Cet article a été publié dans le cadre du Blogathon sur la science des données
L'imputation est une technique utilisée pour remplacer les données manquantes par une valeur de substitution afin de conserver la plupart des données / informations sur l'ensemble de données. Estas técnicas se utilizan porque eliminar los datos del conjunto de datos cada vez no es factible y puede conducir a una reducción en el tamaño del conjunto de datos en gran mesureLa "mesure" C’est un concept fondamental dans diverses disciplines, qui fait référence au processus de quantification des caractéristiques ou des grandeurs d’objets, phénomènes ou situations. En mathématiques, Utilisé pour déterminer les longueurs, Surfaces et volumes, tandis qu’en sciences sociales, il peut faire référence à l’évaluation de variables qualitatives et quantitatives. La précision des mesures est cruciale pour obtenir des résultats fiables et valides dans toute recherche ou application pratique...., ce qui soulève non seulement des inquiétudes quant au biais de l'ensemble de données, cela conduit également à une analyse incorrecte.
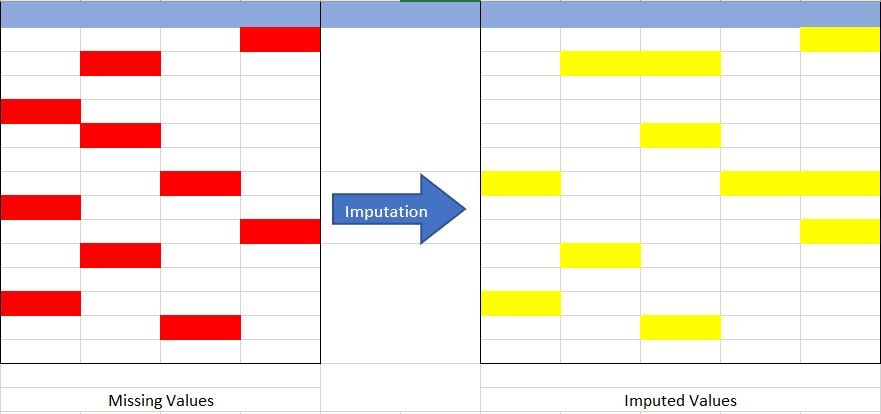
La source: créé par l'auteur
Je ne sais pas quelles données sont manquantes? Comment ça se passe? Et ton genre? Jetez un oeil ICI pour en savoir plus.
Comprenons le concept d'imputation de la figure {Figure 1} antérieur. Dans l'image ci-dessus, J'ai essayé de représenter les données manquantes dans le tableau de gauche (marqué en rouge) et en utilisant des techniques d'imputation, nous avons complété l'ensemble de données manquantes dans le tableau de droite (marqué en jaune), sans réduire la taille réelle de l'ensemble de données. Si nous réalisons ici, nous avons augmenté la taille de la colonne, ce qui est possible dans l'imputation (ajout de l'imputation de catégorie « Manque »).
Pourquoi l'imputation est-elle importante?
Ensuite, après avoir connu la définition de l'imputation, la question suivante est pourquoi devrions-nous l'utiliser et que se passerait-il si je ne l'utilise pas?
C'est parti avec les réponses aux questions précédentes.
Nous utilisons l'imputation parce que les données manquantes peuvent causer les problèmes suivants: –
- Incompatible avec la plupart des bibliothèques Python utilisées en Machine Learning: – Oui, tu lis bien. Lors de l'utilisation des bibliothèques pour le ML (le plus courant est skLearn), n'ont pas de disposition pour traiter automatiquement ces données manquantes et peuvent générer des erreurs.
- Distorsion dans l'ensemble de données: – Una gran cantidad de datos faltantes puede causar distorsiones en la distribución de la variableEn statistique et en mathématiques, ongle "variable" est un symbole qui représente une valeur qui peut changer ou varier. Il existe différents types de variables, et qualitatif, qui décrivent des caractéristiques non numériques, et quantitatif, représentation de grandeurs numériques. Les variables sont fondamentales dans les expériences et les études, puisqu’ils permettent l’analyse des relations et des modèles entre différents éléments, faciliter la compréhension de phénomènes complexes...., c'est-à-dire, peut augmenter ou diminuer la valeur d'une catégorie particulière dans l'ensemble de données.
