introduction
Un défi commun que j'ai rencontré pendant que apprendre le traitement du langage naturel (PNL) – Peut-on construire des modèles pour des langues autres que l'anglais? La réponse est non depuis un certain temps.. Chaque langue a ses propres modèles grammaticaux et nuances linguistiques. Et il n'y a tout simplement pas beaucoup d'ensembles de données disponibles dans d'autres langues.
C'est là qu'intervient la dernière bibliothèque PNL de Stanford.: StanfordPNL.
Je pouvais à peine contenir mon excitation quand j'ai lu les nouvelles la semaine dernière. Les auteurs ont déclaré que StanfordNLP pouvait prendre en charge plus de 53 langages humains. Oui, J'ai dû vérifier ce numéro.
J'ai décidé de vérifier moi-même. Il n'y a pas encore de tutoriel officiel pour la bibliothèque, j'ai donc eu la chance d'expérimenter et de jouer avec. Et j'ai découvert qu'il ouvre un monde de possibilités infinies. StanfordNLP contient des modèles pré-entraînés pour des langues asiatiques rares comme l'hindi, Chinois et japonais dans leurs écritures originales.

La possibilité de travailler avec plusieurs langues est une merveille que tous les passionnés de PNL recherchent. Dans cet article, nous allons analyser ce qu'est StanfordNLP, Pourquoi est-ce si important, puis nous activerons Python pour le voir en direct en action. Nous prendrons également une étude de cas hindi pour montrer comment fonctionne StanfordNLP, Vous ne voulez pas manquer ça!
Table des matières
- Qu'est-ce que StanfordNLP et pourquoi devriez-vous l'utiliser?
- Configuration StanfordNLP en Python
- Utiliser StanfordNLP pour effectuer des tâches de base en PNL
- Implémentation de StanfordNLP en hindi
- Utilisation de l'API CoreNLP pour l'analyse de texte
Qu'est-ce que StanfordNLP et pourquoi devriez-vous l'utiliser?
Voici la description de StanfordNLP par les auteurs eux-mêmes:
StanfordNLP est la combinaison du progiciel utilisé par l'équipe de Stanford dans la tâche partagée CoNLL 2018 sur l'analyse de dépendance universelle et l'interface Python officielle du groupe pour le Logiciel Stanford CoreNLP.
C'est trop d'informations à la fois !! Décomposons-le:
- CoNLL est une conférence annuelle sur l'apprentissage des langues naturelles. Des équipes représentant des instituts de recherche du monde entier tentent de résoudre un problème. PNL basé sur les tâches
- L'une des tâches de l'année dernière était « Analyse multilingue du texte brut aux dépendances universelles ». En termes simples, signifie analyser des données textuelles non structurées de plusieurs langues en annotations utiles de dépendances universelles.
- Les dépendances universelles sont un cadre qui maintient la cohérence dans les annotations. Ces annotations sont générées pour le texte quelle que soit la langue analysée.
- La présentation de Stanford s'est classée première dans 2017. Ils ont perdu la première place dans 2018 à cause d'un bug logiciel (a terminé à la quatrième place)
StanfordNLP est une collection de modèles de pointe pré-entraînés. Ces modèles ont été utilisés par les chercheurs dans les compétitions CoNLL. 2017 Oui 2018. Tous les modèles sont basés sur PyTorch et peuvent être entraînés et évalués avec vos propres données annotées. Impressionnant!
 davantage, StanfordNLP contient également un conteneur officiel pour la bibliothèque NLP géante populaire: NoyauPNL. Cela avait été quelque peu limité à l'écosystème Java jusqu'à présent. Vous devriez consulter ce didacticiel pour en savoir plus sur CoreNLP et son fonctionnement en Python.
davantage, StanfordNLP contient également un conteneur officiel pour la bibliothèque NLP géante populaire: NoyauPNL. Cela avait été quelque peu limité à l'écosystème Java jusqu'à présent. Vous devriez consulter ce didacticiel pour en savoir plus sur CoreNLP et son fonctionnement en Python.
Voici quelques autres raisons pour lesquelles vous devriez consulter cette bibliothèque:
- Implémentation native de Python qui nécessite un effort minimal de configuration
- Canalización de neuronal rougeLes réseaux de neurones sont des modèles computationnels inspirés du fonctionnement du cerveau humain. Ils utilisent des structures appelées neurones artificiels pour traiter et apprendre des données. Ces réseaux sont fondamentaux dans le domaine de l’intelligence artificielle, permettant des avancées significatives dans des tâches telles que la reconnaissance d’images, Traitement du langage naturel et prédiction de séries temporelles, entre autres. Leur capacité à apprendre des motifs complexes en fait des outils puissants.. completa para un análisis de texto sólido, qui inclus:
- Tokenisation
- Extension de jeton multi-mots (MWT)
- Lématisation
- Étiquetage des parties du discours (PDV) et caractéristiques morphologiques
- Analyse de dépendance
- Modèles neuronaux pré-entraînés qui prennent en charge 53 expressions idiomatiques (humains) Présenté dans 73 bancs d'arbre
- Une interface Python stable et officiellement maintenue pour CoreNLP
Que demander de plus pour un passionné de PNL ?? Maintenant que nous avons une idée de ce que fait cette bibliothèque, Faisons un tour en python!
