« Tout comme les athlètes ne peuvent pas gagner sans une combinaison sophistiquée de stratégie, façonner, attitude, tactique et vitesse, l'ingénierie des performances nécessite une bonne collection de métriques et d'outils pour fournir les résultats commerciaux souhaités ».– Todd DeCapua
introduction:
Au fil des ans, l'adoption de l'apprentissage automatique pour prendre des décisions commerciales a augmenté de façon exponentielle. Selon Forbes, Le ML devrait atteindre $ 30.6 milliards pour 2024 et il n'est pas surprenant de voir la myriade de solutions de ML personnalisées envahir le marché qui répondent à des besoins commerciaux spécifiques. La facilité de disponibilité des puissances de calcul, l'infrastructure cloud et l'automatisation l'ont encore plus accélérée.
La tendance actuelle à exploiter les pouvoirs du ML en entreprise a conduit les data scientists et les ingénieurs à concevoir des solutions / des services innovants et l'un de ces services a été Model As A Service (MaaS). Nous avons utilisé bon nombre de ces services sans savoir comment ils ont été créés ou diffusés sur le Web., quelques exemples incluent la visualisation des données, la reconnaissance faciale, traitement du langage naturel, analyse prédictive et plus. En résumé, MaaS encapsule toutes les données complexes, formation et évaluation de modèles, la mise en oeuvre, etc., et permet aux clients de les consommer pour leur usage.
Aussi simple que cela puisse paraître d'utiliser ces services, il y a de nombreux défis dans la création d'un tel service, par exemple: Comment maintenons-nous le service? Comment s'assurer que la précision de notre modèle ne diminue pas avec le temps? etc. Comme pour tout service ou application, un facteur important à considérer est la charge ou le trafic qu'un service / L'API peut gérer pour assurer votre disponibilité. La meilleure caractéristique de l'API est d'avoir d'excellentes performances et la seule façon de le tester est d'appuyer sur l'API pour voir comment elle répond. C'est le test de charge.
Dans ce blog, nous ne verrons pas seulement comment ce service est construit, mais aussi comment tester la charge de service pour planifier les exigences matérielles / infrastructure dans l'environnement de production. Nous allons essayer d'y parvenir dans l'ordre suivant:
- Créer une API simple avec FastAPI
- Construire un modèle de classification en Python
- Enveloppez le modèle avec FastAPI
- Tester l'API avec le client Postman
- Test de charge avec Locust
Commençons !!
Création d'une API Web simple à l'aide de FastAPI:
Le code suivant montre l'implémentation de base de FastAPI. Le code est utilisé pour créer une API Web simple qui, à la réception d'un billet particulier, produit une sortie spécifique. Voici la division du code:
- Charger les bibliothèques
- Créer un objet d'application
- Créez un itinéraire avec @ app.get ()
- Écrire une fonction de contrôleur qui a un hôte et un numéro de port définis
de fastapi importer FastAPI, Demander
en tapant import Dict
de pydantic importer BaseModel
importer de l'uvicorne
importer numpy en tant que np
importer des cornichons
importer des pandas au format pd
importer json
application = FastAPI()
@app.get("/")
racine def asynchrone():
revenir {"un message": "Construit avec FastAPI"}
if __name__ == '__main__':
uvicorn.run(application, hôte="127.0.0.1", port=8000)
Une fois exécuté, vous pouvez naviguer vers le navigateur avec l'url: http: // hôte local: 8000 et observez le résultat qui dans ce cas sera ‘ Construit avec FastAPI ‘
Créer une API à partir d'un modèle de ML à l'aide de FastAPI:
Maintenant que vous avez une idée précise de FastAPI, Voyons comment vous pouvez encapsuler un modèle d'apprentissage automatique (développé en Python) dans une API en Python. je vais utiliser le jeu de données (diagnostic) Cancer du sein du Wisconsin. L'objectif de ce projet ML est de prédire si une personne a une tumeur bénigne ou maligne. j'utiliserai Code VS en tant que mon éditeur et notez que nous allons tester notre service avec facteur Client. Ce sont les étapes que nous suivrons.