- Affecte le modèle final: – les données manquantes peuvent entraîner un biais dans l'ensemble de données et peuvent conduire à une analyse erronée par le modèle.
Une autre raison et la plus importante est « Nous voulons restaurer l'ensemble de données complet ». Cela se produit principalement dans le cas où nous ne voulons pas perdre (plus) les données de notre jeu de données, puisque tout est important et, en second lieu, la taille de l'ensemble de données n'est pas très importante et en supprimer une partie peut avoir un impact significatif. dans le modèle final.
Excellent..!! nous avons quelques notions de base sur les données manquantes et l'imputation. À présent, Jetons un coup d'œil aux différentes techniques d'imputation et comparons-les. Mais avant de se lancer, nous devons connaître les types de données dans notre ensemble de données.
Cela semble étrange..!!! Ne vous inquiétez pas... La plupart des données proviennent de 4 les types: – Numérique, Catégorique, Date-heure et Mixte. Ces noms sont explicites, donc ils ne creusent pas beaucoup ou ne les décrivent pas.
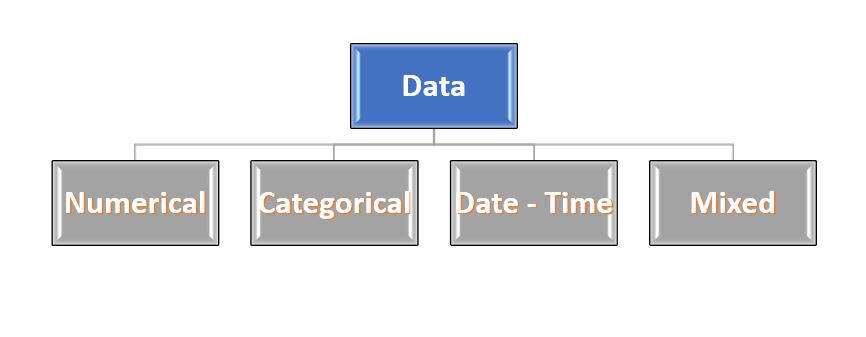
Figure 2: – Type de données
La source: créé par l'auteur
Techniques d'imputation
Passons aux points saillants de cet article … Techniques utilisées en imputation …
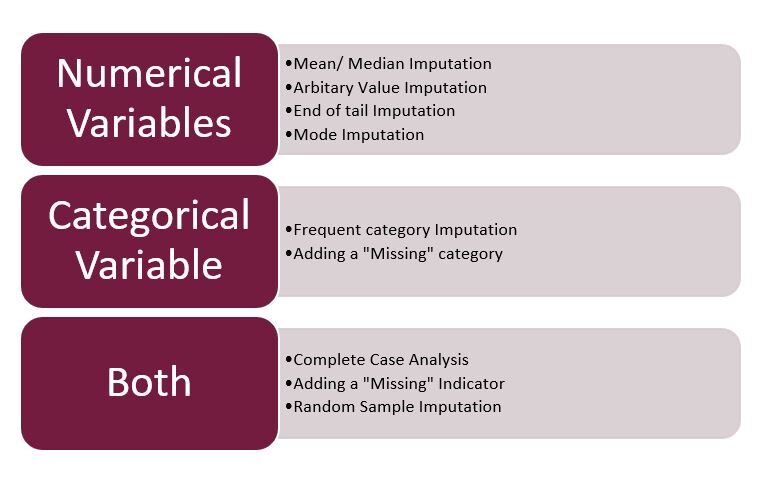
Figure 3: – Techniques d'imputation
La source: créé par l'auteur
Noter: – Ici, je me concentrerai uniquement sur l'imputation mixte, numérique et catégoriel. La date et l'heure feront partie du prochain article.
1. Analyse complète du cas (ACC): –
C'est une méthode assez simple pour gérer les données manquantes, qui supprime directement les lignes qui ont des données manquantes, c'est-à-dire, nous ne considérons que les lignes dans lesquelles nous avons des données complètes, c'est-à-dire, aucune donnée manquante. Cette méthode est également connue sous le nom de « supprimer par liste ».
- Hypothèses: –
- Des données aléatoires sont manquantes (MAR).
- Les données manquantes sont complètement supprimées de la table.