Configuration StanfordNLP en Python
Il y a des choses bizarres à propos de la bibliothèque qui m'ont d'abord intrigué. Par exemple, vous avez besoin Python 3.6.8 / 3.7.2 ou plus tard pour utiliser StanfordNLP. Pour être sûr, J'ai mis en place un environnement séparé dans Anaconda pour Python 3.7.1. C'est comme ça que tu peux faire:
1. Ouvrez l'invite conda et tapez ceci:
conda créer -n stanfordnlp python=3.7.1
2. Activez maintenant l'environnement:
source activer stanfordnlp
3. Installer la bibliothèque StanfordNLP:
pip installer stanfordnlp
4. Nous devons télécharger le modèle spécifique d'une langue pour travailler avec elle. Démarrez un shell Python et importez StanfordNLP:
importer stanfordnlp
puis téléchargez le modèle de langue pour l'anglais (« dans »):
stanfordnlp.télécharger('au')
Cela peut prendre un certain temps en fonction de votre connexion Internet.. Ces modèles de langage sont assez grands (L'anglais vient de 1,96 FR).
Quelques notes importantes
- StanfordNLP est basé sur PyTorch 1.0.0. Pourrait planter si vous avez une ancienne version. Ensuite, Nous vous montrons comment vérifier la version installée sur votre machine:
gel de pépin | torche grep
qui devrait donner une sortie comme torch==1.0.0
- J'ai essayé d'utiliser la bibliothèque sans GPU sur mon Lenovo Thinkpad E470 (8Go de RAM, Graphiques Intel). J'ai eu une erreur de mémoire en Python assez rapidement. Donc, Je suis passé à une machine compatible GPU et je vous conseillerais de faire de même. Tu peux essayer Google Colab qui vient avec un support GPU gratuit
C'est tout! Plongeons tout de suite dans certains processus de base de la PNL..
Utiliser StanfordNLP pour effectuer des tâches de base en PNL
StanfordNLP est livré avec des processeurs intégrés pour effectuer cinq tâches NLP de base:
- Tokenisation
- Extension de jeton multi-mots
- Lématisation
- Parties de l'étiquetage de la parole
- Analyse de dépendance
Commençons par créer un pipeline de texte:
nlp = stanfordnlp.Pipeline(processeurs = "tokeniser,mwt,lemme,position")
doc = pnl("""Les perspectives d'un retrait ordonné de la Grande-Bretagne de l'Union européenne en mars 29 ont encore reculé, alors même que les députés se sont rassemblés pour arrêter un scénario de non-accord. Un amendement au projet de loi sur la fin de l'adhésion de Londres au bloc oblige la Première ministre Theresa May à renégocier son accord de retrait avec Bruxelles. La proposition d'un député conservateur appelle le gouvernement à proposer des alternatives au backstop irlandais, un principe central de l'accord que la Grande-Bretagne a conclu avec le reste de l'UE.""")
Les processeurs = « » L'argument est utilisé pour spécifier la tâche. Les cinq processeurs sont pris par défaut si aucun argument n'est passé. Voici un bref aperçu des processeurs et de ce qu'ils peuvent faire:

Voyons chacun d'eux en action.
Tokenisation
Ce processus se produit implicitement une fois que le processeur Token est en cours d'exécution. En réalité, c'est assez rapide. Vous pouvez jeter un œil aux jetons en utilisant print_tokens ():
doc.phrases[0].print_tokens()
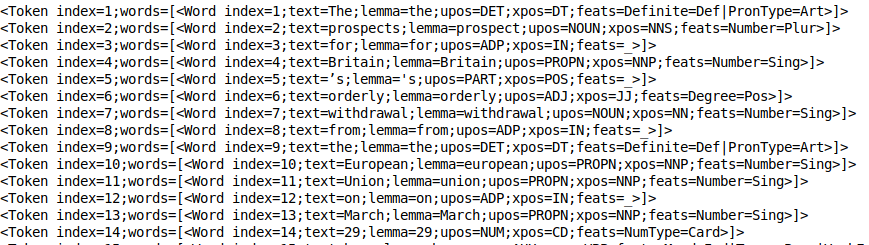
El objeto token contiene el indiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines.... del token en la oración y una lista de objetos de palabra (dans le cas d'un jeton multi-mots). Chaque objet mot contient des informations utiles, comme index du mot, la devise du texte, balise de position (parties du discours) et la balise feat (caractéristiques morphologiques).
