introduction
"Si vous parlez à un homme dans une langue qu'il comprend, ça lui monte à la tête. Si tu lui parles dans sa propre langue, atteindra ton coeur “. – Nelson Mandela
La beauté de la langue transcende les frontières et les cultures. Apprendre une langue autre que notre langue maternelle est un grand avantage. Mais la route du bilinguisme, ou le multilinguisme, cela peut souvent être long et interminable.
Il y a tellement de petites nuances qu'on se perd dans la mer des mots. Cependant, les choses sont devenues beaucoup plus faciles avec les services de traduction en ligne (je regarde Google Translate!).
J'ai toujours voulu apprendre une autre langue que l'anglais. j'ai essayé d'apprendre l'allemand (o Allemand) dans 2014. C'était amusant et stimulant. J'ai finalement dû abandonner, mais j'ai nourri l'envie de recommencer.

Avance rapide vers 2019, J'ai la chance de pouvoir construire un traducteur de langue pour n'importe quelle paire de langues possible. Quel grand avantage le traitement du langage naturel a été !!
Dans cet article, Nous discuterons des étapes pour créer un modèle de traduction de l'allemand vers l'anglais à l'aide de Keras.. Nous jetterons également un rapide coup d'œil à l'histoire des systèmes de traduction automatique avec le recul..
Cet article suppose une familiarité avec RNN, LSTM et Keras. Vous trouverez ci-dessous quelques articles pour en savoir plus à leur sujet:
Table des matières
- Traduction automatique: une histoire brève
- Comprendre l'énoncé du problème
- Introduction à la prédiction séquence par séquence
- Implémentation en Python avec Keras
Traduction automatique: une histoire brève
La plupart d'entre nous ont été initiés à la traduction automatique lorsque Google a introduit le service. Mais le concept existe depuis le milieu du siècle dernier.
Travaux de recherche en traduction automatique (TA) commencé déjà dans la décennie de 1950, principalement aux États-Unis. Ces premiers systèmes étaient basés sur d'énormes dictionnaires bilingues, règles codées à la main et principes universels sous-jacents au langage naturel.
Dans 1954, IBM a fait une première démonstration publique d'une traduction automatique. Le système avait un vocabulaire assez restreint de seulement 250 mots et ne pouvait traduire que 49 phrases russes sélectionnées en anglais. Le nombre semble minuscule maintenant, mais le système est largement considéré comme une étape importante dans le progrès de la traduction automatique.

Cette image a été prise de travail de recherche description du système IBM
Deux écoles de pensée ont rapidement émergé:
- Approches empiriques par essais et erreurs, en utilisant des méthodes statistiques, Oui
- Approches théoriques impliquant la recherche linguistique fondamentale
Dans 1964, le gouvernement des États-Unis a créé le Comité consultatif sur le traitement automatique des langues (ALPAC) évaluer les progrès de la traduction automatique. ALPAC a un peu insisté et a publié un rapport en novembre 1966 sur le statut MT. Voici les points saillants de ce rapport:
- Il a soulevé de sérieux doutes sur la faisabilité de la traduction automatique, la qualifiant de désespérée.
- Le financement de la recherche sur la MT a été découragé
- C'était un rapport assez déprimant pour les chercheurs travaillant dans ce domaine..
- La plupart d'entre eux ont quitté le domaine et ont commencé de nouvelles carrières.
Pas exactement une recommandation enthousiaste!!
Une longue période de sécheresse a suivi ce malheureux rapport. Finalement, dans 1981, un nouveau système appelé Système MÉTÉO déployé au Canada pour la traduction des prévisions météorologiques publiées en français vers l'anglais. C'était un projet assez réussi qui est resté en opération jusqu'à ce que 2001.
Le premier outil de traduction Web au monde, Babel poisson, a été lancé par le moteur de recherche AltaVista à 1997.
Et puis vint la percée que nous connaissons tous maintenant: Google Traduction. Depuis, a changé notre façon de travailler (et nous avons même appris) avec différentes langues.
La source: translate.google.com
Comprendre l'énoncé du problème
Revenons à l'endroit où nous nous sommes arrêtés dans la section d'introduction, c'est-à-dire, apprendre l'allemand. Cependant, cette fois je vais faire faire à ma machine cette tâche. L'objectif est de convertir une phrase allemande en son équivalent anglais à l'aide d'un système neuronal de traduction automatique. (NMT).