- avantage: –
- Facile à mettre en œuvre.
- Aucune manipulation de données requise.
- Limites: –
- Les données supprimées peuvent être informatives.
- Cela peut entraîner la suppression d'une grande partie des données.
- Vous pouvez créer un biais dans l'ensemble de données, si une grande quantité d'un type particulier de variable est supprimée.
- Le modèle de production ne saura pas quoi faire des données manquantes.
- Quand utiliser:-
- Les données sont MAR (Manquant au hasard).
- Bon pour les données mixtes, numérique et catégoriel.
- Les données manquantes ne sont pas plus de 5% à 6% de l'ensemble de données.
- Les données ne contiennent pas beaucoup d'informations et ne fausseront pas l'ensemble de données.
- Code:-
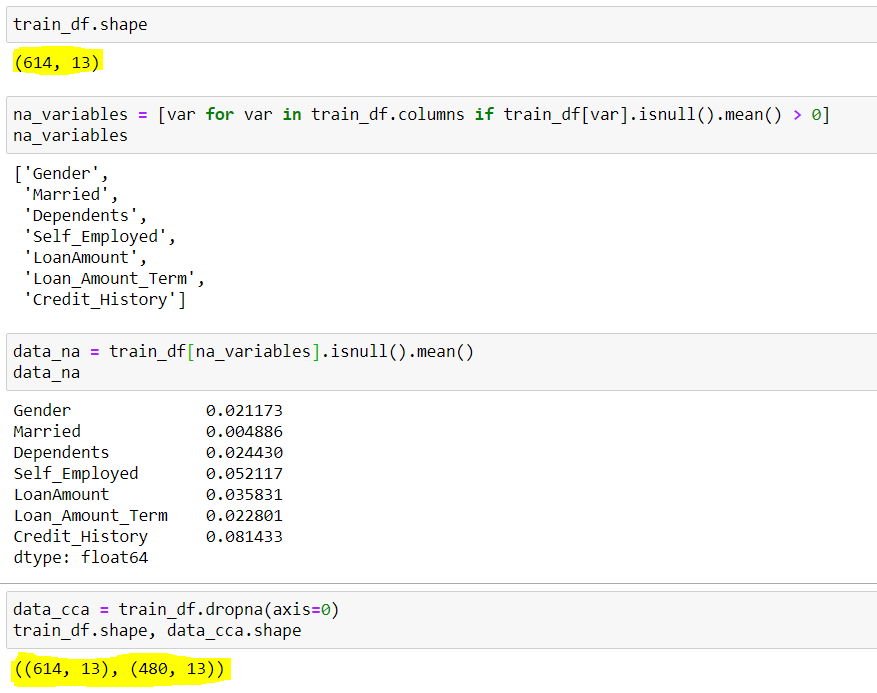
## Pour vérifier la forme de l'ensemble de données d'origine
train_df.shape
## Sortir (614 Lignes & 13 Colonnes) (614,13)
## Trouver les colonnes qui ont des valeurs nulles(Données manquantes) ## Nous utilisons une boucle for pour toutes les colonnes présentes dans l'ensemble de données avec des valeurs nulles moyennes supérieures à 0
na_variables = [ var pour var dans train_df.columns si train_df[où].est nul().moyenne() > 0 ]
## Sortie des noms de colonnes avec des valeurs nulles ['Genre','Marié',« personnes à charge »,'Travailleur indépendant','Montant du prêt',« Loan_Amount_Term »,'Histoire de credit']
## On peut aussi voir les valeurs nulles moyennes présentes dans ces colonnes {Montré dans l'image ci-dessous}
data_na = trainf_df[na_variables].est nul (). moyenne ()
## Mise en œuvre des techniques CCA pour supprimer les données manquantes data_cca = train_df(axe=0) ### axis=0 est utilisé pour spécifier les lignes
## Vérification de la forme finale de l'ensemble de données restant data_cca.shape
## Sortir (480 Lignes & 13 Colonnes) (480,13)
Chiffre"Chiffre" est un terme utilisé dans divers contextes, De l’art à l’anatomie. Dans le domaine artistique, fait référence à la représentation de formes humaines ou animales dans des sculptures et des peintures. En anatomie, désigne la forme et la structure du corps. En outre, en mathématiques, "chiffre" Il est lié aux formes géométriques. Sa polyvalence en fait un concept fondamental dans de multiples disciplines.... 3: – ACC
La source: Créé par l'auteur
Ici, nous pouvons voir, l'ensemble de données avait initialement 614 rangées et 13 Colonnes, desquelles 7 les lignes avaient des données manquantes(variables_variables), ses rangées du milieu manquantes sont indiquées par data_na. Nous avons observé que, à part et , ont tous une moyenne inférieure à 5%. Ensuite, selon le CCA, nous supprimons les lignes avec des données manquantes, qui a abouti à un ensemble de données avec seulement 480 Lignes. Ici vous pouvez voir autour de la 20% de la réduction des données, ce qui peut causer beaucoup de problèmes à l'avenir.
