Cet article a été publié dans le cadre du Blogathon sur la science des données
Un système de recommandation est l'une des principales applications de la science des données. Chaque entreprise Internet grand public a besoin d'un système de recommandation comme Netflix, Youtube, un service de nouvelles, etc. Ce que vous voulez montrer à partir d'un large éventail d'articles est un système de recommandation.

Table des matières
- Introduction à un système de recommandation
- Types de système de recommandation
- Système de recommandation de livres
- Filtrage basé sur le contenu
- Filtrage collaboratif
- Filtrage hybride
- Système de recommandations pratiques
- Description de l'ensemble de données
- Prétraiter les données
- Effectuer l'EDA
- Regroupement
- Prédictions
- Remarques finales
Quel est vraiment le système de recommandation?
Un moteur de recommandation est une classe d'apprentissage automatique qui offre des suggestions pertinentes au client. Avant le système de recommandation, la plus grande tendance à acheter était d'accepter une suggestion d'amis. Mais maintenant, Google sait quelles nouvelles il va lire, Youtube sait quel type de vidéos vous verrez en fonction de votre historique de recherche, historique des vidéos regardées ou historique des achats.
Un système de recommandation aide une organisation à fidéliser les clients et à renforcer la confiance dans les produits et services souhaités pour ceux qui sont venus sur votre site.. Le système de recommandation actuel est si puissant qu'il peut également gérer le nouveau client qui a visité le site pour la première fois.. Ils recommandent des produits tendance ou très bien notés et peuvent également recommander des produits qui apportent le maximum d'avantages à l'entreprise.
Types de système de recommandation
Un système de recommandation est généralement construit en utilisant 3 techniques de filtrage basé sur le contenu, filtrage collaboratif et une combinaison des deux.
1) Filtrage basé sur le contenu
L'algorithme recommande un produit similaire à ceux utilisés comme regards. En mots simples, dans cet algorithme, nous essayons de trouver un élément qui ressemble. Par exemple, une personne aime voir des photos de Sachin Tendulkar, vous aimerez donc peut-être aussi voir des photos de Ricky Ponting car les deux vidéos ont des balises et des catégories similaires.
Seulement, il semble similaire entre les contenus et ne se concentre pas davantage sur la personne qui regarde cela. Ne recommandez que le produit qui a le score le plus élevé en fonction des préférences passées.
2) Filtrage basé sur la collaboration
Les systèmes de recommandation de filtrage basés sur la collaboration sont basés sur les interactions passées des utilisateurs et des éléments cibles. En mots simples, Nous essayons de trouver des clients similaires et proposons des produits en fonction de ce qu'ils ont choisi leur apparence. Comprenons avec un exemple. X et Y sont deux utilisateurs similaires et l'utilisateur X a regardé les films A, Par C. ET l'utilisateur Y a regardé des films B, C y D, alors nous recommanderons un film à l'utilisateur Y et un film D à l'utilisateur X.
YouTube a changé son système de recommandation d'une technique de filtrage basée sur le contenu à une technique basée sur la collaboration.. Si vous avez déjà expérimenté, il y a aussi des vidéos qui n'ont rien à voir avec ton histoire, mais il le recommande aussi parce que l'autre personne semblable à vous l'a vu.
3) Méthode de filtrage hybride
Il s'agit essentiellement d'une combinaison des deux méthodes précédentes. C'est un modèle trop complexe qui recommande un produit en fonction de son histoire et d'utilisateurs similaires comme vous.
Certaines organisations utilisent cette méthode, comme Facebook, qui diffuse des informations importantes pour vous et pour d'autres membres de votre réseau. Linkedin l'utilise également..
Système de recommandation de livres
Un système de recommandation de livres est un type de système de recommandation dans lequel nous devons recommander des livres similaires au lecteur en fonction de son intérêt.. Le système de recommandation de livres est utilisé par les sites Web en ligne qui fournissent des livres électroniques tels que Google Play Books, bibliothèque ouverte, bonnes lectures, etc.
Dans cet article, nous utiliserons la méthode de filtrage basée sur la collaboration pour créer un système de recommandation de livres. Vous pouvez télécharger l'ensemble de données à partir de ici
Mise en œuvre pratique du système de recommandation
Mettons-nous les mains dans le cambouis en essayant de mettre en place un système de recommandation de livres utilisant le filtrage collaboratif.
Description de l'ensemble de données
avoir 3 fichiers dans notre ensemble de données qui sont tirés de certains livres qui vendent des sites Web.