Lématisation
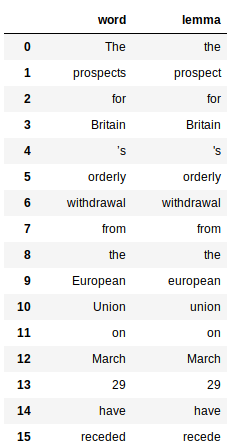
Cela implique l'utilisation de la propriété « devise » des mots générés par le processeur de slogan. Voici le code pour obtenir la devise de tous les mots:
Cela renvoie un pandas trame de données pour chaque mot et sa devise respective:
Étiquetage des parties du discours (Point de vente)
Le tagueur PoS est assez rapide et fonctionne très bien dans toutes les langues. Comme les slogans, Les balises PoS sont également faciles à supprimer:
Remarquez le grand dictionnaire dans le code ci-dessus? C'est juste un mappage entre les balises PoS et leur signification. Cela permet de mieux comprendre la structure syntaxique de notre document.
La sortie serait un bloc de données avec trois colonnes: mot, pos et exp (Explication). La colonne d'explication nous donne le plus d'informations sur le texte (Oui, donc, c'est bien utile).
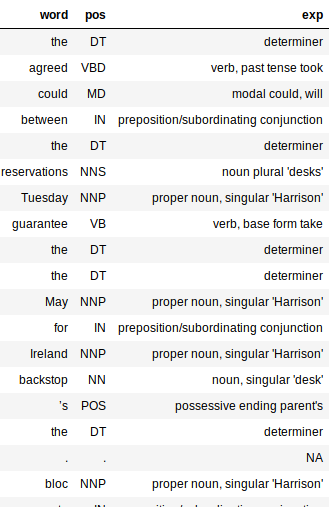
L'ajout de la colonne d'explication permet d'évaluer plus facilement la précision de notre processeur. J'aime le fait que le tagueur soit précis pour la plupart des mots. Il capture même le temps d'un mot et s'il est sous forme basique ou plurielle.
Extraction de dépendances
L'extraction de dépendances est une autre fonctionnalité prête à l'emploi de StanfordNLP. Vous pouvez simplement appeler print_dependencies () dans une phrase pour obtenir les rapports de dépendance pour tous vos mots:
doc.phrases[0].print_dependencies()

La bibliothèque calcule tout ce qui précède au cours d'une seule exécution de pipeline. Cela ne prendra que quelques minutes sur une machine compatible GPU..
Maintenant, nous avons découvert un moyen de faire du traitement de texte de base avec StanfordNLP. Il est temps de profiter du fait que nous pouvons faire de même pour les autres ! 51 langues!
Implémentation de StanfordNLP en hindi
StanfordNLP se démarque vraiment par ses performances d'analyse de texte multilingue et son support. Approfondissons ce dernier aspect.
Traitement de texte hindi (script devanagari)
Premier, nous devons télécharger le modèle de langue hindi (Comparativement plus petit!):
stanfordnlp.télécharger('salut')
À présent, prendre un extrait de texte hindi comme document texte:
hindi_doc = nlp("""Le gouvernement Modi au Centre a présenté vendredi son budget intérimaire.. Le ministre des Finances par intérim Piyush Goyal dans son budget, La main d'oeuvre, contribuable, Pare-chocs annoncés pour tout le monde, y compris les femmes. Même si, Même après le budget, il y avait beaucoup de confusion au sujet de la taxe.. Quelle était la particularité de ce budget provisoire du gouvernement central et qui a obtenu quoi, comprendre ici en langage facile""")
Cela devrait suffire pour générer toutes les étiquettes. Vérifions les balises pour l'hindi:
extract_pos(hindi_doc)
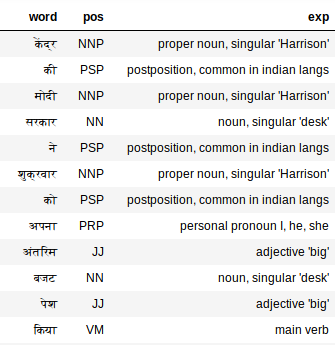
Le tagueur PoS fonctionne également étonnamment bien sur le texte hindi. Voir « Mon », par exemple. Le tagueur PoS l'étiquette comme un pronom, je, il, elle, qu'est-ce qui est exact.