2. Imputation de valeur arbitraire
Il s'agit d'une technique importante utilisée dans l'imputation, car il peut gérer à la fois des variables numériques et catégorielles. Cette technique indique que nous regroupons les valeurs manquantes dans une colonne et les affectons à une nouvelle valeur qui est loin de la plage de cette colonne. En général, nous utilisons des valeurs comme 99999999 O -9999999 O « Manque » O « Non défini » pour les variables numériques et catégorielles.
- Hypothèses: –
- Les données ne manquent pas au hasard.
- Les données manquantes sont imputées avec une valeur arbitraire qui ne fait pas partie de l'ensemble de données ou de la moyenne / médianLa médiane est une mesure statistique qui représente la valeur centrale d’un ensemble de données ordonnées. Pour le calculer, Les données sont organisées de la plus basse à la plus élevée et le numéro au milieu est identifié. S’il y a un nombre pair d’observations, La moyenne des deux valeurs fondamentales est calculée. Cet indicateur est particulièrement utile dans les distributions asymétriques, puisqu’il n’est pas affecté par les valeurs extrêmes.... / mode de données.
- avantage: –
- Facile à mettre en œuvre.
- Nous pouvons l'utiliser en production.
- Préserve l'importance de « valeurs manquantes » s'il existe.
- Désavantages: –
- Vous pouvez fausser la distribution de la variable d'origine.
- Les valeurs arbitraires peuvent créer des valeurs aberrantes.
- Une prudence supplémentaire est requise lors de la sélection de la valeur arbitraire.
- Quand utiliser:-
- Lorsque les données ne sont pas MAR (Manquant au hasard).
- convient à tous.
- Code:-
## Trouver les colonnes qui ont des valeurs nulles(Données manquantes) ## Nous utilisons une boucle for pour toutes les colonnes présentes dans l'ensemble de données avec des valeurs nulles moyennes supérieures à 0
na_variables = [ var pour var dans train_df.columns si train_df[où].est nul().moyenne() > 0 ]
## Sortie des noms de colonnes avec des valeurs nulles ['Genre','Marié',« personnes à charge »,'Travailleur indépendant','Montant du prêt',« Loan_Amount_Term »,'Histoire de credit']
## Utilisez la colonne Sexe pour trouver les valeurs uniques dans la colonne train_df['Genre'].unique()
## Sortir déployer(['Homme','Femelle',dans])
## Ici, nan représente les données manquantes
## Utilisation de la technique d'imputation arbitraire, nous imputerons le genre manquant avec "Disparu" {Vous pouvez également utiliser n'importe quelle autre valeur}
arb_impute = train_df['Genre'].remplir('Disparu')
arb.impute.unique()
## Sortir déployer(['Homme','Femelle','Disparu'])
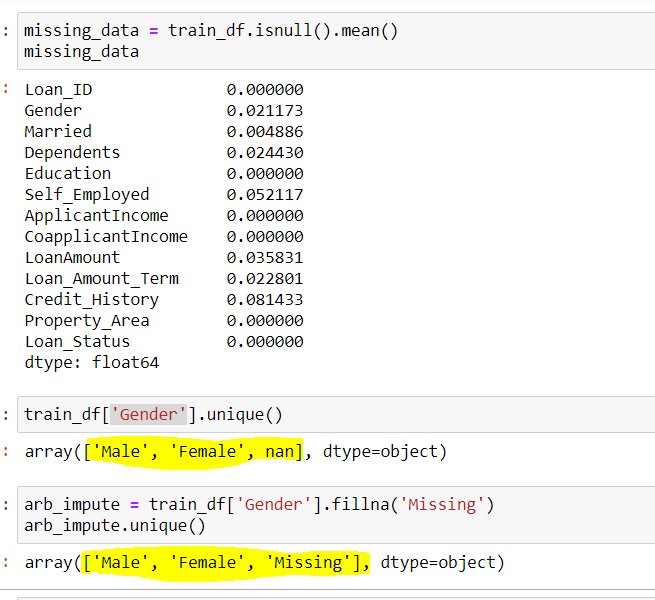
Figure 4: – Imputation arbitraire
La source: créé par l'auteur
On peut voir ici la colonne Genre J'avais 2 valeurs uniques {‘Macho femenino’} et quelques valeurs manquantes {dans}. Lors de l'utilisation de l'imputation arbitraire, nous remplissons les valeurs de {dans} dans cette colonne avec {disparu}, pour ce que vous obtenez 3 valores únicos para la variable ‘Genre’.
