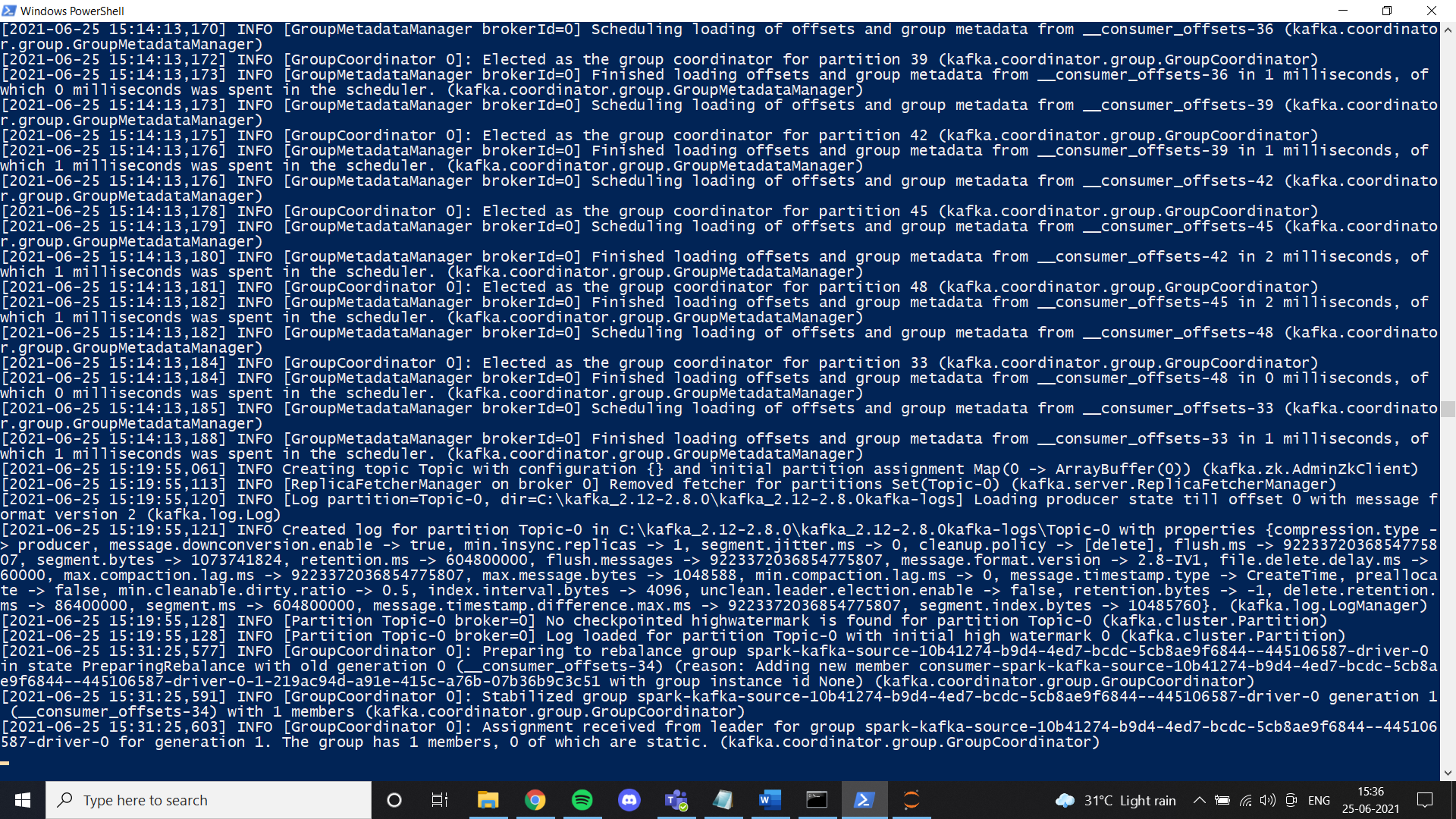
Installation d'étincelles
Dans cette étape, instalamos Spark. Essentiellement, vous pouvez suivre ce lien pour configurer Spark sur votre machine Windows.