- Livres: ce sont d'abord les livres qui contiennent toutes les informations relatives aux livres, en tant qu'auteur, le titre, l'année de parution, etc.
- Utilisateurs: le deuxième fichier contient les informations de l'utilisateur enregistré, comme identifiant d'utilisateur, Lieu.
- notes: les notes contiennent des informations telles que quel utilisateur a donné la note à quel livre.
Ensuite, sur la base de ces trois fichiers, nous pouvons construire un puissant modèle de filtrage collaboratif. commençons.
Charger les données
commençons par importer des bibliothèques et charger des ensembles de données. lors du chargement du fichier, nous avons quelques problèmes comme.
- Les valeurs du fichier CSV sont séparées par des points-virgules, pas par le coma.
- Il y a des lignes qui ne fonctionnent pas comme si nous ne pouvions pas les importer avec les pandas et cela génère une erreur car Python est un langage interprété.
- L'encodage d'un fichier est en latin
Ensuite, lors du chargement des données, nous devons gérer ces exceptions et après avoir exécuté le code suivant, vous recevrez un avertissement et il montrera quelles lignes ont une erreur que nous avons manquée lors du chargement.
importer numpy en tant que np
importer des pandas au format pd
livres = pd.read_csv("BX-Livres.csv", sep=';', encodage="latin-1", error_bad_lines=Faux)
utilisateurs = pd.read_csv("BX-Utilisateurs.csv", sep=';', encodage="latin-1", error_bad_lines=Faux)
notes = pd.read_csv("BX-Book-Ratings.csv", sep=';', encodage="latin-1", error_bad_lines=Faux)
Pré-traitement des données
À présent, dans les archives du livre, nous avons des colonnes supplémentaires qui ne sont pas nécessaires pour notre tâche, comme les URL des images. Et nous renommerons les colonnes de chaque fichier car le nom de la colonne contient de l'espace et des majuscules pour que nous puissions le corriger pour le rendre facile à utiliser.
livres = livres[['ISBN', 'Titre de livre', 'Livre-Auteur', 'Année de publication', 'Éditeur']]
livres.renommer(colonnes = {'Titre de livre':'Titre', 'Livre-Auteur':'auteur', 'Année de publication':'année', 'Éditeur':'éditeur'}, inplace=Vrai)
utilisateurs.renommer(colonnes = {'Identifiant d'utilisateur':'identifiant d'utilisateur', 'Emplacement':'emplacement', 'Âge':'âge'}, inplace=Vrai)
notes.renommer(colonnes = {'Identifiant d'utilisateur':'identifiant d'utilisateur', 'Classement du livre':'évaluation'}, inplace=Vrai)
À présent, si vous voyez l'en-tête de chaque bloc de données, tu peux voir quelque chose comme ça.
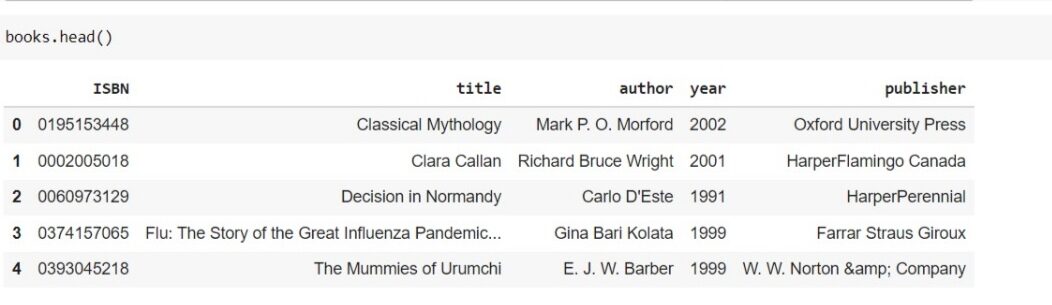
L'ensemble de données est fiable et peut être considéré comme un grand ensemble de données. Ont 271360 livres de données et le nombre total d'utilisateurs enregistrés sur le site Web est d'environ 278000 et ont donné une note de près de 11 lakh. donc, nous pouvons dire que l'ensemble de données dont nous disposons est bon et fiable.
Approche pour poser un problème
Nous ne voulons pas trouver de similitudes entre les utilisateurs ou les livres. nous voulons le faire S'il y a un utilisateur A qui a lu et aimé les livres x et y, et l'utilisateur B a également aimé ces deux livres et maintenant l'utilisateur A a lu et aimé un livre z qui n'est pas lu par B, nous devons donc recommander z book à l'utilisateur B. C'est ça le filtrage collaboratif.