Nous utiliserons les données de paires de phrases allemand-anglais de http://www.manythings.org/anki/. Vous pouvez le télécharger depuis ici.
Introduction à la modélisation séquence par séquence (Seq2Seq)
Modèles séquence à séquence (seq2seq) sont utilisés pour une variété de tâches de PNL, sous forme de résumé de texte, reconnaissance vocale, modélisation de séquences d'ADN, entre autres. Notre objectif est de traduire des phrases données d'une langue à une autre.
Ici, l'entrée et la sortie sont des phrases. En d'autres termes, ces phrases sont une séquence de mots qui entrent et sortent d'un modèle. C'est l'idée de base de la modélisation séquence par séquence.. La figure suivante tente d'expliquer cette méthode.
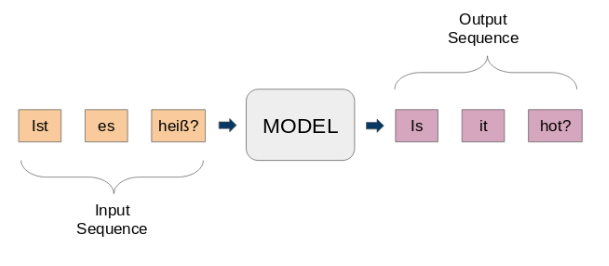
Un modèle seq2seq typique a 2 composants principaux:
une) un encodeur
b) un décodeur
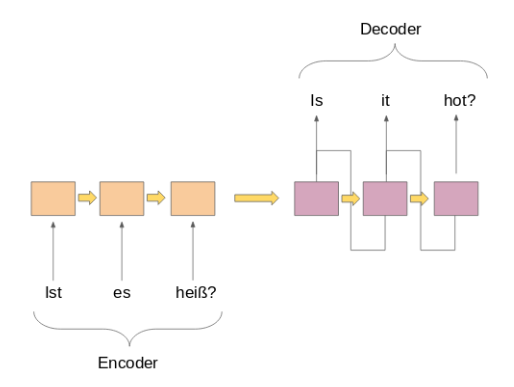
Les deux parties sont essentiellement deux modèles différents de réseaux de neurones récurrents (RNN) réunis en un réseau géant:
J'ai répertorié ci-dessous quelques cas d'utilisation importants de la modélisation séquence par séquence (en dehors de la traduction automatique, bien sûr):
- Reconnaissance vocale
- Extraction d'entité / nom du sujet pour identifier le sujet principal d'un corps de texte
- Classification des relations pour étiqueter les relations entre plusieurs entités étiquetées à l'étape précédente
- Compétences en chatbot pour avoir des compétences conversationnelles et interagir avec les clients
- Résumé de texte pour générer un résumé concis d'une grande quantité de texte
- Systèmes de réponse aux questions
Implémentation en Python avec Keras
Il est temps de se salir les mains! Il n'y a pas de meilleur sentiment que d'apprendre un sujet en voyant les résultats de première main.. Nous allons démarrer notre environnement Python préféré (Carnet Jupyter pour moi) et nous nous mettrons au travail.
Importez les bibliothèques requises
chaîne d'importation
importation re
à partir du tableau d'importation numpy, argmax, Aléatoire, prendre
importer des pandas au format pd
à partir de keras.models Importation séquentielle
de keras.layers importer Dense, LSTM, Intégration, RépéterVecteur
de keras.preprocessing.text import Tokenizer
à partir de keras.callbacks importer ModelCheckpoint
de keras.preprocessing.sequence importer pad_sequences
à partir de keras.models importer load_model
des optimiseurs d'importation keras
importer matplotlib.pyplot en tant que plt
%matplotlib en ligne
pd.set_option('display.max_colwidth', 200)
Lire les données dans notre IDE
Nos données sont un fichier texte (.SMS) paires de phrases anglais-allemand. Premier, nous allons lire le fichier en utilisant la fonction définie ci-dessous.
# fonction pour lire le fichier texte brut
def read_text(nom de fichier):
# ouvrir le fichier
fichier = ouvrir(nom de fichier, mode="rt", encodage='utf-8')
# lire tout le texte
texte = fichier.lire()
fichier.fermer()
texte de retour
Définissons une autre fonction pour diviser le texte en paires anglais-allemand séparées par ‘ n'. Alors, nous allons diviser ces paires en phrases anglaises et phrases allemandes, respectivement.