https://phoenixnap.com/kb/install-spark-on-windows-10
Au cours d'une des étapes, il demandera que le fichier winutils soit configuré. Pour votre confort, j'ai ajouté le fichier dans le lien du lecteur que j'ai partagé. Dans un dossier appelé Hadoop. Placez simplement ce dossier sur votre lecteur C et définissez la variable d'environnement comme indiqué dans les images. Je vous recommande fortement d'utiliser le fichier Spark que j'ai ajouté à Google Drive. L'une des principales raisons est la transmission de données dont nous avons besoin pour configurer manuellement un environnement de transmission structuré. Dans notre cas, J'ai configuré toutes les choses nécessaires et modifié les fichiers après avoir beaucoup essayé. Au cas où vous voudriez faire une nouvelle configuration, n'hésitez pas à le faire. Si la configuration ne fonctionne pas correctement, nous nous retrouvons avec une erreur comme celle-ci lors de la transmission de données dans pyspark:
Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;Une fois que nous sommes un avec Spark, maintenant nous pouvons diffuser les données requises à partir d'un fichier CSV dans un producteur et les obtenir dans un consommateur en utilisant le thème Kafka. Je travaille principalement avec le notebook Jupiter et, donc, J'ai utilisé un cahier pour ce tutoriel.
Dans ton cahier d'abord, vous devez installer des bibliothèques:
1. pip installe pyspark
2. installateur de pip Kafka
3. pip installer py4j
Comment fonctionne le streaming structuré avec Pyspark?
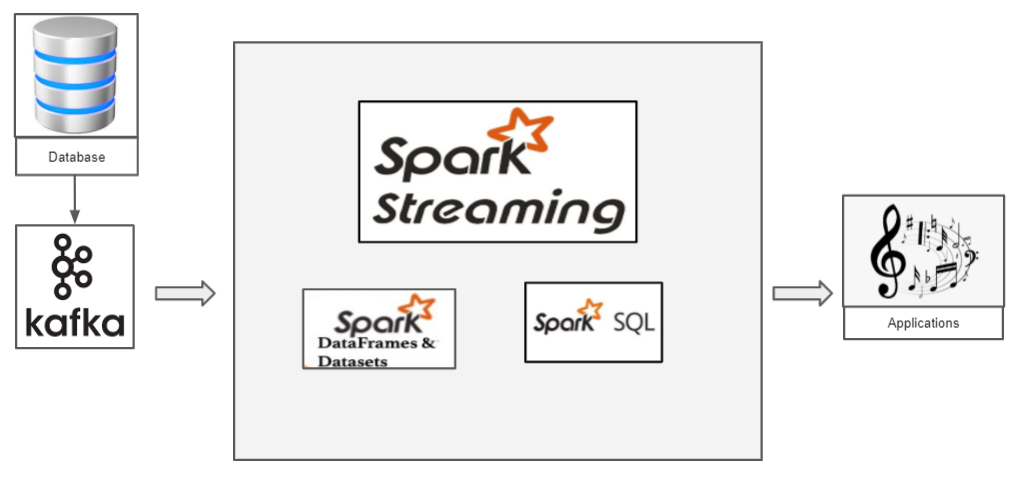