Ensuite, ceci est réalisé en utilisant la factorisation matricielle, nous allons créer une matrice où les colonnes seront les utilisateurs et les index seront les livres et la valeur sera la note. Como si tuviéramos que crear una table dynamiqueLe tableau croisé dynamique est un outil puissant dans les tableurs, tels que Microsoft Excel et Google Sheets. Vous permet de résumer, Analysez et visualisez efficacement de grands volumes de données. Grâce à son interface intuitive, Les utilisateurs peuvent réorganiser les informations, Appliquez des filtres et créez des rapports personnalisés, faciliter la prise de décisions éclairées dans divers contextes, Du domaine de l’entreprise à la recherche académique.....
Un gros défaut avec un énoncé de problème dans l'ensemble de données.
Si on prend tous les livres et tous les utilisateurs pour modéliser, Ne penses-tu pas que cela va créer un problème? Donc ce qu'il faut faire c'est réduire le nombre d'utilisateurs et de livres car on ne peut pas considérer un utilisateur qui s'est seulement inscrit sur le site ou qui n'a lu qu'un ou deux livres. Dans un tel utilisateur, nous ne pouvons pas compter sur la recommandation de livres à d'autres parce que nous devons extraire des connaissances des données. Ensuite, nous allons limiter ce nombre et prendre un utilisateur qui a noté au moins 200 livres et nous limiterons également les livres et ne prendrons que les livres qui ont reçu au moins 50 évaluations des utilisateurs.
L'analyse exploratoire des données
Commençons donc par l'analyse et préparons l'ensemble de données comme nous en avons discuté pour la modélisation. Voyons combien d'utilisateurs ont donné des notes et extrayons les utilisateurs qui ont donné plus de 200 notes.
notes['identifiant d'utilisateur'].value_counts()
Paso 1) Extraire les utilisateurs et les évaluations de plus de 200
lorsque vous exécutez le code ci-dessus, nous pouvons voir que seulement 105283 les gens ont donné une note entre 278000. Nous allons maintenant extraire les identifiants d'utilisateurs qui ont accordé plus de 200 notes et lorsque nous aurons les identifiants d'utilisateur, nous extrairons les qualifications de ces identifiants d'utilisateur à partir du cadre de données de qualification.
x = notes['identifiant d'utilisateur'].value_counts() > 200
y = x[X].index #user_ids
print(y.forme)
notes = notes[notes['identifiant d'utilisateur'].rayon(Oui)]
pas-2) Fusionner les notes avec les livres
Ensuite il y a 900 les utilisateurs qui ont donné une note de 5.2 lakh et c'est ce que nous voulons. Maintenant, nous allons fusionner les notes avec les livres basés sur l'ISBN afin que nous obtenions la note de chaque utilisateur sur chaque identifiant de livre et l'utilisateur qui n'a pas noté cet identifiant de livre, la valeur sera zéro.
rating_with_books = ratings.merge(livres, sur='ISBN') rating_with_books.head()

pas-3) Découvrez les livres qui ont reçu plus de 50 notes.
Maintenant, la taille du bloc de données a diminué et nous avons 4.8 lakh parce que lorsque nous fusionnons le bloc de données, nous n'avions pas toutes les données d'identification du livre. Maintenant, nous allons compter la note de chaque livre, nous allons donc regrouper les données en fonction du titre et les données agrégées en fonction de la notation.
number_rating = rating_with_books.groupby('Titre')['évaluation'].compter().reset_index()
nombre_rating.renommer(colonnes= {'évaluation':'number_of_ratings'}, inplace=Vrai)
note_finale = note_avec_livres.merge(nombre_classement, on='titre')
note_finale.forme
note_finale = note_finale[note_finale['number_of_ratings'] >= 50]
final_rating.drop_duplicates(['identifiant d'utilisateur','Titre'], inplace=Vrai)
nous devons supprimer les valeurs en double car si le même utilisateur a évalué le même livre plusieurs fois, va créer un problème. Finalement, nous avons un ensemble de données avec cet utilisateur qui a évalué plus de 200 livres et livres qui ont reçu plus de 50 notes. la forme de la trame de données finale est 59850 rangées et 8 Colonnes.