- Nous allons d'abord construire notre modèle de classification: KNeighboursClassifier ()
- Construisez notre fichier serveur qui aura une logique pour l'API dans le FlastAPI structure.
- Finalement, nous allons tester notre service avec facteur
Paso 1: Modèle de classement
Un modèle de classification simple avec le processus standard de chargement des données, diviser les données en train / test, suivi de la construction du modèle et de l'enregistrement du modèle au format cornichon dans l'unité. Je n'entrerai pas dans les détails de la construction du modèle, puisque l'article concerne les tests de charge.
importer des pandas au format pd
importer numpy en tant que np
de sklearn.model_selection importer train_test_split
de sklearn.neighbors importer KNeighborsClassifier
importer joblib, cornichon
importer le système d'exploitation
importer yaml
# dossier pour charger le fichier de configuration
CHEMIN_CONFIG = "../Configurations"
# Fonction pour charger le fichier de configuration yaml
def load_config(nom_config):
"""[La fonction prend le fichier de configuration yaml en entrée et charge la configuration]
Arg:
nom_config ([yaml]): [La fonction prend la configuration yaml en entrée]
Retour:
[chaîne de caractères]: [Retourne la configuration]
"""
avec ouvert(os.path.join(CHEMIN_CONFIG, nom_config)) comme fichier:
config = yaml.safe_load(déposer)
retour config
config = load_config("config.yaml")
#chemin d'accès à l'ensemble de données
nom de fichier = "../../Données/cancer-du-sein-wisconsin.csv"
#charger les données
données = pd.read_csv(nom de fichier)
#remplacer "?" avec -99999
données = données.remplacer('?', -99999)
# déposer la colonne d'identifiant
données = données.drop(configuration["drop_columns"], axe=1)
# Définir X (variables indépendantes) Andy (variable cible)
X = np.tableau(data.drop(configuration["nom_cible"], 1))
y = np.tableau(Les données[configuration["nom_cible"]])
X_train, X_test, y_train, y_test = train_test_split(
X, Oui, taille_test=config["taille_test"], état_aléatoire = configuration["état_aléatoire"]
)
# appelez notre classificateur et adaptez-vous à nos données
classificateur = KNeighborsClassifier(
n_neighbors=config["n_voisins"],
poids=config["poids"],
algorithme=config["algorithme"],
leaf_size=config["taille_feuille"],
p=config["p"],
métrique=config["métrique"],
n_jobs=config["n_emplois"],
)
# former le classificateur
classificateur.fit(X_train, y_train)
# tester notre classificateur
résultat = classificateur.score(X_test, y_test)
imprimer("Le score de précision est. {:.1F}".format(résultat))
# Enregistrer le modèle sur le disque
cornichon.dump(classificateur, ouvert('../../FastAPI//Models/KNN_model.pkl','wb'))
Vous pouvez accéder au code complet à partir de Github
Paso 2: compiler l'API avec FastAPI:
Nous allons construire sur l'exemple de base que nous avons fait dans une section précédente.
Charger les bibliothèques:
de fastapi importer FastAPI, Demander en tapant import Dict de pydantic importer BaseModel importer de l'uvicorne importer numpy en tant que np importer des cornichons importer des pandas au format pd importer json
Cargue el modelo KNN guardado y escriba una función de enrutamiento para devolver el JsonJSON, o Notation d’objet JavaScript, Il s’agit d’un format d’échange de données léger, facile à lire et à écrire pour les humains, et facile à analyser et à générer pour les machines. Il est couramment utilisé dans les applications Web pour envoyer et recevoir des informations entre un serveur et un client. Sa structure est basée sur des paires clé-valeur, ce qui le rend polyvalent et largement adopté dans le développement de logiciels..:
application = FastAPI()
@app.get("/")
racine def asynchrone():
revenir {"un message": "Bonjour le monde"}
# Charger le modèle
# modèle = pickle.load(ouvert('../Models/KNN_model.pkl','rb'))
modèle = pickle.load(ouvert('../Models/KNN_model.pkl','rb'))
@app.post('/prédire')
def pred(corps: dict):
"""[sommaire]
Arg:
corps (dict): [La méthode pred prend en entrée Response qui est au format Json et renvoie la valeur prédite à partir du modèle enregistré.]