# diviser un texte en phrases
def vers_lignes(texte):
envois = text.strip().diviser('n')
envois = [Je partage('t') pour moi dans les envois]
renvoyer les envois
Nous pouvons maintenant utiliser ces fonctions pour lire le texte dans un tableau dans le format souhaité.
données = read_text("deu.txt")
deu_eng = to_lines(Les données)
deu_eng = tableau(deu_eng)
Les données réelles contiennent plus de 150.000 paires de phrases. Cependant, nous n'utiliserons que le premier 50,000 paires de phrases pour réduire le temps de formation du modèle. Vous pouvez modifier ce nombre en fonction de la puissance de calcul de votre système (Ou si tu te sens chanceux!).
deu_eng = deu_eng[:50000,:]
Prétraitement de texte
Une étape très importante dans tout projet, surtout en PNL. Les données avec lesquelles nous travaillons sont souvent non structurées, il y a donc certaines choses dont nous devons nous occuper avant de passer à la partie construction du modèle.
(une) Nettoyage de texte
Jetons d'abord un coup d'œil à nos données. Cela nous aidera à décider des étapes de prétraitement à suivre.
deu_eng
déployer([['Salut.', 'Bonjour!'],
['Salut.', 'Bonne journée!'],
['Courir!', 'Courir!'],
...,
['Marie a les cheveux très longs.', 'Maria a les cheveux très longs.'],
["Mary est la secrétaire de Tom.", « Maria est la secrétaire de Tom ».],
[« Marie est une femme mariée. », « Maria est une femme mariée. »]],
type="<U380")
Nous allons nous débarrasser des signes de ponctuation, puis convertir tout le texte en minuscules.
# Supprimer la ponctuation
deu_eng[:,0] = [s.traduire(p.maketrans('', '', chaîne.ponctuation)) pour s dans deu_eng[:,0]]
deu_eng[:,1] = [s.traduire(p.maketrans('', '', chaîne.ponctuation)) pour s dans deu_eng[:,1]]
deu_eng
déployer([['Salut', 'Bonjour'],
['Salut', 'Bonne journée'],
['Courir', 'Courir'],
...,
["Marie a les cheveux très longs", « Maria a les cheveux très longs »],
[« Mary est la secrétaire de Tom », « Maria est la secrétaire de Tom »],
["Marie est une femme mariée", « Maria est une femme mariée »]],
type="<U380")
# convertir le texte en minuscules
pour moi à portée(longueur(deu_eng)):
deu_eng[je,0] = deu_fra[je,0].inférieur()
deu_eng[je,1] = deu_fra[je,1].inférieur()
deu_eng
déployer([['salut', 'Bonjour'],
['salut', 'Bonne journée'],
['Cours', 'Cours'],
...,
['Marie a les cheveux très longs', « Maria a les cheveux très longs »],
['Mary est la secrétaire de Tom', « Maria est la secrétaire de Tom »],
['Marie est une femme mariée', « Maria est une femme mariée »]],
type="<U380")
(b) Conversion de texte en séquence
Un modèle Seq2Seq nécessite que nous convertissions à la fois les phrases d'entrée et de sortie en séquences entières de longueur fixe.
Mais avant de faire ça, visualisons la longueur des phrases. Nous allons capturer la longueur de toutes les phrases dans deux listes distinctes pour l'anglais et l'allemand, respectivement.
# listes vides
eng_l = []
deu_l = []
# remplir les listes avec des longueurs de phrases
pour moi dans deu_eng[:,0]:
eng_l.append(longueur(Je partage()))
pour moi dans deu_eng[:,1]:
deu_l.append(longueur(Je partage()))
length_df = pd.DataFrame({'fra':eng_l, 'ça a donné':deu_l})
longueur_df.hist(bacs = 30)
plt.show()
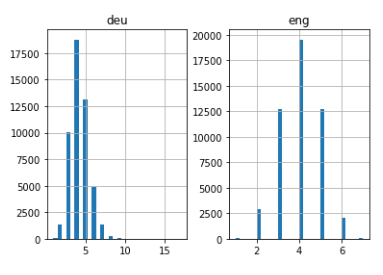
Assez intuitif: la longueur maximale des phrases en allemand est 11 et celle des phrases en anglais est 8.