Paso 4) Créer un tableau croisé dynamique
Comme nous en avons discuté plus tôt, nous allons créer un tableau croisé dynamique dans lequel les colonnes seront les identifiants des utilisateurs, les indiceLe "Indice" C’est un outil fondamental dans les livres et les documents, qui vous permet de localiser rapidement les informations souhaitées. Généralement, Il est présenté au début d’une œuvre et organise les contenus de manière hiérarchique, y compris les chapitres et les sections. Sa préparation correcte facilite la navigation et améliore la compréhension du matériau, ce qui en fait une ressource incontournable tant pour les étudiants que pour les professionnels dans divers domaines.... será el título del libro y el valor las calificaciones. Et l'identifiant d'utilisateur qui n'a évalué aucun livre aura la valeur de NAN, alors imputez-le avec zéro.
book_pivot = classement_final.table_pivot(colonnes="identifiant d'utilisateur", index='titre', valeurs="évaluation") book_pivot.fillna(0, inplace=Vrai)
Nous pouvons voir que plus de 11 Les utilisateurs ont été supprimés car leurs notes étaient dans les livres qui ne reçoivent pas plus de 50 notes, donc ils sont supprimés de l'image.
La modélisation
Nous avons préparé notre jeu de données pour modéliser. Nous utiliserons l'algorithme des voisins les plus proches, qui est le même que le K le plus proche, qui est utilisé pour le regroupement basé sur la distance euclidienne.
Mais ici, dans le tableau croisé dynamique, nous avons beaucoup de valeurs nulles et dans le regroupement, cette puissance de calcul augmentera pour calculer la distance à partir des valeurs nulles, nous allons donc convertir le tableau croisé dynamique en matrice creuse, puis l'alimenter au modèle.
depuis scipy.sparse importer csr_matrix book_sparse = csr_matrix(book_pivot)
Nous allons maintenant entraîner l'algorithme des voisins les plus proches. ici, nous devons spécifier un algorithme qui est un moyen approximatif de trouver la distance de chaque point à tous les autres points.
de sklearn.neighbors importer NearestNeighbors modèle = NearestNeighbors(algorithm='brute') model.fit(book_sparse)
Faisons une prédiction et voyons si elle suggère des livres ou non. nous trouverons les voisins les plus proches de l'identifiant du livre d'entrée et après cela, nous imprimerons le 5 livres principaux qui sont les plus proches de ces livres. Il nous fournira la distance et l'identification du livre à cette distance. passons à Harry Potter, Qu'est ce qui ne va pas avec ça 237 indices.
distances, suggestions = model.kneighbors(book_pivot.iloc[237, :].valeurs.remodeler(1, -1))
imprimons tous les livres suggérés.
pour moi à portée(longueur(suggestions)): imprimer(book_pivot.index[suggestions[je]])
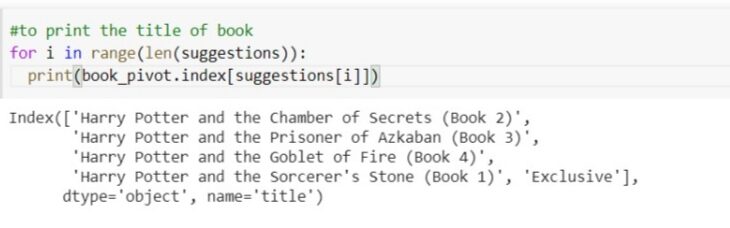
donc, nous avons construit avec succès un système de recommandation de livres.
Remarques finales
Viva! Nous devons construire un système de recommandation de livres fiable et vous pouvez le modifier et le transformer en un projet final. Il s'agit d'un merveilleux projet d'apprentissage non supervisé où nous avons effectué beaucoup de pré-traitement et vous pouvez explorer davantage l'ensemble de données et, si vous trouvez quelque chose de plus intéressant, partagez-le dans la zone de commentaire.
J'espère qu'il était facile de rattraper chaque méthode et de suivre l'article. Si vous avez une requête, postez-le dans la section commentaire ci-dessous. Je serai heureux de vous aider avec toutes les questions.
A propos de l'auteur
Raghav Agrawal
Je poursuis ma licence en informatique. J'aime beaucoup la science des données et le big data. J'aime travailler avec les données et apprendre de nouvelles technologies. S'il vous plait, n'hésitez pas à me contacter sur Linkedin.
Si vous aimez mon article, S'il vous plait, lisez-le aussi aux autres. Relier
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