Retour:
[Json]: [La fonction pred renvoie la valeur prédite]
"""
# Obtenir les données de la requête POST.
données = corps
varListe = []
pour val dans data.values():
varList.append(val)
# Faire une prédiction à partir du modèle enregistré
prédiction = model.predict([varListe])
# Extraire la valeur
sortie = prédiction[0]
#renvoyer la sortie au format json
revenir {« La prédiction est »: sortir}
# 5. Exécuter l'API avec uvicor
# Fonctionnera sur http://127.0.0.1:8000
if __name__ == '__main__':
"""[L'API s'exécutera sur l'hôte local sur le port 8000]
"""
uvicorn.run(application, hôte="127.0.0.1", port=8000)
Vous pouvez accéder au code complet à partir de Github.
Utilisation du client Postman:
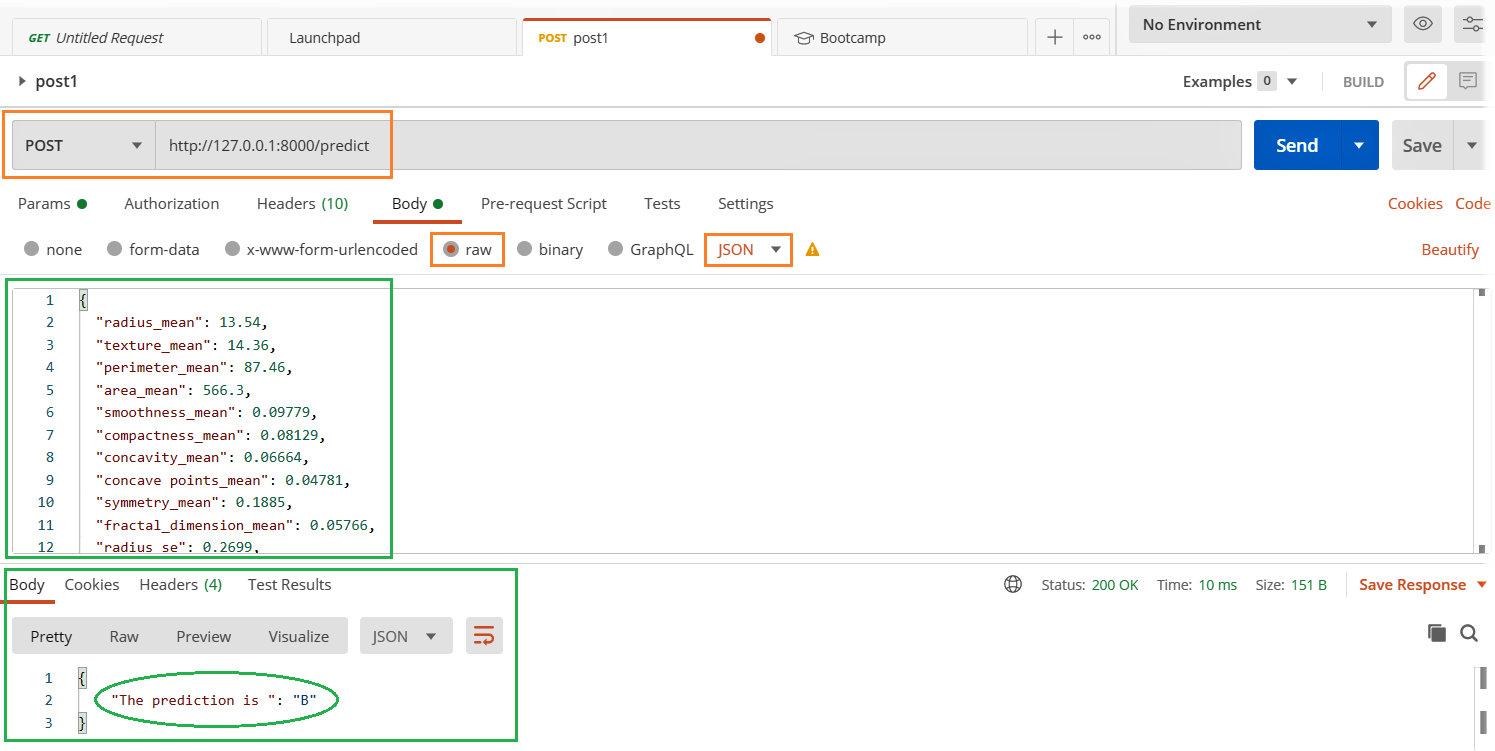
Dans notre rubrique précédente, nous créons une API simple dans laquelle appuyer sur le http: // hôte local: 8000 dans le navigateur, nous avons un message de sortie « Construit avec FastAPI ». C'est bien tant que la sortie est plus simple et qu'une entrée utilisateur ou système est attendue. Mais nous construisons un modèle en tant que service dans lequel nous envoyons des données en entrée pour le modèle à prédire.. Dans ce cas, nous aurons besoin d'un moyen meilleur et plus facile de le tester. nous utiliserons facteur pour tester notre API.
- Exécutez le fichier server.py
- Ouvrez le client Postman et remplissez les détails pertinents mis en évidence ci-dessous et appuyez sur le bouton Soumettre.
- Voir le résultat dans la section réponse ci-dessous.
Vos applications et services sont-ils stables sous une charge maximale?
Test de temps de chargement:
Nous allons explorer la bibliothèque Locust pour les tests de charge et le moyen le plus simple d'installer Langosta il est
pip installer le criquet
Créons un perf.py fichier avec le code suivant. j'ai fait référence au code Démarrage rapide page de homard
heure d'importation
importer json
de l'importation de criquets HttpUser, tâche, entre
classe QuickstartUser(Utilisateur HTTP):
wait_time = entre(1, 3)
@tâche(1)
def testFlacon(soi):
charge = {
"rayon_moyen": 13.54,
"texture_moyenne": 14.36,
......
......
"fractale_dimension_pire": 0.07259}
mes en-têtes = {'Type de contenu': 'application/json', 'J'accepte': 'application/json'}
auto.client.post("/prédire", data=json.dumps(charge), en-têtes = mes en-têtes)
Accédez au fichier de code complet à partir de Github
Commencer le homard: Naviguez jusqu'au répertoire perf.py et exécutez le code suivant.
