Dans le dernier message (Cliquez ici), nous parlons brièvement des bases de la technique ANN. Mais avant d'utiliser la technique, un analyste doit savoir, Comment fonctionne réellement la technique? Même lorsqu'une référence détaillée n'est pas requise, le cadre de l'algorithme doit être connu. Cette connaissance sert à plusieurs fins:
- En premier lieu, nous aide à comprendre l'impact de l'augmentation / réduire l'ensemble de données verticalement ou horizontalement en temps de calcul.
- En second lieu, nous aide à comprendre les situations ou les cas dans lesquels le modèle convient le mieux.
- En troisième lieu, Cela nous aide également à expliquer pourquoi un certain modèle fonctionne mieux dans certains contextes ou situations..
Cet article vous fournira une compréhension de base du cadre du réseau de neurones artificiels (ANN). Nous n'irons pas dans le contournement réel, mais les informations fournies dans cet article vous suffiront pour apprécier et mettre en pratique l'algorithme. A la fin du poste, en outre, je présenterai mon point de vue sur les trois objectifs fondamentaux de la compréhension de tout algorithme mentionné précédemment.
Formulation de réseau de neurones
Nous commencerons par comprendre la formulation d'un simple réseau de neurones à couche cachée. Un simple réseau de neurones peut être représenté comme le montre la figure suivante:
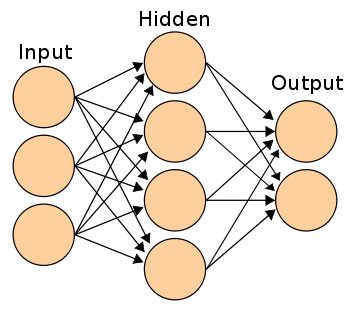
Les liens entre les nœuds sont la découverte la plus cruciale dans un ANN. Nous reviendrons sur « comment trouver le poids de chaque lien » après avoir évoqué le cadre général. Les seules valeurs connues dans le schéma ci-dessus sont les entrées. Appelons les entrées I1, I2 et I3, états cachés comme H1, H2.H3 et H4, sorties comme O1 et O2. Les poids des liens peuvent être notés avec la notation suivante:
W (I1H1) est le poids du lien entre les nœuds I1 et H1.
Voici le cadre dans lequel fonctionnent les réseaux de neurones artificiels (ANN):

Peu de détails statistiques sur le cadre
Chaque calcul de liaison dans un réseau de neurones artificiels (ANN) est équivalent. En général, on suppose un lien sigmoïde entre les variables d'entrée et le taux d'activation des nœuds cachés ou entre les nœuds cachés et le taux d'activation des nœuds de sortie. Préparons l'équation pour trouver le taux d'activation de H1.
Logit (H1) = W (I1H1) * I1 + W (I2H1) * I2 + W (I3H1) * I3 + Constante = f
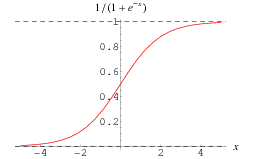
=> P (H1) = 1 / (1 + e ^ (- F))
Voici à quoi ressemble la liaison sigmoïde:
Comment les poids sont-ils recalibrés? Un petit mot
Le recalibrage des poids est une procédure simple, mais longue. Les seuls nœuds où nous connaissons le taux d'erreur sont les nœuds de sortie. Le recalage des poids sur le lien entre le nœud caché et le nœud de sortie est fonction de ce taux d'erreur aux nœuds de sortie. Mais, Comment trouver le taux d'erreur dans les nœuds cachés? On peut montrer statistiquement que:
Erreur @ H1 = W (H1O1) *[email protégé] + W (H1O2) *[email protégé]
Utiliser ces erreurs, nous pouvons recalibrer les poids des liens entre les nœuds cachés et les nœuds d'entrée de manière équivalente. Imaginez que ce calcul soit effectué plusieurs fois pour chacune des observations de l'ensemble d'apprentissage..
Les trois questions fondamentales
Quelle est la corrélation entre le temps consommé par l'algorithme et le volume de données (par rapport aux modèles traditionnels tels que la logistique)?
Comme mentionné précédemment, pour chaque observation, ANN effectue plusieurs réétalonnages pour chaque poids de lien. Pour cela, le temps pris par l'algorithme augmente beaucoup plus vite que les autres algorithmes traditionnels pour la même augmentation de volume de données.
Dans quelle situation l'algorithme s'adapte-t-il le mieux?
ANN est rarement utilisé pour la modélisation prédictive. La raison en est que les réseaux de neurones artificiels (ANN) ils essaient généralement de trop ajuster le chevillage. ANN est généralement utilisé dans les cas où ce qui s'est passé dans le passé se répète presque exactement de la même manière. Par exemple, disons que nous jouons au jeu de black jack contre un ordinateur. Un adversaire intelligent basé sur ANN serait un très bon adversaire pour ce cas. (en supposant qu'ils peuvent garder le temps de calcul bas). Avec le temps, ANN se préparera à tous les cas de flux de cartes possibles. Et comme on bat pas les cartes avec un croupier, ANN pourra mémoriser chaque appel. Pour cela, c'est une sorte de technique d'apprentissage automatique qui a une énorme mémoire. Mais cela ne fonctionne pas bien si la population de notation est significativement différente de celle de l'échantillon d'apprentissage. Par exemple, si je prévois de cibler un client pour une campagne en utilisant sa réponse précédente d'un ANN. Je vais probablement utiliser la mauvaise technique, puisque vous avez peut-être sur-ajusté le lien entre la solution et d'autres prédicteurs.
Pour la même raison, fonctionne très bien dans les cas d'accréditation d'image et d'accréditation de voix.
Ce qui fait d'ANN un modèle très fort en matière de mémorisation?
Réseaux de neurones artificiels (ANN) ont beaucoup de coefficients différents, que vous pouvez profiter au maximum. Pour cela, peut gérer beaucoup plus de variabilité par rapport aux modèles traditionnels.
Le message a-t-il été utile? Avez-vous utilisé d'autres outils d'apprentissage automatique récemment? Envisagez-vous d'utiliser ANN dans l'un de vos problèmes commerciaux? Le cas échéant, dites nous comment vous comptez le faire.