Utilisation de l'API CoreNLP pour l'analyse de texte
NoyauPNL est une boîte à outils NLP de qualité industrielle éprouvée qui est connue pour ses performances et sa précision. StanfordNLP a été déclaré interface Python officielle pour CoreNLP. C'est une GRANDE victoire pour cette bibliothèque.
Il y a eu des efforts auparavant pour créer des packages d'encapsulation Python pour CoreNLP, mais rien ne vaut une implémentation officielle des auteurs eux-mêmes. Cela signifie que la bibliothèque verra des mises à jour et des améliorations régulières..
StanfordNLP nécessite trois lignes de code pour commencer à utiliser l'API sophistiquée CoreNLP. Littéralement, Juste trois lignes de code pour le configurer !!
1. Télécharger le package CoreNLP. Ouvrez votre terminal Linux et tapez la commande suivante:
wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
2. Décompressez le package téléchargé:
décompressez stanford-corenlp-full-2018-10-05.zip
3. Démarrer le serveur CoreNLP:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -temps libre 15000
Noter: CoreNLP nécessite Java8 pour fonctionner. Assurez-vous que JDK et JRE 1.8.x sont installés.
À présent, assurez-vous que StanfordNLP sait où CoreNLP est présent. Pour ça, doit exporter $ CORENLP_HOME comme emplacement de votre dossier. Dans mon cas, ce dossier était dans domicile en soi pour que mon chemin soit comme
export CORENLP_HOME=stanford-corenlp-full-2018-10-05/
Une fois les étapes ci-dessus effectuées, vous pouvez démarrer le serveur et faire des requêtes en code python. Vous trouverez ci-dessous un exemple complet de démarrage d'un serveur, faire des requêtes et accéder aux données de l'objet retourné.
ongle. Configuration du client principalNLPC
B. Analyse de dépendance et POS
C. Reconnaissance des entités nommées et des chaînes de co-référence
Les exemples ci-dessus effleurent à peine la surface de ce que CoreNLP peut faire et, cependant, c'est très intéressant, nous avons pu tout accomplir, des tâches de base de la PNL comme l'étiquetage de parties du discours à des choses comme la reconnaissance d'entités nommées, extraire des chaînes de co-référence et trouver qui a écrit quoi. dans une phrase en quelques lignes de code Python.
Ce que j'aime le plus ici, c'est la facilité d'utilisation et l'accessibilité accrue que cela apporte lorsqu'il s'agit d'utiliser CoreNLP en Python.
Mes réflexions sur l'utilisation de StanfordNLP – Avantages et les inconvénients
Explorer une bibliothèque nouvellement lancée était certainement un défi. Il n'y a pratiquement pas de documentation sur StanfordNLP! Cependant, ce fut une expérience d'apprentissage assez agréable.
Certaines choses qui m'excitent concernant l'avenir de StanfordNLP:
- Votre prise en charge prête à l'emploi pour plusieurs langues
- Le fait que ce sera une interface Python officielle pour CoreNLP. Cela signifie qu'il ne fera qu'améliorer la fonctionnalité et la facilité d'utilisation à l'avenir..
- C'est assez rapide (sauf l'énorme empreinte mémoire)
- Configuration simple en Python
Cependant, il y a des fissures à résoudre. Vous trouverez ci-dessous mes réflexions sur les domaines dans lesquels StanfordNLP pourrait s'améliorer:
- La taille des modèles de langage est trop grande (L'anglais vient de 1,9 FR, chinois ~ 1,8 FR)
- La bibliothèque nécessite beaucoup de code pour produire des fonctions. Comparez cela à NLTK, où vous pouvez rapidement écrire un prototype; cela pourrait ne pas être possible pour StanfordNLP
- Fonctionnalités d'affichage actuellement manquantes. Il est utile de l'avoir pour des fonctions comme l'analyse de dépendance. StanfordNLP échoue ici par rapport aux bibliothèques comme SpaCy
Assurez-vous de vérifier Documentation officielle de StanfordNLP.
Remarques finales
Il y a encore une fonction que je n'ai pas encore essayé. StanfordNLP vous permet d'entraîner des modèles sur vos propres données annotées à l'aide des intégrations Word2Vec / Texte rapide. J'aimerais l'explorer à l'avenir et voir à quel point cette fonctionnalité est efficace.. Je mettrai à jour l'article quand la bibliothèque mûrira un peu.
Clairement, StanfordNLP est en phase bêta. Cela ne fera que s'améliorer à partir d'ici, c'est donc le bon moment pour commencer à l'utiliser: avoir un avantage sur tout le monde.
Pour l'instant, le fait que ces incroyables boîtes à outils (NoyauPNL) atteignent l'écosystème Python et des géants de la recherche comme Stanford s'efforcent d'ouvrir leur logiciel open source, je suis optimiste pour l'avenir.