3. Imputation par catégorie fréquente
Cette technique dit de remplacer la valeur manquante par la variable avec la fréquence la plus élevée ou en mots simples en remplaçant les valeurs par le Mode de cette colonne. Cette technique est également connue sous le nom de Mode d'imputation.
- Hypothèses: –
- Des données aléatoires sont manquantes.
- Il y a une forte probabilité que les données manquantes ressemblent à la plupart des données.
- avantage: –
- La mise en œuvre est simple.
- Nous pouvons obtenir un ensemble de données complet en très peu de temps.
- Nous pouvons utiliser cette technique dans le modèle de production.
- Désavantages: –
- Plus le pourcentage de valeurs manquantes est élevé, plus la distorsion est grande.
- Peut conduire à une surreprésentation d'une catégorie particulière.
- Vous pouvez fausser la distribution de la variable d'origine.
- Quand utiliser:-
- Des données aléatoires sont manquantes (MAR)
- Les données manquantes ne sont pas plus de 5% à 6% de l'ensemble de données.
- Code:-
## trouver le nombre de valeurs uniques dans le genre train_df['Genre'].par groupe(train_df['Genre']).compter()
## Sortir (489 Homme & 112 Femelle) Homme 489 Femelle 112
## Le mâle a la fréquence la plus élevée. On peut aussi le faire en vérifiant le mode train_df['Genre'].mode()
## Sortir Homme
## Utilisation de l'imputeur de catégorie fréquente
frq_impute = train_df['Genre'].remplir('Homme')
frq_impute.unique()
## Sortir déployer(['Homme','Femelle'])
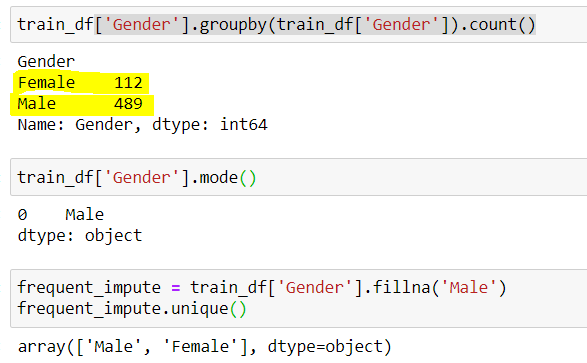
Figure 4: – Imputation par catégorie fréquente
La source: créé par l'auteur
On note ici que « Masculin » était la catégorie la plus fréquente, nous l'utilisons donc pour remplacer les données manquantes. Maintenant, nous sommes laissés seuls 2 catégories, c'est-à-dire, masculin et féminin.
Donc, on voit que chaque technique a ses avantages et ses inconvénients, et cela dépend de l'ensemble de données et de la situation pour laquelle les différentes techniques que nous allons utiliser.
C'est tout d'ici …
Jusque là, este es Shashank Singhal, un passionné de Big Data et de science des données.
Bon apprentissage ...
Si vous avez aimé mon article vous pouvez me suivre ICI
Profil LinkedIn:- www.linkedin.com/in/shashank-singhal-1806
Noter: – Toutes les images utilisées ci-dessus ont été créées par moi (Auteur).
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