Nous avons un fichier CSV qui contient des données que nous souhaitons transmettre. Passons au jeu de données Iris classique. À présent, si nous voulons transmettre les données de l'iris, nous devons utiliser Kafka comme producteur. Kafka, nous créons un sujet auquel nous transmettons les données d'iris et le consommateur peut récupérer la trame de données de ce sujet.
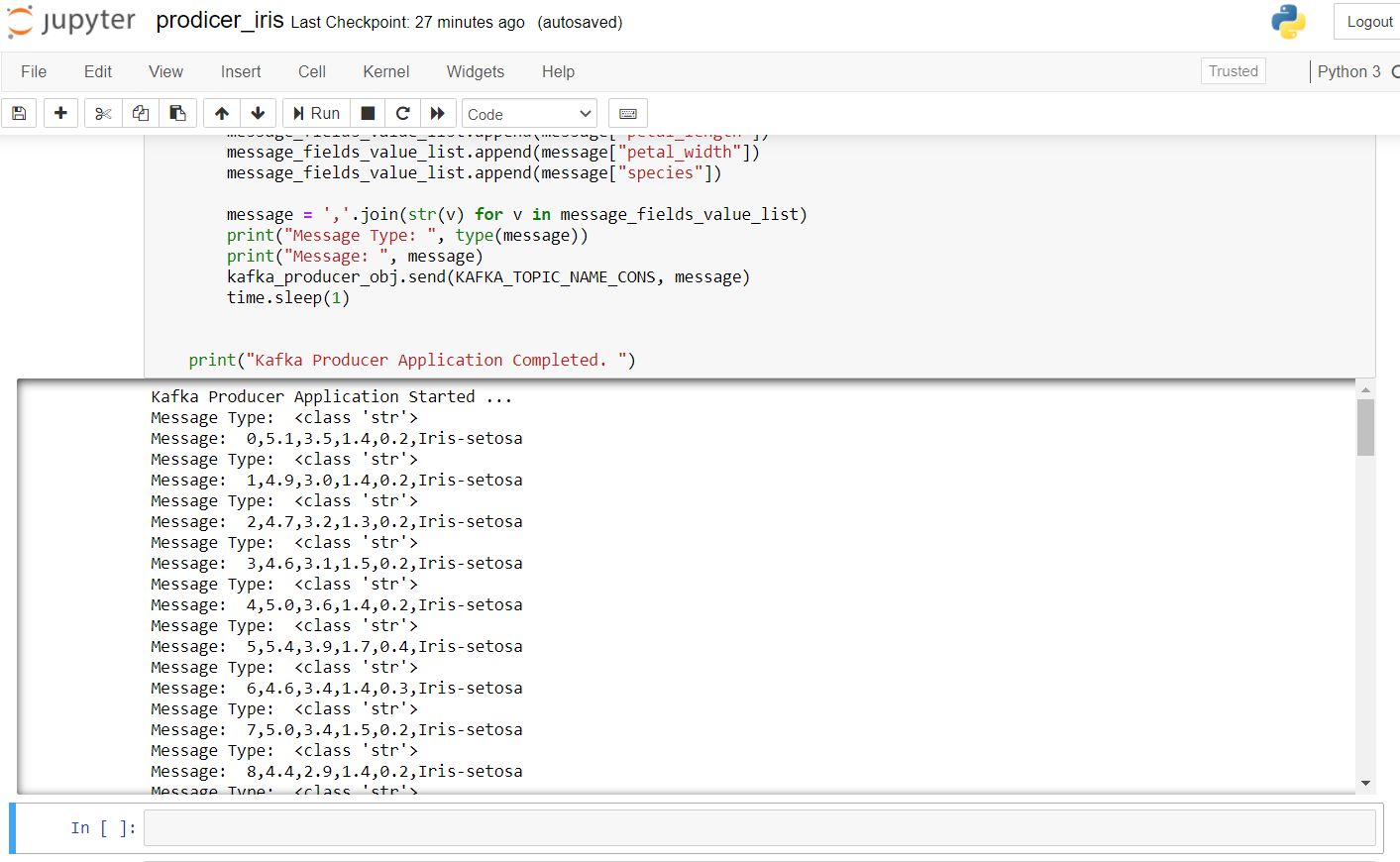
Ce qui suit est le code du producteur pour transmettre les données d'iris:
Pour démarrer le producteur, nous devons exécuter zkserver en tant qu’administrateur à l’invite de commandes Windows, puis démarrer Kafka en utilisant: .binwindowskafka-server-start.bat .configserver.properties à partir de l’invite de commandes dans le répertoire Kafka. Si vous obtenez une erreur de “pas de courtier”, signifie que Kafka ne fonctionne pas correctement.
le résultat après l’exécution de ce code dans le classeur jupyter ressemble à ceci:
À présent, passons en revue le consommateur. Exécutez le code suivant pour voir s’il fonctionne bien sur un nouvel ordinateur portable.
Una vez que ejecute esto, debería obtener un resultado como este:
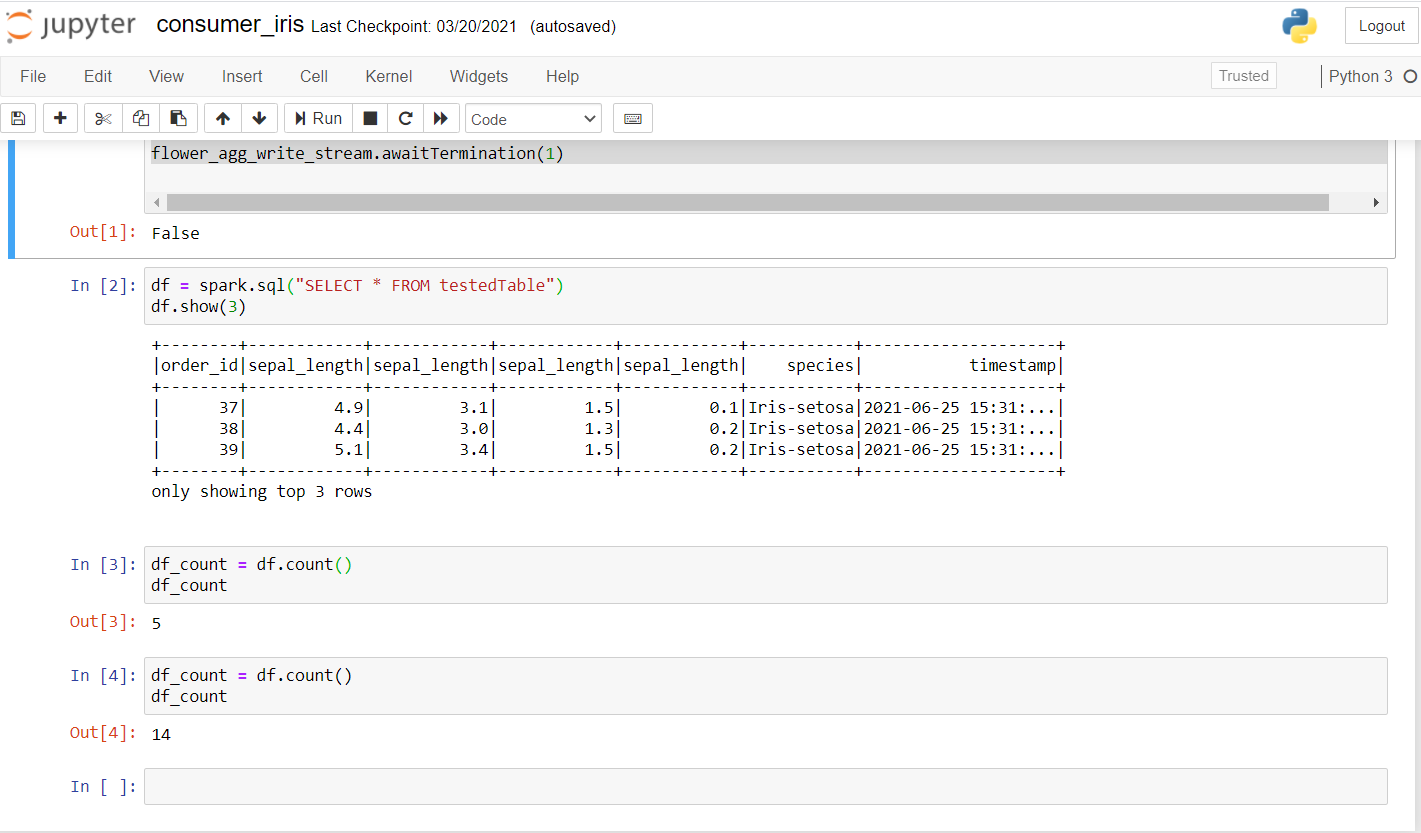
Comme tu peux le voir, effectué quelques enquêtes et vérifié si les données étaient en cours de transmission. Le premier compte était 5 Oui, après quelques secondes, le compte est passé à 14, confirmer que les données sont transmises.
Ici, essentiellement, l'idée est de créer un contexte d'étincelle. Nous obtenons les données en transmettant Kafka à notre sujet sur le port spécifié. La session Spark peut être créée à l'aide de getOrCreate () comme indiqué dans le code. L'étape suivante comprend la lecture du flux Kafka et les données peuvent être chargées à l'aide