Ensuite, vectoriser nos données texte en utilisant Keras Tokenizador () classe. Il convertira nos phrases en séquences de nombres entiers. Ensuite, nous pouvons remplir ces séquences avec des zéros pour que toutes les séquences aient la même longueur.
Veuillez noter que nous préparerons des tokenizers pour les phrases en allemand et en anglais:
# fonction pour construire un tokenizer
def tokenisation(lignes):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lignes)
retour tokenizer
# préparer un tokenizer anglais
eng_tokenizer = tokenisation(deu_eng[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
longueur_eng = 8
imprimer('Taille du vocabulaire anglais: %ré' % eng_vocab_size)
Taille du vocabulaire anglais: 6453
# préparer le tokenizer allemand
deu_tokenizer = tokenisation(deu_eng[:, 1])
deu_vocab_size = len(deu_tokenizer.word_index) + 1
deu_length = 8
imprimer('Taille du vocabulaire allemand: %ré' % deu_vocab_size)
Taille du vocabulaire allemand: 10998
Le bloc de code suivant contient une fonction pour préparer les séquences. Il effectuera également un remplissage de séquence jusqu'à une longueur de phrase maximale comme mentionné ci-dessus.
# encoder et pad séquences
def encode_sequences(tokenizer, longueur, lignes):
# integer encode sequences
seq = tokenizer.texts_to_sequences(lignes)
# séquences de pads avec 0 values
seq = pad_sequences(seq, maxlen=longueur, padding='post')
retour seq
Construction du modèle
Maintenant, nous allons diviser les données en train et ensemble de test pour la formation et l'évaluation du modèle, respectivement.
de sklearn.model_selection importer train_test_split # diviser les données en train et ensemble de test former, test = train_test_split(deu_eng, taille_test=0.2, état_aléatoire = 12)
Le temps de coder les phrases. nous allons coder Phrases en allemand comme séquences d'entrée Oui Phrases en anglais comme séquences cibles. Cela devrait être fait pour le train et les ensembles de données de test.
# préparer les données d'entraînement trainX = encode_sequences(deu_tokenizer, deu_length, former[:, 1]) trainY = encode_sequences(eng_tokenizer, longueur_eng, former[:, 0]) # préparer les données de validation testX = encode_sequences(deu_tokenizer, deu_length, test[:, 1]) testY = encode_sequences(eng_tokenizer, longueur_eng, test[:, 0])
Vient maintenant la partie passionnante!
Nous allons commencer par définir notre architecture de modèle Seq2Seq:
- Pour l'encodeur, nous utiliserons une couche de keying et une couche LSTM
- Pour décodeur, nous utiliserons une autre couche LSTM suivie d'une couche dense

Architecture du modèle
# construire le modèle NMT
def define_model(dans_vocab,out_vocab, in_timesteps,out_timesteps,unités):
modèle = Séquentiel()
model.ajouter(Intégration(dans_vocab, unités, input_length=in_timesteps, mask_zero=Vrai))
model.ajouter(LSTM(unités))
model.ajouter(RépéterVecteur(out_timesteps))
model.ajouter(LSTM(unités, return_sequences=Vrai))
model.ajouter(Dense(out_vocab, activation='softmax'))
modèle de retour
Nous utilisons l'optimiseur RMSprop sur ce modèle, car c'est généralement une bonne option lorsque vous travaillez avec des réseaux de neurones récurrents.
# compilation de modèles modèle = define_model(deu_vocab_size, eng_vocab_size, deu_length, longueur_eng, 512)
rms = optimiseurs.RMSprop(lr=0.001) modèle.compile(optimiseur=rms, perte ="sparse_categorical_crossentropy")
Veuillez noter que nous avons utilisé ‘sparse_categorical_crossentropy'Comme la fonction de perte. En effet, la fonction nous permet d'utiliser la séquence cible telle quelle, au lieu du format encodé à chaud. Le codage à chaud des séquences cibles à l'aide d'un vocabulaire aussi étendu pourrait consommer toute la mémoire de notre système.
Nous sommes prêts à commencer à entraîner notre modèle!
Nous vous formerons pendant 30 fois et avec une taille de lot de 512 avec une division de validation du 20%. Le 80% des données seront utilisées pour entraîner le modèle et le reste pour l'évaluer. Vous pouvez modifier et jouer avec ces hyperparamètres.