criquet -f perf.py
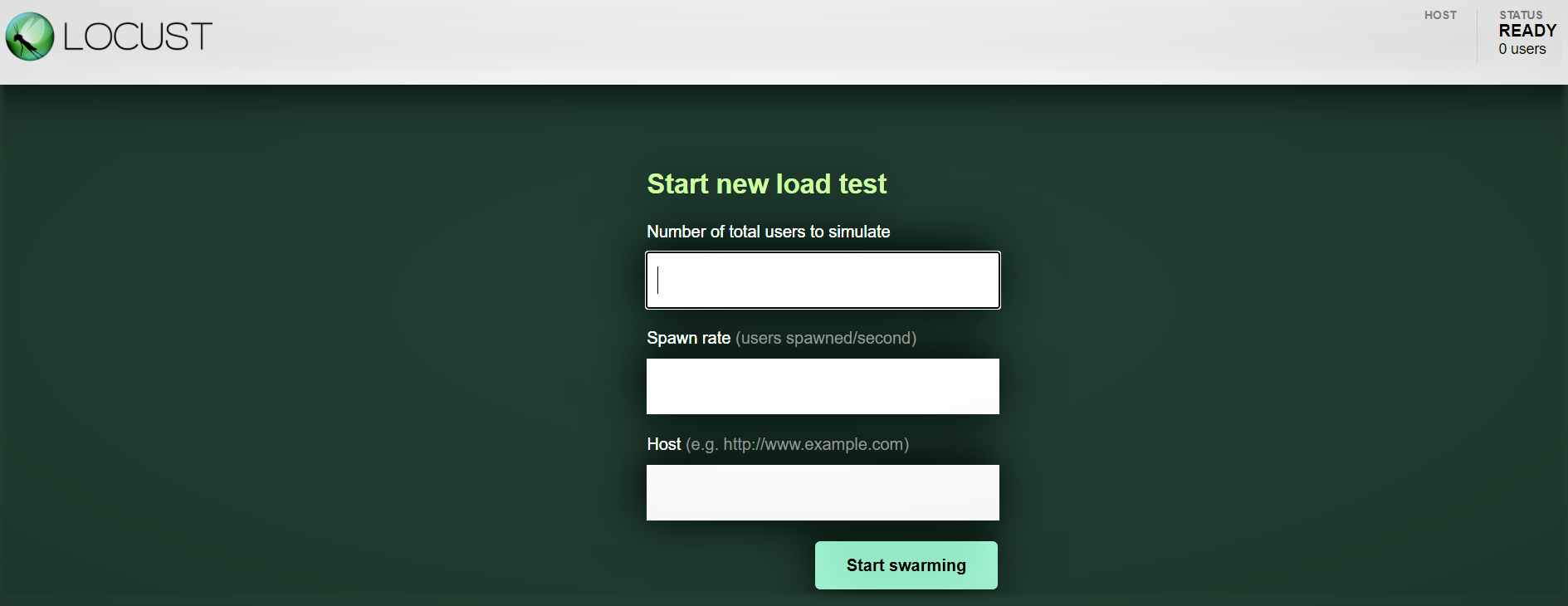
Interfaz web Locust:
Une fois que vous avez démarré Locust avec la commande ci-dessus, accédez à un navigateur et pointez-le sur http: // hôte local: 8089. Vous devriez voir la page suivante:
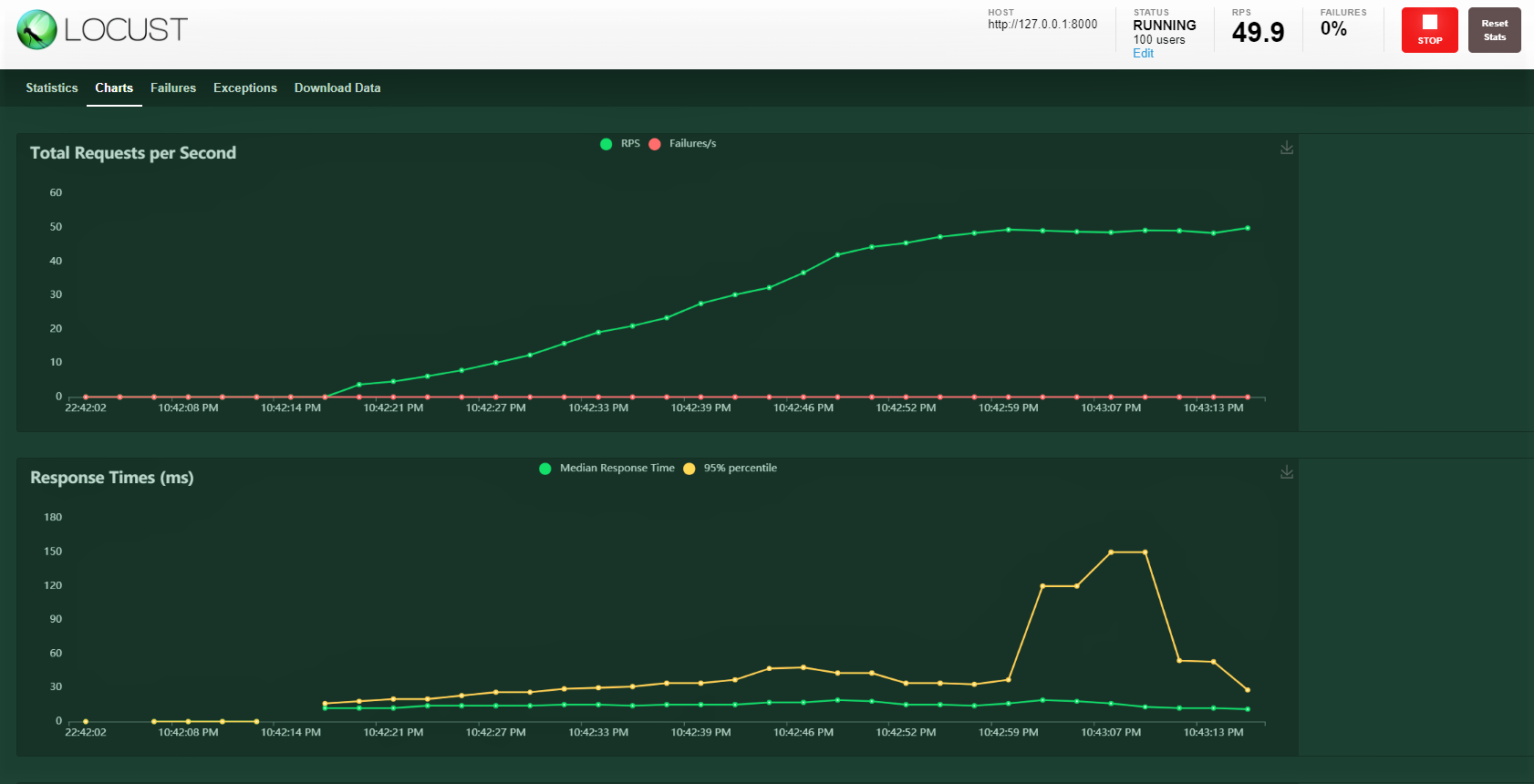
Essayons avec 100 utilisateurs, taux de génération 3 votre hôte: http: 127.0.0.1: 8000 où s'exécute notre API. Vous pouvez voir l'écran suivant. Vous pouvez voir la charge augmenter avec le temps et le temps de réponse, une représentation graphique montre le temps moyen et d'autres métriques.
Noter: assurez-vous que server.py est en cours d'exécution.

conclusion:
Nous couvrons beaucoup sur ce blog, de la construction d'un modèle, fermeture avec une FastAPI, la preuve de service avec le facteur et enfin la réalisation d'un essai de charge avec 100 utilisateurs simulés accédant à notre service avec une charge progressivement croissante. Nous avons pu surveiller la réponse du service.
La plupart du temps, il existe des SLA au niveau de l'entreprise qui doivent être respectés, c'est-à-dire, garder un certain seuil pour un temps de réponse comme 30ms ou 20ms. Si les SLA ne sont pas respectés, il existe des implications financières potentielles en fonction du contrat ou de la perte de clients, car ils n'ont pas reçu le service assez rapidement.
Un test de charge nous aide à comprendre les points de défaillance maximaux et potentiels. Alors, nous pouvons planifier une action proactive en augmentant notre capacité matérielle et, si le service est déployé dans le type de configuration Kubernetes, le configurer pour augmenter le nombre de pods avec une charge croissante.
Bon apprentissage !!!!
Vous pouvez vous connecter avec moi – Linkedin
Vous pouvez trouver le code pour référence: Github
Les références
https://docs.locust.io/en/stable/quickstart.html
https://fastapi.tiangolo.com/
https://unsplash.com/
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