de load (). Étant donné que les données sont transmises, il serait utile d'avoir un horodatage dans lequel chacun des enregistrements est arrivé. Nous spécifions le schéma comme nous le faisons dans notre SQL et créons enfin une trame de données avec les valeurs des données transmises avec son horodatage. Enfin, avec un temps de traitement de 5 secondes, nous pouvons recevoir des données par lots. Nous utilisons SQL View pour stocker temporairement des données en mémoire en mode attaché et nous pouvons effectuer toutes les opérations dessus à l'aide de notre cadre de données Spark.
Voir le code complet ici:
https://github.com/Siddharth1698/Structured-Streaming-Tutorial
C'est l'un de mes projets de streaming Spark, vous pouvez vous y référer pour des requêtes plus détaillées et l'utilisation de l'apprentissage automatique dans Spark:
https://github.com/Siddharth1698/Spotify-Recommendation-System-using-Pyspark-and-Kafka
Les références
1. https://github.com/Siddharth1698/Structured-Streaming-Tutorial
2. https://dzone.com/articles/running-apache-kafka-on-windows-os
3. https://phoenixnap.com/kb/install-spark-on-windows-10
4. https://drive.google.com/drive/u/0/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw
5. https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
6. Vignette -> https://unsplash.com/photos/ImcUkZ72oUs
conclusion
Si vous suivez ces étapes, vous pouvez facilement configurer tous les environnements et exécuter votre premier programme de streaming structuré avec Spark et Kafka. En cas de difficulté de mise en place, Ne hésitez pas à me contacter:
[email protégé]
https://www.linkedin.com/in/siddharth-m-426a9614a/