Nous utiliserons également le ModèleCheckpoint () fonction pour enregistrer le modèle avec le moins de perte de validation. Je préfère personnellement cette méthode à l'arrêt anticipé.
nom de fichier="modèle.h1.24_jan_19"
point de contrôle = modèle point de contrôle(nom de fichier, moniteur ="perte_val", verbeux=1, save_best_only=Vrai, mode="min")
# maquette de train
histoire = model.fit(trainX, trainY.remodeler(former.en.forme[0], former.en.forme[1], 1),
époques=30, taille_bat=512, validation_split = 0.2, rappels =[point de contrôle],
verbeux=1)
Comparons la perte de formation et la perte de validation.
plt.plot(histoire.histoire['perte']) plt.plot(histoire.histoire['val_loss']) plt.légende(['former','validation']) plt.show()
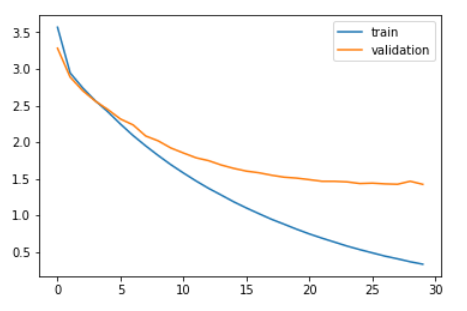
Comme vous pouvez le voir dans le graphique ci-dessus, la perte de validation a cessé de diminuer après 20 époques.
Finalement, nous pouvons charger le modèle enregistré et faire des prédictions sur les données invisibles: testX.
modèle = load_model('model.h1.24_jan_19')
preds = model.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
Ces prédictions sont des suites d'entiers. Nous devons convertir ces entiers en leurs mots correspondants. Définissons une fonction pour faire cela:
def get_word(m, tokenizer):
pour mot, index dans tokenizer.word_index.items():
si indice == n:
mot de retour
retour Aucun
Convertir les prédictions en texte (Anglais):
preds_text = []
pour moi dans les preds:
température = []
pour j dans la plage(longueur(je)):
t = get_word(je[j], eng_tokenizer)
si j > 0:
si (t == get_word(je[j-1], eng_tokenizer)) ou (t == Aucun):
temp.append('')
autre:
temp.append sinon:
si(t == Aucun):
temp.append('')
autre:
temp.append
preds_text.append(' '.rejoindre(température))
Mettons les phrases originales en anglais dans l'ensemble de données de test et les phrases prédites dans un bloc de données:
pred_df = pd.DataFrame({'réel' : test[:,0], 'prévu' : preds_text})
Nous pouvons imprimer au hasard des instances réelles par rapport à celles attendues pour voir comment fonctionne notre modèle:
# imprimer 15 rangées au hasard pred_df.sample(15)
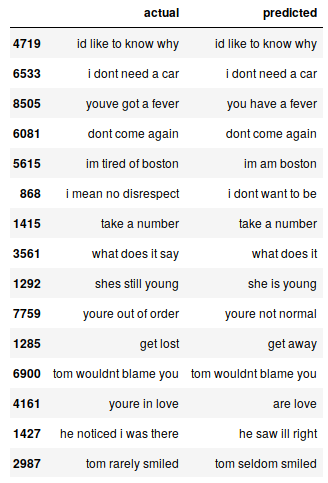
Notre modèle Seq2Seq fait un travail décent. Mais il existe plusieurs cas où vous perdez votre compréhension des mots-clés. Par exemple, ça se traduit “je suis fatigué de Boston” pour “je viens de boston”.
Ce sont les défis que vous rencontrerez régulièrement en PNL. Mais ce ne sont pas des obstacles inamovibles. Nous pouvons atténuer ces défis en utilisant plus de données d'entraînement et en créant un meilleur modèle. (ou plus complexe).
Vous pouvez accéder au code complet depuis ce Github dépôt.
Remarques finales
Même avec un modèle Seq2Seq très simple, Les résultats sont assez encourageants. Nous pouvons facilement améliorer ces performances en utilisant un modèle de codec plus sophistiqué sur un ensemble de données plus important..
Une autre expérience à laquelle je peux penser consiste à tester l'approche seq2seq sur un ensemble de données contenant des phrases plus longues. Plus j'expérimente, en savoir plus sur cet espace vaste et complexe.
Si vous avez des commentaires sur cet article ou avez des questions / question, s'il vous plaît partagez-le dans la section commentaire ci-dessous.





